文章目录
- 一、准备本地系统文件
- 二、把文件上传到HDFS
- 三、启动HDFS服务
- 四、启动Spark服务
- 五、启动Spark Shell
- 六、映射算子案例
- 任务1、将rdd1每个元素翻倍得到rdd2
- 任务2、将rdd1每个元素平方得到rdd2
- 任务3、利用映射算子打印菱形
- IDEA里创建项目实现
- 七、过滤算子案例
- 任务1、过滤出列表中的偶数
- 任务2、过滤出文件中包含spark的行
一、准备本地系统文件
- 在
/home目录里创建words.txt 

二、把文件上传到HDFS
- 将
words.txt上传到HDFS系统的/park目录里

- 说明:
/park是在上一讲我们创建的目录
三、启动HDFS服务
- 执行命令:
start-dfs.sh
四、启动Spark服务
- 执行命令:
start-all.sh
五、启动Spark Shell
-执行命令:spark-shell --master spark://master:7077

六、映射算子案例
- 预备工作:创建一个
RDD - rdd1 - 执行命令:
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6))

任务1、将rdd1每个元素翻倍得到rdd2
- 对rdd1应用map()算子,将rdd1中的每个元素平方并返回一个名为rdd2的新RDD

- 其实,利用神奇占位符_可以写得更简洁

- rdd1和rdd2中实际上没有任何数据,因为parallelize()和map()都为转化算子,调用转化算子不会立即计算结果。

- 若需要查看计算结果,则可使用行动算子collect()。(collect是采集或收集之意)

任务2、将rdd1每个元素平方得到rdd2
- 方法一、采用普通函数作为参数传给map()算子

- 方法二、采用下划线表达式作为参数传给map()算子

- rdd2的元素变成了双精度实数,得转化成整数

任务3、利用映射算子打印菱形
- 右半菱形
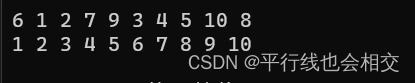
val rdd = sc.makeRDD(List(1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 19, 17, 15, 13, 11, 9, 7, 5, 3, 1))
val rdd1 = rdd.map(“*” * _)
rdd1.collect.foreach(println)

IDEA里创建项目实现
- 创建Maven项目 -
SparkRDDDemo

- 将java目录改成scala目录

- 在pom.xml文件里添加相关依赖和设置源程序目录
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.hw.rdd</groupId>
<artifactId>SparkRDDDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 添加日志属性文件

log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 创建hdfs-site.xml文件,允许客户端访问集群数据节点

<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<description>only config in clients</description>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
</configuration>
- 创建net.xxr.rdd.day01包

- 在net.xxr.rdd.day01包里创建Example01单例对象

package net.xxr.rdd.day01
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
import scala.io.StdIn
object Example01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("PrintDiamond")
.setMaster("local[*]")
val sc = new SparkContext(conf)
print("输入一个奇数:")
val n = StdIn.readInt()
if (n % 2 == 0) {
println("你输入的不是奇数哦~")
return
}
val list = new ListBuffer[Int]()
(1 to n by 2).foreach(list += _)
(n - 2 to 1 by -2).foreach(list += _)
val rdd = sc.makeRDD(list)
val rdd1 = rdd.map(i => " " * ((n - i) / 2) + "*" * i)
rdd1.collect.foreach(println)
}
}
- 查看结果

七、过滤算子案例
任务1、过滤出列表中的偶数
- 方法一、将匿名函数传给过滤算子
val rdd1 = sc.makeRDD(List(4, 7, 9, 2, 45, 89, 120, 666, 25, 129))
val rdd2 = rdd1.filter(x => x % 2 == 0)
rdd2.collect

- 方法二、用神奇占位符改写传入过滤算子的匿名函数

任务2、过滤出文件中包含spark的行
- 执行命令: val lines= sc.textFile(“/park/words.txt”),读取文件 /park/words.txt生成RDD - lines

- 执行命令:val sparkLines = lines.filter(_.contains(“spark”)),过滤包含spark的行生成RDD - sparkLines

- 执行命令:sparkLines.collect,查看sparkLines内容,可以采用遍历算子,分行输出内容


![深度学习基础入门篇[9.1]:卷积之标准卷积:卷积核/特征图/卷积计算、填充、感受视野、多通道输入输出、卷积优势和应用案例讲解](https://img-blog.csdnimg.cn/img_convert/c70cf74e965c4cea8c139fb4632dcaff.png)



![[Hadoop]数据仓库基础与Apache Hive入门](https://img-blog.csdnimg.cn/52e5fe014eb64d38804a2535f7822a88.png)