目录
0.做题的失误
1.引用传值和传址
1.斐波那契数列
一.快速排序
1.挖坑法
2.优化
2.1 随机取数法
2.2 三数取中法
2.3把基准值相同的值移到基准旁边
2.4引用直接插入排序
3.Hoare 法:
4.非递归法
5.总结
二,归并排序
1.原理
2.代码实现
3.分析
4.非递归
5.海量数据的排序问题
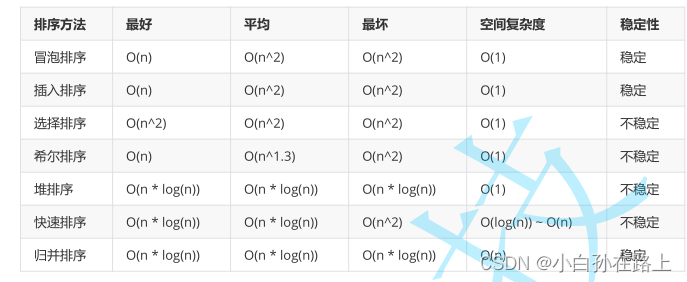
三.排序总结
四.非比较的排序
1.基数排序
2.桶排序
3.计数排序
1.原理
2.代码
3.分析
0.做题的失误
1.引用传值和传址
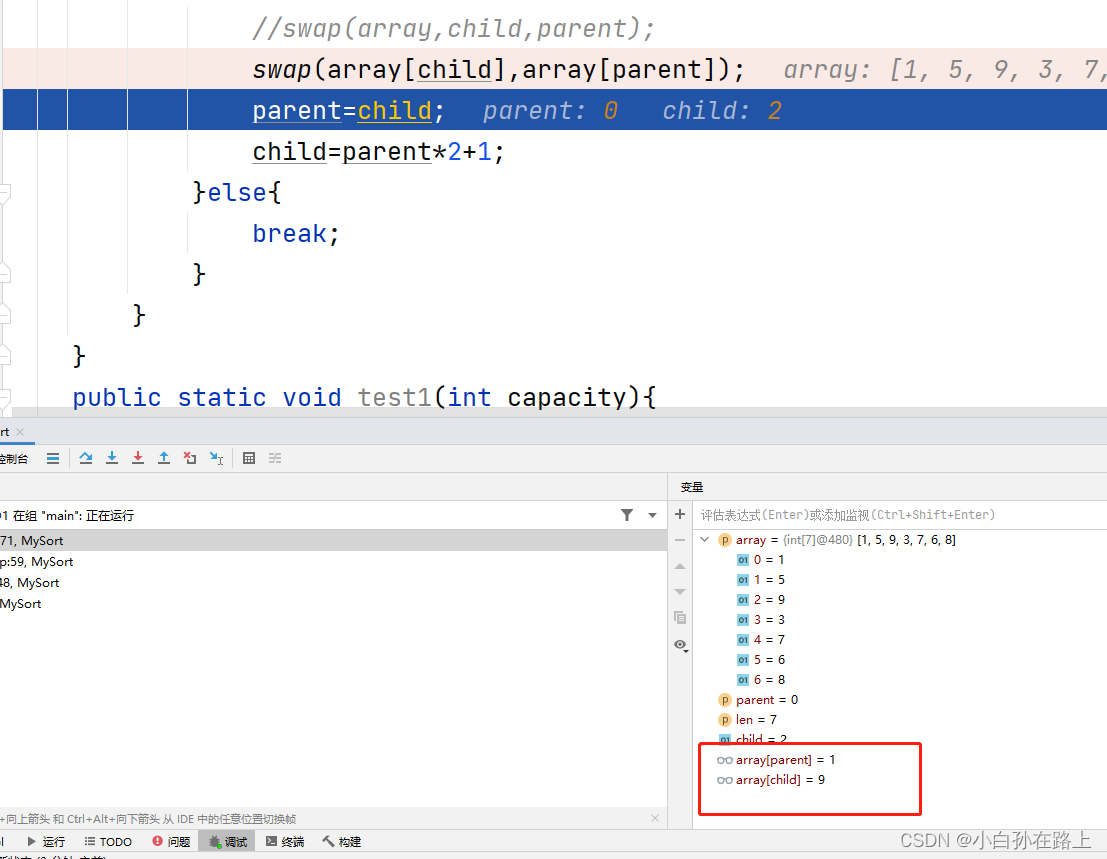
数组指向的对象是一个引用,函数结束的时候 就会消失
所以根本没有交换
要么我们的处理方式就是在函数内直接交换

或者写一个函数把数组也穿进去

1.斐波那契数列

这道题我们就需要找到给的这个数到离他最近的斐波那契左边的数和右边的数步数谁最小
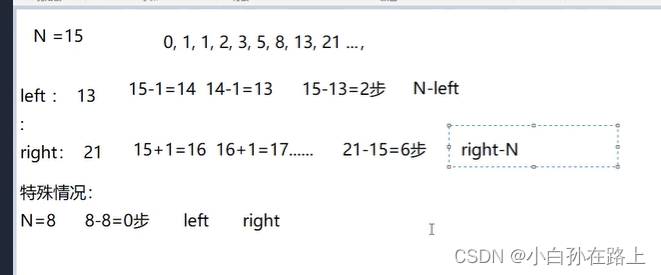
还有一种情况就是相同的时候,那么右边边的就是相同的.左边的还是一样求,最小的还是右边边的


循环结束的时候,N一定大于f1
因为f1是由f2得来的,f1一定比f2小,一次循环下俩
当n跳出循环一定是小于等于f2的
上一次的f2就是这次的f1.上次没有跳出就说明满足循环条件
import java.util.*;
public class Main{
public static void main(String[]args){
Scanner sc=new Scanner(System.in);
int n=sc.nextInt();
int a=0;
int b=1;
while(b<n){
int c=a+b;
a=b;
b=c;
}
//跳出循环的时候a就是N的左边的数,b就是n右边的数
System.out.println(Math.min(n-a,b-n));
}
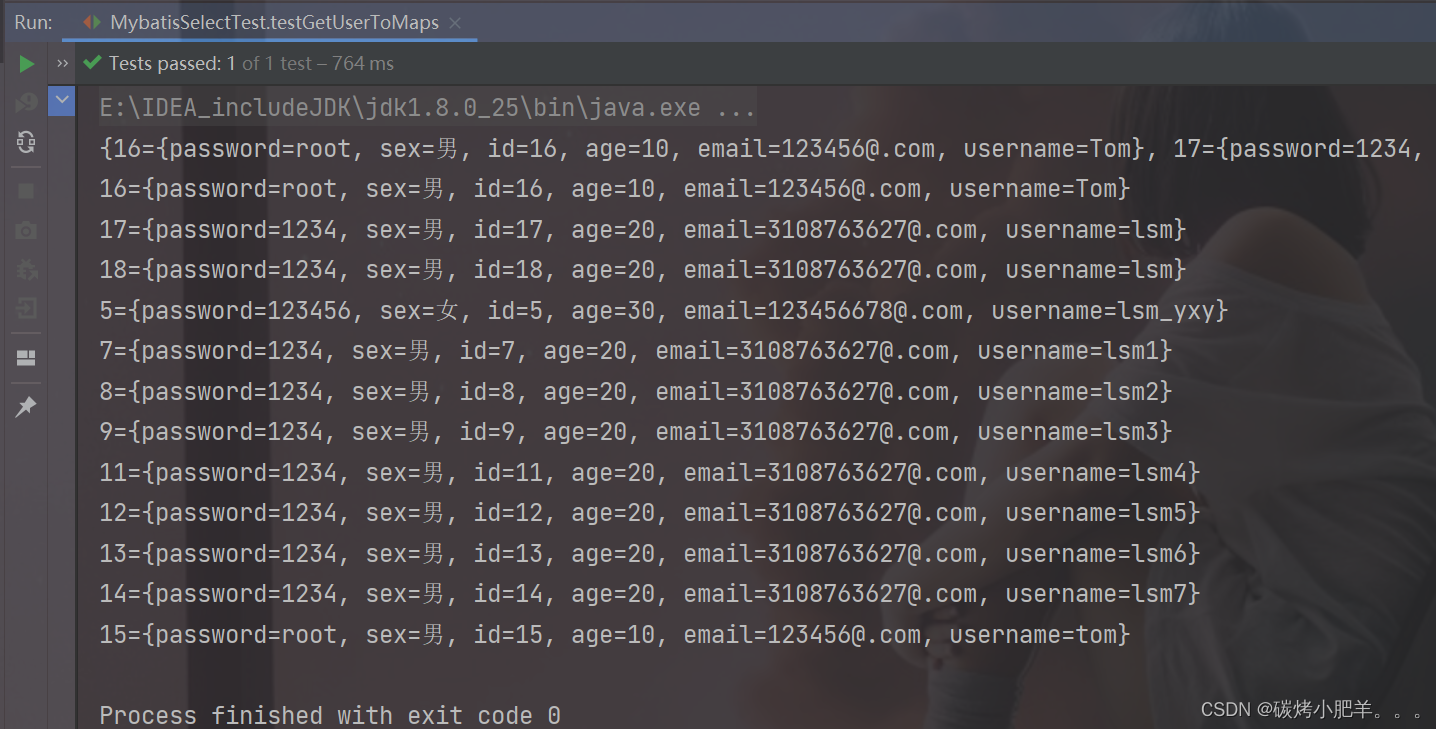
}一.快速排序
1.挖坑法
public static void quickSort(int[] array){
quick(array,0,array.length);
}
public static void quick(int[] array,int left,int right){
if(left>right) return;
int pivot=partition(array,left,right);
quick(array,left,pivot-1);//递归左区间
quick(array,pivot+1,right);
}
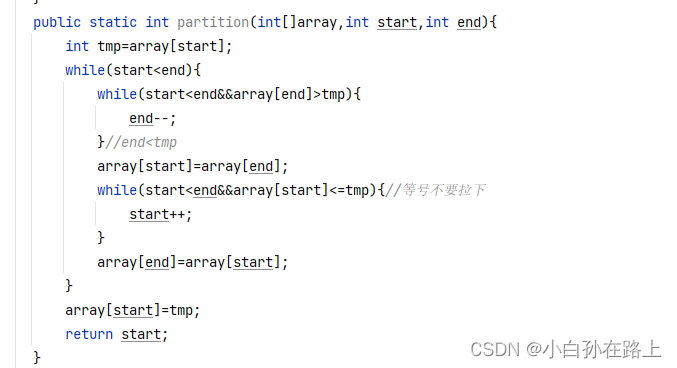
public static int partition(int[]array,int start,int end){
int tmp=array[start];
while(start<end){
while(start<end&&array[end]>tmp){
end--;
}//end<tmp
array[start]=array[end];
while(start<end&&array[start]<tmp){
start++;
}
array[end]=array[start];
}
array[start]=tmp;
return start;
}
2.优化

因为有可能这组数据是有序的,这种排序方法的最好的可能就是每组均匀分布,如果是有序的就成了一种单分支的二叉树
二叉树的高度就是n本身.所以最坏情况下的时间复杂度就是n*n
空间复杂度同理
所以我们尽量变成无序
2.1 随机取数法
随机除了第一个数以外的数与第一个数进行交换.
![]()
2.2 三数取中法
array[left], array[mid], array[right] 大小是中间的为基准值
找到中间数字,与left交换
代码实现

private static int findMidIndex(int[] array,int start,int end) {
int mid = start + ((end-start) >>> 1);
if(array[start] < array[end]) {
if(array[mid] < array[start]) {
return start;
}else if(array[mid] > array[end]) {
return end;
}else {
return mid;
}
}else {
if(array[mid] > array[start]) {
return start;
}else if(array[mid] < array[end]) {
return end;
}else {
return mid;
}
}
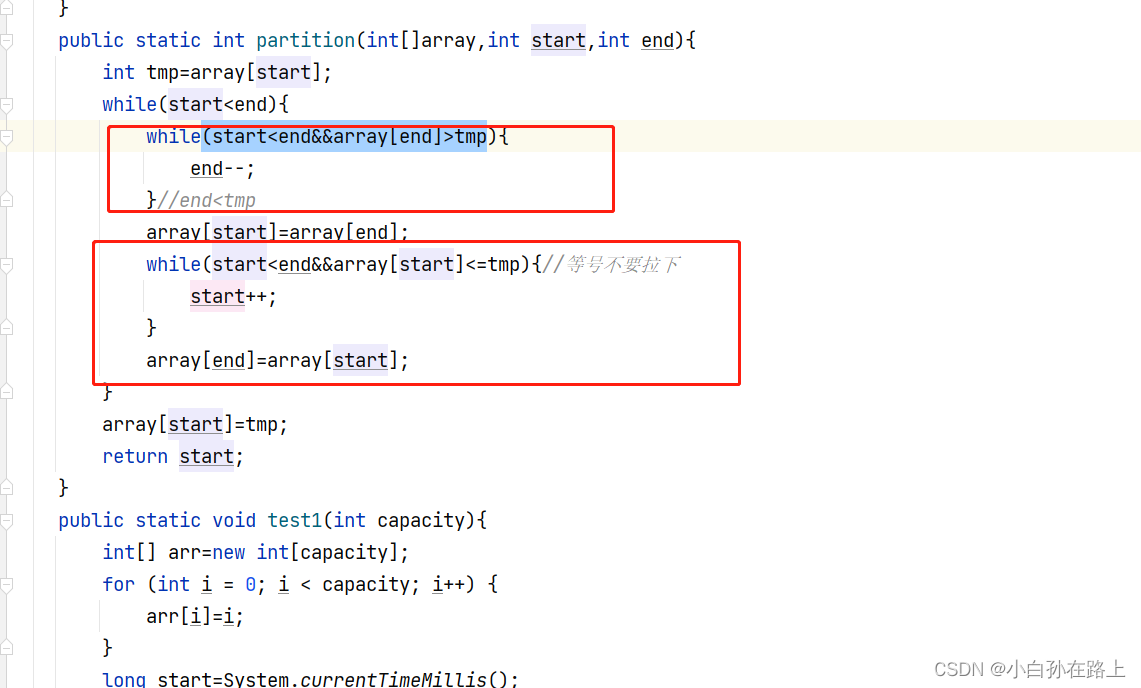
}2.3把基准值相同的值移到基准旁边
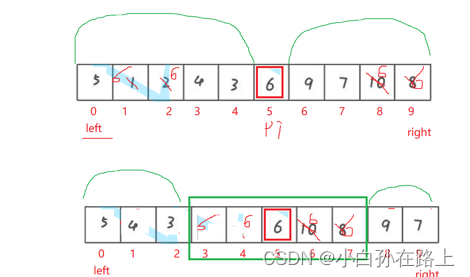
这样减小下次的区间
2.4引用直接插入排序
public static void insertSort2(int[] array,int start,int end){
for (int i = start+1; i <=end; i++) {
int tmp=array[i];
int j=i-1;
for (;j>=start;j--){
if(array[j]>tmp){
array[j+1]=array[j];
}else{
break;
}
}
array[j+1]=tmp;

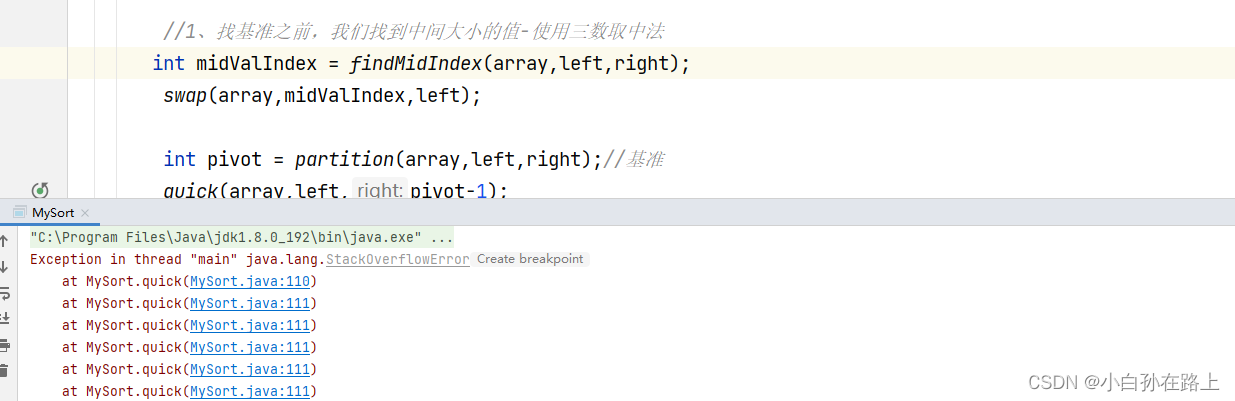
但我们发现 取消优化三数取中法,发生了栈溢出,很有可能就是因为不均匀分布,一直在一边反复递归
虽然有序比无序的情况要快一点,但是还是在一个数量级,
因为有序情况下可能就是一直循环,减少了交换
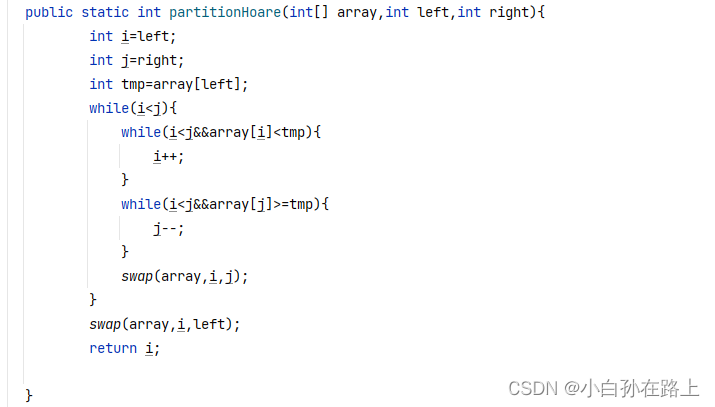
3.Hoare 法:

原理类似,只是从挖坑变成交换.\
定义两个指针,一个从左走,一个从右z走.
j从右走.找到比tmp小的,停止
i从左走,找到从tmp大的,停止
交换i和j
直到i和j相遇
把这个位置和left所在的也就是tmp的值交换
public static int partitionHoare(int[] array,int left,int right){
int i=left;
int j=right;
int tmp=array[left];
while(i<j){
while(i<j&&array[i]<tmp){
i++;
}
while(i<j&&array[j]>tmp){
j--;
}
swap(array,i,j);
}
swap(array,i,left);
return i;
}
经过测试,Hoare明显慢很多还容易栈溢出.可能会反复调用swap方法的原因把
4.非递归法
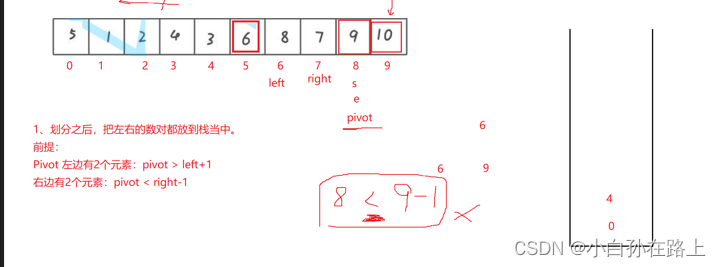
先找到基准,划分后分别把左右数对的下标开始结束放入栈里,
先出的就是右边的,
再从右边的开始找基准
找到后再把左边和右边的放入栈里
但是这个时候我们发现右边只有一个元素
就不需要放进栈里
所以我们可以判断好
我本来想可不可以用队列
发现不行因为你先放左右
然后左先出,再放进左的左和右,这个时候发现再第一段右的上面
还要等右判断完了再判断他的左和右
这块都乱了.

/**
* 快速排序非递归
* @param array
*/
public static void quickSort1(int[] array){
//初始化
int left=0;
int right=array.length-1;
Stack<Integer> stack=new Stack<>();
//找基准
int prvot=partition(array,left,right);
//把左右区间放入栈
if(prvot>left+1){
stack.push(left);
stack.push(prvot-1);
}
if(prvot<right-1){
stack.push(prvot+1);
stack.push(right);
}
while(!stack.isEmpty()){
right=stack.pop();
left=stack.pop();
prvot=partition(array,left,right);
//把左右区间放入栈
if(prvot>left+1){
stack.push(left);
stack.push(prvot-1);
}
if(prvot<right-1){
stack.push(prvot+1);
stack.push(right);
}
}
}前面的不能放到循环里,因为要找基准后吧`
5.总结
- 在待排序区间选择一个基准值
- 选择左边或者右边
- 随机选取
- 几数取中法
- 做 partition,使得小的数在左,大的数在右
- hoare
- 挖坑
- 前后遍历
- 将基准值相等的也选择出来(了解)
- 分治处理左右两个小区间,直到小区间数目小于一个阈值,使用插入排序
二,归并排序
1.原理
原理:把两个有序数组合并成一个有序数组\
代码实现
public static int[] mergeArray(int[]array1,int[] array2){
int s1=0;
int e1=array1.length-1;
int s2=0;
int e2=array2.length-1;
int[] tmp=new int[e1+e2+2];
int k=0;
while(s1<=e1&&s2<=e2){
if(array1[s1]<array2[s2]){
tmp[k++]=array1[s1++];
}else{
tmp[k++]=array2[s2++];
}
}
while(s1<=e1){
tmp[k++]=array1[s1++];
}
while(s2<=e2){
tmp[k++]=array2[s2++];
}
return tmp;
}归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并
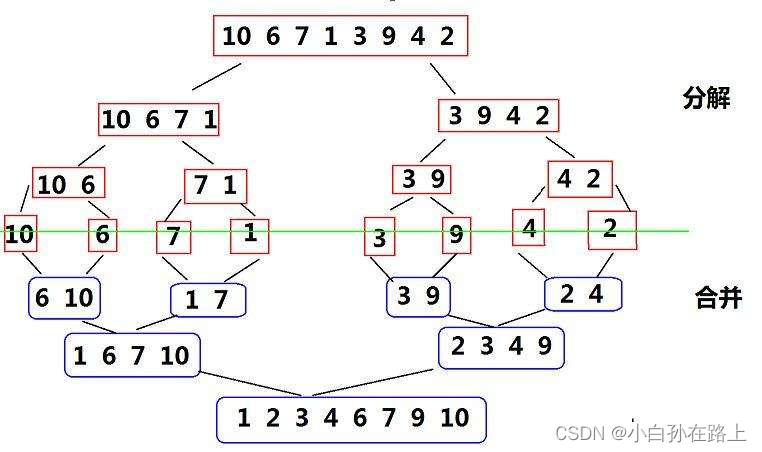
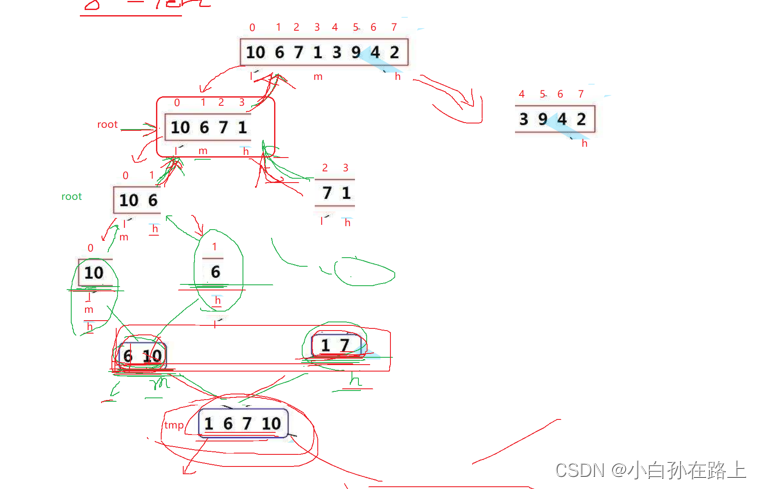
先一步一步递归直到l与h相遇,
也就是只剩下一个元素的情况
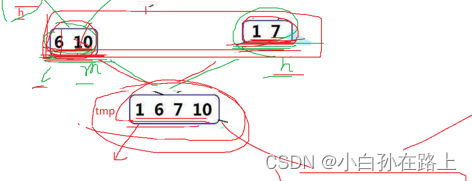
比如要合并1670 这两组,就要在4个一组的时候找到对应的下标

注意要对应上原数组的下标,而不是这次递归的开始
2.代码实现
public static void mergeSort(int[] array){
mergeSortInternal(array,0,array.length-1);
}
public static void mergeSortInternal(int [] array,int low,int high){
//递归终止条件
if(low>=high) return;
int mid=low+((high-low)>>>1);//加号 的优先级比较高
//递归左边的
mergeSortInternal(array,low,mid);
//递归右边的
mergeSortInternal(array,mid+1,high);
//走到这就需要合并 所合并的参数应该是上次递归的
merge(array,low,mid,high);
}
/**
* g归并
*/
private static void merge(int[] array,int low,int mid,int high){
int s1=low;
int e1=mid;
int s2=mid+1;
int e2=high;
int[] tmp=new int[high-low+1];
int k=0;
while(s1<=e1&&s2<=e2){
if(array[s1]<=array[s2]){
tmp[k++]=array[s1++];
}else{
tmp[k++]=array[s2++];
}
}
while(s1<=e1){
tmp[k++]=array[s1++];
}
while(s2<=e2){
tmp[k++]=array[s2++];
}
//还要把tmp拷贝到原来的数组
for (int i = 0; i < k; i++) {
array[i+low]=tmp[i];
}
}3.分析
时间复杂度:一直递归每个数据都要递归到树的高度那么多,所以就是n*logn
空间复杂度就是额外开一个tmp数组所以就是o(n)

并且是一个稳定的排序
/**
* 归并排序:
* 时间复杂度:O(N*logN)
* 空间复杂度:O(N)
* 稳定性:稳定的排序
* 如果 array[s1] <= array[s2] 不取等号 那么就是不稳定的排序
*
* 学过的排序 只有3个是稳定的:
* 冒泡 插入 归并
* @param array
*/4.非递归
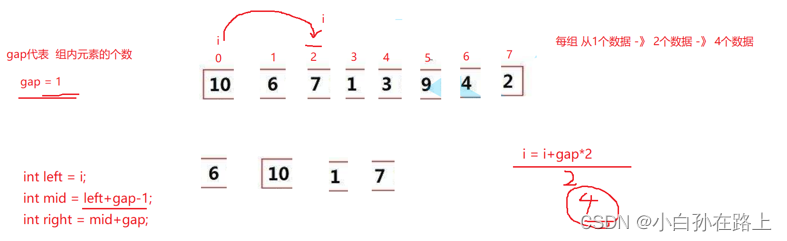
先定义一个gap每组从1个元素开始然后加倍
当每组一个时候.
找到相邻两个数据段的下标
进行归并
然后再往前走找下两个数据段
直到遍历完
再让gap加倍
继续进行循环
直到gap等于数组长度或者大于/
/**
* 非递归实现归并排序
*/
public static void mergeSort1(int[] arr){
int gap=1;//每组的数据个数
while(gap<arr.length){//gap在数组一半长度时候已经完成了两个数据段的合并,所以到等于的时候早就合并完了
//数组每次都要遍历,确定要归并的区间
for (int i = 0; i < arr.length; i+=gap*2) {
int left=i;
int mid=i+gap-1;
//防止越界
if(mid>= arr.length){
mid=arr.length-1;
}
int right=mid+gap;
//防止越界
if(right>=arr.length){
right=arr.length-1;
}
//小标确立后,进行合并
merge(arr,left,mid,right);
}
gap*=2;
}
}5.海量数据的排序问题
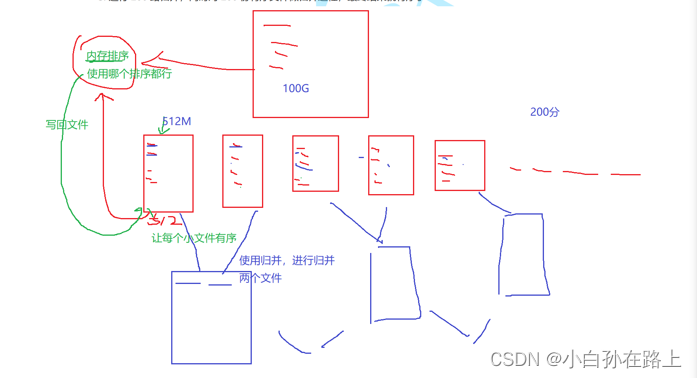
外部排序:排序过程需要在磁盘等外部存储进行的排序
前提:内存只有 1G,需要排序的数据有 100G
因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序
- 先把文件切分成 200 份,每个 512 M
- 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以
- 进行 200 路归并,同时对 200 份有序文件做归并过程,最终结果就有序了
外部排序就是在磁盘上排序,
内部排序就是在内存上排序
三.排序总结
四.非比较的排序
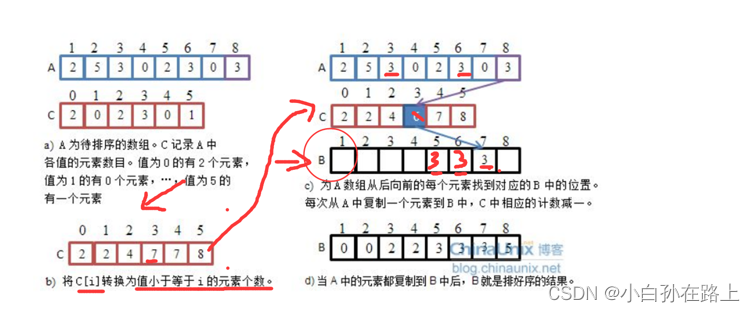
1.基数排序
![]()
因为是十进制的,构成0-9的十个队列
把一组数据从个位数到最高位分别进行排序
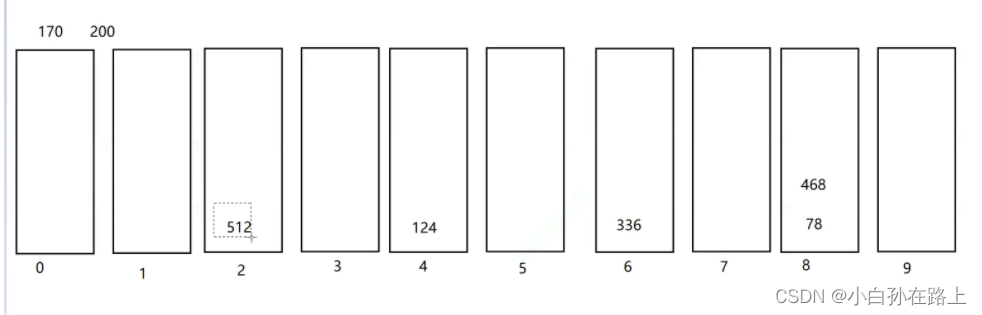
先尾插进,头出
个位
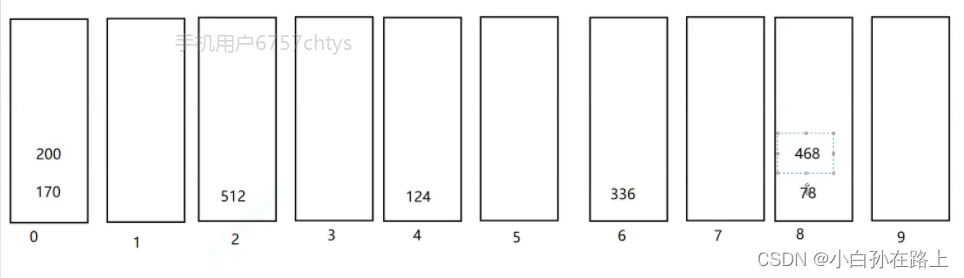
然后在从0-9按照顺序头出来
![]()
可以发现个位已经有序
在来排序十位数
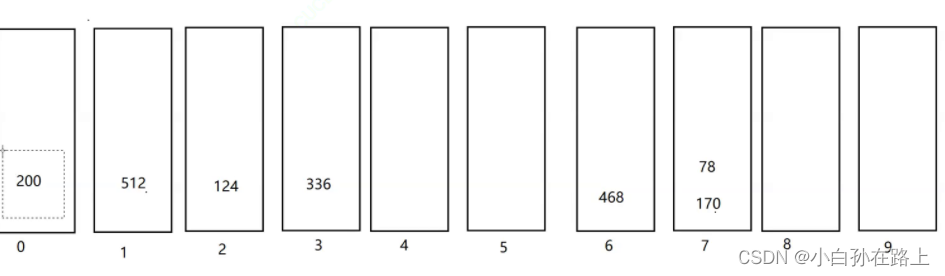
再分别拿出来

再排序百位数
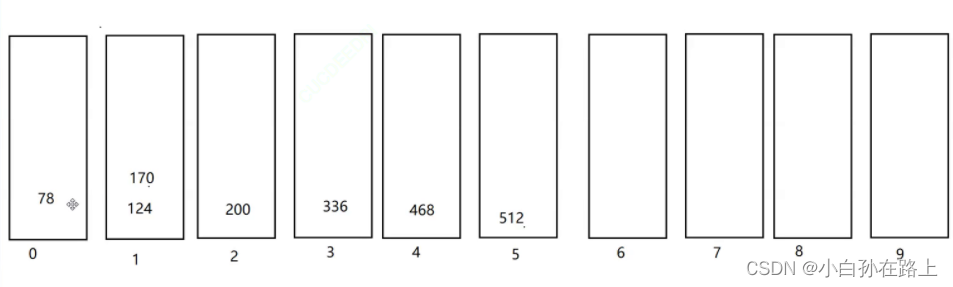
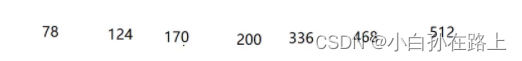
1.10 基数排序 | 菜鸟教程 (runoob.com)
2.桶排序

桶排序(最快最简单的排序) - 知乎 (zhihu.com)
3.计数排序
1.原理
定义一个计数数组.找数组每个元素出现的次数,然后遍历计数数组.从头开始,
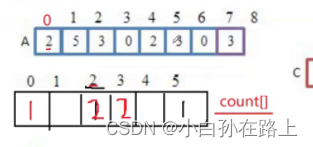
但是有疑问?


计数数组建立好后
把技术数组的数据覆盖到原数组
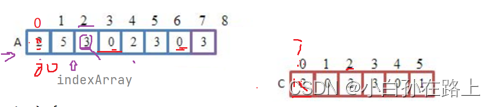
就先遍历计数数组
把不是0的数据进行循环
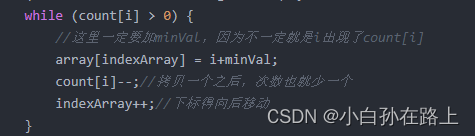
这里就需要定义一个index
因为很有可能一个数据出现好几次
循环一次,index就往后一位
直到计数数组对应的值为0
那我们如果放进去原数组的值呢
其实很简单就是计数数组的下标
但是如果是900-926各元素
我们防止内存冗余 就减去了900存放
那么我们遍历计数数组放元素的时候也需要加上900也就是minval.
2.代码
public static void countingSort(int[] array) {
int maxVal = array[0];
int minVal = array[0];
for (int i = 1; i < array.length; i++) {
if(array[i] < minVal) {
minVal = array[i];
}
if(array[i] > maxVal) {
maxVal = array[i];
}
}
//说明,已经找到了最大值和最小值
int[] count = new int[maxVal-minVal+1];//默认都是0
//统计array数组当中,每个数据出现的次数
for (int i = 0; i < array.length; i++) {
int index = array[i];
//为了空间的合理使用 这里需要index-minVal 防止923-900
count[index-minVal]++;
}
//说明,在计数数组当中,已经把array数组当中,每个数据出现的次数已经统计好了
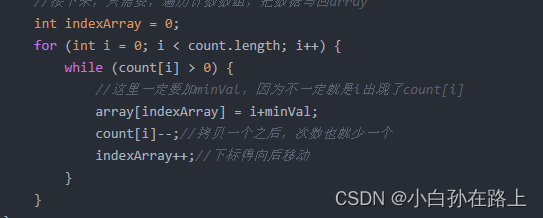
//接下来,只需要,遍历计数数组,把数据写回array
int indexArray = 0;
for (int i = 0; i < count.length; i++) {
while (count[i] > 0) {
//这里一定要加minVal,因为不一定就是i出现了count[i]
array[indexArray] = i+minVal;
count[i]--;//拷贝一个之后,次数也就少一个
indexArray++;//下标得向后移动
}
}
}3.分析
/**
* 计数排序
*/
/**
* 计数排序:
* 时间复杂度:O(N)
* 空间复杂度:O(M) M:代表 当前数据的范围900 - 999
* 稳定性:当前代码是不稳定的,但是本质是稳定的
*
* 一般适用于 有n个数,数据范围是0-n之间的
* @param array
*/







![[附源码]计算机毕业设计JAVA宿舍管理系统](https://img-blog.csdnimg.cn/28a9a94aa6264c65a954ee476ffbaecd.png)