文章目录
- 0 前言
- 1 课题背景
- 2 数据爬取
- 2.1 爬虫简介
- 2.2 房价爬取
- 3 数据可视化分析
- 3.1 ECharts
- 3.2 相关可视化图表
- 4 最后
0 前言
🔥 Hi,大家好,这里是丹成学长的毕设系列文章!
🔥 对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
🚩 大数据房价数据分析及可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
1 课题背景
房地产是促进我国经济持续增长的基础性、主导性产业。如何了解一个城市的房价的区域分布,或者不同的城市房价的区域差异。如何获取一个城市不同板块的房价数据?
本项目利用Python实现某一城市房价相关信息的爬取,并对爬取的原始数据进行数据清洗,存储到数据库中,利用pyechart库等工具进行可视化展示。
2 数据爬取
2.1 爬虫简介
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个 URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪 装 请求头以便更好地获取网页数据。
爬虫流程图如下:
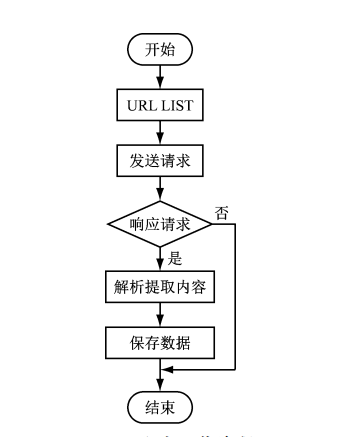
实例代码
# get方法实例
import requests #先导入爬虫的库,不然调用不了爬虫的函数
response = requests.get("http://httpbin.org/get") #get方法
print( response.status_code ) #状态码
print( response.text )
2.2 房价爬取
累计爬取链家深圳二手房源信息累计18906条
- 爬取各个行政区房源信息;
- 数据保存为DataFrame;
相关代码
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm
import math
import requests
import lxml
import re
import time
area_dic = {'罗湖区':'luohuqu',
'福田区':'futianqu',
'南山区':'nanshanqu',
'盐田区':'yantianqu',
'宝安区':'baoanqu',
'龙岗区':'longgangqu',
'龙华区':'longhuaqu',
'坪山区':'pingshanqu'}
# 加个header以示尊敬
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36',
'Referer': 'https://sz.lianjia.com/ershoufang/'}
# 新建一个会话
sess = requests.session()
sess.get('https://sz.lianjia.com/ershoufang/', headers=headers)
# url示例:https://sz.lianjia.com/ershoufang/luohuqu/pg2/
url = 'https://sz.lianjia.com/ershoufang/{}/pg{}/'
# 当正则表达式匹配失败时,返回默认值(errif)
def re_match(re_pattern, string, errif=None):
try:
return re.findall(re_pattern, string)[0].strip()
except IndexError:
return errif
# 新建一个DataFrame存储信息
data = pd.DataFrame()
for key_, value_ in area_dic.items():
# 获取该行政区下房源记录数
start_url = 'https://sz.lianjia.com/ershoufang/{}/'.format(value_)
html = sess.get(start_url).text
house_num = re.findall('共找到<span> (.*?) </span>套.*二手房', html)[0].strip()
print('💚{}: 二手房源共计「{}」套'.format(key_, house_num))
time.sleep(1)
# 页面限制🚫 每个行政区只能获取最多100页共计3000条房源信息
total_page = int(math.ceil(min(3000, int(house_num)) / 30.0))
for i in tqdm(range(total_page), desc=key_):
html = sess.get(url.format(value_, i+1)).text
soup = BeautifulSoup(html, 'lxml')
info_collect = soup.find_all(class_="info clear")
for info in info_collect:
info_dic = {}
# 行政区
info_dic['area'] = key_
# 房源的标题
info_dic['title'] = re_match('target="_blank">(.*?)</a><!--', str(info))
# 小区名
info_dic['community'] = re_match('xiaoqu.*?target="_blank">(.*?)</a>', str(info))
# 位置
info_dic['position'] = re_match('<a href.*?target="_blank">(.*?)</a>.*?class="address">', str(info))
# 税相关,如房本满5年
info_dic['tax'] = re_match('class="taxfree">(.*?)</span>', str(info))
# 总价
info_dic['total_price'] = float(re_match('class="totalPrice"><span>(.*?)</span>万', str(info)))
# 单价
info_dic['unit_price'] = float(re_match('data-price="(.*?)"', str(info)))
# 匹配房源标签信息,通过|切割
# 包括面积,朝向,装修等信息
icons = re.findall('class="houseIcon"></span>(.*?)</div>', str(info))[0].strip().split('|')
info_dic['hourseType'] = icons[0].strip()
info_dic['hourseSize'] = float(icons[1].replace('平米', ''))
info_dic['direction'] = icons[2].strip()
info_dic['fitment'] = icons[3].strip()
# 存入DataFrame
if data.empty:
data = pd.DataFrame(info_dic,index=[0])
else:
data = data.append(info_dic,ignore_index=True)
爬取过程

3 数据可视化分析
3.1 ECharts
ECharts(Enterprise Charts)是百度开源的数据可视化工具,底层依赖轻量级Canvas库ZRender。兼容了几乎全部常用浏览器的特点,使它可广泛用于PC客户端和手机客户端。ECharts能辅助开发者整合用户数据,创新性的完成个性化设置可视化图表。支持折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)等,通过导入 js 库在 Java Web 项目上运行。
python安装
pip install pyecharts
3.2 相关可视化图表
房源面积-总价散点图
scatter = (Scatter(init_opts=opts.InitOpts(theme='dark'))
.add_xaxis(data['hourseSize'])
.add_yaxis("房价", data['total_price'])
.set_series_opts(label_opts=opts.LabelOpts(is_show=False),
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max", name="最大值"),]))
.set_global_opts(
legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(title="深圳二手房 总价-面积 散点图"),
xaxis_opts=opts.AxisOpts(
name='面积',
# 设置坐标轴为数值类型
type_="value",
# 不显示分割线
splitline_opts=opts.SplitLineOpts(is_show=False)),
yaxis_opts=opts.AxisOpts(
name='总价',
name_location='middle',
# 设置坐标轴为数值类型
type_="value",
# 默认为False表示起始为0
is_scale=True,
splitline_opts=opts.SplitLineOpts(is_show=False),),
visualmap_opts=opts.VisualMapOpts(is_show=True, type_='color', min_=100, max_=1000)
))
scatter.render_notebook()
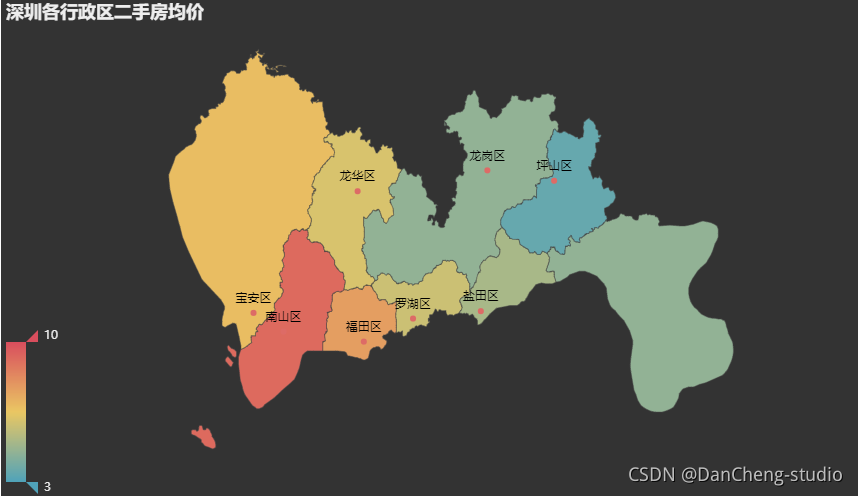
 各行政区均价
各行政区均价
temp = data.groupby(['area'])['unit_price'].mean().reset_index()
data_pair = [(row['area'], round(row['unit_price']/10000, 1)) for _, row in temp.iterrows()]
map_ = (Map(init_opts=opts.InitOpts(theme='dark'))
.add("二手房均价", data_pair, '深圳', is_roam=False)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(
title_opts=opts.TitleOpts(title="深圳各行政区二手房均价"),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(formatter='{b}:{c}万元'),
visualmap_opts=opts.VisualMapOpts(min_=3, max_=10)
)
)
map_.render_notebook()
均价最高的10个地段
temp = data.groupby(['position'])['unit_price'].mean().reset_index()
data_pair = sorted([(row['position'], round(row['unit_price']/10000, 1))
for _, row in temp.iterrows()], key=lambda x: x[1], reverse=True)[:10]
bar = (Bar(init_opts=opts.InitOpts(theme='dark'))
.add_xaxis([x[0] for x in data_pair])
.add_yaxis('二手房均价', [x[1] for x in data_pair])
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, font_style='italic'),
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode("""new echarts.graphic.LinearGradient(0, 1, 0, 0,
[{
offset: 0,
color: 'rgb(0,206,209)'
}, {
offset: 1,
color: 'rgb(218,165,32)'
}])"""))
)
.set_global_opts(
title_opts=opts.TitleOpts(title="深圳二手房均价TOP 10地段"),
legend_opts=opts.LegendOpts(is_show=False),
tooltip_opts=opts.TooltipOpts(formatter='{b}:{c}万元'))
)
bar.render_notebook()

户型分布
temp = data.groupby(['hourseType'])['area'].count().reset_index()
data_pair = sorted([(row['hourseType'], row['area'])
for _, row in temp.iterrows()], key=lambda x: x[1], reverse=True)[:10]
pie = (Pie(init_opts=opts.InitOpts(theme='dark'))
.add('', data_pair,
radius=["30%", "75%"],
rosetype="radius")
.set_global_opts(title_opts=opts.TitleOpts(title="深圳二手房 户型分布"),
legend_opts=opts.LegendOpts(is_show=False),)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
pie.render_notebook()

词云图
word_list = []
stop_words = ['花园','业主','出售']
string = str(''.join([i for i in data['title'] if isinstance(i, str)]))
words = psg.cut(string)
for x in words:
if len(x.word)==1:
pass
elif x.flag in ('m', 'x'):
pass
elif x.word in stop_words:
pass
else:
word_list.append(x.word)
data_pair = collections.Counter(word_list).most_common(100)
wc = (WordCloud()
.add("", data_pair, word_size_range=[20, 100], shape='triangle')
.set_global_opts(title_opts=opts.TitleOpts(title="房源描述词云图"))
)
wc.render_notebook()







![封装window10-21H1踩的坑,无法分析或处理pass[specialize]应答文件](https://img-blog.csdnimg.cn/img_convert/fdb00eb32b5bab426ec385c6668f8b27.jpeg)

![[附源码]计算机毕业设计JAVA新冠疫苗线上预约系统](https://img-blog.csdnimg.cn/542f21ebb5e844f28223a267615c15bd.png)