OpenVINO 2022.3实战三:POT API实现图像分类模型 INT8 量化
1 准备需要量化的模型
这里使用我其他项目里面,使用 hymenoptera 数据集训练好的 MobileNetV2 模型,加载pytorch模型,并转换为onnx。
import os
from pathlib import Path
import sys
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import numpy as np
from openvino.tools.pot.api import DataLoader, Metric
from openvino.tools.pot.engines.ie_engine import IEEngine
from openvino.tools.pot.graph import load_model, save_model
from openvino.tools.pot.graph.model_utils import compress_model_weights
from openvino.tools.pot.pipeline.initializer import create_pipeline
from openvino.runtime import Core
from torchvision import transforms
from subprocess import run
from SlimPytorch.quantization.mobilenet_v2 import MobileNetV2
# Set the data and model directories
DATA_DIR = '/home/liumin/data/hymenoptera/val'
MODEL_DIR = './weights'
def load_pretrain_model(model_dir):
model = MobileNetV2('mobilenet_v2', classifier=True)
num_ftrs = model.fc[1].in_features
model.fc[1] = nn.Linear(num_ftrs, 2)
model.load_state_dict(torch.load(model_dir, map_location='cpu'))
return model
def load_val_data(data_dir):
data_transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image_dataset = datasets.ImageFolder(data_dir, data_transform)
# dataload = torch.utils.data.DataLoader(image_dataset, batch_size=1, shuffle=False, num_workers=4)
return image_dataset
model = load_pretrain_model(Path(MODEL_DIR) / 'mobilenet_v2_train.pt')
dataset = load_val_data(DATA_DIR)
model.eval()
dummy_input = torch.randn(1, 3, 224, 224)
onnx_model_path = Path(MODEL_DIR) / 'mobilenet_v2.onnx'
ir_model_xml = onnx_model_path.with_suffix('.xml')
ir_model_bin = onnx_model_path.with_suffix('.bin')
torch.onnx.export(model, dummy_input, onnx_model_path)
运行模型优化器将ONNX转换为OpenVINO IR:
mo --compress_to_fp16 -m .\weights\mobilenet_v2.onnx --output_dir .\weights\
2 定义数据加载和精度验证功能
这里注意 需要继承来自 openvino.tools.pot.api 的 DataLoader和 Metric 类
# Create a DataLoader.
class QDataLoader(DataLoader):
def __init__(self, config):
"""
Initialize config and dataset.
:param config: created config with DATA_DIR path.
"""
super().__init__(config)
self.dataset = dataset
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
"""
Return one sample of index, label and picture.
:param index: index of the taken sample.
"""
image, label = self.dataset[index]
return (index, label), image.numpy()
def load_data(self, dataset):
"""
Load dataset in needed format.
:param dataset: downloaded dataset.
"""
pictures, labels, indexes = [], [], []
for idx, sample in enumerate(dataset):
pictures.append(sample[0])
labels.append(sample[1])
indexes.append(idx)
return indexes, pictures, labels
class Accuracy(Metric):
# Required methods
def __init__(self, top_k=1):
super().__init__()
self._top_k = top_k
self._name = 'accuracy@top{}'.format(self._top_k)
self._matches = []
@property
def value(self):
""" Returns accuracy metric value for the last model output. """
return {self._name: self._matches[-1]}
@property
def avg_value(self):
""" Returns accuracy metric value for all model outputs. """
return {self._name: np.ravel(self._matches).mean()}
def update(self, output, target):
""" Updates prediction matches.
:param output: model output
:param target: annotations
"""
if len(output) > 1:
raise Exception('The accuracy metric cannot be calculated '
'for a model with multiple outputs')
if isinstance(target, dict):
target = list(target.values())
predictions = np.argsort(output[0], axis=1)[:, -self._top_k:]
match = [float(t in predictions[i]) for i, t in enumerate(target)]
self._matches.append(match)
def reset(self):
""" Resets collected matches """
self._matches = []
def get_attributes(self):
"""
Returns a dictionary of metric attributes {metric_name: {attribute_name: value}}.
Required attributes: 'direction': 'higher-better' or 'higher-worse'
'type': metric type
"""
return {self._name: {'direction': 'higher-better',
'type': 'accuracy'}}
3 运行优化流程
量化模型
model_config = {
'model_name': 'mobilenet_v2',
'model': ir_model_xml,
'weights': ir_model_bin
}
engine_config = {'device': 'CPU'}
dataset_config = {
'data_source': DATA_DIR
}
algorithms = [
{
'name': 'DefaultQuantization',
'params': {
'target_device': 'CPU',
'preset': 'performance',
'stat_subset_size': 300
}
}
]
# Steps 1-7: Model optimization
# Step 1: Load the model.
model = load_model(model_config)
# Step 2: Initialize the data loader.
data_loader = QDataLoader(dataset_config)
# Step 3 (Optional. Required for AccuracyAwareQuantization): Initialize the metric.
metric = Accuracy(top_k=1)
# Step 4: Initialize the engine for metric calculation and statistics collection.
engine = IEEngine(engine_config, data_loader, metric)
# Step 5: Create a pipeline of compression algorithms.
pipeline = create_pipeline(algorithms, engine)
# Step 6: Execute the pipeline.
compressed_model = pipeline.run(model)
# Step 7 (Optional): Compress model weights quantized precision
# in order to reduce the size of final .bin file.
compress_model_weights(compressed_model)
# Step 8: Save the compressed model to the desired path.
compressed_model_paths = save_model(model=compressed_model, save_path=MODEL_DIR, model_name="quantized_mobilenet_v2"
)
compressed_model_xml = compressed_model_paths[0]["model"]
compressed_model_bin = Path(compressed_model_paths[0]["model"]).with_suffix(".bin")
4 比较原始模型和量化模型的准确性
# Step 9: Compare accuracy of the original and quantized models.
metric_results = pipeline.evaluate(model)
if metric_results:
for name, value in metric_results.items():
print(f"Accuracy of the original model: {name}: {value}")
metric_results = pipeline.evaluate(compressed_model)
if metric_results:
for name, value in metric_results.items():
print(f"Accuracy of the optimized model: {name}: {value}")
输出:
Accuracy of the original model: accuracy@top1: 0.9215686274509803
Accuracy of the optimized model: accuracy@top1: 0.921568627450980
5 比较原始模型和量化模型的性能
使用OpenVINO中的Benchmark Tool(推理性能测量工具)测量FP16和INT8模型的推理性能
FP16:
benchmark_app -m .\weights\mobilenet_v2.xml -d CPU -api async
输出:

INT8:
benchmark_app -m .\weights\quantized_mobilenet_v2.xml -d CPU -api async
输出:
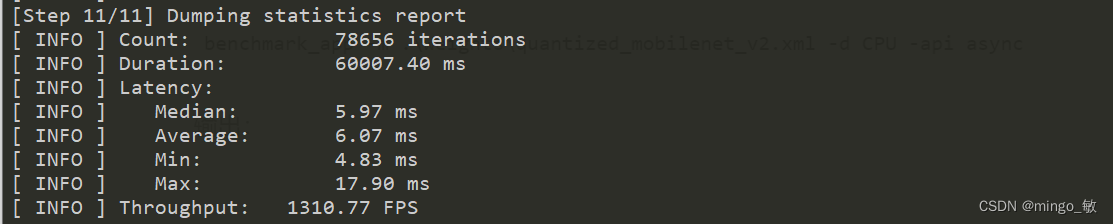
可以看出吞吐量增大了1.5倍