最近,来自阿卜杜拉国王科技大学(KAUST)的研究团队开发了一种基于现有LLMs的机器人交互框架LLM-Brain,LLM-Brain可以直接将LLM作为机器人的大脑,并以此来构建一个以自我为中心的记忆和控制框架。

论文链接:
https://arxiv.org/abs/2304.09349

随着ChatGPT、GPT-4等大模型逐渐进入大众视野,大家开始想象如果将这些大语言模型(LLMs)接入到实实在在的物理机器人中,能否使机器人获得自主的智能感知决策能力呢?例如电影《星际穿越》中的飞船辅助机器人塔斯(TARS)就具有感知外界并进行自主决策的能力,塔斯在电影中多次做出非常智能的决策,力挽狂澜。
最近,来自阿卜杜拉国王科技大学(KAUST)的研究团队开发了一种基于现有LLMs的机器人交互框架LLM-Brain,LLM-Brain可以直接将LLM作为机器人的大脑,并以此来构建一个以自我为中心的记忆和控制框架。作者团队提到,对物理机器人开发能够与环境动态交互的智能系统,需要重点从机器人系统的记忆能力和控制能力两方面入手。LLM-Brain可以通过zero-shot学习方法为机器人集成多个多模态语言模型,这些模型可以实现像ChatGPT一样使用自然语言进行闭环的多轮对话,包括感知、规划、控制和记忆,以达到使机器人能够自行维护一套记忆并自行控制的效果。作者团队通过主动探索(active exploration)和具身问答(embodied question answering)这两个机器人领域的下游任务来评估LLM-Brain框架的性能。其中主动探索任务要求机器人在有限的动作范围内实现对未知环境的感知。而具身问答任务则要求机器人能够根据先前探索中获得的观察结果来回答具体的问题。

一、LLM-Brain的构建过程
1.1机器人子任务分解
为了使机器人能够达到自主感知环境并进行自主决策的效果,作者团队首先将LLM-Brain框架的构建过程分解为三个子任务:
1.首先机器人通过查看视觉传感器捕获的以自我为中心的视频关键帧,并对该帧进行理解和回答与当前场景有关的一系列问题。
2.LLM-Brain通过进一步提问来获取场景中的详细信息,使机器人更加全面的了解环境。
3.LLM-Brain对机器人所观察的历史帧以及执行过的历史动作进行记忆,以达到3D场景和机器人历史轨迹的掌握。随后结合这些历史信息和人类给出的指令来规划和控制机器人。
1.2 眼睛-神经-大脑(Eye-Nerve-Brain)三代理设计
针对上述三个子任务,作者在LLM-Brain中设计了三个关键代理模块分别进行对应,如下图所示。
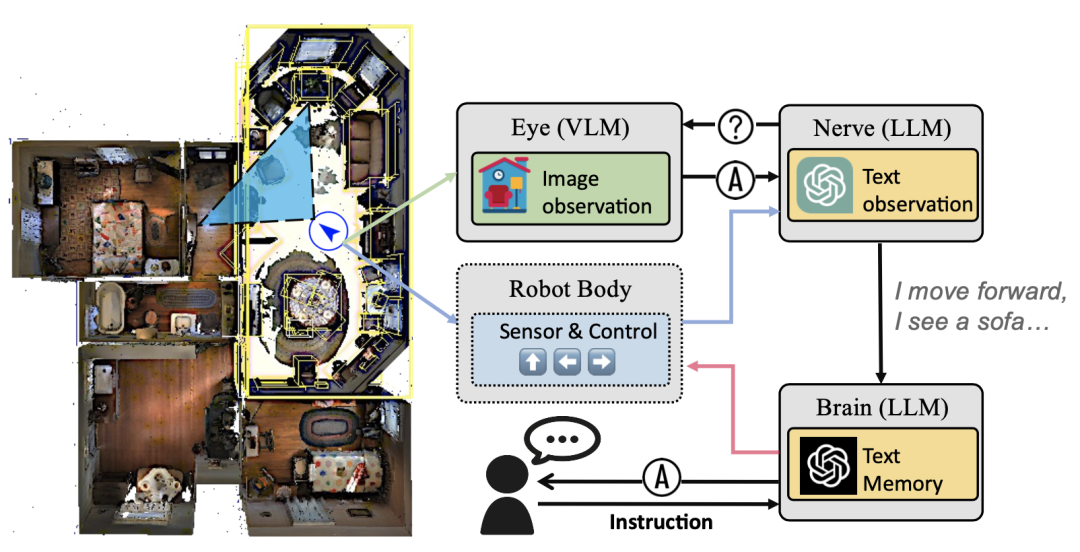
1. 眼睛代理
眼睛代理是机器人感知外界的工具,为了能够对场景图像进行精确的识别和理解,作者在眼睛代理中设置了规模较大的视觉语言模型(Vision Language Model,VLM)[1]。VLM的输入可以是一幅观察图像和与该图像相关的问题,输出是模型根据给定问题使用自然语言做出的回答。但是目前通用的VLM大多都是在高质量图像上训练的,而机器人捕获到的以自我为中心的视频帧通常会遇到由于周围成像环境以及传感器误差而引起的低质量问题,这会大大影响VLM对周围环境的理解效果。作者参考ChatCaptioner[2]中的设计,通过将VLM和LLM连接起来以迭代问答的形式来理解环境。
2. 神经代理
神经代理可以理解为是机器人的中枢控制系统,它首先会解析眼睛代理传回的图像内容,并根据图像内容向眼睛提出多个问题并构成多轮对话,并且结合机器人做出动作来详细总结当前的环境情况。随后将这些信息转发给等级更高的大脑代理。
3. 大脑代理
大脑作为最高等级的信息处理和决策代理,仅与来自中枢系统的神经代理进行环境感知通信。由于机器人整体会处于一个移动的状态,大脑会同时得到神经代理和机器人自身运动的反馈信息。大脑需要同时整合这两者的信息来维护一个机器人的场景记忆库,它可以在没有人为干预的情况下根据历史信息以及从神经代理传回的环境感知信息来推断出下一步的合理动作。作者为大脑设计了一些行动上下文:move_forward、turn_left、turn_right和stop。大脑可以使用这些基本的文本命令来控制机器人。当然,大脑代理也支持接受人类的指令。
在具体操作时,作者分别为眼睛代理设置了一个BLIP2模型[1],这是一个大规模预训练的VQA模型,此外分别为神经和大脑代理设置了两个ChatGPT text-davinci-003模型[3]。对于机器人,作者使用Habitat[4]平台来模拟视觉环境和机器人行动,Habitat可以模拟生成机器人的第一视角与俯视图视角视频。

二 、实验效果
为了对LLM-Brain进行性能评估,作者选取了目前具身智能领域较为流行的Matterport 3D 数据集,Matterport 3D中包含各种室内场景,通过多个RGBD相机扫描真实环境得到,作者团队重点评估了LLM-Brain在主动探索(active exploration)和具身问答(embodied question answering)这两个机器人下游子任务上的效果。
2.1主动探索
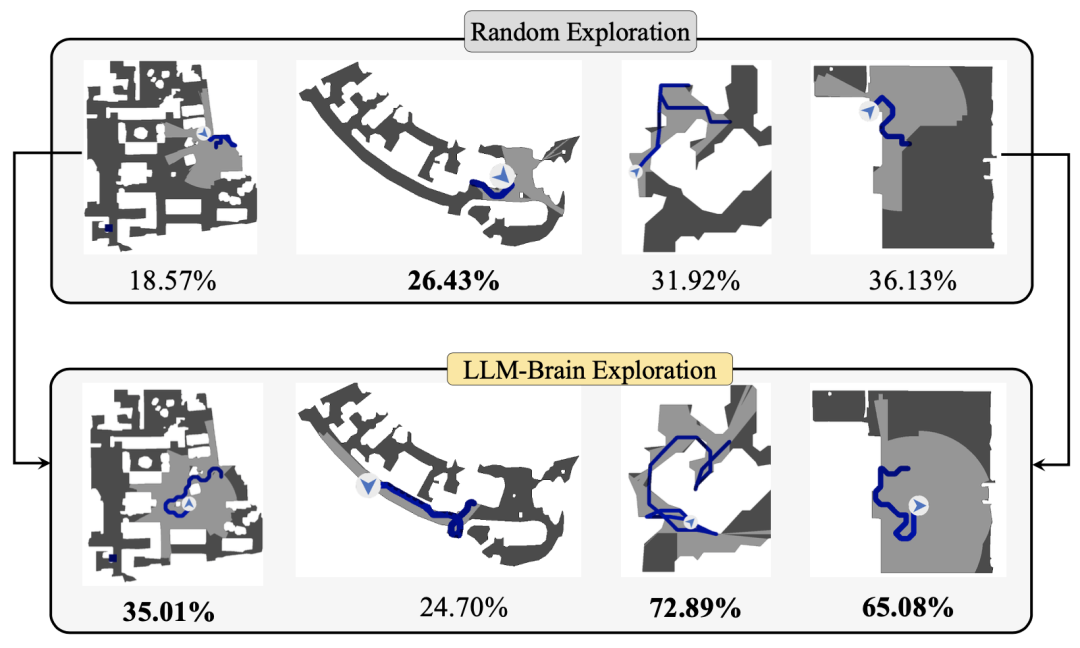
在主动探索子任务中,作者对LLM-Brain设置了”尽可能完整地探索当前这所房子“的指令。下图展示了LLM-Brain根据眼睛-神经-大脑三个代理对环境的理解效果。

在上图(a)中,LLM-Brain对所捕获到的图像分析得到:”这是一个走廊,右边有一扇窗户。房间里没有家具。房间中间有一扇门。房间的大小和形状未知。“ 并且根据这些信息得出下一步的动作是”move_forward(前进)“。
主动探索任务可以通过探索面积与房间总面积的比率来定量评估,如下图所示,LLM-Brain可以有效地驱使机器人来自主的探索环境。并且需要注意的是,LLM-Brain完全是零样本设计的,没有在与当前环境相关的数据集上进行微调训练。
2.2 具身问答
下图展示了LLM-Brain在具身问答任务上的效果,LLM-Brain首先通过以环境感知信息以及运动轨迹等历史信息维护一个机器人自身的记忆库。

随后可以对其进行提问,例如可以询问它”这件房子里有电视机吗?“ LLM-Brain会立马回答道:”是的,这所房子有一台电视。它位于客厅里,在房间的左边。“

可以看到LLM-Brain不仅能够理解问题本身的含义并作出回答,甚至还能够准确理解相关目标在房间中的3D位置关系。
三 、总结
本文基于现有的大型语言模型(ChatGPT)和大型视觉语言模型(BLIP-2)以zero-shot的形式构建了一个多功能多任务的机器人控制框架LLM-Brain。通过引入自然语言交流和闭环对话,LLM-Brain可以有效地对齐不同模态之间的差距,进一步增强了机器人感知、计划、控制和保留记忆的能力。此外,LLM-Brain还具有很强的扩展能力,它可以轻松的集成到各种机器人下游任务中,例如主动探索和具身问题回答。LLM-Brain的出现可以说是提高了嵌入式人工智能系统在现实世界场景中的适应性和适用性,展示了智能机器人在新一轮人工智能大模型变革浪潮中的巨大潜力。
参考文献
[1] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
[2] Jun Chen, Deyao Zhu, Kilichbek Haydarov, Xiang Li, and Mohamed Elhoseiny. Video chatcaptioner: Towards the enriched spatiotemporal descriptions. arXiv preprint arXiv:2304.04227, 2023.
[3] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
[4] Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019.
作者:seven_
Illustration by IconScout Store from IconScout