pytorch的学习与总结
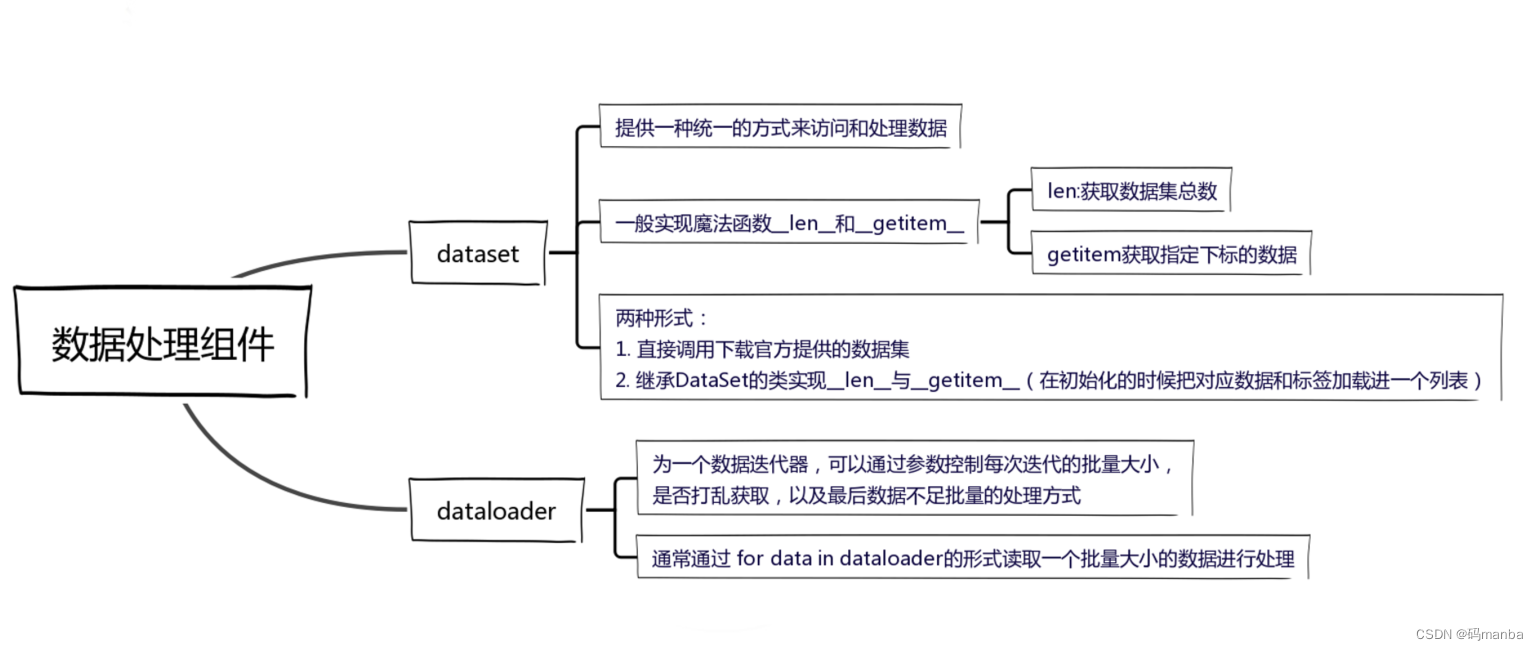
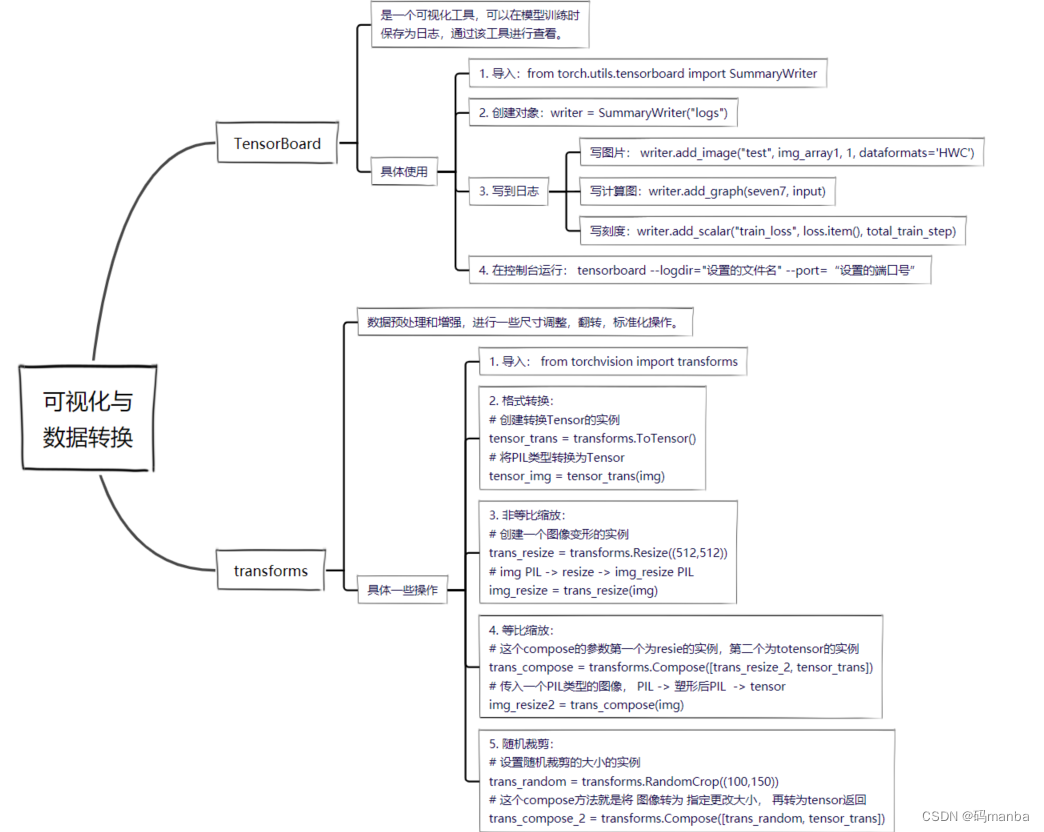
一、pytorch的基础学习 1.1 dataset与dataloader 1.2 可视化工具(tensorboard)、数据转换工具(transforms) 1.3 卷积、池化、线性层、激活函数 1.4 损失函数、反向传播、优化器 1.5 模型的保存、加载、修改 二、 pytorch分类项目实现
model与train
import torch
import torchvision
from torch. utils. tensorboard import SummaryWriter
from torch import nn
from torch. utils. data import DataLoader
device = torch. device( "cuda" if torch. cuda. is_available( ) else "cpu" )
train_data = torchvision. datasets. CIFAR10( root= "../data" , train= True , transform= torchvision. transforms. ToTensor( ) , download= True )
test_data = torchvision. datasets. CIFAR10( root= "../data" , train= False , transform= torchvision. transforms. ToTensor( ) , download= True )
train_data_size = len ( train_data)
test_data_size = len ( test_data)
print ( "训练数据集合的长度为:{}" . format ( train_data_size) )
print ( "测试数据集合的长度为:{}" . format ( test_data_size) )
train_dataloader = DataLoader( dataset= train_data, batch_size= 64 )
test_dataloader = DataLoader( dataset= test_data, batch_size= 64 )
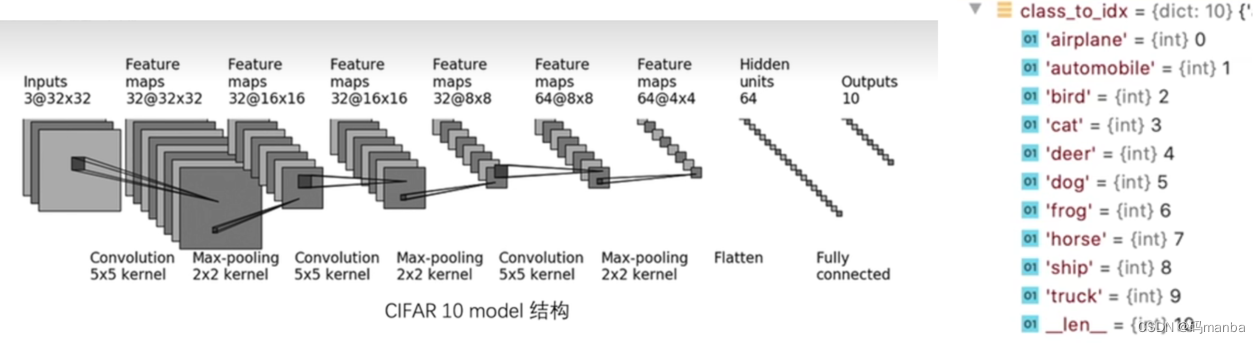
class Seven ( nn. Module) :
def __init__ ( self) :
super ( Seven, self) . __init__( )
self. model = nn. Sequential(
nn. Conv2d( 3 , 32 , 5 , 1 , 2 ) ,
nn. MaxPool2d( 2 ) ,
nn. Conv2d( 32 , 32 , 5 , 1 , 2 ) ,
nn. MaxPool2d( 2 ) ,
nn. Conv2d( 32 , 64 , 5 , 1 , 2 ) ,
nn. MaxPool2d( 2 ) ,
nn. Flatten( ) ,
nn. Linear( 64 * 4 * 4 , 64 ) ,
nn. Linear( 64 , 10 )
)
def forward ( self, x) :
x = self. model( x)
return x
seven = Seven( )
seven. to( device)
loss_fn = nn. CrossEntropyLoss( )
loss_fn. to( device)
learning_rate = 1e - 2
optimizer = torch. optim. SGD( seven. parameters( ) , lr= learning_rate)
total_train_step = 0
total_test_step = 0
epochs = 10
writer = SummaryWriter( "./logs_train" )
for epoch in range ( epochs) :
print ( "第{}轮测试开始" . format ( epoch+ 1 ) )
seven. train( )
for data in train_dataloader:
imgs, targets = data
imgs = imgs. to( device)
targets = targets. to( device)
outputs = seven( imgs)
loss = loss_fn( outputs, targets)
optimizer. zero_grad( )
loss. backward( )
optimizer. step( )
total_train_step += 1
if total_train_step % 100 == 0 :
print ( "训练次数:{},loss:{}" . format ( total_train_step, loss. item( ) ) )
writer. add_scalar( "train_loss" , loss. item( ) , total_train_step)
seven. eval ( )
total_test_loss = 0
total_accuracy = 0
with torch. no_grad( ) :
for data in test_dataloader:
imgs, targets = data
imgs = imgs. to( device)
targets = targets. to( device)
outputs = seven( imgs)
loss = loss_fn( outputs, targets)
total_test_loss = total_test_loss + loss. item( )
accuracy = ( outputs. argmax( 1 ) == targets) . sum ( )
total_accuracy = total_accuracy + accuracy
print ( "整体数据集的Loss:{}" . format ( total_test_loss) )
print ( "整体测试集上的正确率:{}" . format ( total_accuracy/ test_data_size) )
writer. add_scalar( "test_loss" , total_test_loss, total_test_step)
writer. add_scalar( "test_accuracy" , total_accuracy/ test_data_size, total_test_step)
total_test_step += 1
torch. save( seven, "seven_{}.pth" . format ( epoch) )
print ( "第{}次模型保存" . format ( epoch) )
writer. close( )
test import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "./imgs/feiji.jpg"
image = Image. open ( image_path)
print ( image)
transform = torchvision. transforms. Compose( [ torchvision. transforms. Resize( ( 32 , 32 ) ) ,
torchvision. transforms. ToTensor( ) ] )
image = transform( image)
print ( image. shape)
class Seven ( nn. Module) :
def __init__ ( self) :
super ( Seven, self) . __init__( )
self. model = nn. Sequential(
nn. Conv2d( 3 , 32 , 5 , 1 , 2 ) ,
nn. MaxPool2d( 2 ) ,
nn. Conv2d( 32 , 32 , 5 , 1 , 2 ) ,
nn. MaxPool2d( 2 ) ,
nn. Conv2d( 32 , 64 , 5 , 1 , 2 ) ,
nn. MaxPool2d( 2 ) ,
nn. Flatten( ) ,
nn. Linear( 64 * 4 * 4 , 64 ) ,
nn. Linear( 64 , 10 )
)
def forward ( self, x) :
x = self. model( x)
return x
model = torch. load( "seven_9.pth" , map_location= torch. device( 'cpu' ) )
print ( model)
image = torch. reshape( image, ( 1 , 3 , 32 , 32 ) )
model. eval ( )
with torch. no_grad( ) :
output = model( image)
print ( output)
print ( output. argmax( 1 ) )