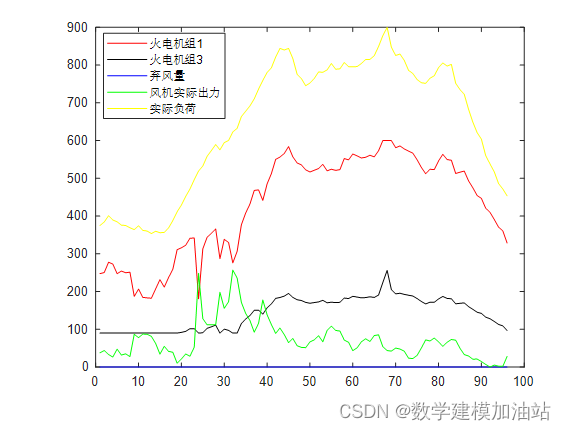
在使用WINDOWS或智能手机的时候,经常会遇到存储空间不足的问题,鲜有人会打开文件管理系统自己逐个清理,不仅因为底层的系统文件繁多操作耗时,更有其操作专业度高、风险高的问题。这时我们往往会求助各种各样的清理大师,快速又安全的完成数据清理工作。这些“大师”虽说也经常搞点“事情”,但是清理效果倒也不错。
运营商业务支撑系统每天业务量动辄几十万笔,每笔订单一般会经过多个环节,关联写入各种表的数据量几百条,导致日增数据几千万至上亿条。为保障订单处理的效率都会将数据库划分为生产库和历史库,生产库的数据控制在一个较小规模,只要订单竣工归档则需要迁移转储到历史库。
一、太难了
数据迁移往往是某种业务在特定时间段范围内的批量操作,某笔业务会涉及到多张表, 如果迁移遗漏表会导致在归档历史数据的查询出错。比如家庭宽带业务开通历史数据迁移,单张订单关联到46张表的528条记录,缺少一条记录都会导致订单查询功能的报错,表间关联深度最多可到6层,数量繁多关联逻辑复杂,一线运维团队往往不敢轻易下手。
数据迁移是一种事务性任务,必须在归档区写入成功后才能在在途库进行清理。单批次操作几百上千笔业务,几万条数据迁移只要一条出错,都可能意味着整批次迁移工作的停止甚至是回退。尤其在异构迁移归档的时候,从关系型数据要到KV数据库,或者是要重建二级索引表的时候。这些事务保障性操作是非常繁多且严格的。
数据从生产库迁移到历史库后,还有可能因为某些原因需要个别逆向恢复。比如某客户投诉业务某项功能不可用,排查分析后发现是因为某张订单生成的业务指令不正确,需要调整规则后重新再执行一遍。这种业务投诉来得急,需要尽快处理,但这种逆向操作不仅涉及的表跟正向归档一样复杂,并且还要考虑对在途订单数据的影响。
二、常见转储场景
全量转储和增量转储
全量是指对整个数据库或者某个表的数据全部重新备份转移。增量转储针对的是对上次完全转储之后,对所有新增或修改的记录进行转储。业务开通/编排系统面对的绝大多数是增量订单/工单转储。
静态转储和动态转储
静态转储是指当系统中无运行事务时进行转储,转储过程数据库处于一致状态,生产业务中断,适用场景相对有限。动态转储是指转储操作与用户事务并发进行,转储期间允许对数据库进行存取或修改,生产业务不会中断,适用场景广泛。但需要处理任务扫描遗漏、表锁、算力使用优先等问题。
同构转储和异构转储
同构转储是指目标库和源头库都基于同样的存储介质/技术/模型结构。数据库本身自带了一些数据导出导入工具,可以快速完成线下数据的简单转储,比如MySQL的outfile、dumpfile等。异构转储的目标和源头之间会存在介质/技术/模型结构的差异,比如从MySQL转储到PG、数据分片字段差异、附件路径转换等,这需要专用工具来解决。
单表转储和多表转储
单表转储过程不涉及其它表,逻辑简单,常见于某些登录日志表。多表转储是生产系统中常见的情况,某些符合条件的业务数据记录分布在多张表上,必须一起迁移,在同一笔事务中完成。否则事务一致性未控制好,会导致生产库业务更新和历史库查询的错误。比如订单、开通流程实例、环节实例、工单、工单属性,必须是一套完整的数据才能实现订单查询功能。
三、怎么破
运营商核心业务支撑系统是7×24不间断运行,每天各类业务量近百万,数据库中增量数据近亿,涉及数百张表。如此繁忙的业务系统,是如何处理业务数据的转储的呢?让我们一探究竟~

一键检测
生产系统中大大小小的表几百张,每张表几百万级的数据量,哪些表数据该做迁移转储,没几个人能都说得清,就算说得清楚的人用运维脚本检测个遍也得用十几分钟以上。一键检测,实时自动构建出鸟瞰全局存储的视图,自动给出给出转储建议和动作。
-
容量超配预警
由产品线系统专家对各个表/文件系统的合理数量设定一个合理阈值,对实时存储数据量和容量使用率进行预警。
-
过期老旧内容
各个表内的数据记录在各时间段/各类数据占比,比如是否存在2个月前已归档的订单数据,是否还有已下线产品的数据,是否还存有压力测试数据等。
-
临时备份数据
在项目运维过程中可能会存在人为去备份某些表的时候,比如XXX_230405,XXX_BAK等,这些备份表使用后往往有忘记清理。通过对表名称、字段结构、内容进行相似度自动检查,自动全库扫描找出这些无用备份表。
自动识别出数量大于一定阈值且未配置转储规则的表,这些表可能是因为项目组自定义,出厂时未纳入管理范畴的表。
一键转储
生产系统中最常规要做的转储工作是生产库转入历史库,每条业务记录分布在几十个表和多个文件中。每次人工转储,都需要细心的运维人员打开多个转储脚本,按顺序逐表转移清理,表表数据彼此关联,稍有不慎生产事故!一键清理,将这些高风险高专业度操作进行标准化封装,让转储运维操作易如反掌。

-
查转删检一体化
封装集成了转储操作的完整过程,包括:计算转储范围、读取源数据并标识、数据转换并写入目标库、完整性校验、源数据清理、表重新统计(确保索引生效)。
-
多表关联操作支持
为各系统各场景提供多表数据关联模板化设计能力,通过各产品线研发将多个彼此相关的多表关联关系预先建立起来,配置正确的操作顺序,对各个项目现场的数据转储操作标准化规范化,普通运维人员无需再去关注难以厘清的转储先后逻辑关系。
-
完整事务化支持
数据转储完整性一致性的保障,如果数据转储失败,可自动进行脏数据清理恢复,能支持异构库(如MySQL到PG)事务、异构技术事务(如报文从接口单文件到归档压缩文件,接口表的报文目录指针也会随之调整)等多种情况。
自动运行
数据转储是个长期化的运维工作,多数在夜间业务闲时执行,长期安排人员在夜间值班运维无论从成本还是从人员能力要求来说都是不可行的。自动化运行能力,从多方面降低转储过程中的人员参与工作量,降低运维成本。
-
忙时自动调度
通常会在预设的闲时时间段内,通过CRON表达式规划转储工作执行计划。在定时执行转储任务的时候,可能会出现突发的业务流(比如半夜从计费发起一大批次的业务开通/关闭单),转储任务调度可智能识别并暂停转储任务,避免与主用业务争抢算力,待突发业务流完结后自动重启。
-
效率自动评估
通过效率指标TPKR(每千条数据转储耗时)和TPM(每兆数据转储耗时),评估转储任务执行效率。当TPKR和TPM劣化的时候,主动通知运维进行优化,形成闭环治理。
-
策略自动优化
当数据转储能力<数据生成能力的时候,生产库的数据总量势必会积压增加,当这种情况持续一段时间后,转储调度会自动识别发现,根据效率评估结果,重新调整任务调度策略,并通知运维人员进行确认。
四、关键要点
脏数据处理
数据转储任务在执行过程中,由于人为或意外中断,导致待转储源数据既没有被转储到目标库,也不能被下批次的转储任务读取到;又或者是目标库已写入但源头库的数据未清理。因此需要在转储工具周期性的自动检查这些数据,按前任务执行的状态完成断点续行或脏数据清理。
充分预检避免异常
在正式转储前,需要对整个转储环境进行检测,评估当前是否具备转储条件,最大可能避免在转储操作过程中可能的出错或中止。这些预检测的环境值一般可通过数据库专用函数自动查询。
转储目标库容量是否满足本次转储数据的存储
-
目标库和源头库索引是否存在。如果索引无效,可能会导致单次转储数据的抓取时间过长,转储任务积压
-
目标库的数据结构是否符合要求,比如:分片表是否已就绪,目标表字段有没有被修改过
-
目标库的数据结构是否符合要求,比如:分片表是否已就绪,目标表字段有没有被修改过
避免滚雪球灾难
数据转储任务是个长期执行的任务,每到一定周期会自动读取一批次数据进行转储,到下一周期又会反复如上操作。如果下一周期任务执行时,上一周期任务未执行完成,那么系统就会并行2批次任务执行。如此迭代下去,就会产生雪球效应,系统内并行任务积压越多,执行越慢,积压越多,最后导致内存泄漏。因此要控制好并行转储的数量,设定安全阈值。
效率与灵活的平衡
操作过数据库的同学一定有体会,批次操作数据的效率一般都会比单次要高,单次读写1000条数据一定比1000次读写1条数据效率高,那每次数据读取量设置个巨高值,甚至一次读完写完?不尽然。目前经过运营商自己重新封装后的各种数据库都会有单次操作限制。此外单次任务如果读写数据量超高,可能会导致单次任务执行时间超长到10分钟以上。期间如果刚好业务流突发,我们想终止转储任务,要么顶着压力漫长等待,要么KILL进程后修复数据。因此,将单次转储任务合理的控制在1分钟以内是个相对合适的选择。
数据转储的可逆性
数据从生产库转储到历史库后,可能会有些意外情况,比如订单已归档,但是后面发现南向的资源中心分配资源错误,需要重新激活订单修正资源配置,那就需要将历史数据转回生产库。因此,在转储模型设计的时候,要考虑原有生产库的信息是否会丢失,是否可转换。由于这种逆向转换是极个别的意外事件,因此可基于数据转储框架将历史库和生产库转置配置即可,封装出一个API在运维页面上以工具按钮的形式开放使用。
面向多场景的可扩展性
数据转储并非简单的表到表的转换,在实际生产中会存在表→压缩表,表→文件,文件→文件的各种场景。比如历史库订单也不会无限膨胀,对于3年以上的数据,会将历史表中的不再用的日志环节数据清理,只保留可用于分析和样本学习的必要核心业务信息,以CSV文本格式进行压缩归档保存。因此转储工具都需要保留灵活的扩展接口,由各业务应用系统的开发团队加以实现所需场景。
五、后语
对于已归档转储出去的业务数据,并非是清理出的垃圾,依旧是有应用价值的。比如分析某些业务的开通效率,或者分析某些经营单元的业务质量,或者分析预测某些业务发展趋势等。
因此在迁移转储设计时,充分考虑这些数据应用场景,规划好技术平台、数据结构模型、存储分区等,后续的数据的价值挖掘和新应用开发将更加的方便。