CBLUE_中文生物医学语言理解评估基准_源码详解
源码链接:https://github.com/CBLUEbenchmark/CBLUE
项目中包括八个不同的中文医学NLP任务:1.中文医学命名实体识别(CMeEE)、2.中文医学文本实体关系抽取(CMeIE)、3.临床术语标准化任务(CHIP-CDN)、4.临床试验筛选标准短文本分类(CHIP-CTC)、5.平安医疗科技疾病问答迁移学习(CHIP-STS)、6.医疗搜索检索词意图分类(KUAKE-QIC)、7.医疗搜索查询词-页面标题相关性(KUAKE-QTR)、8.医疗搜索查询词-查询词相关性(KUAKE-QQR)
本文以医疗搜索检索词意图分类(KUAKE-QIC)任务为例
一、介绍项目目录结构
├── CBLUE
| └── baselines
| └── run_classifier.py # 程序入口
| └── ...
| └── examples
| └── run_qic.sh # QIC任务快捷启动脚本
| └── ...
| └── cblue
| └── data
| └── data_process.py # 训练数据处理
| └── dataset.py # 从json文件中获取数据字段
| └── metrics
| └── cblue_commit.py # 测试数据保存
| └── cblue_metrics.py # 度量方法
| └── models
| └── zen # zen模型实现
| └── model.py # zen模型实现
| └── trainer #
| └── train.py # 模型训练类
| └── utils.py # 工具类
| └── CBLUEDatasets
| └── KUAKE-QIC # 数据集存放路径
| └── KUAKE-QIC_dev.json # 验证集
| └── KUAKE-QIC_test.json # 测试集
| └── KUAKE-QIC_train.json # 训练集
| └── data
| └── output # 训练好生成模型的存放路径
| └── qic
| └── chinese-bert-wwm-ext
| └── config.json # 模型参数配置文件
| └── pytorch_model.bin # 训练完成的模型
| └── training_args.bin #
| └── qic_chinese-bert-wwm-ext.log # 训练日志文件
| └── vocab.txt # 词汇表
| └── model_data
| └── chinese-bert-wwm # 在运行之前,下载pytorch版本的bert模型
| └── bert_config.json # 预训练模型的参数配置文件
| └── pytorch_model.bin # 预训练模型
| └── vocab.txt # 词汇表
| └── result_output
| └── KUAKE-QIC_test.json # 传入do_predict参数,利用训练好的模型预测测试集的样本标签,生成的文件
二、介绍KUAKE-QIC数据集
KUAKE-Query Intent Classification Dataset (KUAKE-QIC)
医疗意图标签共有11类,包括诊断、病因分析、治疗计划、医疗建议、检测结果分析、疾病描述、后果预测、注意事项、预期效果、治疗费用和其它。
数据集示例:训练集(左)、测试集(右)

三、项目运行环境搭建
推荐使用服务器训练模型,或者用笔记本自带的GPU
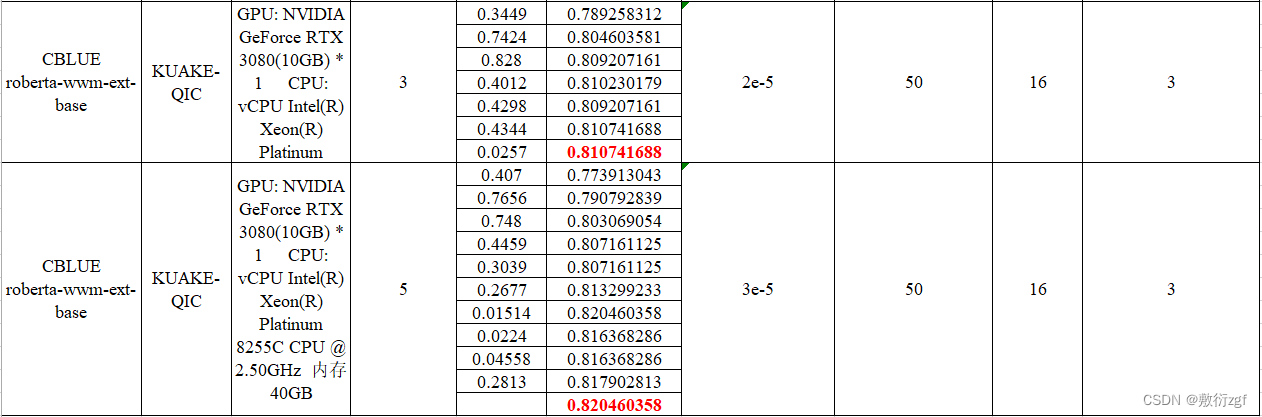
本人租用AutoDL,配置如下图:
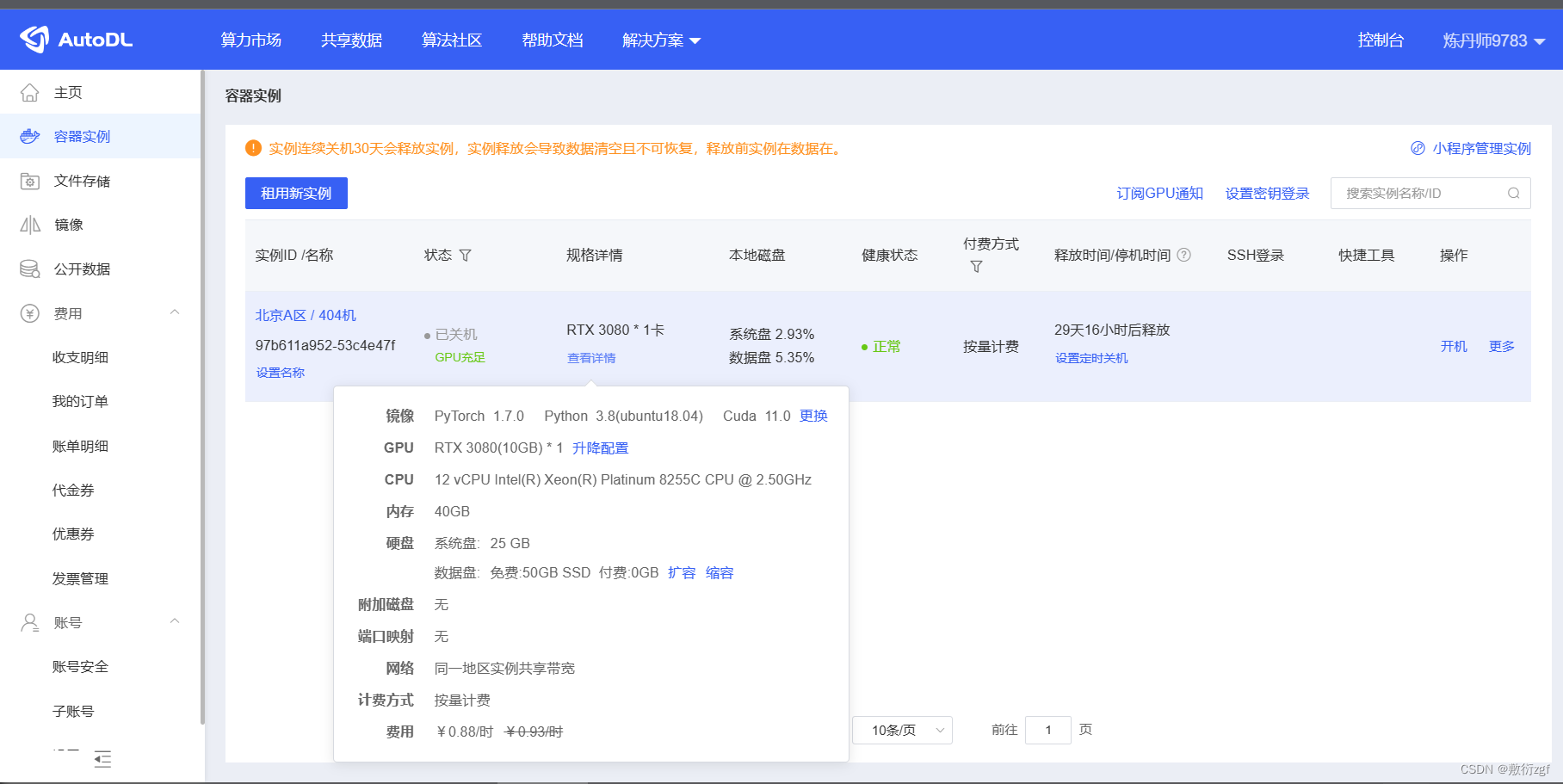
切记选择PyTorch 1.7.0 Python 3.8(ubuntu18.04) Cuda 11.0
其他版本的运行程序会出错。
安装其他第三方库:
本项目使用的第三方库有:torch 1.7 / transformers 4.5.1 / jieba / gensim / scikit-learn等,安装时切记版本对应,否则模型训练报错,版本不兼容。
或者在运行时看程序报错缺失哪个包,再pip安装即可。
-----至此前期工作全部完成,接下来可以运行看看效果!-----
四、运行项目
直接运行sh脚本文件 bash examples/run_qic.sh,若使用服务器,请在终端进入到examples的父目录再运行。
脚本文件中,已经配置了模型训练需要的参数,可以根据不同任务进行微调。
#!/usr/bin/env bash
DATA_DIR="CBLUEDatasets" # 数据集总目录
TASK_NAME="qic" # 具体任务 医疗搜索检索词意图分类(KUAKE-QIC)
MODEL_TYPE="bert" # 预训练模型类型
MODEL_DIR="data/model_data" # 预训练模型保存路径
MODEL_NAME="chinese-bert-wwm-ext" # 预训练模型名称
OUTPUT_DIR="data/output" # 模型保存目录
RESULT_OUTPUT_DIR="data/result_output" # 结果保存目录
MAX_LENGTH=50 # 最大长度
echo "Start running"
if [ $# == 0 ]; then
python baselines/run_classifier.py \
--data_dir=${DATA_DIR} \
--model_type=${MODEL_TYPE} \
--model_dir=${MODEL_DIR} \
--model_name=${MODEL_NAME} \
--task_name=${TASK_NAME} \
--output_dir=${OUTPUT_DIR} \
--result_output_dir=${RESULT_OUTPUT_DIR} \
--do_train \
--max_length=${MAX_LENGTH} \
--train_batch_size=16 \ # 训练的batch-size
--eval_batch_size=16 \ # 验证的batch-size
--learning_rate=3e-5 \ # 学习率
--epochs=3 \ # 训练的迭代次数
--warmup_proportion=0.1 \ # 慢热学习的比例
--earlystop_patience=3 \ #当使用提前终止训练策略时,如果验证集精度在earlystop_patience个epoch内连续下降或持平,则终止训练。默认值为5。
--logging_steps=200 \ # 日志打印的间隔 steps,默认为 20
--save_steps=200 \ # 保存模型参数的间隔 steps,默认为 100
--seed=2021 # 随机种子,默认为1000
elif [ $1 == "predict" ]; then
python baselines/run_classifier.py \
--data_dir=${DATA_DIR} \
--model_type=${MODEL_TYPE} \
--model_name=${MODEL_NAME} \
--model_dir=${MODEL_DIR} \
--task_name=${TASK_NAME} \
--output_dir=${OUTPUT_DIR} \
--result_output_dir=${RESULT_OUTPUT_DIR} \
--do_predict \
--max_length=${MAX_LENGTH} \
--eval_batch_size=16 \
--seed=2021
fi
一些参数介绍:
Warmup:Warmup是在ResNet论文中提到的一种学习率预热的方法,由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
warmup_proportion:慢热学习的比例。比如warmup_proportion=0.1,总步数=100,那么warmup步数就为10。在1到10步中,学习率会比10步之后低,10步之后学习率恢复正常。
五、获取加载数据
class QICDataset(Dataset):
def __init__(
self,
samples,
data_processor,
mode='train'
):
super(QICDataset, self).__init__()
self.text = samples['text']
self.ids = samples['id']
if mode != 'test':
self.labels = samples['label'] # 非测试数据集都有label
self.data_processor = data_processor
self.mode = mode
def __getitem__(self, item):
if self.mode != 'test':
return self.text[item], self.labels[item]
else:
return self.text[item]
def __len__(self):
return len(self.text)
class QICDataProcessor(object):
def __init__(self, root):
self.task_data_dir = os.path.join(root, 'KUAKE-QIC') # 获取数据集名称
# 对训练集 测试集 和 验证集的路径进行拼接
self.train_path = os.path.join(self.task_data_dir, 'KUAKE-QIC_train.json')
self.dev_path = os.path.join(self.task_data_dir, 'KUAKE-QIC_dev.json')
self.test_path = os.path.join(self.task_data_dir, 'KUAKE-QIC_test.json')
# 11种意图标签
self.label_list = ['疾病表述', '指标解读', '医疗费用', '治疗方案', '功效作用', '病情诊断',
'其他', '注意事项', '病因分析', '就医建议', '后果表述']
self.label2id = {label: idx for idx, label in enumerate(self.label_list)}
self.id2label = {idx: label for idx, label in enumerate(self.label_list)}
self.num_labels = len(self.label_list)
def get_train_sample(self):
return self._pre_process(self.train_path, is_predict=False)
def get_dev_sample(self):
return self._pre_process(self.dev_path, is_predict=False)
def get_test_sample(self):
return self._pre_process(self.test_path, is_predict=True)
def _pre_process(self, path, is_predict):
#拿到json文件中标签对应的值
samples = load_json(path)
outputs = {'text': [], 'label': [], 'id': []}
for sample in samples:
outputs['text'].append(sample['query'])
outputs['id'].append(sample['id'])
if not is_predict:
outputs['label'].append(self.label2id[sample['label']])
return outputs
六、模型训练
class QICTrainer(Trainer):
def __init__(
self,
args,
model,
data_processor,
tokenizer,
logger,
model_class,
train_dataset=None,
eval_dataset=None,
ngram_dict=None
):
super(QICTrainer, self).__init__(
args=args,
model=model,
data_processor=data_processor,
tokenizer=tokenizer,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
logger=logger,
model_class=model_class,
ngram_dict=ngram_dict
)
def training_step(self, model, item):
model.train()
text1 = item[0]
labels = item[1].to(self.args.device)
if self.args.model_type == 'zen':
inputs = convert_examples_to_features(text1=text1, ngram_dict=self.ngram_dict,
tokenizer=self.tokenizer, max_seq_length=self.args.max_length,
return_tensors=True)
else:
inputs = self.tokenizer(text1, padding='max_length', max_length=self.args.max_length,
truncation=True, return_tensors='pt')
if self.args.model_type == 'zen':
inputs['input_ngram_ids'] = inputs['input_ngram_ids'].to(self.args.device)
inputs['ngram_position_matrix'] = inputs['ngram_position_matrix'].to(self.args.device)
inputs['ngram_attention_mask'] = inputs['ngram_attention_mask'].to(self.args.device)
inputs['ngram_token_type_ids'] = inputs['ngram_token_type_ids'].to(self.args.device)
inputs['input_ids'] = inputs['input_ids'].to(self.args.device)
inputs['attention_mask'] = inputs['attention_mask'].to(self.args.device)
inputs['token_type_ids'] = inputs['token_type_ids'].to(self.args.device)
# default using 'Transformers' library models.
outputs = model(labels=labels, **inputs)
loss = outputs[0]
loss.backward()
return loss.detach()
def evaluate(self, model):
args = self.args
logger = self.logger
eval_dataloader = self.get_eval_dataloader()
num_examples = len(eval_dataloader.dataset)
preds = None
eval_labels = None
logger.info("***** Running evaluation *****")
logger.info("Num samples %d", num_examples)
for step, item in enumerate(eval_dataloader):
model.eval()
text1 = item[0]
labels = item[1].to(args.device)
if self.args.model_type == 'zen':
inputs = convert_examples_to_features(text1=text1, ngram_dict=self.ngram_dict,
tokenizer=self.tokenizer, max_seq_length=self.args.max_length,
return_tensors=True)
else:
inputs = self.tokenizer(text1, return_tensors='pt', padding='max_length',
truncation='longest_first', max_length=self.args.max_length)
inputs['input_ids'] = inputs['input_ids'].to(self.args.device)
inputs['attention_mask'] = inputs['attention_mask'].to(self.args.device)
inputs['token_type_ids'] = inputs['token_type_ids'].to(self.args.device)
if self.args.model_type == 'zen':
inputs['input_ngram_ids'] = inputs['input_ngram_ids'].to(self.args.device)
inputs['ngram_position_matrix'] = inputs['ngram_position_matrix'].to(self.args.device)
inputs['ngram_attention_mask'] = inputs['ngram_attention_mask'].to(self.args.device)
inputs['ngram_token_type_ids'] = inputs['ngram_token_type_ids'].to(self.args.device)
with torch.no_grad():
outputs = model(labels=labels, **inputs)
loss, logits = outputs[:2]
if preds is None:
preds = logits.detach().cpu().numpy()
eval_labels = labels.detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
eval_labels = np.append(eval_labels, labels.detach().cpu().numpy(), axis=0)
preds = np.argmax(preds, axis=1)
acc = qic_metric(preds, eval_labels)
logger.info("%s-%s acc: %s", args.task_name, args.model_name, acc)
return acc
def predict(self, test_dataset, model):
args = self.args
logger = self.logger
test_dataloader = self.get_test_dataloader(test_dataset)
num_examples = len(test_dataloader.dataset)
model.to(args.device)
preds = None
logger.info("***** Running prediction *****")
logger.info("Num samples %d", num_examples)
pbar = ProgressBar(n_total=len(test_dataloader), desc='Prediction')
for step, item in enumerate(test_dataloader):
model.eval()
text1 = item
if self.args.model_type == 'zen':
inputs = convert_examples_to_features(text1=text1, ngram_dict=self.ngram_dict,
tokenizer=self.tokenizer, max_seq_length=self.args.max_length,
return_tensors=True)
else:
inputs = self.tokenizer(text1, return_tensors='pt', padding='max_length',
truncation='longest_first', max_length=self.args.max_length)
if self.args.model_type == 'zen':
inputs['input_ngram_ids'] = inputs['input_ngram_ids'].to(self.args.device)
inputs['ngram_position_matrix'] = inputs['ngram_position_matrix'].to(self.args.device)
inputs['ngram_attention_mask'] = inputs['ngram_attention_mask'].to(self.args.device)
inputs['ngram_token_type_ids'] = inputs['ngram_token_type_ids'].to(self.args.device)
inputs['input_ids'] = inputs['input_ids'].to(self.args.device)
inputs['attention_mask'] = inputs['attention_mask'].to(self.args.device)
inputs['token_type_ids'] = inputs['token_type_ids'].to(self.args.device)
with torch.no_grad():
outputs = model(**inputs)
if self.args.model_type == 'zen':
logits = outputs
else:
logits = outputs[0]
if preds is None:
preds = logits.detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
pbar(step=step, info="")
preds = np.argmax(preds, axis=1)
qic_commit_prediction(dataset=test_dataset, preds=preds, output_dir=args.result_output_dir,
id2label=self.data_processor.id2label)
return preds
# 保存模型
def _save_checkpoint(self, model, step):
output_dir = os.path.join(self.args.output_dir, 'checkpoint-{}'.format(step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
if self.args.model_type == 'zen':
save_zen_model(output_dir, model=model, tokenizer=self.tokenizer,
ngram_dict=self.ngram_dict, args=self.args)
else:
model.save_pretrained(output_dir)
torch.save(self.args, os.path.join(output_dir, 'training_args.bin')) # 保存训练参数
self.tokenizer.save_vocabulary(save_directory=output_dir)
self.logger.info('Saving models checkpoint to %s', output_dir)
def _save_best_checkpoint(self, best_step): # 保存最佳的模型
model = self.model_class.from_pretrained(os.path.join(self.args.output_dir, f'checkpoint-{best_step}'),
num_labels=self.data_processor.num_labels)
if self.args.model_type == 'zen':
save_zen_model(self.args.output_dir, model=model, tokenizer=self.tokenizer,
ngram_dict=self.ngram_dict, args=self.args)
else:
model.save_pretrained(self.args.output_dir)
torch.save(self.args, os.path.join(self.args.output_dir, 'training_args.bin'))
self.tokenizer.save_vocabulary(save_directory=self.args.output_dir)
self.logger.info('Saving models checkpoint to %s', self.args.output_dir)
七、模型评估
# 计算准确率
def simple_accuracy(preds, labels):
return (preds == labels).mean()
def qic_metric(preds, labels):
return simple_accuracy(preds, labels)
def qic_commit_prediction(dataset, preds, output_dir, id2label):
text1 = dataset.text
label = preds
ids = dataset.ids
pred_result = []
for item in zip(ids, text1, label):
tmp_dict = {'id': item[0], 'query': item[1],
'label': id2label[item[2]]}
pred_result.append(tmp_dict)
with open(os.path.join(output_dir, 'KUAKE-QIC_test.json'), 'w', encoding='utf-8') as f:
f.write(json.dumps(pred_result, indent=2, ensure_ascii=False))
八、运行程序