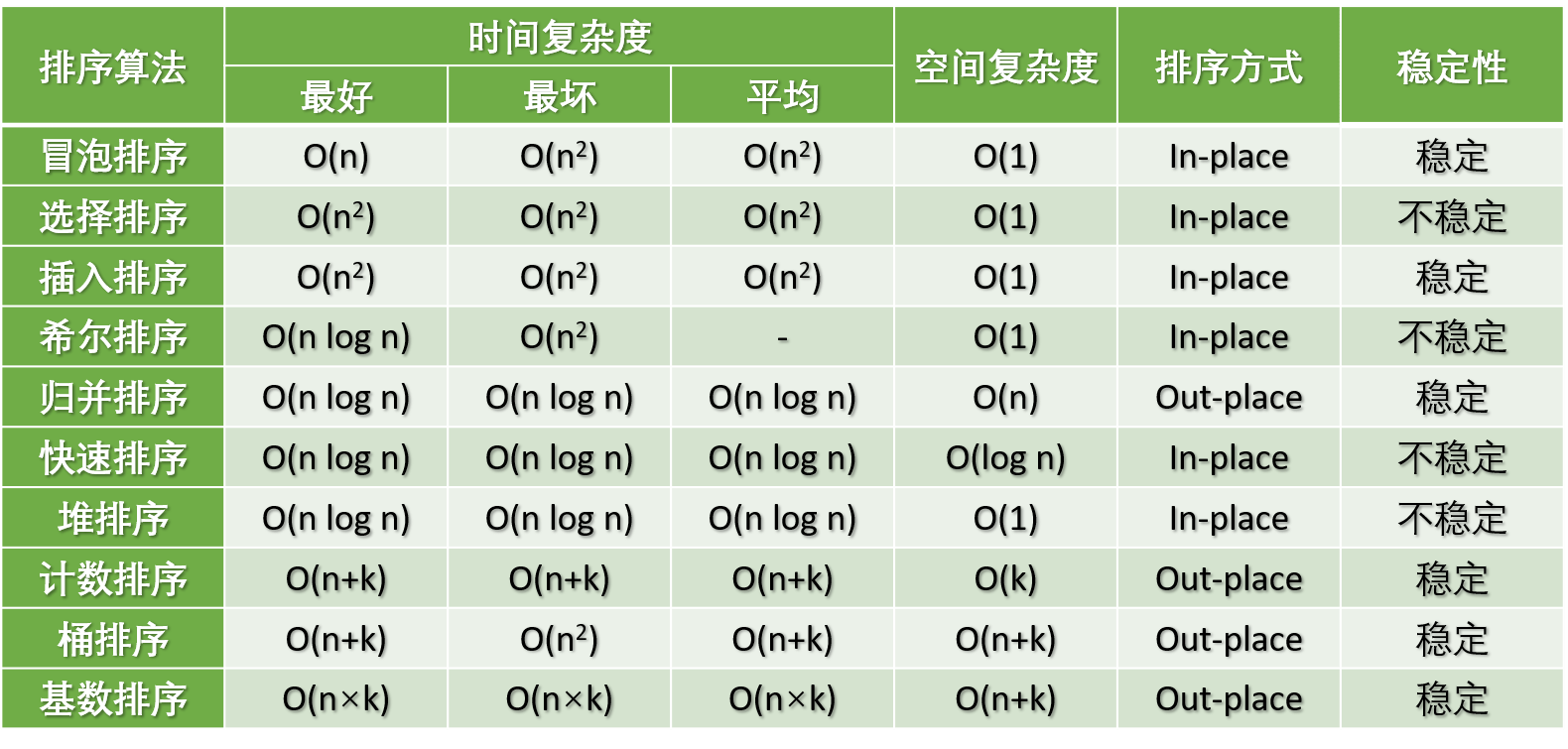
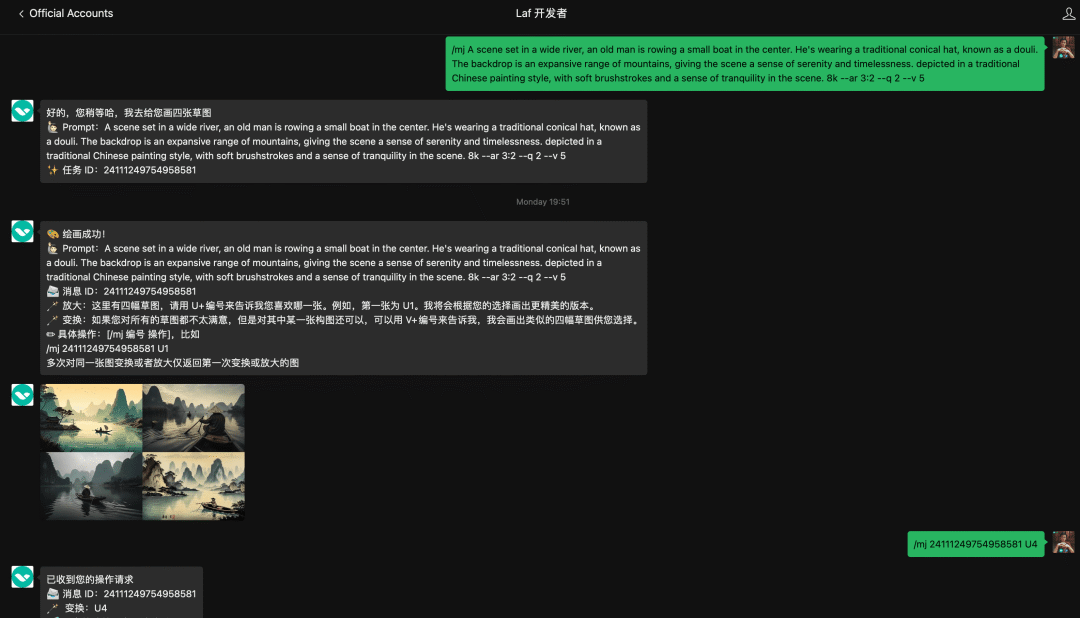
Laf 公众号已接入了 AI 绘画工具 Midjourney,可以让你轻松画出很多“大师”级的作品。同时还接入了 AI 聊天机器人,支持 GPT、Claude 以及 Laf 专有模型,可通过指令来随意切换模型。欢迎前来调戏👇
<<< 左右滑动见更多 >>>
❝原文链接:https://netflixtechblog.com/debugging-a-fuse-deadlock-in-the-linux-kernel-c75cd7989b6d
Netflix 的 Compute 团队负责管理 Netflix 上的所有 AWS 和容器化工作负载,包括自动伸缩、容器部署、问题修复等。作为团队的一员,我的工作是修复用户报告的奇怪问题。
本次遇到的问题涉及到一个内部的定制 FUSE 文件系统[1]:ndrive[2]。它已经存在一段时间了,但需要有人静下心来仔细研究一下。本文展示了我是如何查看 /proc 来排查内核问题,并将问题发布到内核邮件列表上,从而更深入地了解内核的等待代码实际上是如何工作的!
症状:卡住的 Docker Kill 和僵尸进程
我们遇到了一个卡住的 Docker API 调用:
goroutine 146 [select, 8817 minutes]:
net/http.(*persistConn).roundTrip(0xc000658fc0, 0xc0003fc080, 0x0, 0x0, 0x0)
/usr/local/go/src/net/http/transport.go:2610 +0x765
net/http.(*Transport).roundTrip(0xc000420140, 0xc000966200, 0x30, 0x1366f20, 0x162)
/usr/local/go/src/net/http/transport.go:592 +0xacb
net/http.(*Transport).RoundTrip(0xc000420140, 0xc000966200, 0xc000420140, 0x0, 0x0)
/usr/local/go/src/net/http/roundtrip.go:17 +0x35
net/http.send(0xc000966200, 0x161eba0, 0xc000420140, 0x0, 0x0, 0x0, 0xc00000e050, 0x3, 0x1, 0x0)
/usr/local/go/src/net/http/client.go:251 +0x454
net/http.(*Client).send(0xc000438480, 0xc000966200, 0x0, 0x0, 0x0, 0xc00000e050, 0x0, 0x1, 0x10000168e)
/usr/local/go/src/net/http/client.go:175 +0xff
net/http.(*Client).do(0xc000438480, 0xc000966200, 0x0, 0x0, 0x0)
/usr/local/go/src/net/http/client.go:717 +0x45f
net/http.(*Client).Do(...)
/usr/local/go/src/net/http/client.go:585
golang.org/x/net/context/ctxhttp.Do(0x163bd48, 0xc000044090, 0xc000438480, 0xc000966100, 0x0, 0x0, 0x0)
/go/pkg/mod/golang.org/x/net@v0.0.0-20211209124913-491a49abca63/context/ctxhttp/ctxhttp.go:27 +0x10f
github.com/docker/docker/client.(*Client).doRequest(0xc0001a8200, 0x163bd48, 0xc000044090, 0xc000966100, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, ...)
/go/pkg/mod/github.com/moby/moby@v0.0.0-20190408150954-50ebe4562dfc/client/request.go:132 +0xbe
github.com/docker/docker/client.(*Client).sendRequest(0xc0001a8200, 0x163bd48, 0xc000044090, 0x13d8643, 0x3, 0xc00079a720, 0x51, 0x0, 0x0, 0x0, ...)
/go/pkg/mod/github.com/moby/moby@v0.0.0-20190408150954-50ebe4562dfc/client/request.go:122 +0x156
github.com/docker/docker/client.(*Client).get(...)
/go/pkg/mod/github.com/moby/moby@v0.0.0-20190408150954-50ebe4562dfc/client/request.go:37
github.com/docker/docker/client.(*Client).ContainerInspect(0xc0001a8200, 0x163bd48, 0xc000044090, 0xc0006a01c0, 0x40, 0x0, 0x0, 0x0, 0x0, 0x0, ...)
/go/pkg/mod/github.com/moby/moby@v0.0.0-20190408150954-50ebe4562dfc/client/container_inspect.go:18 +0x128
github.com/Netflix/titus-executor/executor/runtime/docker.(*DockerRuntime).Kill(0xc000215180, 0x163bdb8, 0xc000938600, 0x1, 0x0, 0x0)
/var/lib/buildkite-agent/builds/ip-192-168-1-90-1/netflix/titus-executor/executor/runtime/docker/docker.go:2835 +0x310
github.com/Netflix/titus-executor/executor/runner.(*Runner).doShutdown(0xc000432dc0, 0x163bd10, 0xc000938390, 0x1, 0xc000b821e0, 0x1d, 0xc0005e4710)
/var/lib/buildkite-agent/builds/ip-192-168-1-90-1/netflix/titus-executor/executor/runner/runner.go:326 +0x4f4
github.com/Netflix/titus-executor/executor/runner.(*Runner).startRunner(0xc000432dc0, 0x163bdb8, 0xc00071e0c0, 0xc0a502e28c08b488, 0x24572b8, 0x1df5980)
/var/lib/buildkite-agent/builds/ip-192-168-1-90-1/netflix/titus-executor/executor/runner/runner.go:122 +0x391
created by github.com/Netflix/titus-executor/executor/runner.StartTaskWithRuntime
/var/lib/buildkite-agent/builds/ip-192-168-1-90-1/netflix/titus-executor/executor/runner/runner.go:81 +0x411在这里,我们的管理引擎发出了一个 HTTP 调用到 Docker API 的 Unix 套接字,请求杀死一个容器。我们的容器被配置为通过 SIGKILL 方式终止。kill(SIGKILL) 应该是非常彻底的终止方式,但是很奇怪,这里竟然卡住了。
先来看看容器目前是什么状态:
$ docker exec -it 6643cd073492 bash
OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: process_linux.go:130: executing setns process caused: exit status 1: unknown嗯,看起来容器还活着,但是 setns(2) 失败了。为什么会这样?通过 ps awwfux 查看进程树:
\_ containerd-shim -namespace moby -workdir /var/lib/containerd/io.containerd.runtime.v1.linux/moby/6643cd073492ba9166100ed30dbe389ff1caef0dc3d35
| \_ [docker-init]
| \_ [ndrive] <defunct>容器的 init 进程还活着,但它有一个僵尸子进程。容器的 init 进程到底在做什么呢?
# cat /proc/1528591/stack
[<0>] do_wait+0x156/0x2f0
[<0>] kernel_wait4+0x8d/0x140
[<0>] zap_pid_ns_processes+0x104/0x180
[<0>] do_exit+0xa41/0xb80
[<0>] do_group_exit+0x3a/0xa0
[<0>] __x64_sys_exit_group+0x14/0x20
[<0>] do_syscall_64+0x37/0xb0
[<0>] entry_SYSCALL_64_after_hwframe+0x44/0xae它正处在退出的过程中,但好像卡住了。唯一的子进程是 Z(即“僵尸”)状态的 ndrive 进程。僵尸进程是已经成功退出并等待父进程的相应 wait() 系统调用来回收的进程。那么内核为什么会在等待一个僵尸进程上卡住呢?
# ls /proc/1544450/task
1544450 1544574啊哈,线程组中有两个线程?其中一个是僵尸,另一个很有可能不是僵尸:
css
# cat /proc/1544574/stack
[<0>] request_wait_answer+0x12f/0x210
[<0>] fuse_simple_request+0x109/0x2c0
[<0>] fuse_flush+0x16f/0x1b0
[<0>] filp_close+0x27/0x70
[<0>] put_files_struct+0x6b/0xc0
[<0>] do_exit+0x755/0xb80
[<0>] do_group_exit+0x3a/0xa0
[<0>] __x64_sys_exit_group+0x14/0x20
[<0>] do_syscall_64+0x37/0xb0
[<0>] entry_SYSCALL_64_after_hwframe+0x44/0xae没错,它确实不是僵尸进程。它马上就要变成僵尸进程,但它在 FUSE 内部阻塞着出不去了。
为了找出原因,我们需要看一下内核函数 zap_pid_ns_processes() 的代码:
/*
* Reap the EXIT_ZOMBIE children we had before we ignored SIGCHLD.
* kernel_wait4() will also block until our children traced from the
* parent namespace are detached and become EXIT_DEAD.
*/
do {
clear_thread_flag(TIF_SIGPENDING);
rc = kernel_wait4(-1, NULL, __WALL, NULL);
} while (rc != -ECHILD);这就是线程卡住的地方,但在此之前,它还执行了以下操作:
/* Don't allow any more processes into the pid namespace */
disable_pid_allocation(pid_ns);这就是为什么 Docker 无法进行 setns() 操作的原因——该命名空间是一个僵尸。OK,无法进行 setns(2) 操作就算了,但为什么线程还会卡在 kernel_wait4() 上呢?为了理解原理,让我们看看 FUSE 的另一个线程在 request_wait_answer() 函数中做了些什么:
/*
* Either request is already in userspace, or it was forced.
* Wait it out.
*/
wait_event(req->waitq, test_bit(FR_FINISHED, &req->flags));它正在等待一个事件(在本文中,这个事件就是用户空间对 FUSE 刷新请求的回复)。但是 zap_pid_ns_processes() 已经发送了一个SIGKILL信号,为什么它还在等待呢?SIGKILL对一个进程来说应该是非常致命的。通过查看进程,确实可以看到有一个待处理的 SIGKILL 信号:
# grep Pnd /proc/1544574/status
SigPnd: 0000000000000000
ShdPnd: 0000000000000100通过这种方式查看进程状态,可以看到 ShdPnd 的值是 0x100(即第 9 位被设置为 1),它是 SIGKILL 的信号编号。
待处理信号是由内核生成的,但尚未传递到用户空间。
信号只在特定的时刻传递,例如进入或离开系统调用时,或者在等待事件时。
如果内核当前正在执行某些操作,信号可能会保持待处理状态。信号也可以被任务阻塞,这样它们就永远不会被传递。被阻塞的信号也会出现在相应的待处理集合中。
然而,man 7 signal 中说了:“ SIGKILL 和 SIGSTOP 信号不能被捕获、阻塞或忽略。” 但是这里内核告诉我们有一个待处理的 SIGKILL 信号,也就是说即使任务正在等待,它仍然被忽略了!
进入内核:等待事件
要弄清楚这个问题,我们需要深入内核的等待代码。我花了一些时间阅读内核头文件,特别是 include/linux/wait.h。发现 wait_event() 是内核中的一个常见宏,用于实现信号量、等待队列、完成队列等。那么 wait_event() 实际上是做什么的呢?
通过对宏展开和包装的分析,我们找到了关键部分:
#define ___wait_event(wq_head, condition, state, exclusive, ret, cmd) \
({ \
__label__ __out; \
struct wait_queue_entry __wq_entry; \
long __ret = ret; /* explicit shadow */ \
\
init_wait_entry(&__wq_entry, exclusive ? WQ_FLAG_EXCLUSIVE : 0); \
for (;;) { \
long __int = prepare_to_wait_event(&wq_head, &__wq_entry, state);\
\
if (condition) \
break; \
\
if (___wait_is_interruptible(state) && __int) { \
__ret = __int; \
goto __out; \
} \
\
cmd; \
} \
finish_wait(&wq_head, &__wq_entry); \
__out: __ret; \
})这段代码是一个无限循环,执行 prepare_to_wait_event(),检查条件,然后检查是否需要中断。然后执行 cmd,在本文中就是 schedule(),即“暂时执行其他操作”。prepare_to_wait_event() 代码如下:
long prepare_to_wait_event(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry, int state)
{
unsigned long flags;
long ret = 0;
spin_lock_irqsave(&wq_head->lock, flags);
if (signal_pending_state(state, current)) {
/*
* Exclusive waiter must not fail if it was selected by wakeup,
* it should "consume" the condition we were waiting for.
*
* The caller will recheck the condition and return success if
* we were already woken up, we can not miss the event because
* wakeup locks/unlocks the same wq_head->lock.
*
* But we need to ensure that set-condition + wakeup after that
* can't see us, it should wake up another exclusive waiter if
* we fail.
*/
list_del_init(&wq_entry->entry);
ret = -ERESTARTSYS;
} else {
if (list_empty(&wq_entry->entry)) {
if (wq_entry->flags & WQ_FLAG_EXCLUSIVE)
__add_wait_queue_entry_tail(wq_head, wq_entry);
else
__add_wait_queue(wq_head, wq_entry);
}
set_current_state(state);
}
spin_unlock_irqrestore(&wq_head->lock, flags);
return ret;
}
EXPORT_SYMBOL(prepare_to_wait_event);看来唯一能够通过非零退出码中断循环的方式是 signal_pending_state() 返回 true。由于我们的调用点只是 wait_event(),我们知道这里的状态是 TASK_UNINTERRUPTIBLE;signal_pending_state() 的定义如下:
这个函数看起来像是在为我们提供的状态为TASK_UNINTERRUPTIBLE的任务准备等待事件。signal_pending_state()的定义如下:
static inline int signal_pending_state(unsigned int state, struct task_struct *p)
{
if (!(state & (TASK_INTERRUPTIBLE | TASK_WAKEKILL)))
return 0;
if (!signal_pending(p))
return 0;
return (state & TASK_INTERRUPTIBLE) || __fatal_signal_pending(p);
}我们的任务是不可中断的,因此第一个 if 条件不成立。但是我们的任务应该包含了待处理的信号:
static inline int signal_pending(struct task_struct *p)
{
/*
* TIF_NOTIFY_SIGNAL isn't really a signal, but it requires the same
* behavior in terms of ensuring that we break out of wait loops
* so that notify signal callbacks can be processed.
*/
if (unlikely(test_tsk_thread_flag(p, TIF_NOTIFY_SIGNAL)))
return 1;
return task_sigpending(p);
}正如注释所指出的,TIF_NOTIFY_SIGNAL 跟这个问题并没有什么关系,虽然它的名字很容易让人误解。我们再来看看 task_sigpending():
static inline int task_sigpending(struct task_struct *p)
{
return unlikely(test_tsk_thread_flag(p,TIF_SIGPENDING));
}嗯。看起来这个标志应该被设置过了。要弄清楚这个问题,需要研究一下信号传递是如何工作的。当我们在 zap_pid_ns_processes() 中关闭 pid 命名空间时,它会执行以下操作:
group_send_sig_info(SIGKILL, SEND_SIG_PRIV, task, PIDTYPE_MAX);最终会调用到 __send_signal_locked(),其中包含以下代码:
pending = (type != PIDTYPE_PID) ? &t->signal->shared_pending : &t->pending;
...
sigaddset(&pending->signal, sig);
...
complete_signal(sig, t, type);这里使用 PIDTYPE_MAX 作为类型有点奇怪,但大概意思应该是“这是非常特权的内核空间发送的信号,一定要传递”。然而,这里发生了一件让人意想不到的事情,__send_signal_locked() 最终将 SIGKILL 发送到了共享的信号集,而不是单个任务的信号集。通过查看 __fatal_signal_pending() 的代码便知:
static inline int __fatal_signal_pending(struct task_struct *p)
{
return unlikely(sigismember(&p->pending.signal, SIGKILL));
}但事实证明,这个排查方向误导性太大了(虽然我花了点时间才明白过来)。
信号如何传递给进程
要理解这里究竟发生了什么,需要查看 complete_signal(),因为它无条件地将 SIGKILL 添加到任务的等待信号集中:
sigaddset(&t->pending.signal, SIGKILL);但这里为什么不起作用呢?来看一下函数的顶部代码:
/*
* Now find a thread we can wake up to take the signal off the queue.
*
* If the main thread wants the signal, it gets first crack.
* Probably the least surprising to the average bear.
*/
if (wants_signal(sig, p))
t = p;
else if ((type == PIDTYPE_PID) || thread_group_empty(p))
/*
* There is just one thread and it does not need to be woken.
* It will dequeue unblocked signals before it runs again.
*/
return;Eric Biederman[3] 说过,实际上每个线程都可以在任何时候处理 SIGKILL。这是 wants_signal() 的实现:
static inline bool wants_signal(int sig, struct task_struct *p)
{
if (sigismember(&p->blocked, sig))
return false;
if (p->flags & PF_EXITING)
return false;
if (sig == SIGKILL)
return true;
if (task_is_stopped_or_traced(p))
return false;
return task_curr(p) || !task_sigpending(p);
}因此,如果线程正在退出(即具有 PF_EXITING 标志),它就不想再接收信号。考虑以下事件序列:
1、Task 打开一个 FUSE 文件,然后没有关闭它就退出了。在退出过程中,内核会调用 do_exit(),其中包括以下操作:
exit_signals(tsk); /* 设置 PF_EXITING 标志 */2、do_exit() 继续执行 exit_files(tsk);,刷新所有仍处于打开状态的文件,导致上面的堆栈跟踪。
3、pid 命名空间退出,并进入 zap_pid_ns_processes(),向所有线程发送一个 SIGKILL,然后等待所有线程退出。
4、这将杀死 pid 命名空间中的 FUSE 守护进程,使其无法响应。
5、对于已经退出的 FUSE 线程,complete_signal() 会忽略该信号,因为它具有 PF_EXITING 标志。
6、死锁。除非手动中止 FUSE 连接,否则这个事件将永远挂起。
解决方案:不要等待!
在本文遇到的场景中,等待刷新并没有太多意义:线程正在退出,所以没有线程可以接收 flush() 的返回代码。事实证明,这个错误可能会发生在多个文件系统中(任何在 flush() 中调用内核的等待代码的文件系统,也就是与本地内核外部进行通信的任何文件系统)。
在此期间,需要给各个文件系统打补丁,例如 FUSE 的修复补丁在这里[4],该补丁已于 4 月 23 日合并到 Linux 6.3 中。
虽然本文只讨论了 FUSE 死锁的情况,但在 NFS 代码和其他地方也存在类似问题,虽然目前我们还没有在生产环境中遇到这个情况,但可以肯定将来一定会遇到。
引用链接
[1]
FUSE 文件系统: https://www.kernel.org/doc/html/latest/filesystems/fuse.html
[2]ndrive: https://netflixtechblog.com/netflix-drive-a607538c3055
[3]Eric Biederman: https://lore.kernel.org/all/877d4jbabb.fsf@email.froward.int.ebiederm.org/
[4]这里: https://github.com/torvalds/linux/commit/14feceeeb012faf9def7d313d37f5d4f85e6572b
关于 Laf
Laf 是一款为所有开发者打造的集函数、数据库、存储为一体的云开发平台,助你像写博客一样写代码,随时随地发布上线应用!3 分钟上线 ChatGPT 应用!
🌟GitHub:https://github.com/labring/laf
🏠官网(国内):https://laf.run
🌎官网(海外):https://laf.dev
💻开发者论坛:https://forum.laf.run
关注 Laf 公众号与我们一同成长👇👇👇