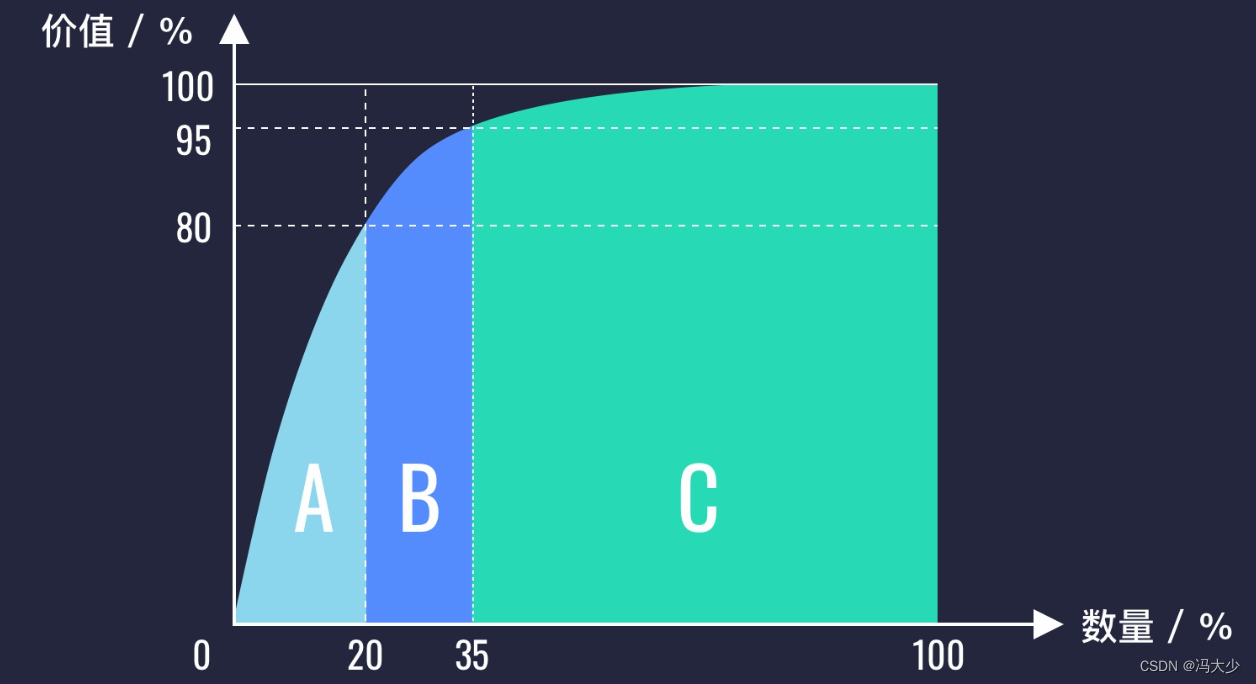
在任何特定群体中,重要的因子通常只占少数,而不重要的因子则占多数,因此只要能控制具有重要性的少数因子即能控制全局。例如,在企业中,通常认为它80%的利润来自于20%的项目或重要客户;全球最富有的 20% 人口,掌握着全世界 80% 以上的收入。简单理解这个法则重要的原则是避免将时间花在琐碎的多数问题上,因为就算你花了80%的时间,你也只能取得20%的成效:你应该将时间花于重要的少数问题上,因为掌握了这些重要的少数问题,你只花20%的时间,即可取得80%的成效。这一规律被称为帕累托法则,其分析方法称之为帕累托分析法,也称之为 ABC法则(分析法)或者 2/8 法则(分析法)。
在电商领域,我们可以根据 ABC 分析法将商品按 售卖比 的高低分为 A、B、C 三类,进而针对每一类商品制定不同的营销策略。结合本关需求,我们可以在 A 类中挑选出 净销售额 高的商品,作为下一季的主推商品;从 C 类中挑出 高库存 的商品,进行清仓促销。
主要有以下3个核心指标:
1.售卖比:用于将商品划分为三类,售卖比前 20% 的商品为 A 类,20%~35% 为 B 类,其余为 C 类;
2.净销售额:用于从 A 类商品中筛选出主推商品;
3.库存:用于从 C 类商品中筛选出适合清仓商品。
售卖比,又称 售罄率, 指的是售出商品数量占备货总量的比值,可以衡量一件商品卖得好不好。计算方式为:售卖比 = 销量 / 备货量 = (备货量 - 库存量) / 备货量 这个指标也符合我们日常生活的经验,如果一个商品一经上架就全部售罄,就说明它供不应求,我们该增加库存。每件商品的备货量,都记录在了数据表 items 里,共有6 列信息。
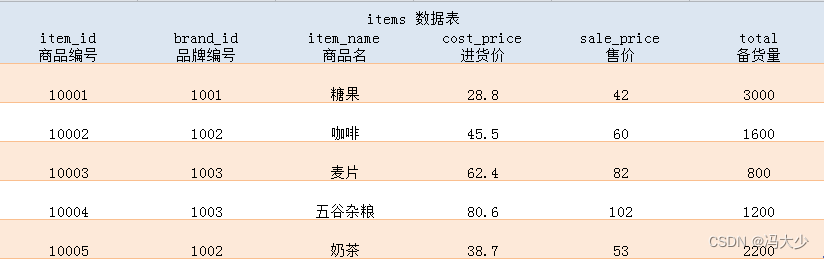
另外 通过 user_behavior 表和订单中心数据,统计出了每件商品在浏览量、收藏数等维度上的数据表现,记录在了 item_data 数据表里,由 6 列组成:
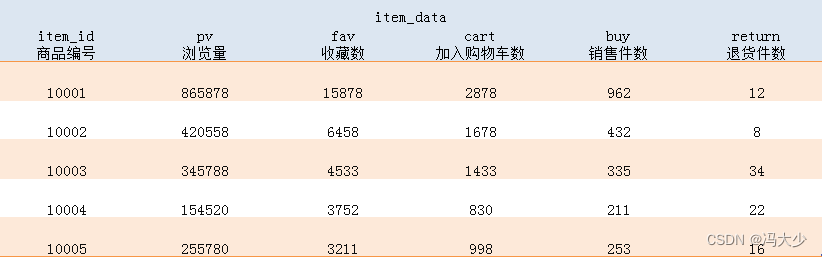
从以上两张数据表,还可以计算出 净销售额,它的计算方法为:销售额 - 退货金额。由于电商平台的平均退货率是远远高于实体店铺的退货率的,用户只有在收到商品时,才能确认商品运输情况是否良好、其样式或功能是否与描述一致。因此 净销售额 更能体现一件商品是否真正受用户的肯定。
找出主推、清仓商品后,我们不仅要提供检索的依据,也就是上面三个指标,还要提供商品的品牌信息便于后续的检索统计,它记录在 brands 数据表中。

如果用子查询来处理跨多表的查询,最后写成的 SQL 语句将十分繁琐。如果把与商品有关的信息全部整合在一张数据表里,看起来是可行的。但假如品牌 “奇趣趣“ 改名为 “乐趣趣“, 对于已经录入的商品,需要筛选出所有属于 “奇趣趣“ 的,修改为 “乐趣趣“;很难保证所有人此后都正确输入 “乐趣趣“ 的品牌名,很可能需要定期复查。 此外,同一品牌下的所有商品,其品牌信息都是相同的。目前我们每个品牌只记录了品牌 ID 和品牌名两个信息,如果再加上联系方式、地址等个人信息,此时对每个商品都添加这些重复信息,既浪费人力,又浪费计算机的存储空间。而如果将商品属性、数据表现、品牌信息区分开,分别记录在 items、item_data 和 brands 三张数据表中,表与表之间通过 item_id 与 brand_id 相互关联起来:
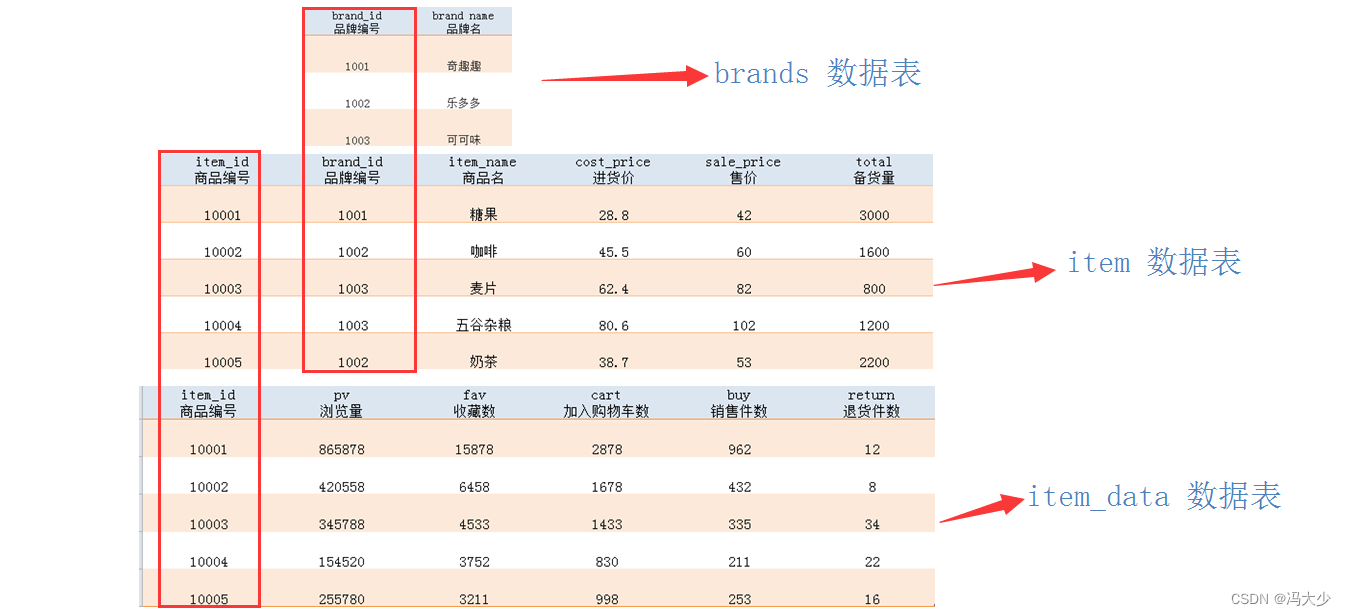
有了这关联表的关系,除了 item_id 与 brand_id 作为商品、品牌的标识会重复出现,几乎没有信息的重复。如果“奇趣趣“ 改名为 “乐趣趣“,也只需要在 brands 数据表中更改一行记录,其它的数据表不需要变动,也不用担心录入时发生差错。把不同类别的信息分解成多张数据表,表与表之间通过某个或某些共同的值相互关联起来,进而达到消减冗余项、降低维护难度与成本的目的。
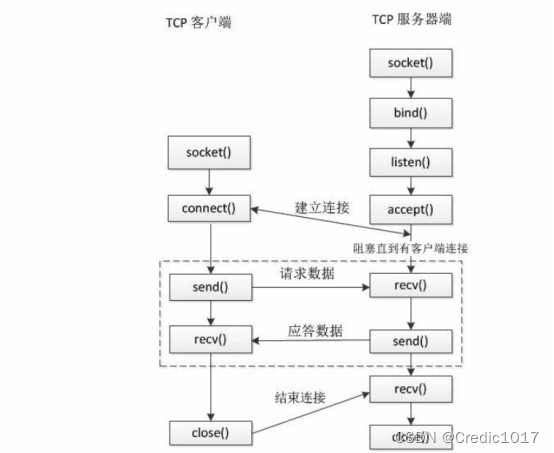
如果用 “子查询” 来完成跨多张数据表的查询的话,难度是非常大而且效率非常低,它的本质是在一次查询结果的基础上完成其它查询,通常是用来缩减查询步骤的。如果我们只是想要从多张存在于数据库的数据表中选择字段、完成简单的计算的话,用"子查询"就显得大材小用了。因此,我们可以通过 “联结” 的方式来处理跨表查询问题。借助 FROM 子句和 WHERE 子句建立的 FROM 型联结,以及使用 JOIN 子句建立的 INNER JOIN 型和 LEFT JOIN 型联结。
FROM 型联结
假设有以下两张数据表:fruits 表记录着四种水果信息,有 4 行 3 列。fruit_price 表记录着两类水果的单价,有 2 行 2 列。两张数据表之间由 fruit_id 列关联起来。
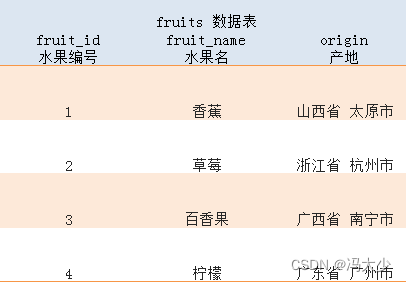
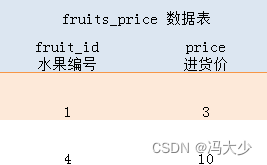
如果我们在 FROM 子句里同时选择这两张数据表并检索出所有列:
SELECT *
FROM fruits,
fruit_price;
查询结果如下, 可以看到,查询结果共有 8 行,即两表行数的乘积;5 列,即两表列数之和。不加任何条件时,多表的查询结果是它们的 笛卡尔积 ,这是数学上的一个概念,简单理解就是把 fruits 表的所有行,分别和 fruit_price 表的所有行一一匹配起来。
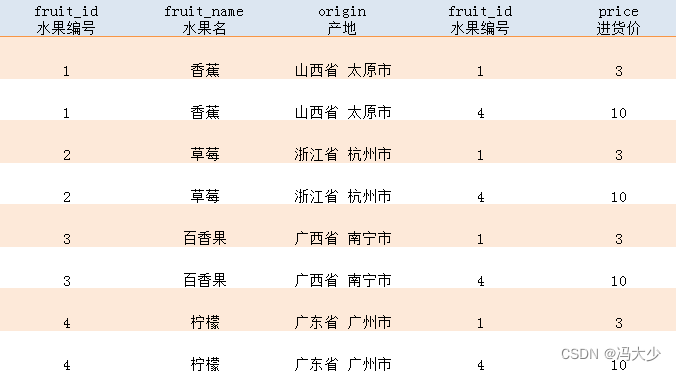
显然这样的结果是不正确的。以香蕉为例,它的编号为 1。对应到 fruit_price 数据表中,编号为 1 的数据 price 列的值为 3。所以我们可以判断出,香蕉的进价为 3 元。而查询结果中,除了这条正确信息,还错把 10 元的内容包含了进来。这并非我们想要的结果。
所以,只是在 FROM 子句中写上数据表名是不够的,我们还需要把那些符合关联关系的数据,也就是 fruits.fruit_id 与 fruit_price.fruit_id 列相同的行检索出来。通过 WHERE 子句,把关联关系 fruits.fruit_id = fruit_price.fruit_id 写入 WHERE 子句中:
SELECT *
FROM fruits,
fruit_price
WHERE fruits.fruit_id = fruit_price.fruit_id;
再次执行查询,查询结果如下:

以上才是正确的输出结果。像这样通过筛选列值相等的行建立起的联结,叫做 等值联结。包括以下奖继续介绍的JOIN 型联结,都属于等值联结。
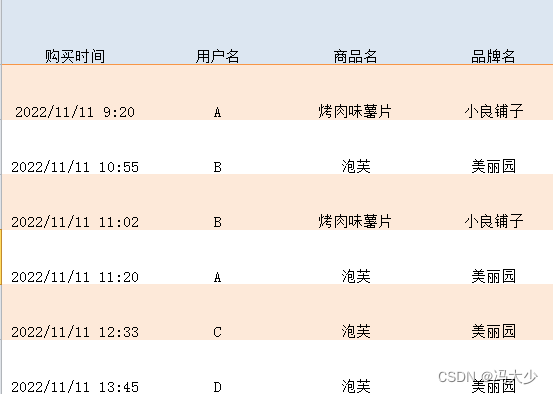
我们还可以通过等值关系将更多张数据表关联起来。假如我们想从 user_behavior、brands 和 users 这三张数据表中,筛选出购物行为,并选择出购买时间(即行为的发生时间)、用户名、商品名、品牌名这四项信息。
那么首先,我们需要把这三张数据表填入 FROM 子句,并把所需的字段写在 SELECT 子句里。接下来,在 WHERE 子句里按表与表之间的关联规则,把条件补充完整。最后在 WHERE 子句中再加上筛选条件 user_behavior.type = ‘buy’。完整的 SQL 语句是这样的:
SELECT datetime(user_behavior.time, 'unixepoch') AS 购买时间,
user_behavior.user_name AS 用户名,
items.item_name AS 商品名,
brands.brand_name AS 品牌名
FROM user_behavior,
items,
brands
WHERE user_behavior.item_id = items.item_id
AND items.brand_id = brands.brand_id
AND user_behavior.type = 'buy';
AS 关键字
我们可以像给列取别名一样,给每一张出现在 FROM 子句里的数据表起一个简短的别名,目的是为了压缩 SQL 语句长度,方便我们书写,所以应当取一个简短、不重复的名字。
SELECT datetime(user_behavior.time, 'unixepoch') AS 购买时间,
user_behavior.user_name AS 用户名,
items.item_name AS 商品名,
brands.brand_name AS 品牌名
FROM user_behavior, AS ub,
items, AS i,
brands AS b
WHERE user_behavior.item_id = items.item_id
AND items.brand_id = brands.brand_id
AND user_behavior.type = 'buy';
如果在 FROM 子句里给数据表起了别名,在这整条 SQL 语句中就只能使用别名来指代这张数据表,而不能使用原本的表名了。例如我们在第 5 行给 user_behavior 表取名为 ub,那么在 SELECT 子句中选择它的 user_name 列的话,只能写成 ub.user_name,而不能写成 user_behavior.user_name
对于那些不重名的列,例如 user_behavior 数据表中的 type,items 数据表中的 price 等等,加不加数据表名进行限定,SQL 都能分辨出来。所以我们可以省略前面的表名。在绝大多数 DBMS 中,取别名的关键字 AS 也是可以省略的,只要符合 列名/数据表名 别名 的形式,SQL 会自动判断原名与别名。因此上面的 SQL 语句最终可以简化成这样 :
SELECT datetime(user_behavior.time, 'unixepoch') 购买时间,
user_behavior.user_name 用户名,
items.item_name 商品名,
brands.brand_name 品牌名
FROM user_behavior, ub,
items, i,
brands b
WHERE user_behavior.item_id = items.item_id
AND items.brand_id = brands.brand_id
AND user_behavior.type = 'buy';
JOIN 子句
join 有“连接”的意思,放在 SQL 中,JOIN 关键字表示把两张数据表 联结 起来。例如 数据表A JOIN 数据表B,就表示把数据表 A 和数据表 B 联结起来。同样的道理,只是把表拼起来是不够的,还需要指明它们之间的关系。这部分功能由关键字 ON 来完成,完整的写法是 数据表A JOIN 数据表B ON 关联关系。
JOIN 关键字和 ON 关键字一起构成了 JOIN … ON … 子句,也可以简称为 JOIN 子句。由 JOIN 子句联结起来的数据表,将作为该条 SQL 语句的数据来源,要一起写在 FROM 子句里。
例如 fruits 数据表通过 fruit_id 列关联到 fruit_price 数据表。那么用 JOIN 子句创建它俩的联结时,需要编写如下 SQL 语句:
SELECT *
FROM fruits f
JOIN fruit_price fp ON f.fruit_id = fp.fruit_id;
JOIN 子句可以创建多种联结,不同种类的联结,是用特殊的关键字进行标记的。如果像我们上面所写的 SQL 语句一样,JOIN 前面什么都不标的话,SQL 会默认使用 INNER JOIN 型联结方式。INNER JOIN 型联结的效果和 FROM 型联结一样,会先列出数据表的笛卡尔积,再把 完全符合关联条件 的行检索出来。因此以上 SQL 语句的查询结果为 2 行 5 列。

我们也能把 FROM 型联结改写成 INNER JOIN 型联结。例如我们在 FROM 型联结中完成的任务:从 user_behavior、brands 和 users 这三张数据表中检索信息。改用 JOIN 子句来创造联结的话,需要写成这样:
SELECT datetime(time, 'unixepoch') 购买时间,
user_name 用户名,
item_name 商品名,
brand_name 品牌名
FROM user_behavior ub
JOIN items i ON ub.item_id = i.item_id
JOIN brands b ON i.brand_id = b.brand_id
WHERE type = 'buy';
可以看到,与联结相关的内容,都在 FROM 子句里,而且我们能一眼看出来,参与到联结的有 user_behavior 表和 JOIN 关键字后面的 items 表和 brands 表,关联关系分别是 ub.item_id = i.item_id 和 i.brand_id = b.brand_id。基于联结表的筛选条件,则在 WHERE 子句里。每个子句功能明确,清晰明了。
LEFT JOIN 型联结
很多时候,表与表的数据并非每一条都能对应起来。例如 fruits 数据表和 fruit_price 表都有 fruit_id 列,但 fruits 表中有 ID 为 1、2、3、4 的四条数据,fruit_price 中只有 ID 为 1、4 的两条数据。当我们使用 FROM 或 INNER JOIN 创建联结时,fruits 数据表中那些尚未记录进价的水果——草莓和百香果,它们的编号、名称、产地信息就丢失了。如果我们想保全 fruits 数据表中的信息,即以 fruits 数据表中记录的每种水果为基准,如果已经进货了,就正常显示进价;没有进货,也就是 fruit_price 数据表中没有记录的话,则把进价标记为 NULL。这时该怎么办呢?这需要用到另一种联结方式,LEFT JOIN 型联结。
FROM 型联结与 INNER JOIN 型联结,所联结的数据表之间是平等的。我们调换数据表的书写顺序,例如把 FROM fruits, fruit_price 换为 FROM fruit_price, fruits,它只影响各列出现的顺序,并不会影响联结表中的行数。而 LEFT JOIN 型联结蕴含着一种主次关系,数据表A LEFT JOIN 数据表B 与 数据表B LEFT JOIN 数据表A 的行数可能并不相同。例如我们通过 fruit_id 列相等的条件,将 fruit_price 数据表与 fruits 数据表以 LEFT JOIN 方式联结:
SELECT *
FROM fruit_price fp
LEFT JOIN fruits f ON fp.fruit_id = f.fruit_id;

而如果调换顺序,把 fruits 写在 LEFT JOIN 之前:
SELECT *
FROM fruits f
LEFT JOIN fruit_price fp ON f.fruit_id = fp.fruit_id;
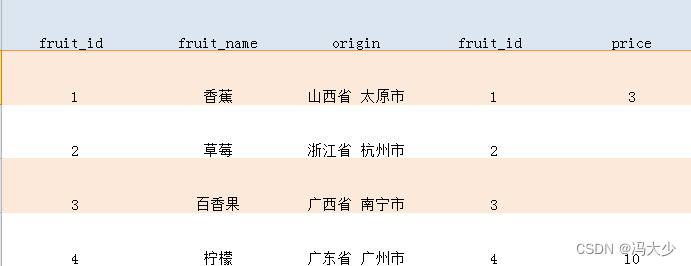
可以看到,此时的查询结果变成了 4 行。如果单看前面 3 列的话,它和 fruits 数据表的内容一模一样。再看后面两列,很显然是来自 fruit_price 表的数据,而且满足 f.fruit_id = fp.fruit_id 条件的行有数据,不满足条件的行没有数据。
这就是 LEFT JOIN 型联结的特征。它会把 LEFT JOIN 关键字之前的数据表作为主表,把后面的作为次表。在创建联结时,先把主表中的所有数据誊抄一遍,再把次表中符合联结条件的数据拼接在后面。这样我们就可以完全保留主表中的数据。
除了 INNER JOIN 和 LEFT JOIN,SQL 标准中还有其它多种联结,例如与 LEFT JOIN 相对的 RIGHT JOIN,以及把两张表中所包含的数据完全保留下来的 FULL JOIN。但是,RIGHT JOIN 可以通过调换数据表顺序的方式转化为 LEFT JOIN,FULL JOIN 则在日常工作中几乎没有用。
回顾 items、brands 与 item_data 这三张数据表之间的关联关系:可以看到,三张数据表是通过 items 数据表彼此关联起来的。所以我们可以把 items 数据表紧紧放在 FROM 关键字后面,作为后续联结的基准。
售卖比:通过 (销售件数 - 退货件数) / 备货量 公式计算,并使用 round() 保留 2 位小数;
净销售额:(销售件数 - 退货件数) * 售价。
库存则要稍微麻烦一些。当 item_data 数据表中记录了商品的数据,即 buy 的值不为 NULL 时,库存等于 备货量 - 销售件数 + 退货件数。而有些商品在 item_data 中没有数据,如果也套用这个公式,即 NULL 值参与计算,结果自然会出现问题。
所以我们在计算库存时,要做个判断,如果 buy 值为 NULL,直接把 total 的值作为库存;如果不为 NULL,则通过 total - buy + return 计算出结果。
SELECT item_name 商品名,
brand_name 品牌名,
round((buy - return) / total, 2) 售卖比,
(buy - return) * sale_price 净销售额,
iif(
buy IS NULL, -- 判断 buy 是否为 NULL
total, -- 为 NULL 时,把 total 作为库存
total - buy + return -- 不为 NULL 时,通过计算得到结果库存
)
FROM items i
LEFT JOIN item_data id ON i.item_id = id.item_id
JOIN brands b ON i.brand_id = b.brand_id;
按照 ABC 分析法,将表中所有商品根据 售卖比 情况分为三类。由于 ABC 分析法指出,占比 20% 的元素,产生 80% 的价值,所以我们可以把售卖比最高的前 20% 商品为 A 类商品,最末尾的 65% 为 C 类商品,其余为 B 类商品。
划分完 A、B、C 类后,我们还需要根据 净销售额,在 A 类商品中找出下季度主推商品。主推商品的件数,一般是根据平台自身体量以及过往数据决定的,在这里我们取净销售额最高的 前 10 件商品作为最终结果。对于 C 类,则需要根据 库存,找出需要清仓的商品。在这里,我们取库存量最高的 前 10 件商品作为最终结果。
我们可以分两条 SQL 语句,分别筛选出主推商品清单和清仓商品清单。筛选主推商品时,先按照 售卖比 降序,再按照 净销售额 降序,此时排在数据表前 10 条的数据,就是我们想要的商品。筛选清仓商品时,则先按照 售卖比 升序,再按照 库存 降序,此时排在数据表前 10 条的数据,就是适合清仓商品。