全部学习汇总: GreyZhang/g_TC275: happy hacking for TC275! (github.com)

这里接触到了几种测试的方式。其中一个是反复执行同一个命令,看看执行之间的间隔。执行的时候,命令是有一定顺序的。这样,有时候流水线等特性会导致效率的降低。最后一个程序流的延迟,我觉得更加贴近于实际的使用。不同于前面的限制,前面其实是没有限制命令的目的地的。而这个程序流的延迟其实是限制了相同的目的地,但是指令是哪个并不重要。
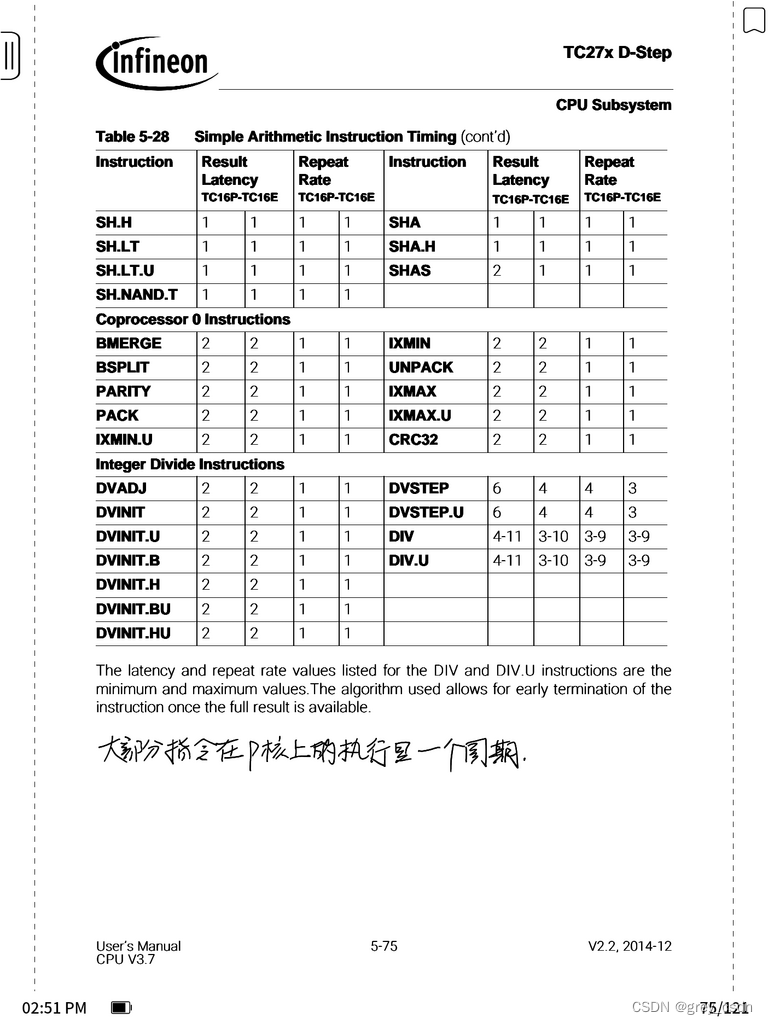
大部分指令在P核上的执行是一个机器指令,相比之下E核心的效率会差一些。

这里的结果其实是来自于理论分析而不是实际的测试。

由于没有分支预测的功能,E核上的时间特性其实比较稳定。尤其是在控制流方面,甚至说还有一些优势。
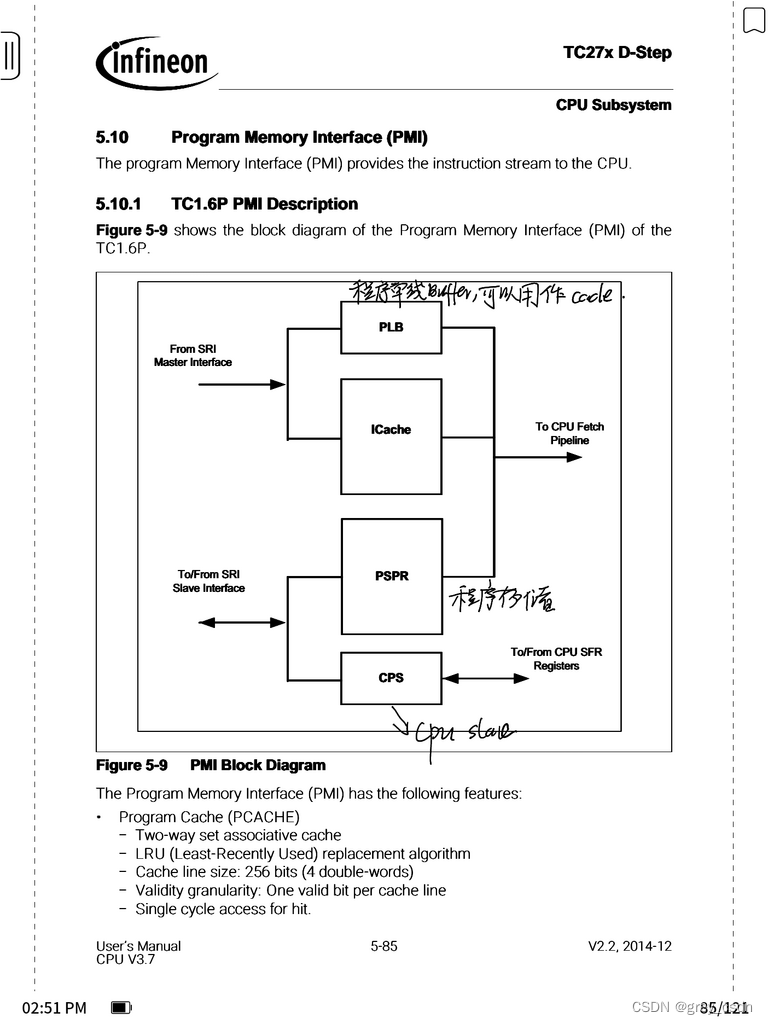
这个图中的PLB是程序单线buffer的意思,可以理解为是指令加载的专用cache。CPS则是CPUslave的意思,主要是通过SRI访问其他的寄存器。

1. PSPR,程序用的RAM。可以用来提升代码执行时候的性能。CPU取这些存储上的指令的时候会直接读取而不会进行缓存。
2. 作为程序存储用的时候,这部分存储是只读的。

1. 看到这里我思考了一个问题,cache听上去似乎是只有速度提升的作用不会慢。为什么也有导致执行慢的时候呢?cache之所以能够实现执行的加速就是因为访问速度快,而这部分的数据更新其实是按块来更新的。在CPU进行指令获取的时候,得看所需要的内容是否会在cache中。如果在,那就是命中,可以以高速访问的方式读取。如果不在,还得按照普通的方式来获取。这样,相比于直接进行普通的读取就会多一个判断的时间。
2. PCache有一个数据流的模式,一定条件下可以读写并行。
3. 默认情况下的PCache是不开启的。
4. cache与存储的一致性没有绑定关系,硬件是不支持直接的绑定的。

这里有对前面框图中的模块的具体解释。
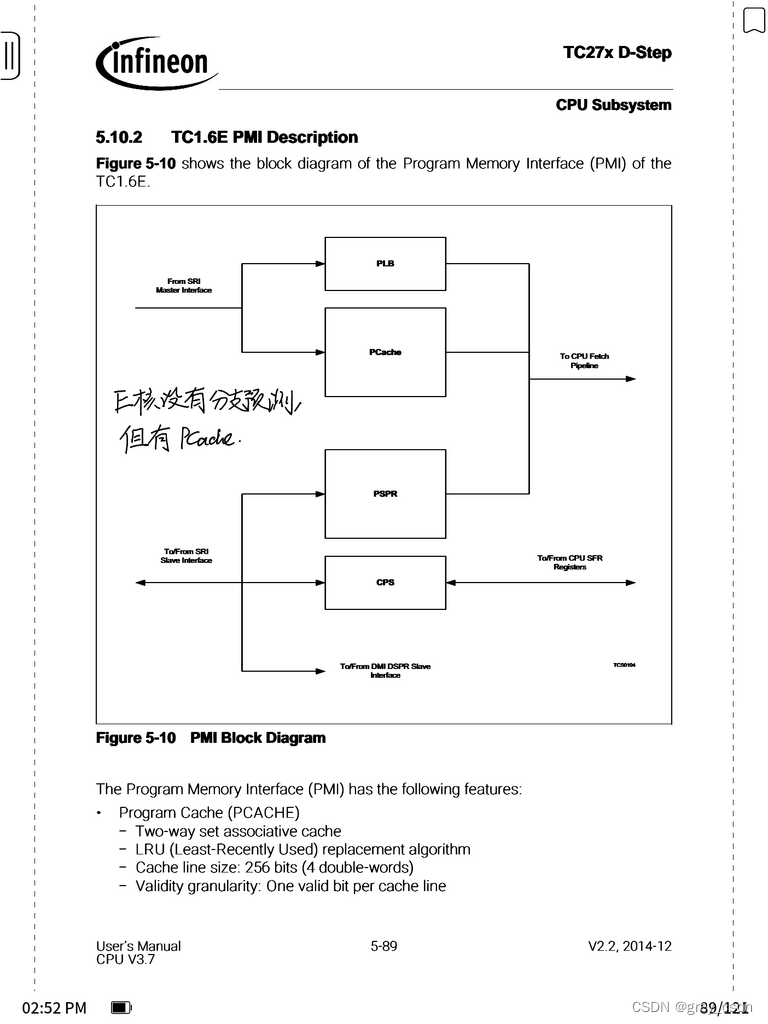
这个框图跟P核是一样的,这里也有过一点疑惑但是发现是自己弄混了。E核与P核最大的效率差异有两点,一个是总线宽度,另一个则是预测功能。但是两者都有PCache的支持。

1. 相比于P核,E少了一个单时钟周期命中的特性。
2. E核的总线宽度有些设计不同于P核,这也是其效率较低的一个因素。
3. 其他的部分,E核其实与P核的功能是类似的。

一直很好奇cache的开启以及关闭如何实现,这里找到了相关的寄存器。

这个trap相关寄存器位的清除方法是写入信息,不管写什么内容。

最后这一部分是关于程序存储接口的几种错误检测机制。



![封装window10-21H1踩的坑,无法分析或处理pass[specialize]应答文件](https://img-blog.csdnimg.cn/img_convert/fdb00eb32b5bab426ec385c6668f8b27.jpeg)

![[附源码]计算机毕业设计JAVA新冠疫苗线上预约系统](https://img-blog.csdnimg.cn/542f21ebb5e844f28223a267615c15bd.png)