一把年纪了还是这么菜
1 Redis 是啥
Redis 是一个高性能的 Key-Value 数据库,key 的类型是字符串,value 的类型有:string 字符串类型、list 列表类型、set 集合类型、sortedset(zset) 有序集合类型、hash 类 型、bitmap 位图类型等。
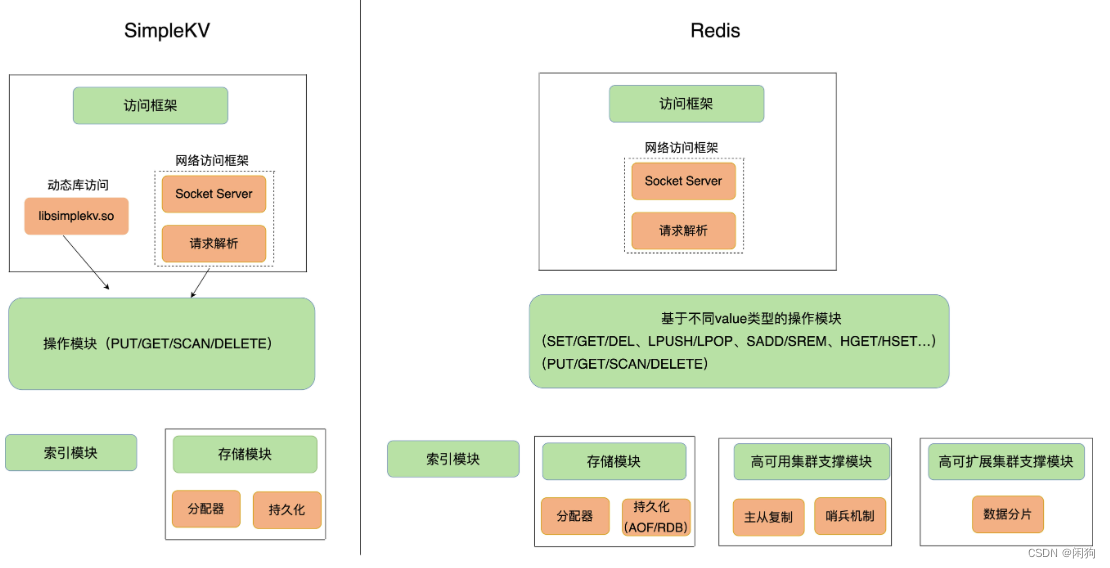 上图是普通键值数据库到 Redis 的演进,可以看出 Redis 的 Value 类型丰富,有 2 种持久化方式并且支持集群。
上图是普通键值数据库到 Redis 的演进,可以看出 Redis 的 Value 类型丰富,有 2 种持久化方式并且支持集群。
2 Redis 数据类型及应用场景
2.1 String 类型
Reids 的 String 能表达 3 种值的类型:字符串,整数和浮点数。
常见命令:
| 命令名称 | 命令格式 | 命令描述 |
| set | set key value | 赋值 |
| get | get key | 取值 |
| setnx | setnx key value | 当 key 不存在时才赋值,可用于实现分布式锁。 set key value NX PX 3000 原子操作,px 设置毫秒数 set age 28 NX PX 10000 不存在则赋值,有效期 10 秒 |
| incr | incr key | 递增数字,可用于实现乐观锁 |
| decr | decr key | 递减数字 |
应用场景
开发一个图片存储系统,要求这个系统能快速地记录图片 ID 和图片在存储系统中保存时的 ID。同时,还要能够根据图片 ID 快速查找到图片存储对象 ID。
因为图片数量巨大,所以我们就用 10 位数来表示图片 ID 和图片存储对象 ID,例如,图片 ID 为 1101000051,它在存储系统中对应的 ID 号是 3301000051。
set photo_id photo_obj_id
set 1101000051 3301000051问题来了,上述例子中保存 1 亿张图片的信息,用了约 6.4GB 的内存,一个图片 ID 和图片存储对象 ID 的记录平均用了 64 字节。而一组图片 ID 及其存储对象 ID 的记录,实际用两个 8 字节的 Long 类型就可以表示,因为 8 字节的 Long 类型最大可以表示 2 的 64 次方的数值。
但是,为什么 String 类型却用了 64 字节呢?其实,除了记录实际数据,String 类型还需要额外的内存空间记录数据长度、空间使用等信息,这些信息也叫作元数据。当实际保存的数据较小时,元数据的空间开销就显得比较大了。
2.2 列表
list 列表类型可以存储有序、可重复的元素。
常见命令:
| 命令名称 | 命令格式 | 命令描述 |
| lpush | lpush key v1 v2 v3 | 从左侧插入列表 |
| lpop | lpop key | 从左侧弹出 |
| rpush | rpush key v1 v2 v3 | 从右侧插入列表 |
| rpop | rpop key | 从右侧弹出 |
应用场景:
1、作为栈或队列使用
2、适用于展示最新列表、排行榜等场景,且数据不频繁更新且不用分页展示
如:每个商品对应一个 List,这个 List 包含了对这个商品的所有评论,而且会按照评论时间保存这些评论,每来一个新评论,就用 LPUSH 命令把它插入 List 的队头。
2.3 Set
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的不可重复的。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
常用命令:
| 命令名称 | 命令格式 | 命令描述 |
| sadd | sadd key mem1 mem2 .... | 为集合添加新成员 |
| spop | spop key | 返回集合中一个随机元素,并将该元素删除 |
| srandmember | srandmember key | 返回集合中一个随机元素,不会删除该元素 |
| sinter | sinter key1 key2 key3 | 求多集合的交集 |
| sdiff | sdiff key1 key2 key3 | 求多集合的差集 |
| sunion | sunion key1 key2 key3 | 求多集合的并集 |
应用场景:
1 关注的用户,通过 spop 进行随机抽奖
2.4 Sorted Set
元素有序不可重复
常见命令
| 命令名称 | 命令格式 | 命令描述 |
| zadd | zadd key score1 member1 score2 member2 ... | 为有序集合添加新成员 |
| zcount | zcount key min max | 返回集合中score值在[min,max]区间 的元素数量 |
| zrank | zrank key member | 获得集合中member的排名(按分值从 小到大) |
| zrange | zrange key start end | 获得集合中指定区间成员,按分数递增排序 |
| zrevrange | zrevrange key start end | 获得集合中指定区间成员,按分数递减排序 |
应用场景:
1 点击排行榜、销量排行榜、关注排行榜等
2 多维排序
需求 1:
假设有5个app的下载量和最后更新时间分别如下:
wechat-下载量:12,最后更新时间:1;其score为:12.1
qq-下载量:12,最后更新时间:2;其score为:12.2
tiktok-下载量:10,最后更新时间:3;其score为:10.3
taobao-下载量:11,最后更新时间:5;其score为:11.5
alipay-下载量:11,最后更新时间:4;其score为:11.4
将上述数据存到redis,参照命令:zadd key score1 member1 score2 member2 ...
zadd TopApp 12000000.1564022201 wechat 12000000.1564022222 qq 9808900.1563552267 tiktok 11006600.1564345601 taobao 11006600.1564345600 alipay
排序
127.0.0.1:6379> zrevrange TopApp 0 -1 1) "qq" (12.2) 2) "wechat" (12.1) 3) "taobao" (11.5) 4) "alipay" (11.4) 5) "tiktok" (10.3)
如果有三维排序,四维排序呢?可以自定义得分权重计算公式 ,这个公式包含所有影响排序的因子,例如:downloadCount*1000 + updatedTime
2.5 Hash
例子1:采用 Hash 存储下表的数据

参考命令
1)hmset key field1 value1 field2 value2 同时将多个 field-value (域-值)对设置到哈希表 key 中
2)hmget key field1 field2 获取所有给定字段的值
实际指令
1)hmset user 1:name wyd 1:balance 1888 2:name hk 2:balance 110 3:name dd 3:balance 800
2)hmget user 1:name 1:balance
缺点:
上述例子 key 都为 user,经过哈希都会定位到同一个 redis 节点,整个表的数据都存在一个 redis 节点,redis 分布式集群存储就发挥不了作用。
例子 2

key = 用户id field = 商品id value = 商品数量
参考指令
1)hset key field value
2)hincrby key field increment:为哈希表 key 中的指定字段的整数值加上增量 increment
3) hlen key:获取哈希表中字段的数量
4)hdel key field1 field2:删除一个或多个哈希字段
5)hgetall key:获取指定 key 的所有字段和值
购物车操作
1)添加商品 hset cart:{用户id} {商品id} 1
2)增加数量 hincrby cart:{用户id} {商品id} 1
3)商品总数 hlen cart:{用户id}
4)删除商品 hdel cart:{用户id} {商品id}
5)获取购物车所有商品 hgetall cart:{用户id}
2.6 bitmap 位图类型
bitmap是进行位操作的,通过一个 bit 位来表示某个元素对应的值或者状态,其中的 key 就是对应元素本身。 bitmap本身会极大的节省储存空间。
常用命令:
| 命令名称 | 命令格式 | 命令描述 |
| setbit | setbit key offset value | 设置key在offset处的bit值(只能是0或者1) |
| bitcount | bitcount key | 获得key的bit位为1的个数 |
| getbit | getbit key offset | 获得key在offset处的bit值 |
应用场景:
1、用户每月签到,用户id为key , 日期作为偏移量 1表示签到
2、统计活跃用户, 日期为key,用户id为偏移量 1表示活跃
3、查询用户在线状态, 日期为key,用户id为偏移量 1表示在线
1)setbit user:sign:1000 20200101 1 #id为1000的用户20200101签到
2)bitcount user:sign:1000 #获取id为1000的用户的签到次数



![[附源码]Python计算机毕业设计SSM久宠宠物店管理系统(程序+LW)](https://img-blog.csdnimg.cn/e67b5ba1c2834c95b0392984c65b9f53.png)