一、前言
近年来,很多公司随着业务的发展都开始采用云原生的架构方式来部署服务系统,以便满足系统的弹性需求。但随着业务的进一步增长,k8s的节点数不断的增加,每个月消耗的费用也随之增加,导致了资源的利用率并不平均的问题,特别是在多云环境下。比如有的节点利用率高,有的利用率低,但是费用还是相差无几。
遇到这种情况,大部分的做法都是人为的去各个云平台核对账单,根据资源的实际使用情况及财务情况来选择是否降配或释放一些无用的资源等。但这也需要大量的时间和人力成本来解决。这时如果有一种自动化的方式来解决这个问题,通过工具、大数据、人工智能等策略帮我们分析用量成本并给出优化建议那将节省不少成本,效率也会有质的飞跃和提升。
因此,业界对此提出了一种概念就是FinOps。
FinOps 是由“Finance”和“DevOps”组成的, FinOPS也被称为“云财务管理”、、“云成本管理”等,
FinOps 是一种不断发展的云财务管理学科和文化实践,通过帮助工程、财务、技术和业务团队在数据驱动的支出决策上进行协作,使组织能够获得最大的业务价值:

刚好,最近有机会体验到腾讯开源的云资源分析与成本优化平台-FinOps Crane,总体的体验效果来说也是非常不错的,符合它的愿景:在保证客户应用运行质量的前提下实现极致的降本。下面就将此次体验过程分享给大家。
二、体验分享
1)Crane介绍
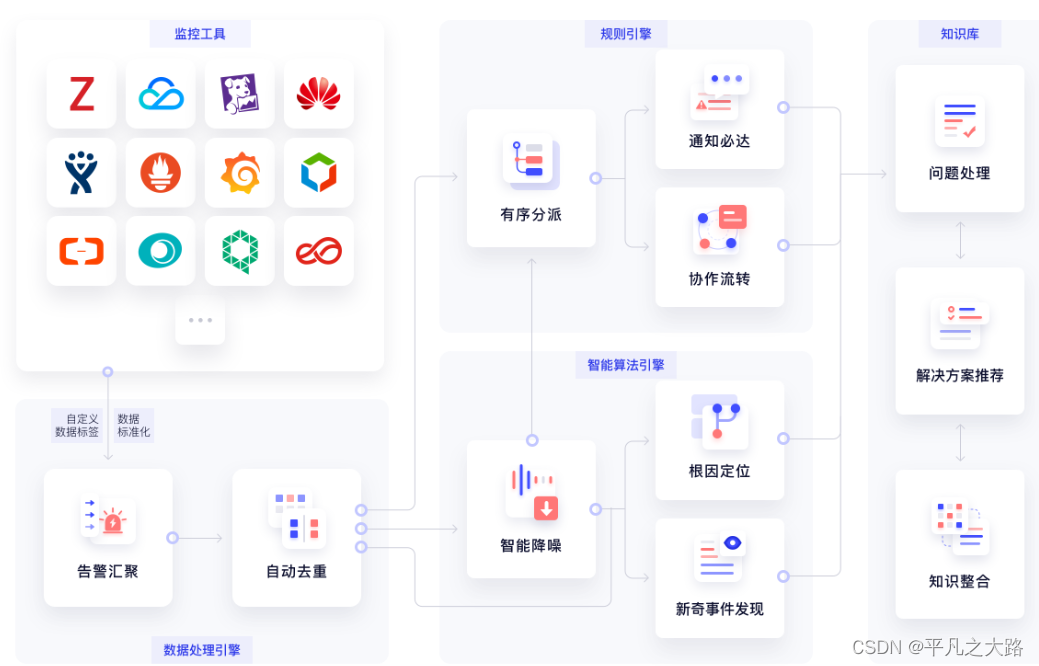
Crane 遵循 FinOps 标准,依托云原生技术,结合智能预测、自动调度、业务混部等多种手段,将优化措施应用到了云成本优化的多个关键环节,以可视化的方式帮助用户快速决策、简化运维效率、提升系统稳态、全面降本增效,从而为云原生用户提供一站式的云成本优化解决方案,其主要功能如下图所示:
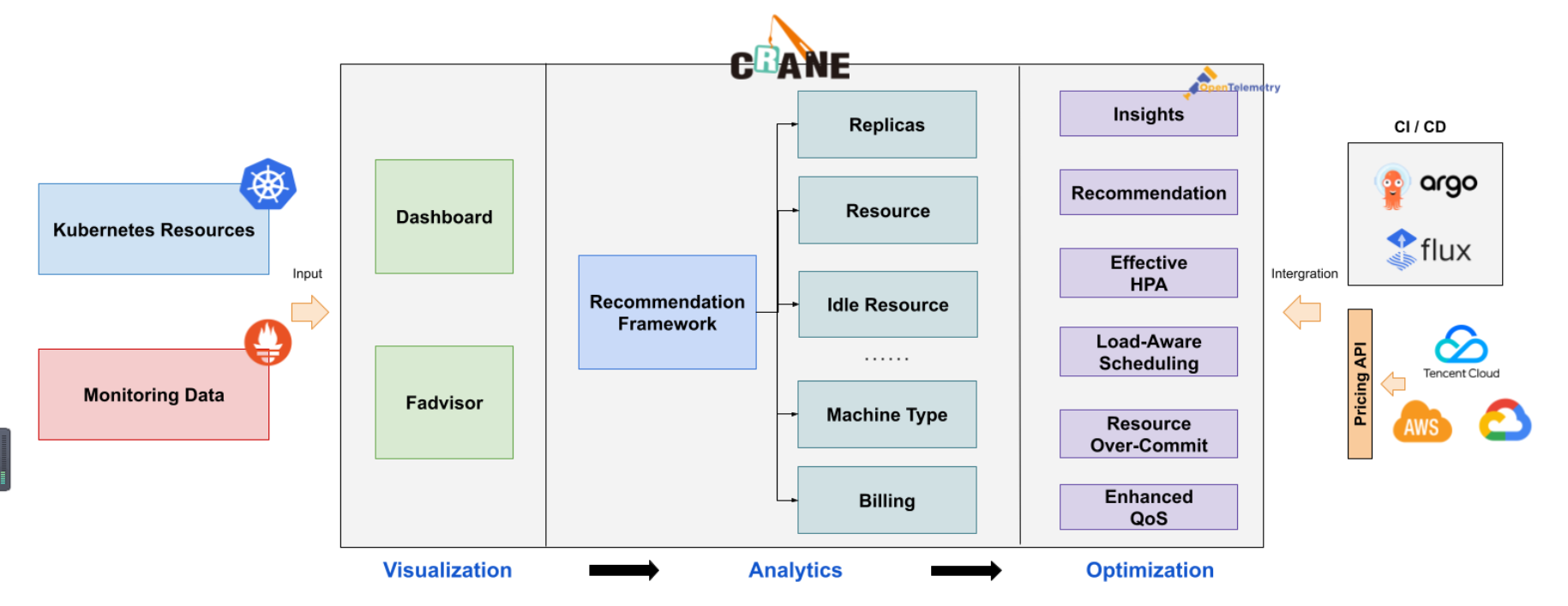
成本可视化和优化评估
提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统,比如 Prometheus。
多维度的成本洞察,优化评估。通过 Cloud Provider 支持多云计费。
推荐框架
提供了一个可扩展的推荐框架以支持多种云资源的分析,内置了多种推荐器:资源推荐,副本推荐,HPA 推荐,闲置资源推荐。
基于预测的水平弹性器
EffectiveHorizontalPodAutoscaler 支持了预测驱动的弹性。它基于社区 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,观测,周期),让弹性更加高效,并保障了服务的质量。
负载感知的调度器
动态调度器根据实际的节点利用率构建了一个简单但高效的模型,并过滤掉那些负载高的节点来平衡集群。
拓扑感知的调度器
Crane Scheduler与Crane Agent配合工作,支持更为精细化的资源拓扑感知调度和多种绑核策略,可解决复杂场景下“吵闹的邻居问题",使得资源得到更合理高效的利用。
基于 QOS 的混部
QOS相关能力保证了运行在 Kubernetes 上的 Pod 的稳定性。具有多维指标条件下的干扰检测和主动回避能力,支持精确操作和自定义指标接入;具有预测算法增强的弹性资源超卖能力,复用和限制集群内的空闲资源;具备增强的旁路cpuset管理能力,在绑核的同时提升资源利用效率。
Crane 的整体架构

Craned
Craned 是 Crane 的最核心组件,它管理了 CRDs 的生命周期以及API。Craned 通过 Deployment 方式部署且由两个容器组成:
Craned: 运行了 Operators 用来管理 CRDs,向 Dashboard 提供了 WebApi,Predictors 提供了 TimeSeries API
Dashboard: 基于 TDesign's Starter 脚手架研发的前端项目,提供了易于上手的产品功能
Fadvisor
Fadvisor 提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统,比如 Prometheus。Fadvisor 通过 Cloud Provider 支持了多云计费的 API。
Metric Adapter
Metric Adapter 实现了一个 Custom Metric Apiserver. Metric Adapter 读取 CRDs 信息并提供基于 Custom/External Metric API 的 HPA Metric 的数据。
Crane Agent
Crane Agent 通过 DaemonSet 部署在集群的节点上。
2)搭建一个 Kubernetes+Crane 环境
这里我是基于Lniux进行搭建的,其他环境的搭建可以参考官方文档。
2.1 环境搭建,安装kubectl、Helm、kind、Docker
官方提供了各环境的安装文档,小伙伴们根据自己的情况选择即可:
安装 kubectl:https://kubernetes.io/zh-cn/docs/tasks/tools/
安装 Helm:https://helm.sh/zh/docs/intro/install/
安装kind:https://kind.sigs.k8s.io/docs/user/quick-start/#installation
安装docker:https://docs.docker.com/get-docker/
2.2 安装 Crane
执行下面的命令安装Crane 以及其依赖 (Prometheus/Grafana):
mkdir training # 为crane创建目录
cd training
# 如果访问不了,建议科学上网
curl -sf https://raw.githubusercontent.com/gocrane/crane/main/hack/local-env-setup.sh | sh -如果上面安装命令报网络错误,可以用本地的安装包执行安装,在命令行中执行以下安装命令:
# 必须在 installation 的上级目录例如:我们预设好的 training 跟目录中执行# Mac/Linuxbash installation/local-env-setup.sh
# Windows
./installation/local-env-setup.sh安装完成后会有如下提示,提示执行的这两个命令是用来访问 Crane Dashboard的:

按照上图的提示执行这两个命令:
# 配置 KUBECONFIG 环境变量
export KUBECONFIG=${HOME}/.kube/config_crane
# 运行 crane-system项目
kubectl get deploy -n crane-system出现下面的运行结果就算成功:
NAME READY UP-TO-DATE AVAILABLE AGE
craned 1/1 1 1 4m01s
fadvisor 1/1 1 1 4m02s
grafana 0/1 1 0 4m03s
kube-state-metrics 0/1 1 0 4m03s
metric-adapter 1/1 1 1 4m02s
prometheus-server 0/1 1 0 4m03s继续执行命令:kubectl get pod -n crane-system,待所有集群状态都为running时代表成功:
NAME READY STATUS RESTARTS AGE
craned-6dcc5c569f-vnfsf 2/2 Running 0 17m
fadvisor-5b685f4cd6-xpxzq 1/1 Running 0 17m
grafana-64656f6d54-6l24j 1/1 Running 0 17m
metric-adapter-967c6d57f-swhfv 1/1 Running 0 17m
prometheus-kube-state-metrics-7f9d78cffc-p8l7c 1/1 Running 0 17m
prometheus-server-fb944f4b7-4qqlv 2/2 Running 0 17m再执行命令:kubectl -n crane-system port-forward service/craned 9090:9090
然后在浏览器访问http://127.0.0.1:9090/,就可以打开Grane 的 dashboard 了:

注意:后续的终端操作请在新窗口操作,每一个新窗口操作前需要执行下面的命令,把配置环境变量加上(不然会出现8080端口被拒绝的提示):
export KUBECONFIG=${HOME}/.kube/config_crane至此我们已成功部署好Crane了。
3)基于Crane 环境优化你的集群和应用
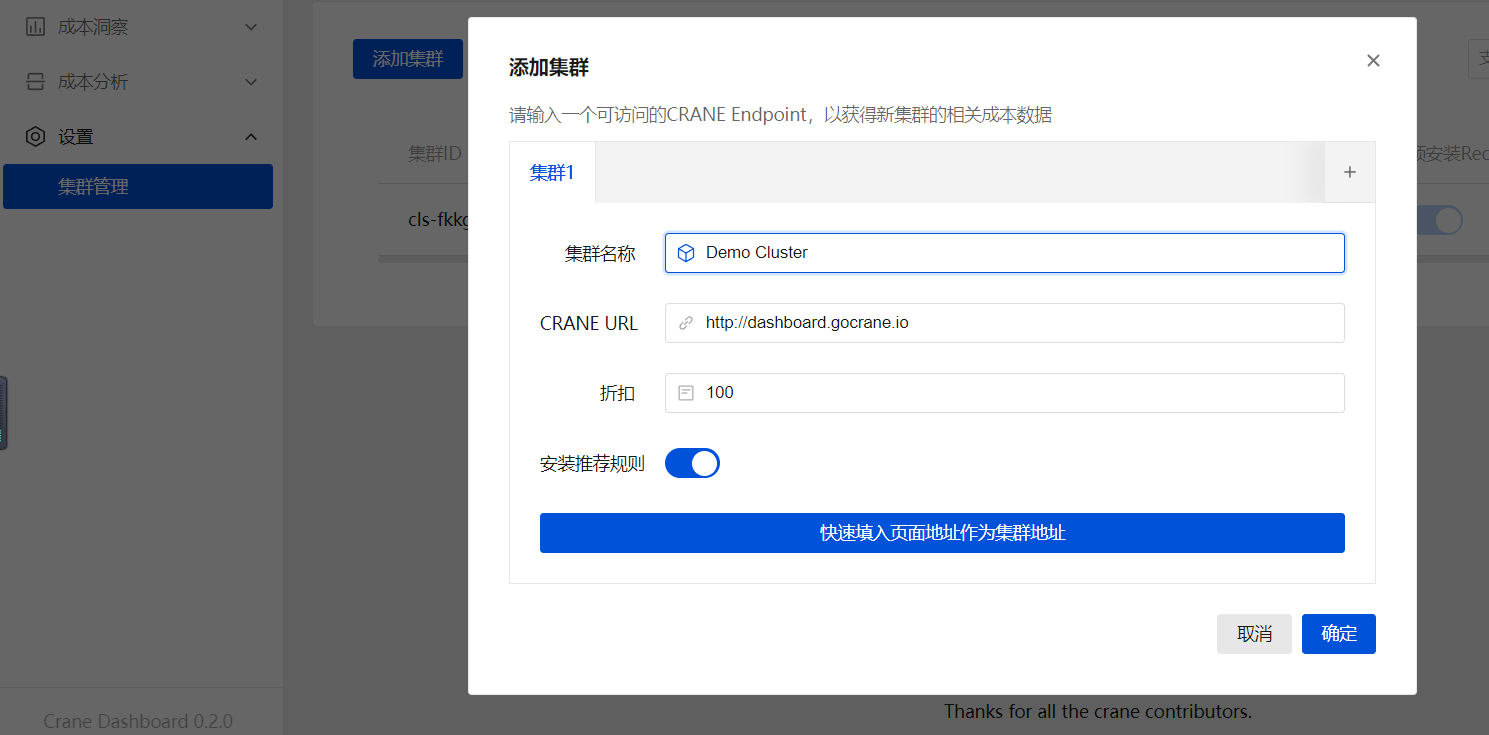
3.1 添加集群
在页面中点击设置-集群管理-添加集群,地址填写: http://dashboard.gocrane.io:
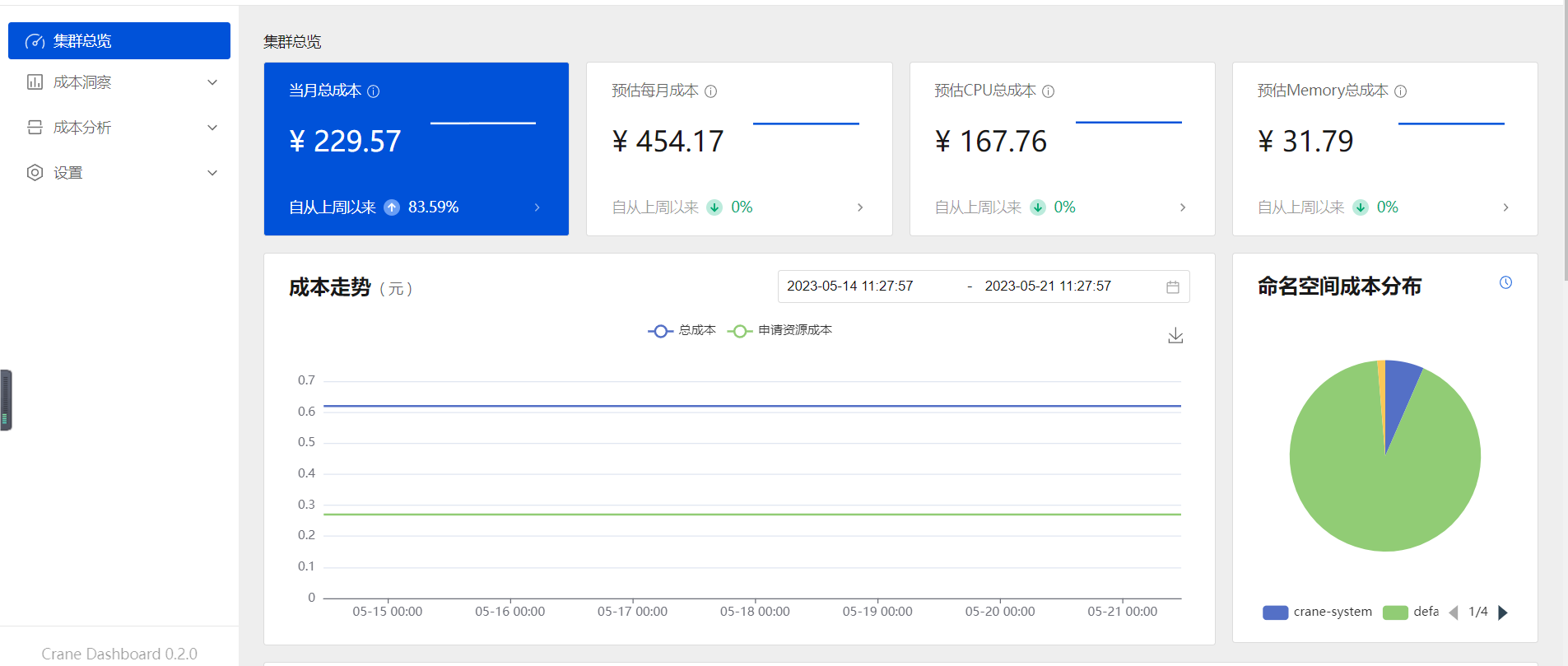
添加成功后就可以在集群总览中看到数据信息:
3.2 成本洞察
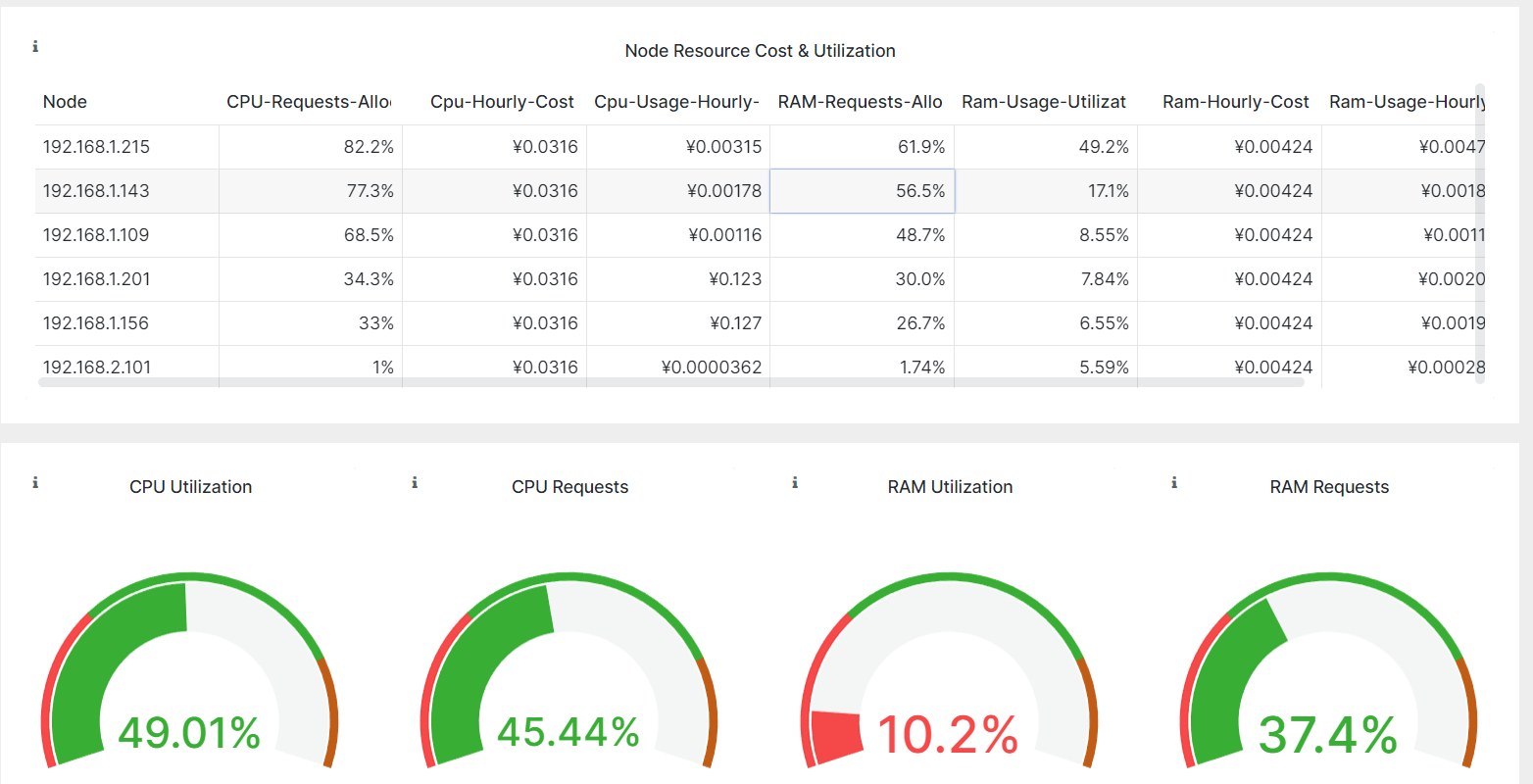
成本洞察可以快速查看集群中的相关信息,比如内存、Cpu等占用信息以及各个应用信息成本和碳排放等数据信息:
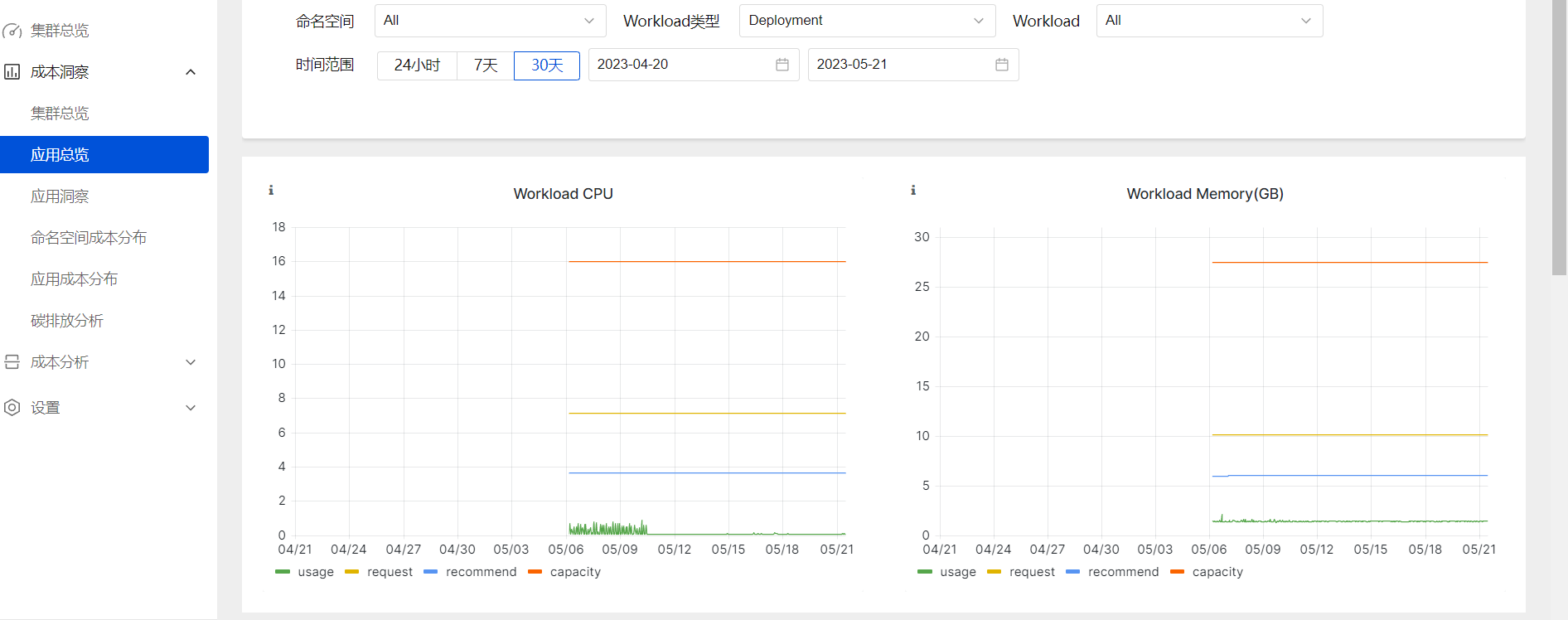
成本是如何计算的?
成本计算功能是由组件 Fadvisor 实现,在安装 Crane 时会一起安装,一起提供了成本展示和成本分析功能:
Server:收集集群 Metric 数据并计算成本
Exporter:将成本 Metric 暴露出来
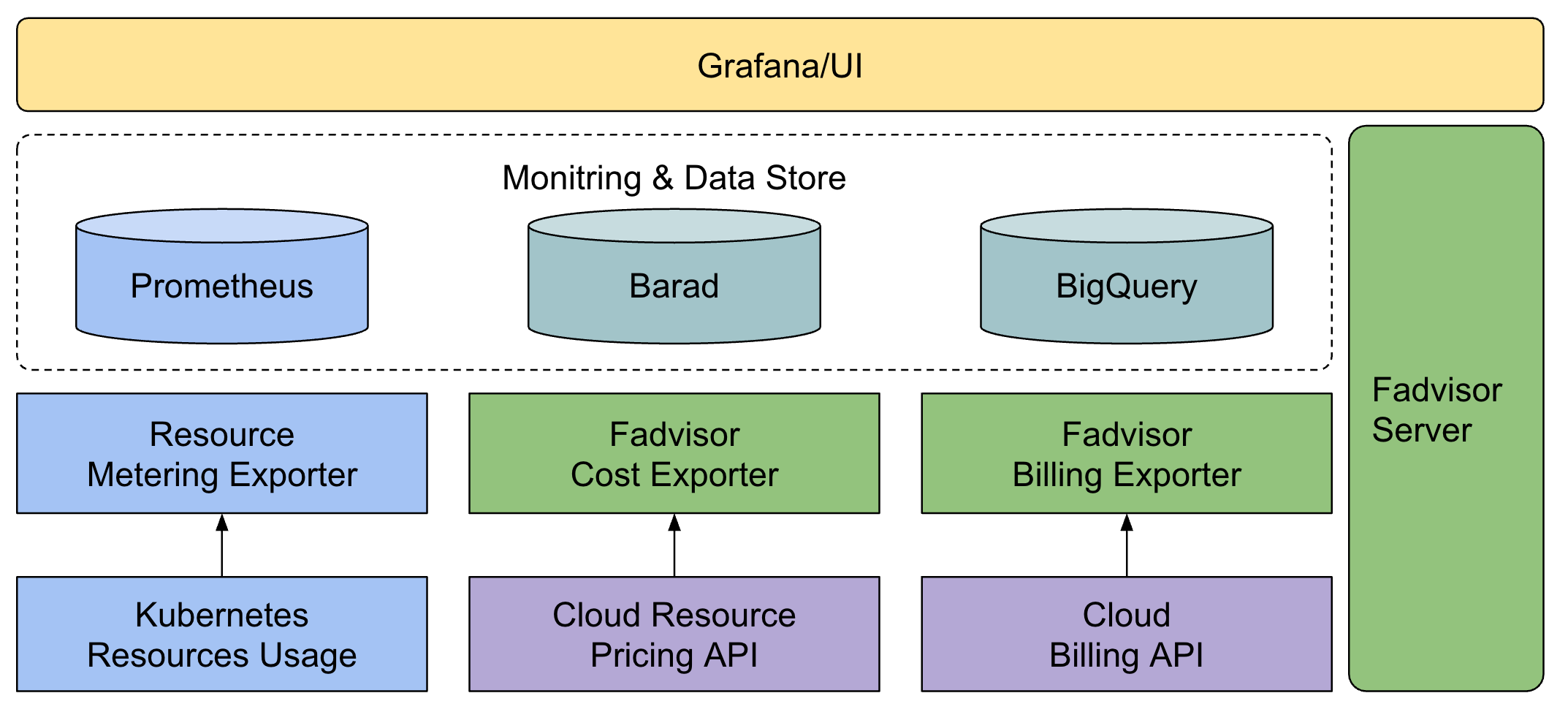
原理
Fadvisor 成本模型提供了一个方法来估计和分析每个容器,pod 或其他资源在 Kubernetes 中的资源价格。
请注意,成本模型只是预估成本,而不是替代云订单,因为实际的计费数据取决于更多原因,比如各类计费逻辑。以下是计算理论:
最简单的成本模型是以相同的价格估算所有节点或 pod 的资源价格。例如,在计算成本时,您可以假设所有容器的 CPU 和 RAM 单位价格相同,2/小时核心,0.3/小时 Gib
高级成本模型是通过成本分摊来估计资源价格。 这一理论的基础是不同实例类型和计费类型的每个云机器实例的价格不同,不过 CPU 和 RAM 的价格比率是相对固定的,可以通过这个价格比率来计算资源成本。
成本分摊模型下的具体的计算公式如下:
集群整体成本:cvm 成本之和
CPU/mem 价格比率相对固定
cvm 的成本 = CPU 成本 * CPU 数量 + mem 成本 * mem 数量
CPU 申请成本:整体成本 * (CPU 占 cvm 成本的比例)得到整体 CPU 成本,再按申请的 CPU 总览占整体 CPU 总量的比例计算出 CPU 申请的成本
namespace 下的 CPU 申请成本: CPU 申请成本按 namespace 聚合
3.3 成本分析
成本分析模块会自动分析集群中各种资源的运行情况并给出资源及副本的推荐建议、
它是如何进行资源推荐的?
Kubernetes 用户在创建应用资源时常常是基于经验值来设置 request 和 limit,通过资源推荐的算法分析应用的真实用量推荐更合适的资源配置,你可以参考并采纳它提升集群的资源利用率。该推荐算法模型采用了 VPA 的滑动窗口(Moving Window)算法进行推荐:
通过监控数据,获取 Workload 过去一周(可配置)的 CPU 和内存的历史用量。
算法考虑数据的时效性,较新的数据采样点会拥有更高的权重。
CPU 推荐值基于用户设置的目标百分位值计算,内存推荐值基于历史数据的最大值。
资源推荐


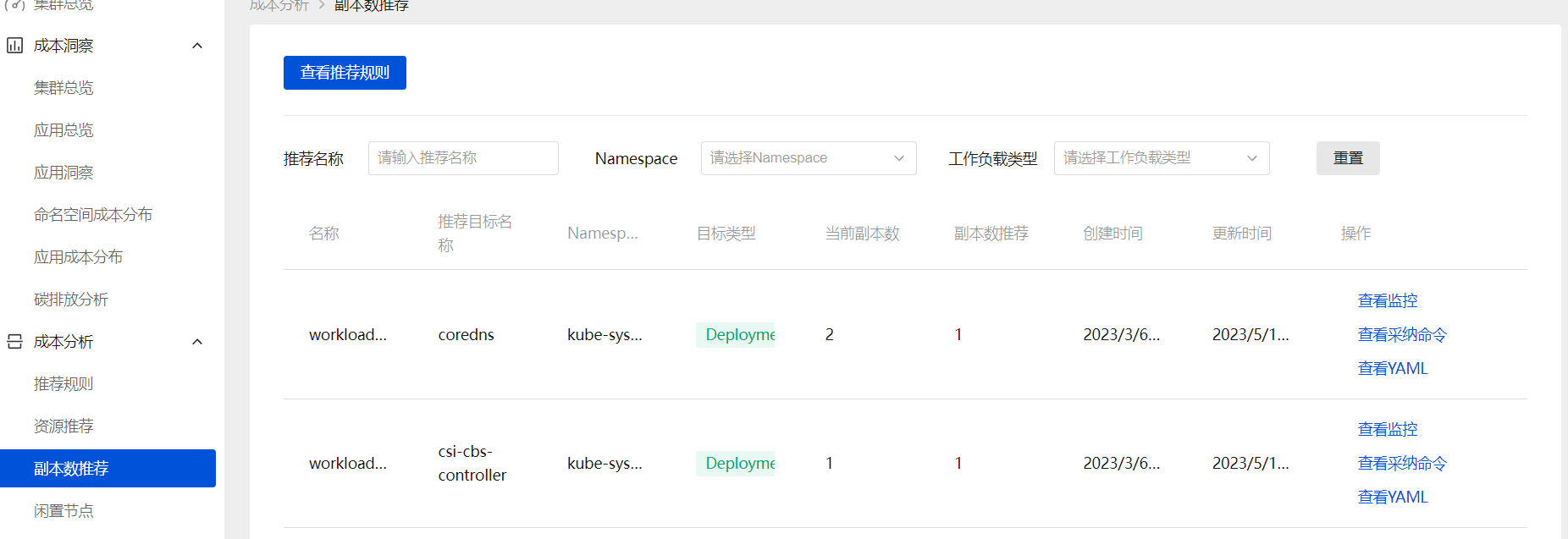
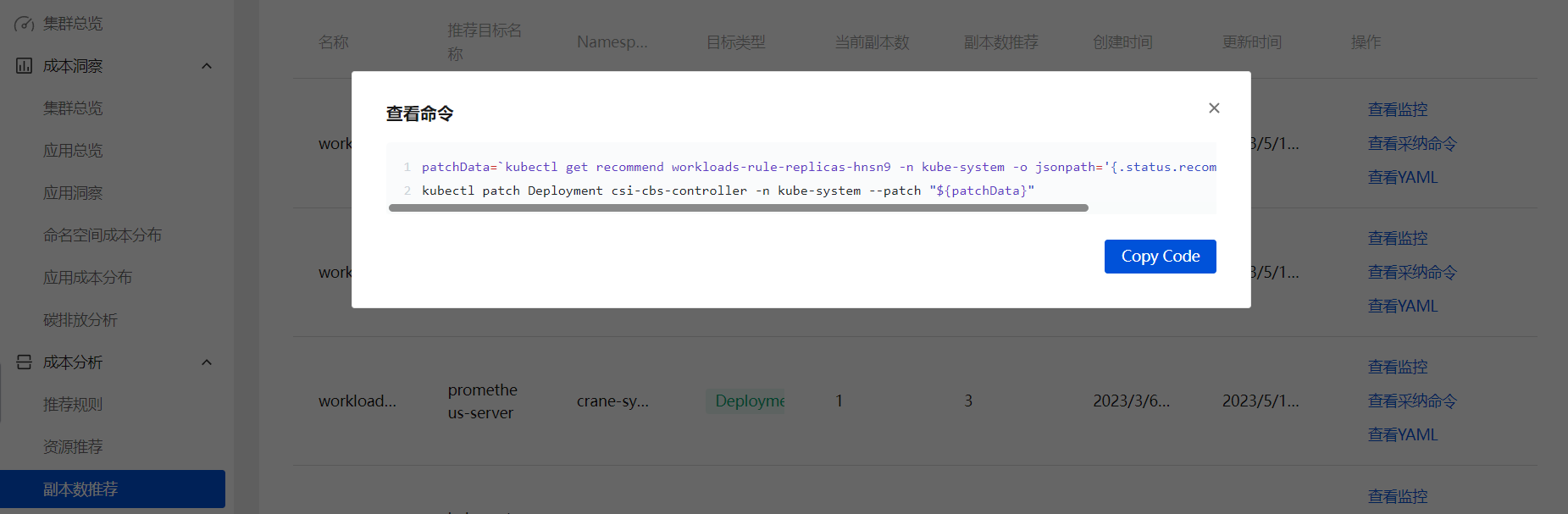
副本数推荐
Kubernetes 用户在创建应用资源时常常是基于经验值来设置副本数。通过副本数推荐的算法分析应用的真实用量推荐更合适的副本配置,同样可以参考并采纳它提升集群的资源利用率。其实现的基本算法是基于工作负载历史 CPU 负载,找到过去七天内每小时负载最低的 CPU 用量,计算按 50%(可配置)利用率和工作负载 CPU Request 应配置的副本数:
三、总结
根据最新的 2022 年分析师和供应商报告,云支出总额的 32% 是浪费的支出,即在云上的每 100 元支出中就有 32 元是浪费了的,所以越来越多的企业和组织开始注重云成本的优化工作,也衍生出了Finops概念。
经过这次体验Crane 的过程,让我看到了基于Finops的应用真正落地。而且Crane的上手也是非常容易的,提供的实时监控成本、应用资源使用量、资源推荐、智能弹性等功能也是真正能解决行业现状的痛点的。另外,Crane 已经在腾讯内部自研业务实现了大规模落地,他们的一自研业务落地 Crane 后,在一个月内实现了总 CPU 规模 40 万核的节省量,按照 CPU 单核每月40元估算,相当于成本节约超 1000 万元/月。这是非常有价值的!
最近腾讯云也在开展 Finops Crane 集训营的活动:
Finops Crane集训营主要面向广大开发者,旨在提升开发者在容器部署、K8s层面的动手实践能力,同时吸纳Crane开源项目贡献者,鼓励开发者提交issue、bug反馈等,并搭载线上直播、动手实验组队、有奖征文等系列技术活动。既能让开发者通过活动对 Finops Crane 开源项目有深入了解,同时也能帮助广大开发者在云原生技能上有实质性收获。
为奖励开发者,我们特别设立了积分获取任务和对应的积分兑换礼品。
活动介绍送门:https://marketing.csdn.net/p/038ae30af2357473fc5431b63e4e1a78
开源项目: https://github.com/gocrane/crane