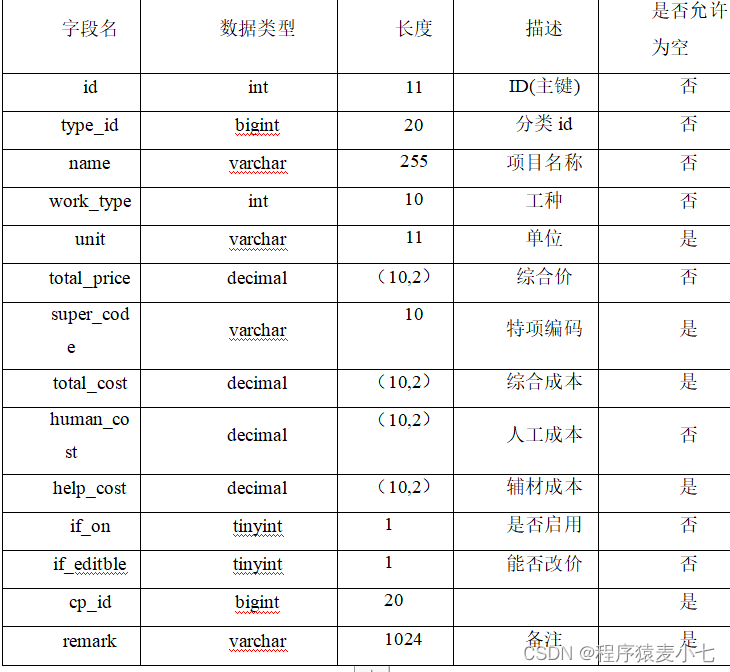
Jupyter Notebook 教程: How to Build a Video Deduplication System
「视频去重」可以在海量的视频数据中实现侵权片段或者删除掉重复冗余的内容 。随着抖音、快手、Bilibili 等视频平台的兴起和火爆,类似视频这样的非结构化数据在数量上有了极大的增长。
 |  |
视频平台存储着大量的视频资源,但其中会包含很多重复的视频数据。视频资源的冗余会带来两个问题:
-
重复的视频会占用大部分的存储空间。据统计,一个未压缩的时长 1 分钟的 4k 视频可能需要 40GB 的存储空间。
-
重复的视频资源不利于用户的体验。视频平台通常会利用推荐算法将视频推送给用户,然而当视频资源重复时,用户会被多次推送高度相似、甚至完全相同的视频内容。
因此,为了更有效地管理视频和提升用户体验,「视频去重」是视频平台必不可少的一项工作!
这篇文章将教你如何利用 Milvus[1] 和 Towhee[2] 搭建一个粗粒度「视频去重」系统!该系统的核心思路就是通过 Towhee 利用预训练的神经网络模型提取视频的特征向量,并将其存储在向量数据库 Milvus 中,然后比较查询对象的特征向量与数据库中的向量,从而实现判断视频之间的相似性。
#01
安装工具包

在开始之前,我们需要安装环境所依赖的包。我们用到了以下工具:
-
Towhee : 用于构建模型推理流水线的框架,对于新手非常友好。
-
Milvus : 用于存储向量并创建索引的数据库,简单好上手
-
Pillow:图像处理常用的 Python 库。
-
Pandas:一个基于 Python 的快速、灵活且易于使用的开源数据分析和操作工具。
python -m pip install -q pymilvus towhee pillow pandas ipython
#02
准备数据集
我们在这里选用了 VCDB[3] core dataset 的子集作为我们的数据。VCDB 是一个常用于「视频去重」任务的数据集,包含了超过 10 万个 Web 视频,以及 9,000 多个手动找到的复制片段对。
该数据集由两部分组成:VCDB core dataset 和 VCDB background dataset。 其中 core dataset 的数据来自在 YouTube 和 MetaCafe,选自 28 个精心挑选的查询,共计 528 个视频,总时长大约 27 小时。 经过大量的人工筛选,数据集中收录了 9236 对部分视频的副本。 这些副本对比原视频经过了不同的变换形式,包括“插入图案”、“录像”、“比例变化”、“画中画”等。
我们从中选取的视频描述了 20 个事件,每个事件包含大约 5 个内容相同或相似的视频,总共约占 1.3G。
首先,我们下载并解压数据:
curl -L https://github.com/towhee-io/examples/releases/download/data/VCDB_core_sample.zip -O
unzip -q -o VCDB_core_sample.zip
然后,我们利用以下代码简单地观察这些视频:
import random
from pathlib import Path
import torch
import pandas as pd
random.seed(6)
root_dir = './VCDB_core_sample'
min_sample_num = 5
sample_folder_num = 20
all_video_path_lists = []
all_video_path_list = []
df = pd.DataFrame(columns=('path','event','id'))
query_df = pd.DataFrame(columns=('path','event','id'))
video_idx = 0
for i, mid_dir_path in enumerate(Path(root_dir).iterdir()):
if i >= sample_folder_num:
break
if mid_dir_path.is_dir():
path_videos = list(Path(mid_dir_path).iterdir())
if len(path_videos) < min_sample_num:
print('len(path_videos) < min_sample_num, continue.')
continue
sample_video_path_list = random.sample(path_videos, min_sample_num)
all_video_path_lists.append(sample_video_path_list)
all_video_path_list += [str(path) for path in sample_video_path_list]
for j, path in enumerate(sample_video_path_list):
video_idx += 1
if j == 0:
query_df = query_df.append(pd.DataFrame({'path': [str(path)],'event':[path.parent.stem],'id': [video_idx]}),ignore_index=True)
df = df.append(pd.DataFrame({'path': [str(path)],'event':[path.parent.stem],'id': [video_idx]}),ignore_index=True)
all_sample_video_dicts = []
for i, sample_video_path_list in enumerate(all_video_path_lists):
anchor_video = sample_video_path_list[0]
pos_video_path_list = sample_video_path_list[1:]
neg_video_path_lists = all_video_path_lists[:i] + all_video_path_lists[i + 1:]
neg_video_path_list = [neg_video_path_list[0] for neg_video_path_list in neg_video_path_lists]
all_sample_video_dicts.append({
'anchor_video': anchor_video,
'pos_video_path_list': pos_video_path_list,
'neg_video_path_list': neg_video_path_list
})
id2event = df.set_index(['id'])['event'].to_dict()
id2path = df.set_index(['id'])['path'].to_dict()
df_csv_path = 'video_info.csv'
query_df_csv_path = 'query_video_info.csv'
df.to_csv(df_csv_path)
query_df.to_csv(query_df_csv_path)
df
以上代码返回了一个 95 x 3 的表格,其中第一列是视频路径(path)、第二列是视频描述的事件(event)、第三列是视频编号(id):

我们将数据集中的视频分为基准视频(Anchor video)、目标视频(positive video)、非目标视频(negative video),并以 GIF 的形式展示:
random_video_pair = random.sample(all_sample_video_dicts, 1)[0]
neg_sample_num = min(5, sample_folder_num)
anchor_video = random_video_pair['anchor_video']
anchor_video_event = anchor_video.parent.stem
pos_video_list = random_video_pair['pos_video_path_list']
pos_video_list_events = [path.parent.stem for path in pos_video_list]
neg_video_list = random_video_pair['neg_video_path_list'][:neg_sample_num]
neg_video_list_events = [path.parent.stem for path in neg_video_list]
show_video_list = [str(anchor_video)] + [str(path) for path in pos_video_list] + [str(path) for path in neg_video_list]
# print(show_video_list)
caption_list = ['anchor video: ' + anchor_video_event] + ['positive video ' + str(i + 1) for i in range(len(pos_video_list))] + ['negative video ' + str(i + 1) + ': ' + neg_video_list_events[i] for i in range(len(neg_video_list))]
print(caption_list)
tmpdirname = './tmp_gifs'
display_gifs_from_video(show_video_list, caption_list, tmpdirname=tmpdirname)
比如我们选取电影《拯救大兵瑞恩》(‘saving_private_ryan_omaha_beach’)中的片段作为基准视频,数据集中共有 4 个目标视频,5 个非目标视频:
['anchor video: saving_private_ryan_omaha_beach',
'positive video 1', 'positive video 2', 'positive video 3', 'positive video 4',
'negative video 1: obama_kicks_door',
'negative video 2: the_legend_of_1900_magic_waltz',
'negative video 3: kennedy_assassination_slow_motion',
'negative video 4: scent_of_woman_tango',
'negative video 5: bolt_beijing_100m']
(请注意,我们将仅变化比例的视频也视作重复视频。)

anchor video: saving_private_ryan_omaha_beach
 |  |  |
positive videos
 |  |  |
negative videos
#03
创建集合
在创建 Milvus 合集之前,请确保你已经安装并启动了 Milvus[4] 。Milvus 是处理非结构化数据的好手,它能在后续的相似度检索和近邻搜索中发挥至关重要的作用。然后,我们在 Milvus 数据库中创建一个「视频去重」的集合(Collection),配置如下:
- 数据包含 2 列(Fields):
-
id:主键,唯一且不重复 -
embedding:向量数据
-
-
创建索引(Index)可以加速检索:基于
embedding列创建 IVF_FLAT[5] 索引,使用参数"nlist":2048 -
相似度衡量方式(Metric):
L2欧式距离,越小表示越相近
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
connections.connect(host='127.0.0.1', port='19530')
def create_milvus_collection(collection_name, dim):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='ids', is_primary=True, auto_id=False),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, descrition='embedding vectors', dim=dim)
]
schema = CollectionSchema(fields=fields, description='video deduplication')
collection = Collection(name=collection_name, schema=schema)
# create IVF_FLAT index for collection.
index_params = {
'metric_type':'L2', #IP
'index_type':"IVF_FLAT",
'params':{"nlist":2048}
}
collection.create_index(field_name="embedding", index_params=index_params)
return collection
collection = create_milvus_collection('video_deduplication', 1024)
#04
插入向量
在这一环节,我们会用到预训练好的 DnS[6](distill and select) student 模型提取视频的特征向量,随后将视频向量插入到事先创建好的 Milvus 集合中。
DnS 是一套高效检索和筛选视频的方案,首先对细粒度但复杂的 teacher 模型进行预训练,然后在 teacher 模型的引导下,用更多数据对粗粒度但更轻便的 student 模型进行训练。根据原论文的数据,这个方法训练出的 student 模型性能表现出色,不仅在速度上比 teacher 模型快了 20 倍,在内存上也减少了 240 倍。在这里例子中,我们仅使用预训练好 student 模型搭建一个视频级别(粗粒度)的「视频去重」系统,因此每个视频会被转换成一个向量,代表了粗粒度的视频特征。
详情可参考论文原文:https://arxiv.org/abs/2106.13266
我们利用 Towhee 提供的 DC API[7] 以及算子 distill_and_select[8] 搭建一个流水线,将视频库里的每个视频都转换成一个向量,并存入 Milvus 集合中:
import os
import towhee
from towhee import dc
device = 'cuda'
# device = 'cpu'
dc = (towhee.read_csv('path_to_csv.csv').unstream()
.runas_op['id', 'id'](func=lambda x: int(x "'id', 'id'"))
.video_decode.ffmpeg['path', 'frames'](
start_time=0.0,
end_time=60.0,
sample_type='time_step_sample',
args={'time_step': 1})
.runas_op['frames', 'frames'](func=lambda x: [y for y in x] "'frames', 'frames'")
.distill_and_select['frames', 'vec'](
model_name='cg_student',
device=device)
.to_milvus['id', 'vec'](collection=collection, batch=30 "'id', 'vec'")
)
我们在这里对上面的代码做一些说明:
-
towhee.read_csv(df_csv_path):从 csv 文件中读取数据 -
.runas_op['id', 'id'](func=lambda x: int(x "'id', 'id'")):将 csv 中id列的数据类型从str转换为int -
.video_decode.ffmpeg: 每隔一秒对视频进行统一的二次采样,得到对应的视频帧列表 -
.distill_and_select['frames', 'vec'](model_name='cg_student' "'frames', 'vec'"):使用 DnS 中的粗粒度 student 模型从视频中提取特征向量 -
.to_milvus['id', 'vec'](collection=collection, batch=30 "'id', 'vec'"):将视频向量30个一批(batch=30)存入到 Milvus 集合中
print('Total number of inserted data is {}.'.format(collection.num_entities))
最后,我们存储到 Milvus 集合中的向量共有 95 个:Total number of inserted data is 95.
#05
查询与评估
当成功将视频库中的视频都转换成向量存储到 Milvus 集合后,我们就可以进行查询了:输入一个视频,查询视频库中与其重复的视频。
dc = (
towhee.read_csv('query_video_csv.csv').unstream()
.runas_op['event', 'ground_truth_event'](func=lambda x:[x] "'event', 'ground_truth_event'")
.video_decode.ffmpeg['path', 'frames'](
start_time=0.0,
end_time=60.0,
sample_type='time_step_sample',
args={'time_step': 1})
.runas_op['frames', 'frames'](func=lambda x: [y for y in x] "'frames', 'frames'")
.distill_and_select['frames', 'vec'](
model_name='cg_student',
device=device)
.milvus_search['vec', 'topk_raw_res'](
collection=collection,
limit=min_sample_num)
.runas_op['topk_raw_res', 'topk_events'](
func=lambda res: [id2event[x.id] for i, x in enumerate(res)])
.runas_op['topk_raw_res', 'topk_path'](
func=lambda res: [id2path[x.id] for i, x in enumerate(res)])
)
dc_list = dc.to_list()
# random_idx = random.randint(0, len(dc_list) - 1)
sample_num = 3
sample_idxs = random.sample(range(len(dc_list)), sample_num)
def get_query_and_predict_videos(idx):
query_video = id2path[int(dc_list[idx].id)]
print('query_video =', query_video)
predict_topk_video_list = dc_list[idx].topk_path[1:]
print('predict_topk_video_list =', predict_topk_video_list)
return query_video, predict_topk_video_list
dsp_res_list = []
for idx in sample_idxs:
query_video, predict_topk_video_list = get_query_and_predict_videos(idx)
show_video_list = [query_video] + predict_topk_video_list
caption_list = ['query video: ' + Path(query_video).parent.stem] + ['result{0} video'.format(i) for i in range(len(predict_topk_video_list))]
dsp_res_list.append(display_gifs_from_video(show_video_list, caption_list, tmpdirname=tmpdirname))
我们随机查看三个查询的结果:左侧是我们查询的视频,右侧则是系统检测到的重复视频:
| query_video | predict_topk_video_list |
|---|---|
| VCDB_core_sample/t-mac_13_points_in_35_seconds/5df28e18b3d8fbdc0f4cd07ef5aefcdc1b4f8d42.flv | ['VCDB_core_sample/t-mac_13_points_in_35_seconds/e4b443e64c27a3364d16db8e11e6e85f2d3fd7ed.flv', 'VCDB_core_sample/t-mac_13_points_in_35_seconds/b61905d41276ccf2af59d4985158f8b1ce1d4990.flv', 'VCDB_core_sample/t-mac_13_points_in_35_seconds/3d0a3002441f682c7124806eb9b92c677af2ee9e.flv', 'VCDB_core_sample/t-mac_13_points_in_35_seconds/2bdf8029b38735a992a56e32cfc81466eea81286.flv'] |
| VCDB_core_sample/obama_kicks_door/14c81d68b80d04743a107d4de859cb4724ccc2c1.flv | ['VCDB_core_sample/obama_kicks_door/f26a39de8e8ec290703f4937977fc17322974748.flv', 'VCDB_core_sample/obama_kicks_door/4df943d4903333df61bb3854d47365edf3076b5b.flv', 'VCDB_core_sample/obama_kicks_door/df0c9e9664cfa6720c94e13eae35ddb7a9b5b927.flv', 'VCDB_core_sample/president_obama_takes_oath/e29e65d0e362b8e7d450d833227ea3c0f5f65f12.flv'] |
| VCDB_core_sample/troy_achilles_and_hector/ee417a6b882853ffcd3f78b380b0205a9411f4d6.flv | ['VCDB_core_sample/troy_achilles_and_hector/0b3f9e88e5ab73e19dc4d1a32115ea3457867128.flv', 'VCDB_core_sample/troy_achilles_and_hector/6fe097a963673b26c62f6ff6d6151d383c194b9d.flv', 'VCDB_core_sample/troy_achilles_and_hector/a89a3193db3354c059dfe4effac05c4667f9c239.flv', 'VCDB_core_sample/troy_achilles_and_hector/ccc879ecfb35a1a77667dd8357b71a930c19092c.flv'] |
我们先查看第一个视频的结果:第一个查询的视频选取自 NBA 的球员 Tracy McGrady 在 35 秒内狂夺 13 分的片段,我们的系统检测出了 4 个重复的视频。
dsp_res_list[0]

 |  |  |  |
query for t-mac_13_points_in_35_seconds
我们接着再看第二个视频的检测结果:第二个视频选取自奥巴马的一场演讲视频。令人惊讶的是,在演讲结束后,他生气地踹了门。可以发现第四个结果并不包含奥巴马这段演讲的片段,而是一段奥巴马在室外的演讲视频。
dsp_res_list[1]

 |  |  |  |
query for obama_kicks_door
最后,我们看第三个视频的检测结果:第三个视频出自 2004 年的一部名叫 Troy 的电影中 Hector 和 Achilles 的对决片段。
dsp_res_list[2]

 |  |  |  |
query for troy_achilles_and_hector
从上面的结果可以发信,我们的「视频去重」系统都能准确地查找出相似或重复的视频!找到相似的视频片段后,我们可以自行决定是否删除,是不是很方便呢?
接下来,我们将使用 mAP@topk 评估这个「视频去重」系统。我们利用目标结果ground_truth_event和检测结果topk_events对系统进行评估:
benchmark = (
dc.with_metrics(['mean_average_precision',])
.evaluate['ground_truth_event', 'topk_events'](name='map_at_k' "'ground_truth_event', 'topk_events'")
.report()
)
在本文选取的数据上,我们可以得到 mAP@top5 大约是 97 %:map_at_k:0.973977 这表明我们的「视频去重」系统取得了很高的分数!
#06
总结
在今天的这篇文章中,我们构建了一个简单的「视频去重」系统,这个系统可以帮助我们查找到重复的视频片段,减少存储空间的占用以及在个性化推荐视频时提升用户的体验。然而这个系统仅限于粗粒度的去重,无法实现更精细的识别和检测。比如视频重复片段占比较小的情况下,该系统会因为受到大量的不重复片段干扰而检测失败。那么如何解决这种情况,实现更精细的视频去重呢?我们会在下一篇文章中揭晓,敬请期待!
参考资料
[1]
Milvus: https://milvus.io/
[2]
Towhee: https://towhee.io/
[3]
VCDB: https://fvl.fudan.edu.cn/dataset/vcdb/list.htm
[4]
Milvus: https://milvus.io/docs/v2.0.x/install_standalone-docker.md
[5]
IVF_FLAT: https://link.zhihu.com/?target=https://milvus.io/docs/v2.0.x/index.md#IVF_FLAT
[6]
DnS: https://arxiv.org/abs/2106.13266
[7]
DC API: https://towhee.readthedocs.io/en/main/index.html
[8]
distill_and_select: https://towhee.io/towhee/distill-and-select

![[附源码]计算机毕业设计JAVA学生量化考核管理系统](https://img-blog.csdnimg.cn/4bfc93ece1fc425eb82c09fc58e3289b.png)





![[激光原理与应用-29]:典型激光器 -1- 固体激光器](https://img-blog.csdnimg.cn/img_convert/3c68ef503e77263219223b884a3937f7.png)