前言
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章

女同事最近迷上了一本书
但她又不想下载软件,就想要我给你下载成txt慢慢看
一看章节,两千四百四十四章,这我能答应嘛?

面对美女小姐姐的请求,我当场表示:锻炼技术嘛~这事我熟,马上就给你下载下来

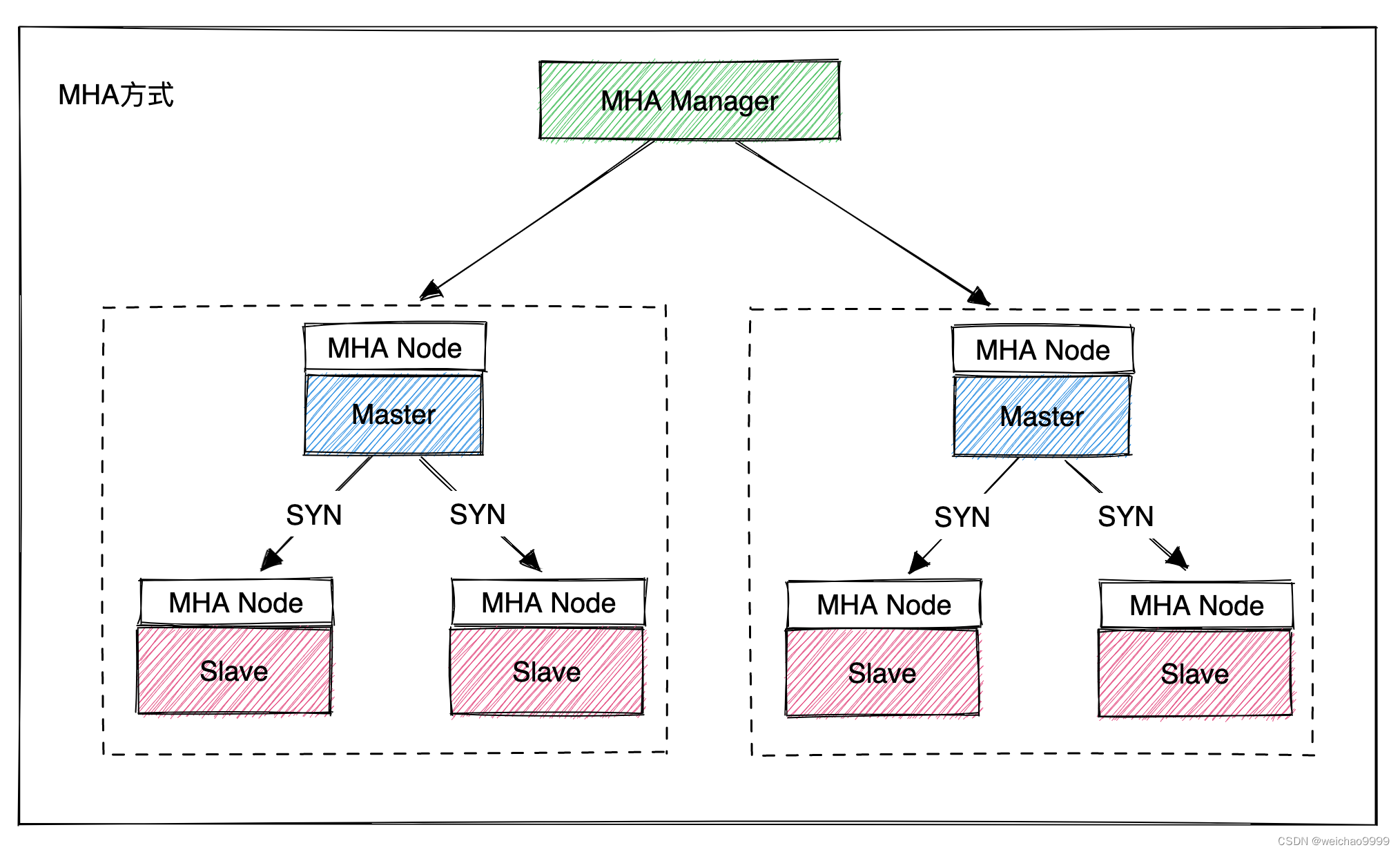
开发环境:
-
python 3.8 运行代码
-
pycharm 2022.3 辅助敲代码
-
requests 发送请求模块
代码实现:
-
发送请求
-
获取数据
-
解析数据
-
保存数据
代码展示
import requests # 发送请求的模块 第三方的模块 需要额外安装
import re
url = 'https://****/book_2700/1556861.html'
# 1. 发送请求
response = requests.get(url)
# 2. 获取数据
html_data = response.text
# 3. 解析数据 提取数据内容
# 结构化数据 json数据
# 非结构化数据 网页源代码
# css/xpath/re
# https://.*html
# <br><br>.*?</div>
text = re.findall('<br><br>(.*?)</div>', html_data)[0]
text = text.replace('<br />', '\n')
text = text.replace(' ', ' ')
# 4. 保存数据
open("第二章.txt", mode='w', encoding='utf-8').write(text)
更多精彩请点击文末名片解锁噢~
括展小知识
什么是re(正则表达式).*?:
搜索功能的 更高级的一个用法
在正则里面 . 可以去代表一个字符
*: 匹配前面表达式 0次或者多次
.*: 需要匹配 一个字符 n次 贪婪匹配
?: 非贪婪匹配符
尾语 💝
好了,今天的分享就差不多到这里了!
完整代码、更多资源、疑惑解答直接点击下方名片自取即可。
对下一篇大家想看什么,可在评论区留言哦!看到我会更新哒(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!