基于IF的网站异常流量检测
小P:最近渠道好多异常数据啊,有没有什么好的办法可以识别这些异常啊
小H:箱线图、 3 σ 3\sigma 3σ 都可以啊
小P:那我需要把每个特征都算一遍吗?不是数值的怎么算啊?
小H:你说的是高维数据啊。。。那就只能用算法去检测了,可以尝试IF(孤立森林)算法
IF全称为Isolation Forest,正如字面含义,在一片森林(数据集)中找到被孤立的点,将其识别为异常值。
数据探索
# 导入库
from sklearn.preprocessing import OrdinalEncoder
from sklearn.ensemble import IsolationForest
import pandas as pd
import matplotlib.pyplot as plt
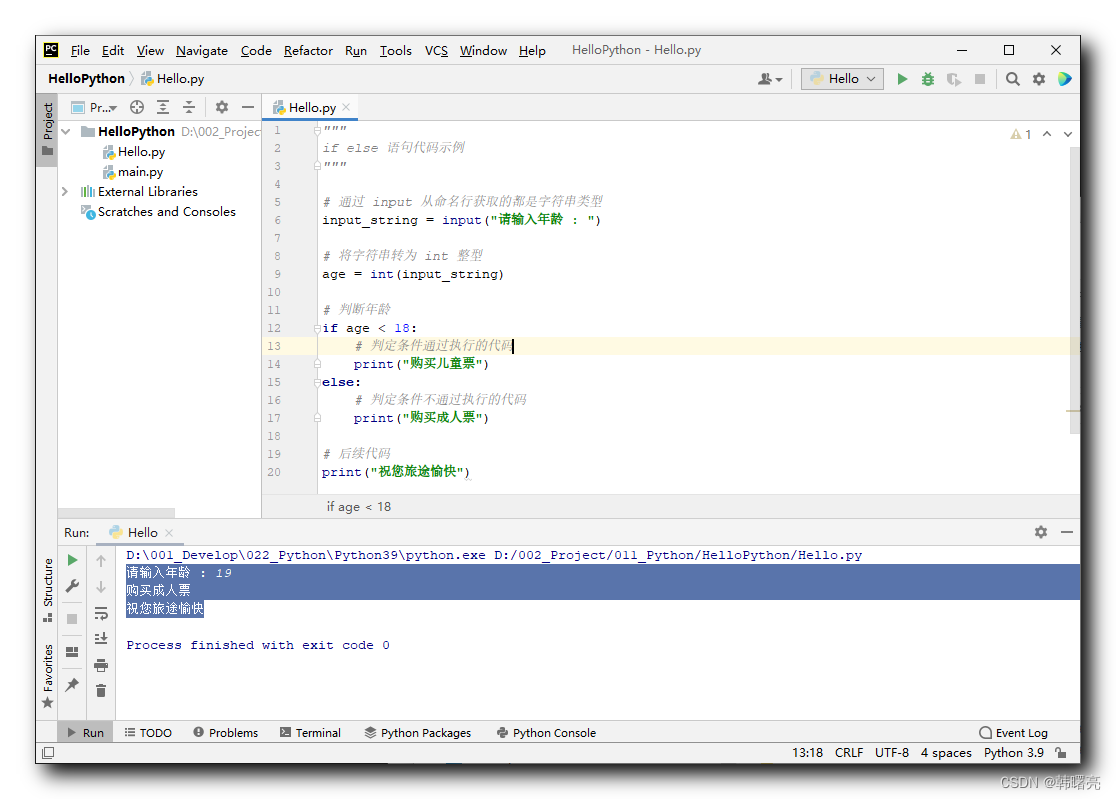
from mpl_toolkits.mplot3d import Axes3D # 导入3D样式库
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-异常检测】自动获取~
# 读取数据
raw_data = pd.read_csv('outlier.txt',sep=',') # 读取数据
raw_data.head()

特征工程
# 去除全部为空的特征
data_dropna = raw_data.dropna(axis='columns',how='all')
data_dropna = data_dropna.drop(['clientId'],axis=1)
data_dropna.shape
(10492, 44)
# 填充NA列
# 找到NA列
cols_is_na = data_dropna.isnull().any()
na_cols = [cols_is_na.index[ind]
for ind, na_result in enumerate(cols_is_na) if na_result == True]
print(data_dropna[na_cols].dtypes)
# 填充NA列
print(data_dropna[na_cols].head())
#print(type(data_dropna[na_cols].iloc[2,3]))
fill_rules = {'newVisits': 0, 'pageviews': 0, 'isVideoAd': False, 'isTrueDirect': False}
data_fillna = data_dropna.fillna(fill_rules)
print(data_fillna.isnull().any().sum())
newVisits float64
pageviews float64
isVideoAd object
isTrueDirect object
dtype: object
newVisits pageviews isVideoAd isTrueDirect
0 1.0 11.0 NaN NaN
1 NaN 9.0 NaN NaN
2 NaN 11.0 NaN True
3 NaN 10.0 NaN NaN
4 NaN 6.0 NaN True
0
# 拆分数值特征和字符串特征
str_or_num = (data_fillna.dtypes=='object')
str_cols = [str_or_num.index[ind]
for ind, na_result in enumerate(str_or_num) if na_result == True]
string_data = data_fillna[str_cols]
num_data = data_fillna[[i for i in str_or_num.index if i not in str_cols]]
# 分类特征转换为数值型索引
model_oe = OrdinalEncoder()
string_data_con = model_oe.fit_transform(string_data)
string_data_pd = pd.DataFrame(string_data_con,columns=string_data.columns)
# 合并原数值型特征和onehotencode后的特征
feature_merge = pd.concat((num_data,string_data_pd),axis=1)
数据建模
# 异常点检测
model_isof = IsolationForest(n_estimators=20, n_jobs=1)
outlier_label = model_isof.fit_predict(feature_merge)
# 异常结果汇总
outlier_pd = pd.DataFrame(outlier_label,columns=['outlier_label'])
data_merge = pd.concat((data_fillna,outlier_pd),axis=1)
outlier_count = data_merge.groupby(['outlier_label'])['visitNumber'].count()
print('outliers: {0}/{1}'.format(outlier_count.iloc[0], data_merge.shape[0])) # 输出异常的结果数量
outliers: 1958/10492
结果展示
# 统计每个渠道的异常情况
def cal_sample(df):
data_count = df.groupby(['source'],as_index=False)['outlier_label'].count()
return data_count.sort_values(['outlier_label'],ascending=False)
# 取出异常样本
outlier_source = data_merge[data_merge['outlier_label']==-1]
outlier_source_sort = cal_sample(outlier_source)
# 取出正常样本
normal_source = data_merge[data_merge['outlier_label']==1]
normal_source_sort = cal_sample(normal_source)
# 合并总样本
source_merge = pd.merge(outlier_source_sort,normal_source_sort,on='source',how='outer')
source_merge = source_merge.rename(index=str, columns={'outlier_label_x':'outlier_count','outlier_label_y':'normal_count'})
source_merge=source_merge.fillna(0)
# 计算异常比例
source_merge['total_count'] = source_merge['outlier_count']+source_merge['normal_count']
source_merge['outlier_rate'] = source_merge['outlier_count']/(source_merge['total_count'])
print(source_merge.sort_values(['total_count'],ascending=False).head())
source outlier_count normal_count total_count outlier_rate
0 google 731.0 3749.0 4480.0 0.163170
1 (direct) 441.0 2567.0 3008.0 0.146609
6 webgains 62.0 571.0 633.0 0.097946
4 shareasale 98.0 381.0 479.0 0.204593
2 linkshare 124.0 297.0 421.0 0.294537
总结
IF使用起来很方便,因此在高维数据中识别异常值可以考虑它~
共勉~