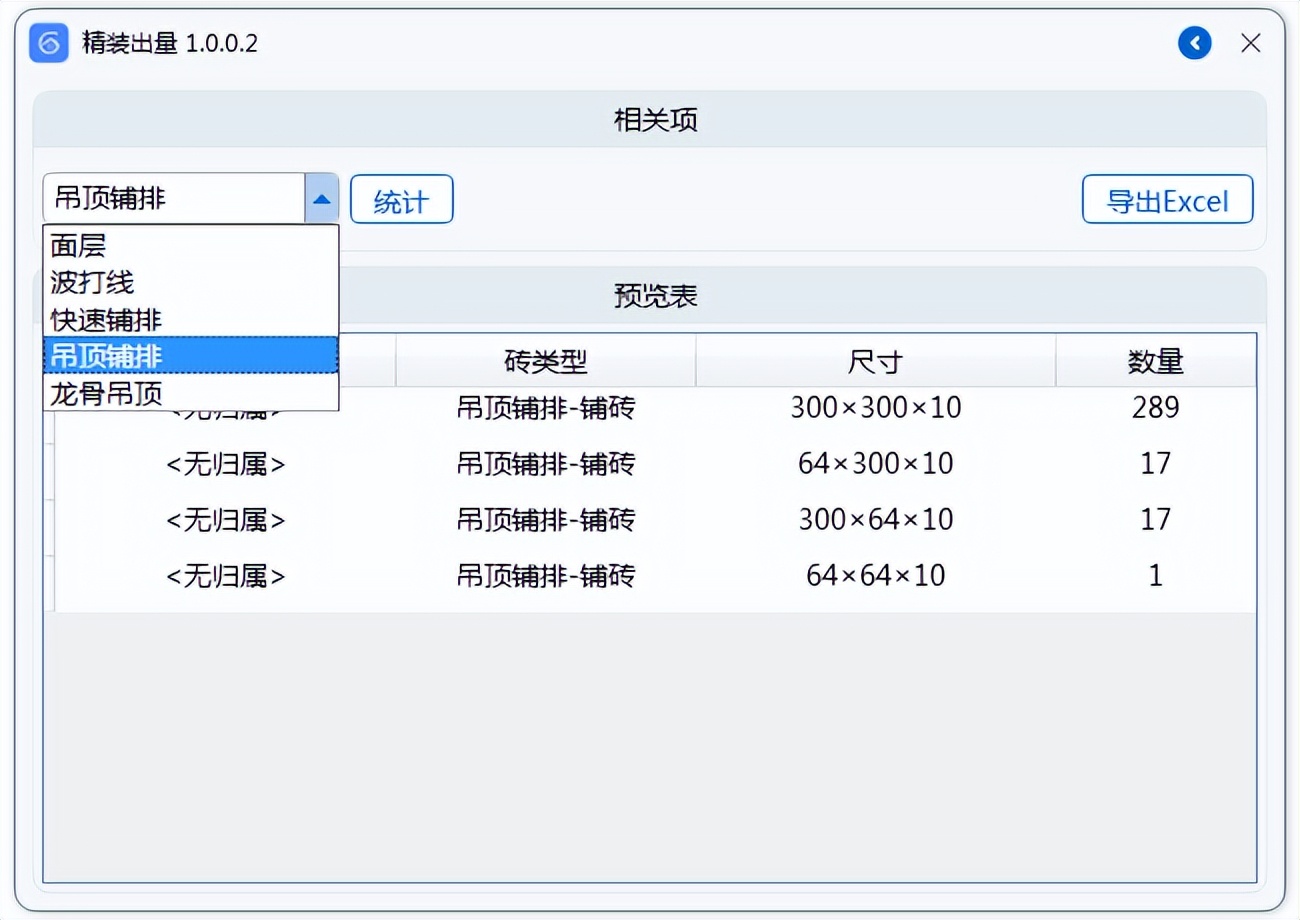
我们提出了一种新的领域泛化框架(称为EISNet),该框架利用来自多源领域图像的外在关系监督和内在自我监督学习,学习如何同时在不同领域中进行泛化。
- 具体而言,我们采用多任务学习范式,通过特征嵌入来构建我们的框架。
- 除了进行常规的监督识别任务外,我们无缝地集成了动量度量学习任务和自监督辅助任务,以共同整合外在和内在监督。
- 此外,我们还开发了一种有效的动量度量学习方案,采用K-hard负样本挖掘来提高网络的泛化能力。
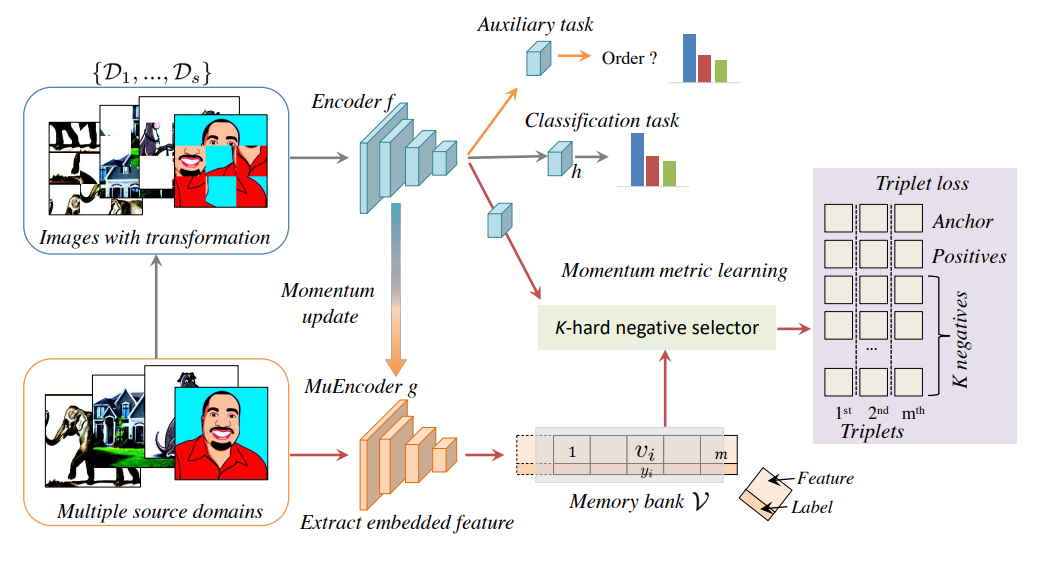
- 我们维护一个动量更新编码器(MuEncoder),生成存储在大型内存库中的动量更新嵌入。
- 此外,我们设计了一个K-hard负选择器,以从内存库中定位信息量大的三元组来计算三元组损失。辅助的自监督任务预测图像内部的patch顺序。
One is an extrinsic supervision with momentum metric learning, and the other is an intrinsic supervision with a self-supervised auxiliary task.
The momentum metric learning is employed by a triplet loss with a K-hard negative selector on the momentum updated embeddings stored in a large memory bank. We implement a self-supervised auxiliary task by predicting the order of patches within an image. All these tasks adopt a shared encoder f and are seamlessly integrated into an end-to-end learning framework. Below, we introduce the extrinsic supervision and intrinsic self-supervision in detail.
Extrinsic Supervision with Momentum Metric Learning
对于领域泛化问题,需要确保具有相同标签的样本特征彼此接近,而不同类别样本的特征之间相距较远。否则,在未知的目标领域上进行预测时,可能会遭受模糊的决策边界和性能下降[8,20]。这与度量学习的理念是一致的。
因此,我们设计了一个动量度量学习方案,通过考虑跨域样本之间的相互关系,鼓励网络学习这种领域无关但类别特定的特征。具体而言,我们提出了一种新的K-hard负选择器用于三元组损失,通过在内存库中选择信息量大的三元组来提高训练效果,以及一个动量更新编码器,以保证内存库中的嵌入表示的一致性。
K-hard negative selector for triplet loss
The triplet loss is defined as:
L_triplet = max(0, d(fθ(xa), fθ(xp)) - d(fθ(xa), fθ(xn)) + margin)
where d(·, ·) is a distance function, and margin is a hyperparameter that controls
the margin between the positive and negative pairs.
However, randomly selecting negative samples may not be sufficient to provide
informative triplets for effective training. Therefore, we propose a K-hard negative
selector to select the K hardest negative samples for each anchor sample xa from
the memory bank.
The memory bank stores the momentum updated embeddings
generated by the momentum updated Encoder MuEncoder.
The K-hard negative selector ensures that the selected negative samples have the highest distance to the anchor sample among all the negative samples in the memory bank.
- This strategy improves the training effectiveness by selecting informative triplets with larger distances and more challenging sample pairs.
Intrinsic Supervision with Self-supervised Auxiliary Task
许多工作都专注于设计辅助自监督任务,例如旋转度预测和图像中两个补丁的相对位置预测[7,13,21]。在这里,我们采用最近提出的拼图任务[2,32]作为我们的辅助任务。然而,大多数关注高级语义特征学习的自监督任务都可以纳入我们的框架。
- 具体而言,我们首先将图像分成九个(3×3)patch,并按照[2]的方法将这些patch随机组合成30种不同的组合方式。
正如[2]所指出的,当类别数设置为30时,模型的性能最高,当任务难度增加时,随着组合方式的增加,预测性能下降。一个新的辅助任务分支ha跟随提取的特征表示fθ,预测补丁的顺序。交叉熵损失被应用于解决这个顺序分类任务:
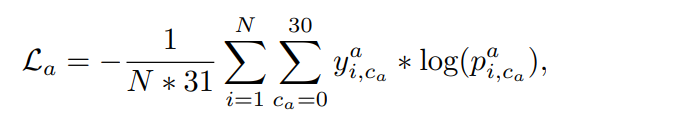
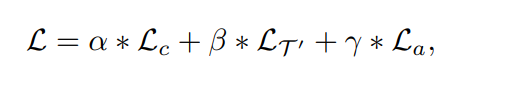

import argparse
import os
import torch
from torch import nn
from torch.nn import functional as F
from data import data_helper
from models import model_factory
from optimizer.optimizer_helper import *
from utils.Logger import Logger
from utils.losses import *
from utils.anchor_selector import *
from tqdm import tqdm
import torch.backends.cudnn as cudnn
cudnn.benchmark = True
def get_args():
parser = argparse.ArgumentParser(description="Script to launch jigsaw training", formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('-g', '--gpu', type=int, default=0, help='gpu id')
parser.add_argument("--source", choices=data_helper.available_datasets, help="Source", nargs='+')
parser.add_argument("--target", choices=data_helper.available_datasets, help="Target")
parser.add_argument("--batch_size", "-b", type=int, default=64, help="Batch size")
parser.add_argument("--image_size", type=int, default=225, help="Image size")
# data aug stuff
parser.add_argument("--min_scale", default=0.8, type=float, help="Minimum scale percent")
parser.add_argument("--max_scale", default=1.0, type=float, help="Maximum scale percent")
parser.add_argument("--random_horiz_flip", default=0.0, type=float, help="Chance of random horizontal flip")
parser.add_argument("--jitter", default=0.4, type=float, help="Color jitter amount")
parser.add_argument("--tile_random_grayscale", default=0.1, type=float, help="Chance of randomly greyscaling a tile")
parser.add_argument("--limit_source", default=None, type=int, help="If set, it will limit the number of training samples")
parser.add_argument("--limit_target", default=None, type=int, help="If set, it will limit the number of testing samples")
parser.add_argument("--learning_rate", "-l", type=float, default=.01, help="Learning rate")
parser.add_argument("--learning_rate_moco", "-lmoco", type=float, default=.003, help="Learning rate")
parser.add_argument("--epochs", "-e", type=int, default=100, help="Number of epochs")
parser.add_argument("--n_classes", "-c", type=int, default=31, help="Number of classes")
parser.add_argument("--jigsaw_n_classes", "-jc", type=int, default=30, help="Number of classes for the jigsaw task")
parser.add_argument("--network", choices=model_factory.nets_map.keys(), help="Which network to use", default="caffenet")
parser.add_argument("--jig_weight", type=float, default=0.7, help="Weight for the jigsaw puzzle")
parser.add_argument("--tri_weight", type=float, default=0.001, help="Weight for the triplet loss")
parser.add_argument("--moco_weight", type=float, default=0.1, help="Weight for the moco loss")
parser.add_argument("--ooo_weight", type=float, default=0, help="Weight for odd one out task")
parser.add_argument("--tf_logger", type=bool, default=True, help="If true will save tensorboard compatible logs")
parser.add_argument("--val_size", type=float, default="0.1", help="Validation size (between 0 and 1)")
parser.add_argument("--folder_name", default=None, help="Used by the logger to save logs")
parser.add_argument("--bias_whole_image", default=0.9, type=float, help="If set, will bias the training procedure to show more often the whole image")
parser.add_argument("--train_all", default=True, type=bool, help="If true, all network weights will be trained")
parser.add_argument("--suffix", default="", help="Suffix for the logger")
parser.add_argument("--nesterov", default=False, type=bool, help="Use nesterov")
parser.add_argument("--margin", default=0.2, type=float, help="Margin in triplet loss")
# loss function
parser.add_argument('--softmax', action='store_true', help='using softmax contrastive loss rather than NCE')
parser.add_argument('--nce_k', type=int, default=4096)
parser.add_argument('--nce_t', type=float, default=0.07)
parser.add_argument('--nce_m', type=float, default=0.5)
parser.add_argument('--k_triplet', type=int, default=5)
# memory setting
parser.add_argument('--moco', default=True, action='store_true', help='using MoCo (otherwise Instance Discrimination)')
parser.add_argument('--alpha', type=float, default=0.999, help='exponential moving average weight')
return parser.parse_args()
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def moment_update(model, model_ema, m):
""" model_ema = m * model_ema + (1 - m) model """
for p1, p2 in zip(model.parameters(), model_ema.parameters()):
p2.data.mul_(m).add_(1-m, p1.detach().data)
class Trainer:
def __init__(self, args, device):
self.args = args
self.device = device
model = model_factory.get_network(args.network)(classes=args.n_classes)
model_ema = model_factory.get_network(args.network)(classes=args.n_classes)
self.model = model.to(device)
self.model_ema = model_ema.to(device)
if args.moco:
moment_update(self.model, self.model_ema, 0)
self.tri_weight = self.args.tri_weight
print(self.model)
self.source_loader, self.val_loader = data_helper.get_train_dataloader(args, False)
self.target_loader = data_helper.get_val_dataloader(args)
self.test_loaders = {"val": self.val_loader, "test": self.target_loader}
self.len_dataloader = len(self.source_loader)
print("Dataset size: train %d, val %d, test %d" % (len(self.source_loader.dataset), len(self.val_loader.dataset), len(self.target_loader.dataset)))
self.optimizer, self.scheduler = get_optim_and_scheduler(self.model, args.epochs, args.learning_rate)
self.jig_weight = args.jig_weight
self.n_classes = args.n_classes
if args.target in args.source:
self.target_id = args.source.index(args.target)
print("Target in source: %d" % self.target_id)
print(args.source)
else:
self.target_id = None
self.moco_weight_init = self.args.moco_weight
self.moco_weight = self.moco_weight_init
self.k_triplet = args.k_triplet
self.initialize_queue()
def update_moco_weight(self):
self.moco_weight = self.moco_weight_init + (1-self.moco_weight_init)/self.args.epochs * self.current_epoch
def queue_data(self, data, k, label_list, label):
self.queue = torch.cat([data, k], dim=0)
label = label.float().unsqueeze(1)
self.label_list = torch.cat([label_list, label], dim=0)
def dequeue_data(self, K=4096):
if len(self.queue) > K:
self.queue = self.queue[-K:]
self.label_list = self.label_list[-K:]
def initialize_queue(self):
queue = torch.zeros((0, 128), dtype=torch.float).cuda()
label_list = torch.zeros((0, 1), dtype=torch.float).cuda()
for batch_idx, ((data, jig, class_l), d_idx) in enumerate(self.source_loader):
data1, data2 = torch.split(data, [3, 3], dim=1)
x_k = data1
x_k = x_k.cuda()
with torch.no_grad():
_, _, k, _ = self.model_ema(x_k)
k = k.detach()
self.queue_data(queue, k, label_list, class_l.cuda())
self.dequeue_data(K=self.args.nce_k)
break
def momentum_update(self, model_q, model_k, beta=0.999):
param_k = model_k.state_dict()
param_q = model_q.named_parameters()
for n, q in param_q:
if n in param_k:
param_k[n].data.copy_(beta * param_k[n].data + (1 - beta) * q.data)
model_k.load_state_dict(param_k)
def _do_epoch(self):
margin = self.args.margin
criterion_class = nn.CrossEntropyLoss()
triplet_loss = OnlineKTripletLoss(margin, KSemihardNegativeTripletSelectorFromMomentum(margin, k=self.k_triplet))
jigen_loss = nn.CrossEntropyLoss()
self.model.train()
self.model_ema.eval()
moco_loss = 0
for it, ((data, order, class_l), d_idx) in enumerate(self.source_loader):
data, class_l, d_idx, order = data.to(self.device), class_l.to(self.device), d_idx.to(self.device), order.to(self.device)
self.optimizer.zero_grad()
data1, data2 = torch.split(data, [3, 3], dim=1) # normal Jigen
class_logit, jig, q, qc = self.model(data2) # , lambda_val=lambda_val)
with torch.no_grad():
_, _, k, kc = self.model_ema(data1)
k = k.detach()
self.queue_data(self.queue, k, self.label_list, class_l)
self.dequeue_data(K=self.args.nce_k)
moco_loss, _ = triplet_loss(q, k, self.queue, class_l, self.label_list)
moco_loss = moco_loss * self.moco_weight
jig_loss = jigen_loss(jig, order)
jig_loss = jig_loss * self.jig_weight
class_loss = criterion_class(class_logit, class_l)
_, cls_pred = class_logit.max(dim=1)
loss = class_loss + jig_loss + moco_loss
loss.backward()
self.optimizer.step()
self.momentum_update(self.model, self.model_ema)
if (it) % 30 == 0:
print("{}/{} iter/epoch, [losses] class: {}, jig: {}, moco: {}, total: {}. ".format(it, self.current_epoch,
class_loss.item(),
jig_loss.item(),
moco_loss.item(),
loss.item(),
))
self.logger.writer.add_scalar('training loss/class', class_loss.item(), self.current_epoch*len(self.source_loader)+it)
self.logger.writer.add_scalar('training loss/jig', jig_loss.item(),
self.current_epoch * len(self.source_loader) + it)
self.logger.writer.add_scalar('training loss/moco', moco_loss.item(),
self.current_epoch * len(self.source_loader) + it)
self.logger.writer.add_scalar('training loss/total', loss.item(),
self.current_epoch * len(self.source_loader) + it)
self.model.eval()
with torch.no_grad():
for phase, loader in self.test_loaders.items():
total = len(loader.dataset)
if loader.dataset.isMulti():
class_correct, single_acc = self.do_test_multi(loader)
print("Single vs multi: %g %g" % (float(single_acc) / total, float(class_correct) / total))
else:
class_correct = self.do_test(loader)
class_acc = float(class_correct) / total
self.logger.writer.add_scalar('acc/'+phase, class_acc,
self.current_epoch * len(self.source_loader) + it, )
print("[{}] acc: {}".format(phase, class_acc))
self.results[phase][self.current_epoch] = class_acc
def do_test(self, loader):
class_correct = 0
for it, ((data, class_l), _) in enumerate(loader):
data, class_l = data.to(self.device), class_l.to(self.device)
class_logit, _, _, _ = self.model(data)
_, cls_pred = class_logit.max(dim=1)
class_correct += torch.sum(cls_pred == class_l.data)
return class_correct
def do_test_multi(self, loader):
class_correct = 0
single_correct = 0
for it, ((data, class_l), d_idx) in enumerate(loader):
data, class_l = data.to(self.device), class_l.to(self.device)
n_permutations = data.shape[1]
class_logits = torch.zeros(n_permutations, data.shape[0], self.n_classes).to(self.device)
for k in range(n_permutations):
class_logits[k] = F.softmax(self.model(data[:, k])[1], dim=1)
class_logits[0] *= 4 * n_permutations # bias more the original image
class_logit = class_logits.mean(0)
_, cls_pred = class_logit.max(dim=1)
single_logit, _ = self.model(data[:, 0])
_, single_logit = single_logit.max(dim=1)
single_correct += torch.sum(single_logit == class_l.data)
class_correct += torch.sum(cls_pred == class_l.data)
return class_correct, single_correct
def save_tsne(self):
self.model.eval()
embedding = torch.zeros((0, 2048), dtype=torch.float)
embedding_label = torch.zeros((0, 1), dtype=torch.long)
with torch.no_grad():
for it, ((data, class_l), _) in enumerate(self.target_loader):
data, class_l = data.to(self.device), class_l.to(self.device)
class_logit, jig, q, qc = self.model(data)
embedding = torch.cat([embedding, qc.cpu()])
embedding_label = torch.cat([embedding_label, class_l.unsqueeze(1).cpu()])
torch.cuda.empty_cache()
self.logger.writer.add_embedding(embedding.data,
metadata=embedding_label.data,
tag="TestImg")
def do_training(self):
self.logger = Logger(self.args, update_frequency=30) # , "domain", "lambda"
self.results = {"val": torch.zeros(self.args.epochs), "test": torch.zeros(self.args.epochs)}
for self.current_epoch in tqdm(range(self.args.epochs)):
self._do_epoch()
torch.cuda.empty_cache()
self.scheduler.step()
self.logger.writer.add_scalar('lr/basic', get_lr(self.optimizer), self.current_epoch)
self.save_tsne()
val_res = self.results["val"]
test_res = self.results["test"]
idx_best = val_res.argmax()
print('Val best test: ', test_res[idx_best], 'Test best test: ', test_res.max())
return self.logger, self.model
def main():
args = get_args()
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpu)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
trainer = Trainer(args, device)
trainer.do_training()
if __name__ == "__main__":
torch.backends.cudnn.benchmark = True
main()