导读:本文是“数据拾光者”专栏的第六十二篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇作为之前keybert的补充主要介绍了keybert在实际业务中的使用分享,对于希望在实际业务场景中使用keybert的小伙伴可能有帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者

摘要:本篇主要从实际工作业务角度补充介绍了keybert。首先介绍了keybert抽取关键词的三个流程,重点介绍了在我们实际业务场景工业实践的做法;然后展示了keybert在我们实际场景中的抽取示例,通过实验的方式对比了不同的预训练模型对抽取关键词效果的影响,其中chinese_roformer-sim-char-ft_L-6_H-384_A-6预训练模型效果是最好的。对于希望将keybert应用到实际工作中的小伙伴可能会有帮助。
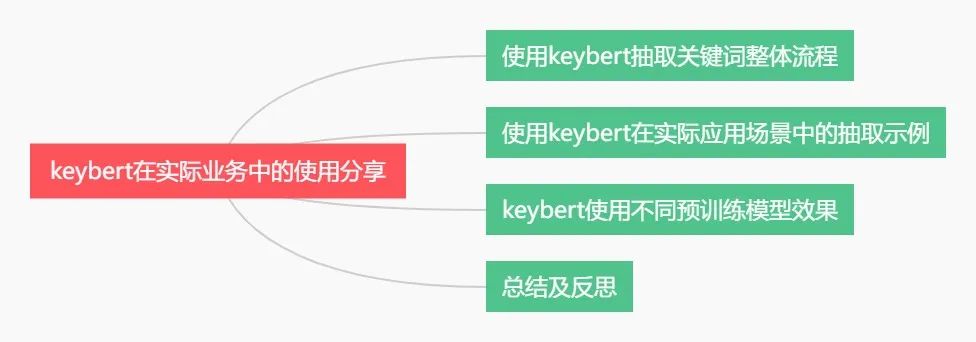
下面主要按照如下思维导图进行学习分享:
01 使用keybert抽取关键词整体流程
之前的文章《广告行业中那些趣事系列60:详解超好用的无监督关键词提取算法Keybert》主要从理论和动手实践的角度介绍了keybert,本篇主要会补充一些keybert在实际公司业务中使用的经验分享。
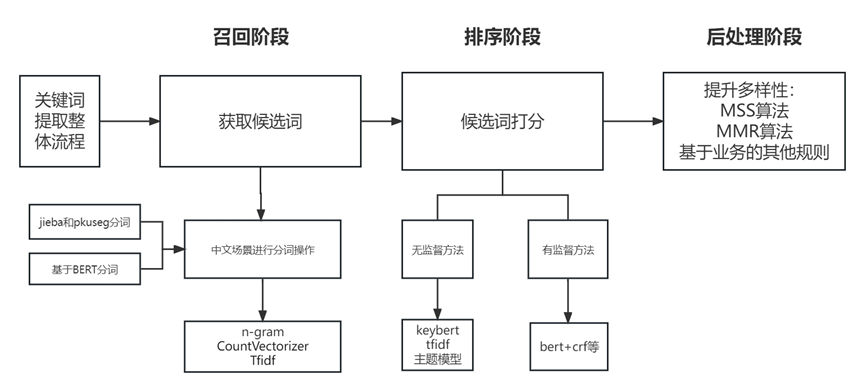
图1 使用keybert抽取关键词整体流程
整体来看,使用keybert抽取关键词主要包括三个阶段:
第一个阶段是召回阶段,主要目的是获取候选词。在中文场景中需要对文档进行分词操作,这里常规的可以使用jieba分词,还可以尝试使用哈工大的pkuseg分词,还可以考虑使用基于bert的分词。经过分词操作之后,可以通过n-gram、CountVectorizer和Tfidf等方式获取候选词。在实际工业落地实践中,我们为了提升获取候选词的效率,还会从业务角度来积累候选词,比如通过积累的app名、各种实体库数据,还会通过广告主上传的关键词等也会作为候选词。将这些候选词去搜索query、浏览资讯title和广告文案等文本中去进行匹配计算得到uv/pv,根据pv/uv获取头部候选词,然后人工去review头部候选词,尾部的则直接去掉。因为尾部的候选词占比在60%甚至更高,所以通过这种方式可以有效的提升获取候选词库的效率。但是这种方式也存在一定的缺点,可能会漏掉一些新词,这里会定时的去挖掘新词;
第二个阶段是排序阶段,主要目的是给候选词打分。这里主要分成有监督学习方法和无监督学习方法。有监督学习方法目前用的比较多的是基于bert+crf经典套路。而无监督学习方法主要常用的有tfidf和一些主题模型,还有我们介绍的keybert方法。Keybert在排序阶段主要是使用bert预训练模型对文档和候选词进行编码得到embedding,使用余弦相似度计算embedding得分进行排序操作;
第三阶段是后处理阶段。这里有很多方面,其中一个点是提升关键词的多样性。Keybert主要通过MSS(Max Sum Similarity)算法和MMR(Maximal Marginal Relevance)算法来提升抽取关键词的多样性。
02 使用keybert在实际应用场景中的抽取示例
case1:
query | 民国悬疑剧《甜心美探》,搜狐视频全网独播 |
标注 | 悬疑剧、民国悬疑剧、甜心美探、搜狐视频 |
roformer-sim-char-ft-L6 | 民国悬疑剧:0.7526 /甜心美探:0.6728 /视频全网独播:0.6238 /搜狐视频全网:0.5615 /悬疑剧:0.5708 / |
roformer-sim-char | 甜心美探:0.8833 /民国悬疑剧:0.8624 /视频全网独播:0.8229 /悬疑剧:0.8419 /美探:0.819 / |
roberta_L-4_H-312 | 搜狐视频全网:0.8308 /民国悬疑剧:0.7694 /独播:0.7626 /视频全网独播:0.8172 /搜狐视频:0.7816 |
roberta_L-6_H-384_ | 搜狐视频全网:0.8236 /民国悬疑剧:0.7715 /全网独播:0.804 /甜心美探:0.6803 /搜狐视频:0.8076 |
tinybert_L-4 | 民国悬疑剧:0.9652 /搜狐视频全网:0.9499 /甜心美探:0.9486 /视频全网独播:0.9499 /甜心美:0.9421 |
case2:
query | 天才神医,一手鬼谷医术纵横都市,邂逅各路美女,走上人生巅峰 |
标注关键词 | 神医、天才神医、邂逅美女、鬼谷艺术、人生巅峰 |
roformer-sim-char-ft | 鬼谷医术纵横:0.6293 /走上人生巅峰:0.5773 /天才神医:0.6129 /美女:0.5358 /医术纵横都市:0.5692 /鬼谷医术:0.5539 |
roformer-sim-char | 走上人生巅峰:0.8374 /鬼谷医术纵横:0.8249 /天才神医:0.8328 /美女:0.7684 /医术纵横都市:0.8102 |
roberta_L-4_H-312 | 医术纵横都市:0.7842 /走上人生巅峰:0.7504 /天才神医:0.7297 /邂逅:0.6383 /鬼谷医术纵横:0.7618 |
roberta_L-6_H-384_ | 天才神医:0.8088 /走上人生巅峰:0.7932 /鬼谷医术纵横:0.8026 /医术纵横都市:0.7935 /鬼谷:0.7039 |
tinybert_L-4 | 走上人生巅峰:0.9402 /走上人生:0.9296 /医术纵横都市:0.9239 /鬼谷医术纵横:0.9241 /人生巅峰:0.9223 |
case3:
query | 网购千万别花冤枉钱了,在这里,新人领券下单,便宜哭了 |
标注关键词 | 新人领券、领券下单 |
roformer-sim-char-ft | 新人领券下单:0.7365 /便宜哭:0.6147 /网购:0.654 /领券下单:0.6774 /新人领券:0.6646 |
roformer-sim-char | 新人领券下单:0.8395 /花冤枉钱:0.8256 /便宜哭:0.8239 /网购:0.7742 /便宜:0.7772 |
roberta_L-4_H-312 | 花冤枉钱:0.762 /新人领券下单:0.7573 /网购:0.701 /便宜哭:0.6062 /新人领券:0.7219 |
roberta_L-6_H-384_ | 花冤枉钱:0.7661 /新人领券下单:0.7636 /便宜哭:0.7363 /网购:0.6792 /下单:0.7146 |
tinybert_L-4 | 新人领券下单:0.9552 /领券下单:0.9327 /新人领券:0.9317 /花冤枉钱:0.9285 /冤枉钱:0.9143 |
case4:
query | 新春将至,家中常备这4款酒,纯粮酿造口感好,宴请送礼倍有面儿 |
标注关键词 | 纯粮酿造、宴请送礼 |
roformer-sim-char-ft | 粮酿造口感:0.6088 /宴请送礼:0.5518 /纯粮酿造:0.5735 /新春:0.4946 /纯粮:0.5268 |
roformer-sim-char | 粮酿造口感:0.8215 /宴请送礼:0.779 /常备:0.7362 /新春:0.7186 /面儿:0.7112 |
roberta_L-4_H-312 | 粮酿造口感:0.7565 /宴请送礼:0.6923 /新春:0.6656 /常备:0.6494 /面儿:0.6042 |
roberta_L-6_H-384_ | 粮酿造口感:0.759 /新春:0.7247 /送礼:0.7291 /纯粮:0.7092 /面儿:0.6848 |
tinybert_L-4 | 粮酿造口感:0.9241 /酿造口感:0.9187 /口感:0.9022 /新春:0.8877 /纯粮酿造:0.897 |
case5:
query | 聚焦新能源汽车发展趋势,厦门企业聚合发展建立生态共享 |
标注关键词 | 新能源汽车、厦门企业、生态共享 |
roformer-sim-char-ft | 新能源汽车发展趋势:0.7606 /厦门企业聚合:0.7471 /发展建立生态:0.7184 /聚焦新能源汽车:0.7349 /企业聚合发展:0.6857 |
roformer-sim-char | 新能源汽车发展趋势:0.8986 /建立生态共享:0.8797 /企业聚合发展:0.8833 /聚焦新能源:0.8925 /聚焦新能源汽车:0.8903 |
roberta_L-4_H-312 | 聚合发展:0.8362 /聚焦新能源汽车:0.7554 /企业聚合发展:0.8355 /聚合发展建立:0.7895 /新能源汽车发展趋势:0.6976 |
roberta_L-6_H-384_ | 企业聚合发展:0.8758 /建立生态共享:0.836 /聚焦新能源汽车:0.7733 /厦门企业聚合:0.8196 /聚合发展建立:0.831 |
tinybert_L-4 | 新能源汽车发展趋势:0.9735 /发展建立生态:0.961 /建立生态共享:0.9618 /聚焦新能源汽车:0.9592 /聚合发展建立:0.9534 |
case6:
query | 卫龙·大面筋,儿时辣条风靡几十年还是老味道,重,卫龙,其体息以1688APP内力准 |
标注关键词 | 大面筋、辣条、味道、卫龙 |
roformer-sim-char-ft | 辣条风靡:0.62 /大面筋:0.495 /卫龙:0.4525 /APP内力准:0.446 /辣条:0.513 |
roformer-sim-char | 辣条风靡:0.8256 /大面筋:0.787 /老味道:0.8143 /APP内力准:0.7579 /卫龙:0.7454 |
roberta_L-4_H-312 | 辣条风靡:0.788 /APP内力准:0.7342 /老味道:0.7646 /辣条:0.7695 /大面筋:0.7113 |
roberta_L-6_H-384_ | 大面筋:0.7303 /APP内力准:0.6887 /辣条:0.625 /体息:0.6138 /卫龙:0.6211 |
tinybert_L-4 | APP内力准:0.9203 /APP:0.8898 /APP内力:0.9056 /辣条风靡:0.8938 /内力准:0.9015 |
03 keybert使用不同预训练模型效果
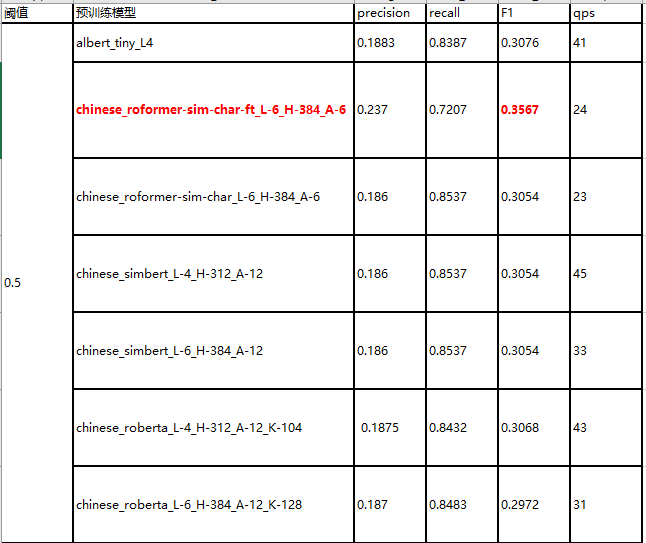
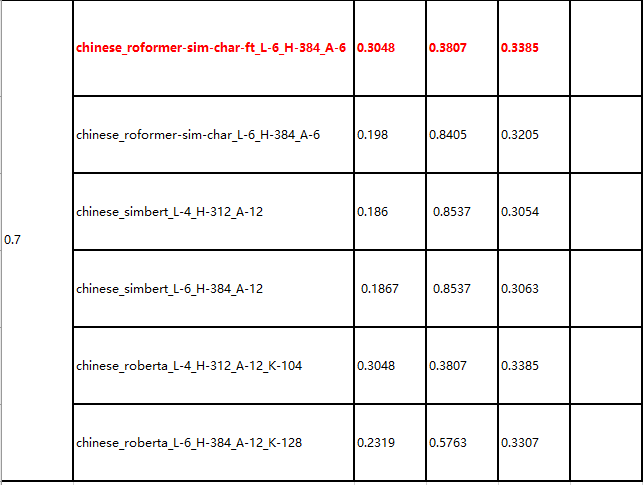
上图中分别使用0.5和0.6作为阈值,通过实验对比使用不同的预训练模型进行编码操作的p、r和f1得分。整体发现,chinese_roformer-sim-char-ft_L-6_H-384_A-6在我们当前的任务场景中关键词抽取的效果是比较好的。
总结和反思
本篇主要从实际工作业务角度补充介绍了keybert。首先介绍了keybert抽取关键词的三个流程,重点介绍了在我们实际业务场景中的做法;然后展示了keybert在我们实际场景中的抽取示例,通过实验的方式对比了不同的预训练模型对抽取关键词效果的影响,其中chinese_roformer-sim-char-ft_L-6_H-384_A-6预训练模型效果是最好的。对于希望将keybert应用到实际工作中的小伙伴可能会有帮助。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们点赞和分享。