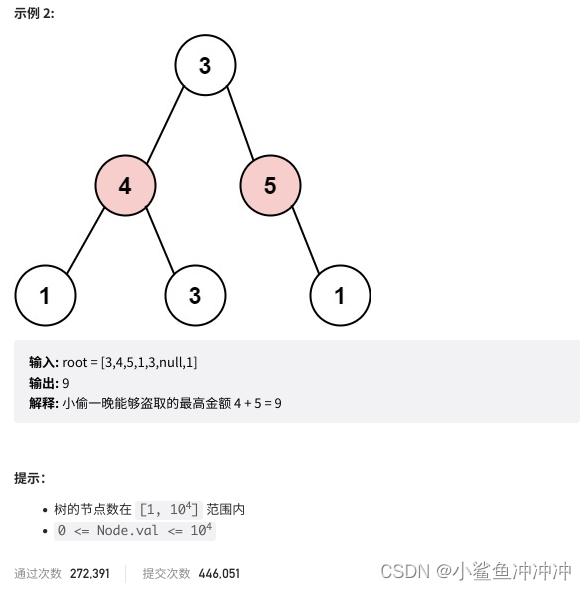
首先放效果图,更直观看到本片是要干嘛的:

如图,就是将大图划分为4×4宫格的,4个部件类的目标框按照固定位置拼图,其中head、body的大图为每个宫格一张图,hand、foot的小图为每个宫格2×2张图(因为hand、foot截下来的图片都普遍很小,为了不resize太多而太模糊)。
每个部件类别的小图拼在一起,实验目标检测算法是否会特定区域关注特定目标从而达到缩小学习空间的目的(为了控制变量,算法本身的位置变换类的数据增强要关闭)。
这里的的部件指的是一类目标,比如head包括head、hat等在头部区域内的目标。每类部件的图片是根据部件截图的方式获得的。
准备
首先是将数据的json格式转化为txt格式的py文件json2txt.py:
import json
import os
import cv2
print(cv2.__version__)
def getBoundingBox(points):
xmin = points[0][0]
xmax = points[0][0]
ymin = points[0][1]
ymax = points[0][1]
for p in points:
if p[0] > xmax:
xmax = p[0]
elif p[0] < xmin:
xmin = p[0]
if p[1] > ymax:
ymax = p[1]
elif p[1] < ymin:
ymin = p[1]
return [int(xmin), int(xmax), int(ymin), int(ymax)]
def json2txt(json_path, txt_path):
json_data = json.load(open(json_path))
img_h = json_data["imageHeight"]
img_w = json_data["imageWidth"]
shape_data = json_data["shapes"]
shape_data_len = len(shape_data)
img_name = os.path.split(json_path)[-1].split(".json")[0]
name = img_name + '.jpg'
data = ''
for i in range(shape_data_len):
lable_name = shape_data[i]["label"]
points = shape_data[i]["points"]
[xmin, xmax, ymin, ymax] = getBoundingBox(points)
if xmin <= 0:
xmin = 0
if ymin <= 0:
ymin = 0
if xmax >= img_w:
xmax = img_w - 1
if ymax >= img_h:
ymax = img_h - 1
b = name + ' ' + lable_name + ' ' + str(xmin) + ' ' + str(ymin) + ' ' + str(xmax) + ' ' + str(ymax)
# print(b)
data += b + '\n'
with open(txt_path + '/' + img_name + ".txt", 'w', encoding='utf-8') as f:
f.writelines(data)
if __name__ == "__main__":
json_path = "/data/cch/yolov5-augment/train/json"
saveTxt_path = "/data/cch/yolov5-augment/train/txt"
filelist = os.listdir(json_path)
for file in filelist:
old_dir = os.path.join(json_path, file)
if os.path.isdir(old_dir):
continue
filetype = os.path.splitext(file)[1]
if(filetype != ".json"): continue
json2txt(old_dir, saveTxt_path)
def main_import(json_path, txt_path):
filelist = os.listdir(json_path)
for file in filelist:
old_dir = os.path.join(json_path, file)
if os.path.isdir(old_dir):
continue
filetype = os.path.splitext(file)[1]
if(filetype != ".json"): continue
json2txt(old_dir, txt_path)
随机取了一个txt文件,查看其格式:
body_21.jpg cloth 51 12 255 270
body_21.jpg hand 50 206 79 257
body_21.jpg hand 195 217 228 269
body_21.jpg other 112 0 194 1
格式:为图片名 类名 x1 y1 x2 y2(为目标框的左上右下角坐标,此txt格式并非yolo训练的darknet格式)。
然后是将数据的txt格式转化为darknet格式的py文件modeTxt.py:
import os
from numpy.lib.twodim_base import triu_indices_from
import pandas as pd
from glob import glob
import cv2
import codecs
def txt2darknet(txt_path, img_path, saved_path):
data = pd.DataFrame()
filelist = os.listdir(txt_path)
for file in filelist:
if not os.path.splitext(file)[-1] == ".txt":
continue
# print(file)
file_path = os.path.join(txt_path, file)
filename = os.path.splitext(file)[0]
imgName = filename + '.jpg'
imgPath = os.path.join(img_path, imgName)
img = cv2.imread(imgPath)
[img_h, img_w, _] = img.shape
data = ""
with codecs.open(file_path, 'r', encoding='utf-8',errors='ignore') as f1:
for line in f1.readlines():
line = line.strip('\n')
a = line.split(' ')
if a[1] == 'other' or a[1] == 'mask' or a[1] == 'del': continue
# if a[1] == 'mouth':
# a[1] = '0'
# elif a[1] == 'wearmask':
# a[1] = '1'
if a[1] == 'head':
a[1] = '0'
elif a[1] == 'hat':
a[1] = '1'
elif a[1] == 'helmet':
a[1] = '2'
elif a[1] == 'eye':
a[1] = '3'
elif a[1] == 'glasses' or a[1] == 'glass':
a[1] = '4'
'''这里根据自己的类别名称及顺序'''
x1 = float(a[2])
y1 = float(a[3])
w = float(a[4]) - float(a[2])
h = float(a[5]) - float(a[3])
# if w <= 15 and h <= 15: continue
center_x = float(a[2]) + w / 2
center_y = float(a[3]) + h / 2
a[2] = str(center_x / img_w)
a[3] = str(center_y / img_h)
a[4] = str(w / img_w)
a[5] = str(h / img_h)
b = a[1] + ' ' + a[2] + ' ' + a[3] + ' ' + a[4] + ' ' + a[5]
# print(b)
data += b + '\n'
with open(saved_path + '/' + filename + ".txt", 'w', encoding='utf-8') as f2:
f2.writelines(data)
print(data)
txt_path = '/data/cch/yolov5/runs/detect/hand_head_resize/labels'
saved_path = '/data/cch/yolov5/runs/detect/hand_head_resize/dr'
img_path = '/data/cch/data/pintu/test/hand_head_resize/images'
if __name__ == '__main__':
txt2darknet(txt_path, img_path, saved_path)
以上两个转换代码都是在拼图当中会调用到。
拼图
下面开始我们的拼图代码:
'''
4*4
左上五个 1 2 3 5 6 head
左下五个 9 10 11 13 14 body
右上三个 4 7 8 各划分4宫格 hand
右下三个 12 15 16 各划分4宫格 foot
针对于部件拼图,每个部件一个文件夹,image和json的地址都取总地址
'''
import sys
import codecs
import random
import PIL.Image as Image
import os
import cv2
sys.path.append("/data/cch/拼图代码/format_transform")
import json2txt
import modeTxt
import shutil
# 定义图像拼接函数
def image_compose(imgsize, idx, ori_tmp, num, save_path, gt_resized_path, flag):
to_image = Image.new('RGB', (imgsize, imgsize)) #创建一个新图
new_name = ""
for y in range(idx):
for x in range(idx):
index = y*idx + x
if index >= len(ori_tmp):
break
open_path = [gt_resized_path, small_pintu_foot, small_pintu_hand]
for op in open_path:
if os.path.exists(os.path.join(op, ori_tmp[index])):
to_image.paste(Image.open(os.path.join(op, ori_tmp[index])), (
int(x * (imgsize / idx)), int(y * (imgsize / idx))))
break
else:
continue
new_name = os.path.join(save_path, flag + str(num) + ".jpg")
to_image.save(new_name) # 保存新图
# print(new_name)
return new_name
def labels_merge(imgsize, idx, ori_tmp, new_name, txt_resized_path, txt_pintu_path):
data = ""
for y in range(idx):
for x in range(idx):
index = y*idx + x
if index >= len(ori_tmp):
break
txt_path = os.path.join(txt_resized_path, ori_tmp[index].split(".")[0] + ".txt")
if not os.path.exists(txt_path):
txt_path = os.path.join(txt_pintu_path_small, ori_tmp[index].split(".")[0] + ".txt")
try:
os.path.exists(txt_path)
except:
print(txt_path, "file not exists!")
if os.path.exists(txt_path):
with codecs.open(txt_path, 'r', encoding='utf-8',errors='ignore') as f1:
for line in f1.readlines():
line = line.strip('\n')
a = line.split(' ')
a[2] = str(float(a[2]) + (x * (imgsize / idx)))
a[3] = str(float(a[3]) + (y * (imgsize / idx)))
a[4] = str(float(a[4]) + (x * (imgsize / idx)))
a[5] = str(float(a[5]) + (y * (imgsize / idx)))
b =a[0] + ' ' + a[1] + ' ' + a[2] + ' ' + a[3] + ' ' + a[4] + ' ' + a[5]
data += b + "\n"
write_path = os.path.join(txt_pintu_path, os.path.splitext(new_name)[0].split("/")[-1] + ".txt")
with open(write_path, 'w', encoding='utf-8') as f2:
f2.writelines(data)
def pintu2black(txt_pintu_path, save_path, to_black_num, to_black_min_num, label_black):
files = os.listdir(txt_pintu_path)
for file in files:
img_path = os.path.join(save_path, os.path.splitext(file)[0] + ".jpg")
img_origal = cv2.imread(img_path)
data = ""
with codecs.open(txt_pintu_path+"/"+file, encoding="utf-8", errors="ignore") as f1:
for line in f1.readlines():
line = line.strip("\n")
a = line.split(" ")
xmin = int(eval(a[2]))
ymin = int(eval(a[3]))
xmax = int(eval(a[4]))
ymax = int(eval(a[5]))
if ((xmax - xmin < to_black_num) and (ymax - ymin < to_black_num)) or \
((xmax - xmin < to_black_min_num) or (ymax - ymin < to_black_min_num)) \
or a[1] in label_black:
img_origal[ymin:ymax, xmin:xmax, :] = (0, 0, 0)
cv2.imwrite(img_path, img_origal)
line = ""
if line:
data += line + "\n"
with open(txt_pintu_path+"/"+file, 'w', encoding='utf-8') as f2:
f2.writelines(data)
# print(data)
def gt_distribute(images_path, ori, gt_resized_path, txt_path, gt_range):
image_names = os.listdir(images_path)
for image_name in image_names:
if not os.path.splitext(image_name)[-1] == ".jpg":
continue
imgPath = os.path.join(images_path, image_name)
img = cv2.imread(imgPath)
gt_resized_name = gt_resize(gt_resized_path, txt_path, image_name, img, gt_range, 2)
ori.append(gt_resized_name)
def gt_resize(gt_resized_path, txt_path, image_name, img, img_size, x):
if not os.path.exists(gt_resized_path):
os.mkdir(gt_resized_path)
[img_h, img_w, _] = img.shape
img_read = [0, 0, 0]
if img_h < img_w:
precent = img_size / img_w
img_read = cv2.resize(img, (img_size, int(img_h * precent)), interpolation=cv2.INTER_CUBIC)
else:
precent = img_size / img_h
img_read = cv2.resize(img, (int(img_w * precent), img_size), interpolation=cv2.INTER_CUBIC)
img_resized = gt_resized_path + "/" + image_name.split(".")[0] + "_" + str(x) + ".jpg"
cv2.imwrite(img_resized, img_read)
txt_name = txt_path + "/" + image_name.split(".")[0] + ".txt"
txt_resized_name = gt_resized_path + "/" + image_name.split(".")[0] + "_" + str(x) + ".txt"
if os.path.exists(txt_name):
data = ""
with codecs.open(txt_name, 'r', encoding='utf-8',errors='ignore') as f1:
for line in f1.readlines():
line = line.strip('\n')
a = line.split(' ')
a[2] = str(float(a[2]) * precent)
a[3] = str(float(a[3]) * precent)
a[4] = str(float(a[4]) * precent)
a[5] = str(float(a[5]) * precent)
b =a[0] + ' ' + a[1] + ' ' + a[2] + ' ' + a[3] + ' ' + a[4] + ' ' + a[5]
data += b + "\n"
with open(txt_resized_name, 'w', encoding='utf-8') as f2:
f2.writelines(data)
return img_resized.split("/")[-1]
def pintu(idx, ori, img_threshold, imgsize, save_path, gt_resized_path, txt_pintu_path, flag):
num = 0
if flag != "wear_" :
random.shuffle(ori)
picknum = idx * idx
index = 0
while num < int(img_threshold):
ori_tmp = []
# random.sample(ori, picknum)
if index >= len(ori) and flag != "wear_" :
random.shuffle(ori)
index = 0
ori_tmp = ori[index:index+picknum]
index = index + picknum
new_name = image_compose(imgsize, idx, ori_tmp, num, save_path, gt_resized_path, flag)
labels_merge(imgsize, idx, ori_tmp, new_name, gt_resized_path, txt_pintu_path)
ori_tmp.clear()
num += 1
print(flag, num, len(ori))
if __name__ == "__main__":
images_path = '/data/cch/test' # 图片集地址
json_path = "/data/cch/test"
save_path = '/data/cch/save'
if not os.path.exists(save_path):
os.mkdir(save_path)
else:
shutil.rmtree(save_path)
os.mkdir(save_path)
tmp = "/data/cch/pintu_data/save/tmp"
if not os.path.exists(tmp):
os.mkdir(tmp)
else:
shutil.rmtree(tmp)
os.mkdir(tmp)
gt_resized_path = os.path.join(tmp, "gt_resized")
txt_path = os.path.join(tmp, "txt") # 原数据txt
txt_pintu_path = os.path.join(tmp, "txt_pintu")
txt_pintu_path_small = os.path.join(tmp, "txt_pintu_small")
small_pintu_foot = os.path.join(tmp, "pintu_foot")
small_pintu_hand = os.path.join(tmp, "pintu_hand")
os.mkdir(txt_path)
os.mkdir(txt_pintu_path)
os.mkdir(txt_pintu_path_small)
os.mkdir(small_pintu_foot)
os.mkdir(small_pintu_hand)
label_black = ["other"]
imgsize = 416
to_black_num = 15
to_black_min_num = 5
gt_range_large = int(imgsize / 4)
gt_range_small = int(imgsize / 8)
json_dirs = os.listdir(json_path)
for json_dir in json_dirs:
json_ori_dir = os.path.join(json_path, json_dir)
txt_dir = os.path.join(txt_path, json_dir)
os.mkdir(txt_dir)
json2txt.main_import(json_ori_dir, txt_dir)
# foot
ori_foot = []
foot_images = os.path.join(images_path, "foot")
foot_txt = os.path.join(txt_path, "foot")
gt_distribute(foot_images, ori_foot, gt_resized_path, foot_txt, gt_range_small)
img_threshold = int(len(ori_foot) / 4 * 1.6)
idx = 2
pintu(idx, ori_foot, img_threshold, int(imgsize/4), small_pintu_foot, gt_resized_path,\
txt_pintu_path_small, "foot_")
# hand
ori_hand = []
hand_images = os.path.join(images_path, "hand")
hand_txt = os.path.join(txt_path, "hand")
gt_distribute(hand_images, ori_hand, gt_resized_path, hand_txt, gt_range_small)
img_threshold = int(len(ori_hand) / 4 * 1.6)
idx = 2
pintu(idx, ori_hand, img_threshold, int(imgsize/4), small_pintu_hand, gt_resized_path,\
txt_pintu_path_small, "hand_")
# head
ori_head = []
head_images = os.path.join(images_path, "head")
head_txt = os.path.join(txt_path, "head")
gt_distribute(head_images, ori_head, gt_resized_path, head_txt, gt_range_large)
# body
ori_body = []
body_images = os.path.join(images_path, "body")
body_txt = os.path.join(txt_path, "body")
gt_distribute(body_images, ori_body, gt_resized_path, body_txt, gt_range_large)
# pintu
ori = []
idx = 4
ori_foot = os.listdir(small_pintu_foot)
ori_hand = os.listdir(small_pintu_hand)
random.shuffle(ori_foot)
random.shuffle(ori_hand)
random.shuffle(ori_head)
random.shuffle(ori_body)
[idx_hand, idx_foot, idx_head, idx_body] = [0, 0, 0, 0]
img_threshold = int((len(ori_hand) + len(ori_foot) + len(ori_head) + len(ori_body)) / (idx*idx) * 1.5)
while True:
for i in range(idx*idx):
if i in [0,1,2,4,5]:
if idx_head >= len(ori_head):
random.shuffle(ori_head)
idx_head = 0
ori.append(ori_head[idx_head])
idx_head += 1
elif i in [3,6,7]:
if idx_hand >= len(ori_hand):
random.shuffle(ori_hand)
idx_hand = 0
ori.append(ori_hand[idx_hand])
idx_hand += 1
elif i in [8,9,10,12,13]:
if idx_body >= len(ori_body):
random.shuffle(ori_body)
idx_body = 0
ori.append(ori_body[idx_body])
idx_body += 1
elif i in [11,14,15]:
if idx_foot >= len(ori_foot):
random.shuffle(ori_foot)
idx_foot = 0
ori.append(ori_foot[idx_foot])
idx_foot += 1
if int(len(ori)/(idx*idx)) > img_threshold:
break
pintu(idx, ori, int(len(ori)/(idx*idx)), imgsize, save_path, gt_resized_path,\
txt_pintu_path, "wear_")
pintu2black(txt_pintu_path, save_path, to_black_num, to_black_min_num, label_black)
# input()
modeTxt.txt2darknet(txt_pintu_path, save_path, save_path)
shutil.rmtree(tmp)
这里的输入地址是4个部件的总地址,如图: