推荐超级课程:
- 本地离线DeepSeek AI方案部署实战教程【完全版】
- Docker快速入门到精通
- Kubernetes入门到大师通关课
- AWS云服务快速入门实战
目录
-
- 介绍
- 什么是 vLLM?
- 处理 vLLM 中的多模态模型
- 实现独特的视频生成模型
- 转换为 vLLM 模型的策略
-
- 准备输入标记序列
- 如何添加多个多模式输入
- 如何输入动作向量序列
- 输出处理
- vLLM 模型的实现
-
- 注册 HF Model实现
- 为您自己的模态准备一个插件
- 位置编码实现的变更
- 实现虚拟输入函数
- 注册自己的插件和虚拟数据相关函数
- 用多模式数据替换占位符
- 配置学习到的权重名称映射
- 使用 vLLM 模型进行推理
-
- 初始化模型
- 模型推理
- 测速
- 结论
介绍
在本文中,我们将解释如何使用 vLLM 使用视频生成模型推断独特的多模式模型。 vLLM 是一个用于高速推理和服务的 LLM 库,它非常易于使用,支持 Llama 和 Qwen 等知名模型。另一方面,除了官方文档之外,关于如何合并自定义实现模型的信息非常少,甚至官方文档也没有特别的信息,因此很难上手。
因此,在本文中,我们将仔细解释将您自己的多模态模型合并到 vLLM 中的具体步骤,包括官方文档中未包含的信息。具体来说,我们以视频生成模型为例,详细讲解如何将 Hugging Face Transformers 库中实现的模型适配到 vLLM。我们还将介绍利用 vLLM 可以实现的推理速度的提升以及实际结果。
本文涵盖以下主题:
- 如何使用 vLLM 实现自己的模型
- 如何使用 vLLM 处理您自己的多模式数据
什么是 vLLM?
vLLM是一个开源库,用于加速大型语言模型(LLM)的推理并使模型服务变得简单而高效。近年来,Hugging Face Transformers库被广泛用于 LLM 的训练和实验。然而,Transformers 的实现在推理过程中存在一些效率低下的问题。最值得注意的问题是键值缓存管理效率低下。
键值缓存是 Transformer 模型用来在推理过程中有效重用过去的上下文信息的一种机制。该缓存存储了过去令牌激活的结果,并在生成新令牌时重复使用。然而,在 Transformers 库的标准实现中,这种缓存的管理结构使得其容易出现不必要的内存消耗和处理延迟,从而限制了 LLM 推理的速度。
vLLM旨在通过采用独特的PagedAttention算法来解决这一问题。 PagedAttention 是一种优化键值缓存分配和管理的机制,可显著减少缓存内存浪费,同时实现快速访问和更新。因此,与传统库相比,vLLM 可以实现更高的推理吞吐量。
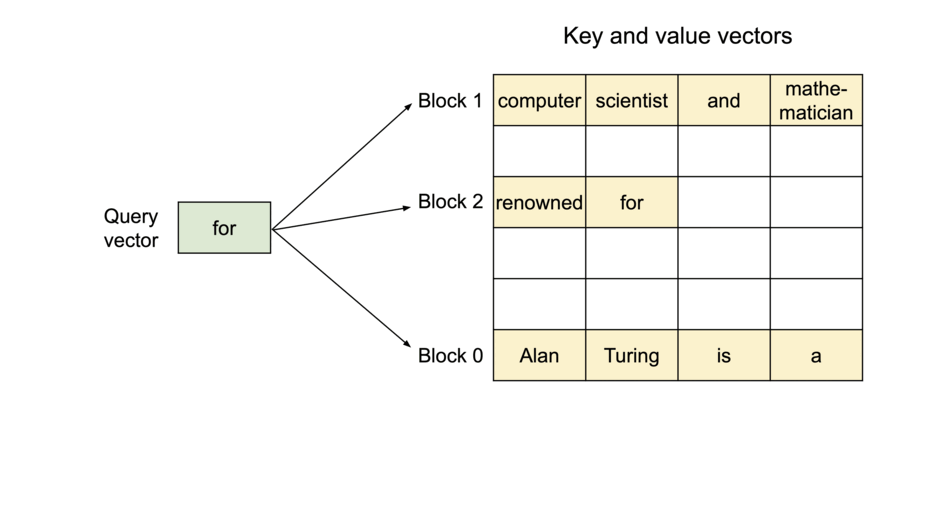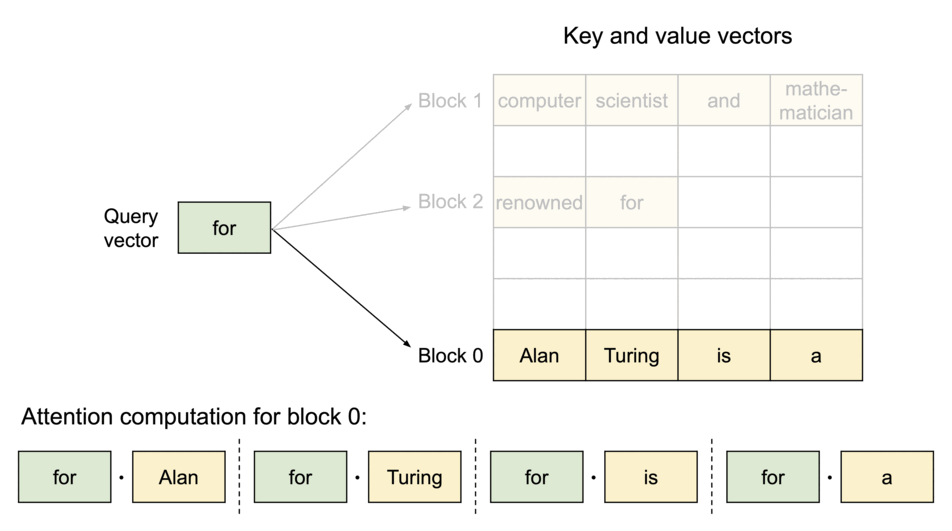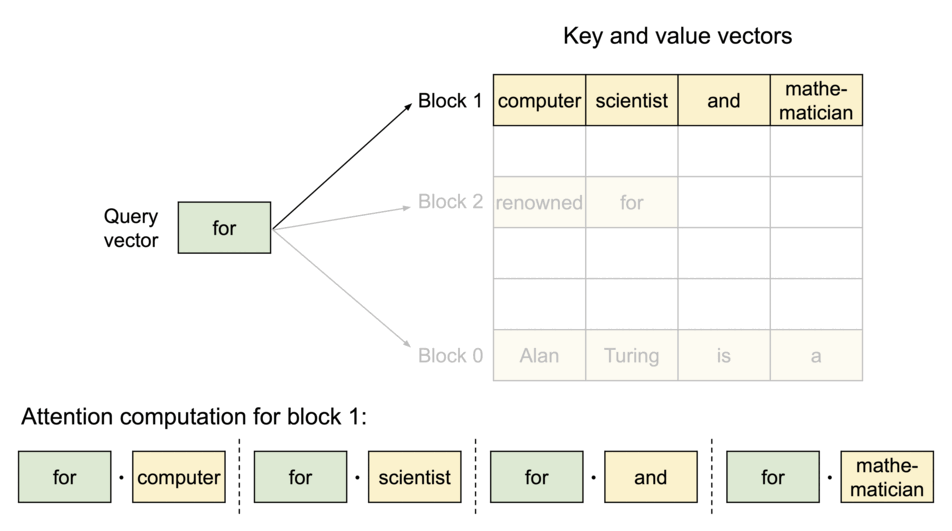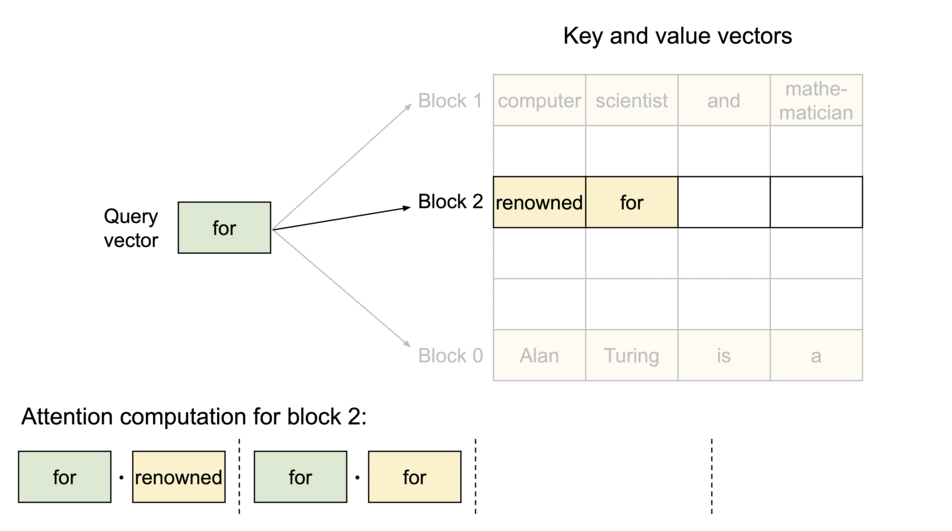
此外,我们还做出了各种努力来加快这一过程,包括实现在使用 LLM 服务时有效的连续批处理,以及支持量化(GPTQ、AWQ、INT4/8、FP8)。
vLLM 与 Hugging Face Transformers 高度兼容,对于流行模型来说,不需要任何特殊工作。因此,它在开发速度很重要的项目和原型设计阶段特别有用。
处理 vLLM 中的多模态模型
vLLM 是一个用于高速推理和提供 LLM 的库,但它也可以加速处理图像和音频以及语言等输入的多模式模型的推理。此外,如果实施得当,任何自回归 Transformer 模型都可以变得更快。
通过vLLM包vllm.multimodal支持多模式模型。用户可以使用字段vllm.inputs.PromptType以及multi_modal_data文本和令牌提示将多模式输入传递给模型。目前,vLLM 提供对图像和视频数据的内置支持,但可以扩展以处理其他模式。
vLLM 还提供了使用多模态模型进行离线推理的示例。例如,官方文档提供了使用单幅图像输入进行推理和组合多幅图像进行推理的示例代码。
实现独特的视频生成模型
在这篇博客中,我们考虑使用 vLLM 来加速视频生成模型“Terra”。
该模型使用图像标记器将视频的每个图像帧转换为离散标记序列,然后使用代表图像序列的标记序列作为输入来预测未来图像序列的离散标记序列。然后使用解码器将预测的离散标记序列转换为图像序列以生成视频。


您还可以输入称为动作的向量序列来进行条件反射。该矢量序列是一个 3 x 6 矩阵,由六个三维矢量组成,插入在每个图像帧之间。由于有 576 个离散标记代表一个图像帧,因此在推理过程中,会为图像中的每 576 个离散标记插入一个 6 标记向量。
Hugging Face在Transformers中的实现如下。该模型基于Llama架构的LLM模型,但不同之处在于它包含处理动作向量的机制和可以作为位置编码进行学习的特殊位置编码。
- 使用 Transformer 实现
from typing import List, Optional, Tuple, Union
import torch
import torch.nn as nn
from transformers import LlamaConfig, LlamaForCausalLM
from transformers.modeling_outputs import CausalLMOutputWithPast
from ..positional_embedding import LearnableFactorizedSpatioTemporalPositionalEmbedding
class LlamaActionConfig(LlamaConfig):
model_type = "llama_action"
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.num_spatio_embeddings = kwargs.get("num_spatio_embeddings", 582)
self.num_temporal_embeddings = kwargs.get("num_temporal_embeddings", 25)
self.num_action_embeddings = kwargs.get("num_action_tokens", 6)
self.num_image_patches = kwargs.get("num_image_patches", 576)
self.action_dim = kwargs.get("action_dim", 3)
class LlamaActionForCausalLM(LlamaForCausalLM):
config_class = LlamaActionConfig
def __init__(self, config: LlamaActionConfig):
super().__init__(config)
self.num_spatio_embeddings = config.num_spatio_embeddings
self.num_temporal_embeddings = config.num_temporal_embeddings
self.num_image_patches = config.num_image_patches
self.num_action_embeddings = config.num_action_embeddings
self.pos_embedding_spatio_temporal = LearnableFactorizedSpatioTemporalPositionalEmbedding(
config.num_spatio_embeddings, config.num_temporal_embeddings, config.hidden_size,
)
self.action_projection = nn.Linear(config.action_dim, config.hidden_size)
self.post_init()
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
actions: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.Tensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], CausalLMOutputWithPast]:
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError(
"You cannot specify both input_ids and inputs_embeds at the same time"
)
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
inputs_embeds = self.model.get_input_embeddings()(input_ids)
if past_key_values is None:
inputs_embeds_list = torch.split(
inputs_embeds,
split_size_or_sections=self.num_image_patches,
dim=1
)
actions_list = torch.split(
actions,
split_size_or_sections=self.num_action_embeddings,
dim=1
)
embeddings = []
if len(inputs_embeds_list) == len(actions_list):
# 学习时使用的的逻辑,推理时几乎不用
for inputs_embeds, action_embeds in zip(inputs_embeds_list, actions_list):
action_features = self.action_projection(action_embeds)
embeddings.append(inputs_embeds)
embeddings.append(action_features)
elif len(inputs_embeds_list) < len(actions_list):
# 推理使用embeded
for i, inputs_embeds in enumerate(inputs_embeds_list):
embeddings.append(inputs_embeds)
if i < len(inputs_embeds_list) - 1:
# 最后一帧可能是生成过程中的图像令牌序列,因此不添加动作嵌入。
action_embeds = self.action_projection(actions_list[i])
embeddings.append(action_embeds)
if inputs_embeds_list[-1].size(1) == self.num_image_patches:
# 如果图像令牌正好输出了一帧,则在添加动作嵌入的基础上,进一步添加用于下一帧的文本令牌。
action_embeds = self.action_projection(actions_list[len(inputs_embeds_list) - 1])
embeddings.append(action_embeds)
else:
past_key_values_length = past_key_values[0][0].size(2)
embeddings = []
# image, image, ..., image, action, action, ..., action格式进行输入
# 由于只生成图像令牌,所以在生成完一帧的时添加动作令牌。
if past_key_values_length % self.num_spatio_embeddings == (self.num_spatio_embeddings - self.num_action_embeddings):
seq_index = past_key_values_length // self.num_spatio_embeddings + 1
actions_list = torch.split(
actions,
split_size_or_sections=self.num_action_embeddings,
dim=1
)
action_features = self.action_projection(actions_list[seq_index - 1])
embeddings.append(action_features)
embeddings.append(inputs_embeds)
else:
pass
if len(embeddings) > 0:
inputs_embeds = torch.cat(embeddings, dim=1)
# Insert Spatio Temporal Positional Embedding
past_key_values_length = past_key_values[0][0].size(2) if past_key_values is not None else 0
inputs_embeds += self.pos_embedding_spatio_temporal(inputs_embeds, past_key_values_length)
outputs = self.model(
input_ids=None,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.lm_head(sequence_output).contiguous()
loss = None
if labels is not None:
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1))
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def prepare_inputs_for_generation(
self,
input_ids,
past_key_values=None,
attention_mask=None,
use_cache=None,
**kwargs):
batch_size = input_ids.size(0)
seq_length = input_ids.size(1