Innodb如何实现表--上篇
- 数据是如何被管理起来的
- 表空间
- 段
- 区
- 页
- 行
- 行记录格式
- Compact记录行格式
- Redundant行记录格式
- 行溢出数据
- Compressed和Dynamic行记录格式
- Char的行存储结构
- 小结
数据是如何被管理起来的
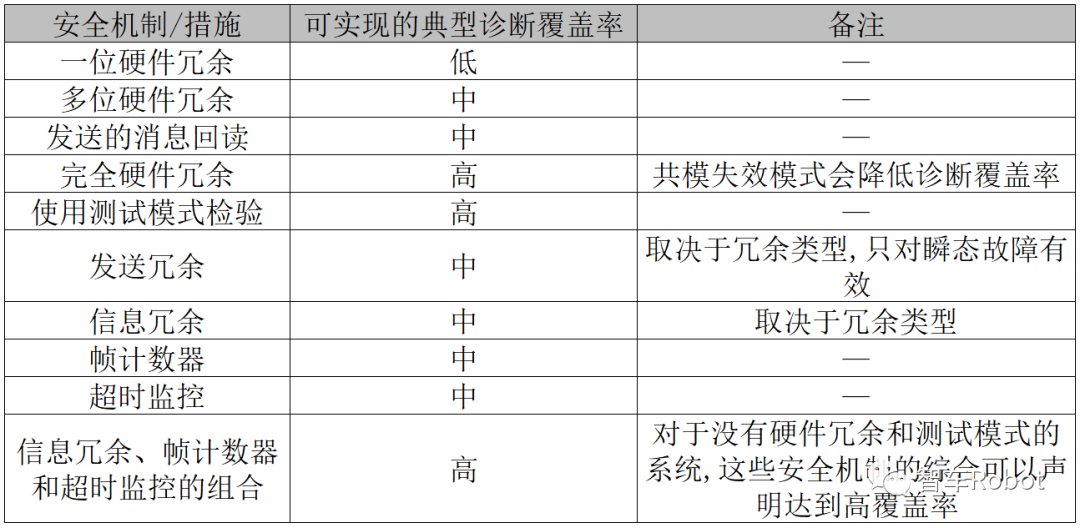
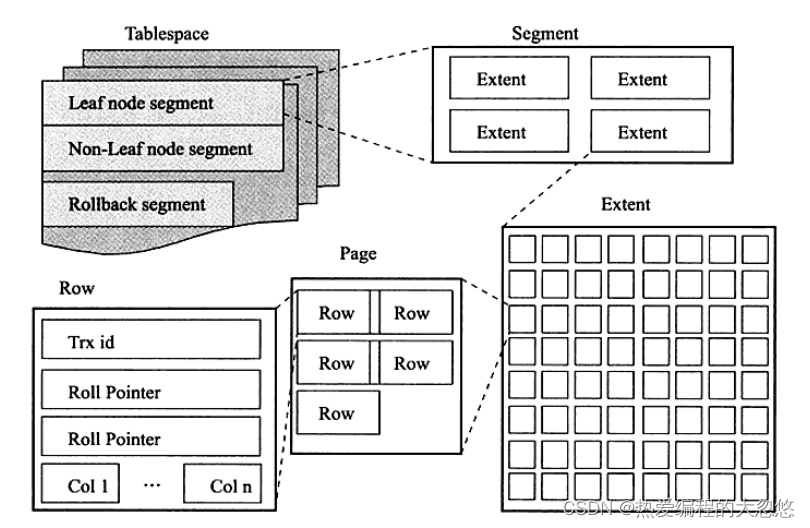
从InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block),InnoDB存储引擎的逻辑存储结构大致如下:
图一
表空间
在默认情况下InnoDB存储引擎有一个共享表空间 ibdatal,即所有数据都存放在这个表空间内。如果用户启用了参数 innodb_file_per_table,则每张表内的数据可以单独放到一个表空间内。
如果启用了innodb_file_per_table的参数,需要注意的是每张表的表空间内存放的只是数据、索引和插入缓冲Bitmap页,其他类的数据,如回滚(undo)信息,插入缓冲索引页、系统事务信息,二次写缓冲(Double write buffer)等还是存放在原来的共享表空间内。这同时也说明了另一个问题:即使在启用了参数innodb_file_per_table之后,共享表空间还是会不断地增加其大小。
注意: 共享表空间虽然存放了回滚日志,但是不会在相关回滚日志被回收后,而使得共享表空间主动回收这些空闲空间,而是会标记这些空间为可用空间,供下次undo使用。
段
表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。InnoDB存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为B+树的叶子节点(图一的 Leaf node segment),索引段即为B+树的非索引节点(图一的Non-leaf node segment)。回滚段较为特殊,将会在后面进行单独介绍。
在InnoDB存储引擎中,对段的管理都是由引擎自身所完成,DBA不能也没有必要对其进行控制。这和Oracle数据库中的自动段空间管理(ASSM)类似,从一定程度上简化了DBA对于段的管理。
区
区是由连续页组成的空间,在任何情况下每个区的大小都为1MB。为了保证区中页的连续性,InnoDB存储引擎一次从磁盘申请4~5个区。在默认情况下,InnoDB存储引擎页的大小为16KB,即一个区中一共有64个连续的页。
InnoDB 1.0.x版本开始引入压缩页,即每个页的大小可以通过参数KEY_BLOCK_SIZE设置为2K、4K、8K,因此每个区对应页的数量就应该为512、256、128。
InnoDB 1.2.x版本新增了参数 innodb_page_size,通过该参数可以将默认页的大小设置为4K、8K,但是页中的数据库不是压缩。这时区中页的数量同样也为256、128。总之,不论页的大小怎么变化,区的大小总是为1M。
但是,这里还有这样一个问题:在用户启用了参数 innodb_file_per_talbe后,创建的表默认大小是96KB。区中是64个连续的页,创建的表的大小至少是1MB才对啊?其实这是因为在每个段开始时,先用32个页大小的碎片页(fragment page)来存放数据,在使用完这些页之后才是64个连续页的申请。这样做的目的是,对于一些小表,或者是undo这类的段,可以在开始时申请较少的空间,节省磁盘容量的开销。
页
同大多数数据库一样,InnoDB有页(Page)的概念(也可以称为块),页是InnoDB磁盘管理的最小单位。在InnoDB存储引擎中,默认每个页的大小为16KB。
而从InnoDB 1.2.x版本开始,可以通过参数innodb_page_size将页的大小设置为4K、8K、 16K。若设置完成,则所有表中页的大小都为innodb_page_size,不可以对其再次进行修改。除非通过 mysqldump导入和导出操作来产生新的库。
在InnoDB存储引擎中,常见的页类型有:
- 数据页(B-tree Node)
- undo 页(undo Log Page)
- 系统页(System Page)
- 事务数据页(Transaction system Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(compressed BLOB Page)
行
InnoDB存储引擎是面向列的(row—oriented),也就说数据是按行进行存放的。每个页存放的行记录也是有硬性定义的,最多允许存放16KB/2—200行的记录,即7992行记录。这里提到了row-oriented的数据库,也就是说,存在有column-oriented的数据库。 MySQL infobright存储引擎就是按列来存放数据的,这对于数据仓库下的分析类SQL语句的执行及数据压缩非常有帮助。类似的数据库还有 Sybase IQ、Google Big Table。
面向列的数据库基本概念建议各位阅读数据密集型应用一书的如下章节进行学习:
行记录格式
InnoDB存储引擎和大多数数据库一样(如Oracle和Microsoft SQL Server数据库), 记录是以行的形式存储的。这意味着页中保存着表中一行行的数据。
在InnoDB 1.0.x版本之前,InnoDB存储引擎提供了Compact和 Redundant两种格式来存放行记录数据,这也是目前使用最多的一种格式。
Redundant格式是为兼容之前版本而保留的,如果阅读过InnoDB的源代码,用户会发现源代码中是用PHYSICAL RECORD(NEW STYLE) 和PHYSICAL RECORD(OLD STYLE)来区分两种格式的。
在MySQL 5.1版本中,默认设置为Compact行格式。用户可以通过命令 SHOW TABLE STATUS LIKE 'table_ name'来查看当前表使用的行格式,其中row_format属性表示当前所使用的行记录结构类型。如:
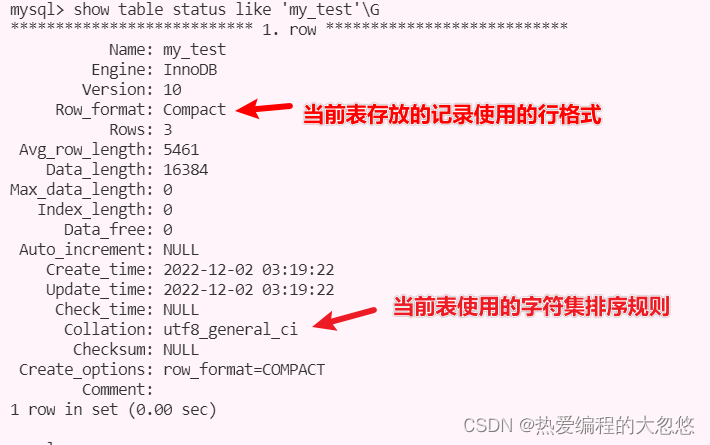
Compact记录行格式
Compact行记录格式是在MySQL 5.0引入的,其设计的目的是搞笑存储数据,简单来说,一个页中存放的行数据越多,性能就越高。

从上图可以观察到,Compact行记录格式的首部是一个变长字段长度列表,并且其是按照列的顺序逆序放置的,其长度为:
- 若列的长度小于255字节,用1字节表示;
- 若大于255个字节,用2字节表示。
变长字段的长度最大不可以超过2字节,这是因在MySQL数据库中 VARCHAR类型的最大长度限制为65535。
第二个部分是NULL位图,该位图每个二进制位对应一列,如果该位为1,则表示该列为NULL,该部分所占的字节应该为1字节(如果不够,就继续加)。
接下来的部分是记录头信息(record header),固定占用5字节(40位),每位的含义如下:
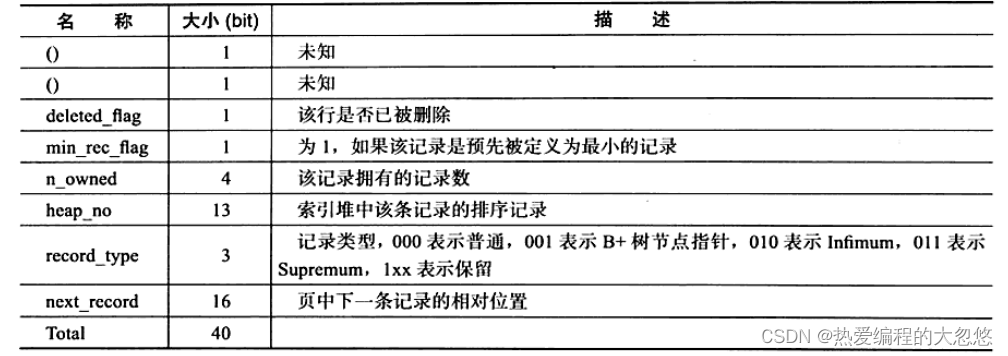
最后的部分就是实际存储每个列的数据。需要特别注意的是,NULL不占该部分任何空间,即NULL除了占有NULL标志位,实际存储不占有任何空间。
另外有一点需要注意的是,每行数据除了用户定义的列外,还有两个隐藏列,事务ID列和回滚指针列,分别为6字节和7字节的大小。若InnoDB表没有定义主键,每行还会增加一个6字节的rowid列。
这里我们通过一个具体案例来分析一下:
DROP TABLE IF EXISTS `my_test`;
CREATE TABLE `my_test` (
`t1` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci,
`t2` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci,
`t3` char(10) CHARACTER SET utf8 COLLATE utf8_general_ci,
`t4` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci
) ENGINE = InnoDB AUTO_INCREMENT = 0 CHARACTER SET = 'utf8' COLLATE = 'utf8_general_ci' ROW_FORMAT = compact;
INSERT into my_test values('a','bb','bb','cccc');
INSERT into my_test values('d','ee','ee','fff');
INSERT into my_test values('d',NULL,NULL,'fff');
SELECT * FROM `my_test`;
随后,我们定位到对应表my_test所在的索引文件my_test.ibd:

通过hexdump -c my_test.ibd命令以十六进制+ASCII显示的方式查看idb二进制文件:
linux提供的hexdump命令,感兴趣可以自己去了解一下,主要是用来查看各类文件的
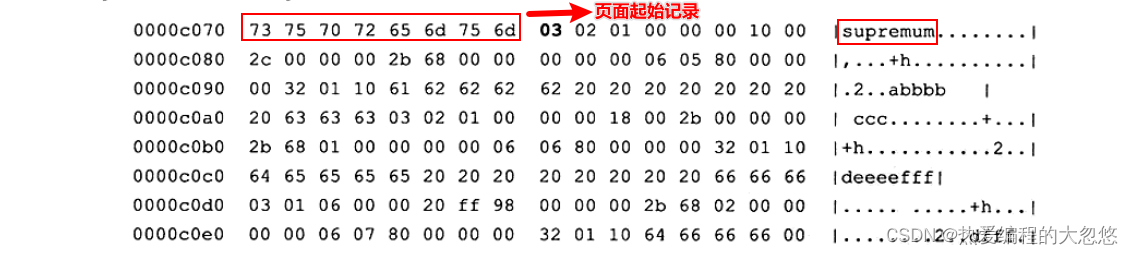
该行记录从0000c078开始:


现在第一行数据就展现在用户眼前了。需要注意的是,变长字段长度列表是逆序存放的,因此变长字段长度列表为030201,而不是010203。此外还需要注意InnoDB每行有隐藏列 TransactionID和Roll Pointer。同时可以发现,固定长度CHAR字段在未能 完全占用其长度空间时,会用0x20来进行填充。
接着再来分析下 Record Header的最后两个字节,这两个字节代表 next_recorder, 0x2c代表下一个记录的偏移量,即当前记录的位置加上偏移量0x2c就是下条记录的起始位置。所以InnoDB存储引擎在页内部是通过一种链表的结构来串连各个行记录的。
最后,我们再来看看存在NULL值的第三行是如何存储的:

第三行有NULL值,因此NULL标志位不再是00而是06,转换成二进制为00000110,为1的值代表第2列和第3列的数据为NULL。在其后存储列数据的部分,用户会发现没有存储NULL列,而只存储了第1列和第4列非NULL的值。因此这个例子很好地说明了:不管是CHAR类型还是VARCHAR类型,在compact格式下NULL 值都不占用任何存储空间。
Redundant行记录格式
Redundant是MySQL 5.0版本之前InnoDB的行记录存储方式,MySQL5.0支持 Redundant是为了兼容之前版本的页格式。Redundant行记录采用如图所示的方式存储。

从上图可以看到,不同于Compact行记录格式,Redundant行记录格式的首部是一个字段长度偏移列表,同样是按照列的顺序逆序放置的。若列的长度小于255字节,用1字节表示;若大于255字节,用2字节表示。
第二个部分为记录头信息(recordheader),不同于Compact行记录格式,Redundant行记录格式的记录头占用6字节(48 位),每位的含义如下:
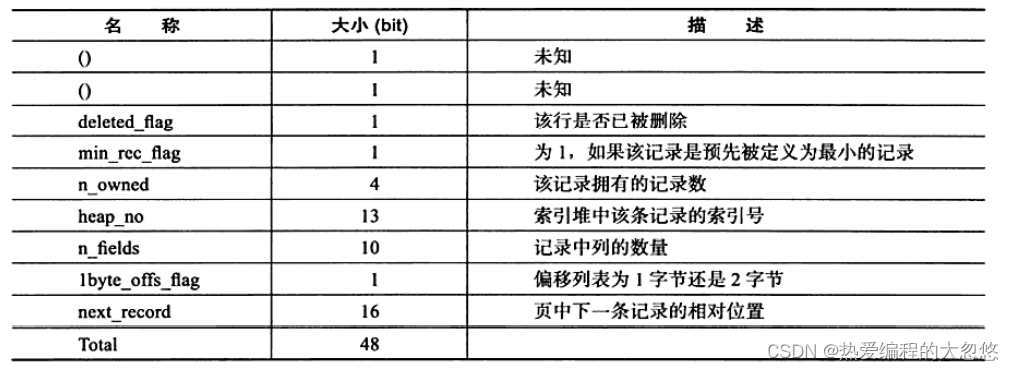
从上图中可以发现,n_fields值代表一行中列的数量,占用10位。同时这也很好地解释了为什么MySQL数据库一行支持最多的列为1023。另一个需要注意的值为1byte_offs_flags,该值定义了偏移列表占用1字节还是2字节。而最后的部分就是实际存储的每个列的数据了。
这里我们还是通过一个具体案例来分析一下:
create TABLE my_test2 engine=INNODB ROW_FORMAT=Redundant as SELECT * FROM my_test;
my_test2表 copy了my_test表,但是记录的存储格式改为了Redundant类型,我们还是通过hexdump来查看my_test2.ibd文件:

23 20 16 14 13 0c 06逆转为06,0c,13,14,16,20,23,分别代表第一列长度6,第二列长度6(6+6=0x0C),第三列长度为7(6+6+7=0x13),第四列长度1 (6+6+7+1=0x14)第五列长度2(6+6+7+1+2=0x16),第六列长度10(6+6+7+1+2+10=0x20),第七列长度3 (6+6+7+1+2+10+3=0x23)。
在接下来的记录头信息(Record Header)中应该注意48位中的第22~32位,为0000000111,表示表共有7个列(包含了隐藏的3列),接下来的第33位为1,代表偏移列表为一个字节。
后面的信息就是实际每行存放的数据了,这同Redundant行记录格式大致相同,注意是大致相同,因为如果分析第三行,会发现对于NULL值的处理两者是非常不同的:

这里与之前Compact行记录格式有着很大的不同了,首先来看长度偏移列表,逆序排列后得到06 0c 13 14 94 9e 21,前4个值都很好理解,第5个NULL值变为了94,接着第6个CHAR类型的NULL值为9e(94+10=0x9e),之后的21代表 (14+3=0x21), 可以看到对于VARCHAR类型的NULL值,Redundant行记录格式同样不占用任何存储空间,而CHAR类型的NULL值需要占用空间。
当前表mytest2的字符集为Latinl,每个字符最多只占用1字节。若用户将表mytest2的字符集转换为utf8,第三列CHAR固定长度类型不再是只占用10字节了,而是10x3=30字节。所以在Redundant行记录格式下,CHAR类型将会占用可能存放的最大值字节数。有兴趣的读者可以自行尝试。
行溢出数据
InnoDB存储引擎表是索引组织的,即B+Tree的结构,这样每个页中至少应该有两条行记录(否则失去了B+Tree的意义,变成链表了)。因此,如果页中只能存放下一条记录,那么InnoDB存储引擎会自动将行数据存放到溢出页中。
常见的如Varchar,Blob,Text等数据类型都有可能会导致上述溢出现象产生,那么具体情况如何,下面通过例子进行说明。
首先对VARCHAR数据类型进行研究。很多DBA喜欢MySQL数据库提供的VARCHAR类型,因为相对于Oracle VARCHAR2最大存放4000字节,SQL Server最大存放8000字节,MySQL数据库的VARCHAR类型可以存放65535字节。但是,这是真的吗?真的可以存放65535字节吗?如果创建VARCHAR长度为65535的表,用户会得到下面的错误信息:

从错误消息可以看到InnoDB存储引擎并不支持65535长度的VARCHAR。这是因为还有别的开销,通过实际测试发现能存放VARCHAR类型的最大长度为65532。例如,按下面的命令创建表就不会报错了。

注意: 如果没有将SQL_MODE设置为严格模式,在将varchar最大长度设置为65535时是可以创建表的,但是MySQL数据库会抛出一个warning警告。

waring信息提示这次可以创建是因为MySQL数据库自动地将VARCHAR类型转换为了TEXT类型,此时查看test的表结构会发现:

还需要注意上述创建的VARCHAR长度为65532的表,其字符类型是latinl的,如果换成GBK又或UTF—8的,会产生怎样的结果呢?
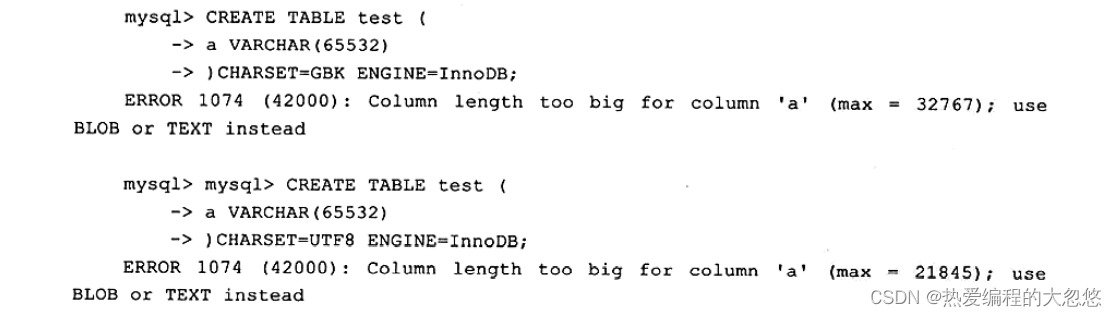
这次即使创建列的VARCHAR长度为65532,也会提示报错,但是两次报错对max值的提示是不同的。因此从这个例子中用户也应该理解VARCHAR(N)中的N指的是字符的长度。而文档中说明VARCHAR类型最大支持65535,单位是字节。
并且MySQL官方手册中定义的65535长度是指所有VARCHAR列的长度总和,如果列的长度总和超过这个长度,依然无法创建:

3个列长度总和是66000,因此InnoDB存储引擎再次报了同样的错误。即使能存放65532个字节,但是有没有想过,InnoDB存储引擎的页为16KB,即16384字节,怎么能存放65532字节呢?因此,在一般情况下,InnoDB存储引擎的数据都是存放在页类型为B-tree node中。但是当发生行溢出时,数据存放在页类型为Uncompress BLOB页 中。来看下面一个例子:
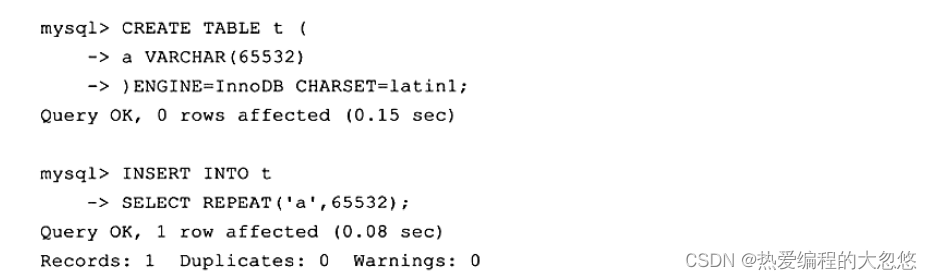
在上述例子中,首先创建了一个列a长度为65532的VARCHAR类型表t,然后插入了列a长度为65532的记录,接着通过工具py_innodb_page_info看表空间文件,可以看到的页类型有:
yum install python3
git clone https://github.com/lynnlz/py_innodb_page_info
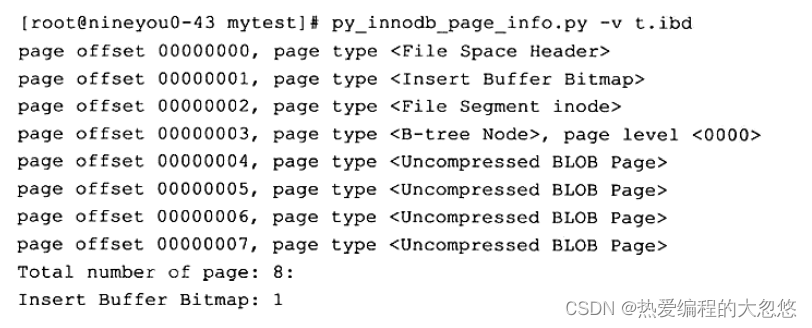
通过工具可以观察到表空间中有一个数据页节点B-tree Node,另外有4个未压缩的二进制大对象页Uncompressed BLOB Page,在这些页中才真正存放了65532字节的数据。既然实际存放的数据都在BLOB页中,那数据页中又存放了些什么内容呢?同样通过之前的hexdump来读取表空间文件,从数据页c000开始查看:

可以看到,从0x0000c093 到0x0000c392数据页面其实只保存了VARCHAR (65532)的前768字节的前缀(prefix)数据(这里都是a),之后是偏移量,指向行溢出页,也就是前面用户看到的Uncompressed BLOB Page。因此,对于行溢出数据,其存放采用下图所示的方式:

行溢出数据小结:
Innodb要求一页最少给我存两条记录,如果塞入一条记录时,发现已经塞满了整个页,那么就将该记录大部分数据都存放到BLOB页保存。如果塞入第二条记录时,发现塞满了整个页,那么将第二条记录大部分数据都存放到BLOB页保存。
对于TEXT和BLOB数据类型,是放在数据页还是BLOB也中,这一点和前面讨论的VARCHAR类型一样,至少保证一个页给劳资塞入两条记录。
Compressed和Dynamic行记录格式
InnoDB 1.0.x版本开始引入了新的文件格式(file format,用户可以理解为新的页格式),以前支持的Compact和 Redundant 格式称为Antelope 文件格式,新的文件格式称为Barracuda 文件格式。Barracuda 文件格式下拥有两种新的行记录格式:Compressed和Dynamic。
新的两种记录格式对于存放在BLOB中的数据采用了完全的行溢出的方式,如下图所示,在数据页中只存放20个字节的指针,实际的数据都存放在Off Page中,而之前的 Compact 和 Redundant 两种格式会存放768个前缀字节。

Compressed行记录格式的另一个功能就是,存储在其中的行数据会以zlib的算法进行压缩,因此对于BLOB、TEXT、VARCHAR这类大长度类型的数据能够进行非常有效的存储。
Char的行存储结构
通常理解 VARCHAR是存储变长长度的字符类型,CHAR是存储固定长度的字符类型。而在前面的小节中,用户已经了解行结构的内部的存储,并可以发现每行的变长字段长度的列表都没有存储CHAR类型的长度。
然而,值得注意的是之前给出的两个例子中的字符集都是单字节的latinl格式。从MySQL 4.1版本开始,CHAR(N)中的N指的是字符的长度,而不是之前版本的字节长度。也就说在不同的字符集下,CHAR类型列内部存储的可能不是定长的数据。例如下面的这个示例:


上面例子中,表j的字符集是GBK,用户分别插入了两个字符的数据’ab’和’我们’,然后查看所占字节,可得如下结果:

我们再通过HEX函数查看内部的十六进制存储:


可以看到对于字符串'ab',其内部存储为0x6162。而字符串,我们'为0xCED2C3C7。因此对于多字节的字符编码,CHAR类型不再代表固定长度的字符串了。
例如,对于UTF-8下CHAR(10)类型的列,其最小可以存储10字节的字符,而最大可以存储30字节的字符。因此,对于多字节字符编码的CHAR数据类型的存储,InnoDB存储引擎在内部将其视为变长字符类型。这也就意味着在变长长度列表中会记录CHAR数据类型的长度。下面通过hexdump工具来查看表空间j.ibd文件:
我们还是通过hexdump命令来看到一些表空间j.ibd文件:

上述例子清楚地显示了InnoDB存储引擎内部对CHAR类型在多字节字符集类型的存储。CHAR类型被明确视为了变长字符类型,对于未能占满长度的字符还是填充0x20。
InnoDB 存储引擎内部对字符的存储和我们用HEX函数看到的也是一致的。因此可以认为在多字节字符集的情况下, CHAR和VARCHAR的实际行存储基本是没有区别的。
小结
本文简单介绍了表空间,段和区的概念,重点讲解了行是如何实现的。
下一篇文章,我们将重点转入页是如何实现的。
本文主要参考Innodb技术内幕第二版第4章整理而来。
![[附源码]计算机毕业设计JAVA宿舍管理系统](https://img-blog.csdnimg.cn/28a9a94aa6264c65a954ee476ffbaecd.png)






![[附源码]Python计算机毕业设计SSM久宠宠物店管理系统(程序+LW)](https://img-blog.csdnimg.cn/e67b5ba1c2834c95b0392984c65b9f53.png)