导航:
【黑马Java笔记+踩坑汇总】Java基础+进阶+JavaWeb+SSM+SpringBoot+瑞吉外卖+SpringCloud+黑马旅游+谷粒商城+学成在线+设计模式+牛客面试题
目录
1. 关联查询优化
1.0 优化方案
1.1 数据准备
1.2 左外连接:优先右表创建索引,连接字段类型要一致
1.3 内连接:驱动表由数据量和索引决定
1.4 join语句原理
2. 子查询优化:拆开查询或优化成连接查询
1. 关联查询优化
1.0 优化方案
- 外连接小表驱动大表:LEFT JOIN 时,选择小表作为驱动表, 大表作为被驱动表 。减少外层循环的次数。
- 内连接驱动表由优化器决定:INNER JOIN 时,MySQL会自动将 小结果集的表选为驱动表 。选择相信MySQL优化策略。
- 被驱动表优先创建索引:被驱动表的JOIN字段要创建索引;
- 两表连接字段类型必须一致:两个表JOIN字段数据类型保持绝对一致。防止自动类型转换导致索引失效。
- 关联替代子查询:能够直接多表关联的尽量直接关联,不用子查询。(减少查询的趟数)。子查询是一个SELECT查询的结果作为另一个SELECT语句的条件。
- 多次查询代替子查询:不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用 JOIN 来代替子查询。
- 衍生表建不了索引
1.1 数据准备
# 分类
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
#向分类表中添加20条记录
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
#向图书表中添加20条记录
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
1.2 左外连接:优先右表创建索引,连接字段类型要一致
优先右表创建索引:因为左表是查所有数据,右表是按条件查询,所以右表的条件字段创建索引价值更高一点。
连接字段类型要一致:两个表的card字段一定要是同一类型,如果类型不同会导致隐式类型转换从而索引失效。
验证:
EXPLAIN 分析左外连接
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
结论:type 有All,全表扫描。
右表创建索引优化:
#ALTER TABLE book ADD INDEX Y ( card); #【被驱动表】,可以避免全表扫描 CREATE INDEX Y ON book(card); EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
可以看到第二行的 type 变为了 ref,rows 也变成了优化比较明显。这是由左连接特性决定的。LEFT JOIN 条件用于确定如何从右表搜索行,左边一定都有,所以 右边是我们的关键点,一定需要建立索引 。
左表创建索引优化:
ALTER TABLE `type` ADD INDEX X (card); #【驱动表】,无法避免全表扫描 EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
接着:
DROP INDEX Y ON book; EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;




1.3 内连接:驱动表由数据量和索引决定
内连接查到的是交集,两个表谁做驱动表查的结果是一样的。所以查询优化器会根据查询成本选择驱动表。驱动表就是主表,被驱动表就是从表
驱动表的选择依据:
- 没索引的表:当只有一个表有索引时,查询优化器会选择没索引的表作为驱动表。
- 小表:当两个表都有或都没有索引时,数据量小的表为驱动表。
验证:
drop index X on type; drop index Y on book;(如果已经删除了可以不用再执行该操作)inner join不加索引(MySQL自动选择驱动表)
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
book表添加索引优化,可以看到被驱动表是book表:
ALTER TABLE book ADD INDEX Y (card); EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;

type表添加索引, 可以看到被驱动表是type表:
ALTER TABLE type ADD INDEX X (card); EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
对于内连接来说,查询优化器可以决定谁作为驱动表,谁作为被驱动表出现的
删除type表索引,发现:
DROP INDEX X ON `type`; EXPLAIN SELECT SQL_NO_CACHE * FROM TYPE INNER JOIN book ON type.card=book.card;
接着:
ALTER TABLE `type` ADD INDEX X (card); EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;
接着:
#向图书表中添加20条记录 INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); ALTER TABLE book ADD INDEX Y (card); EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON `type`.card = book.card;
图中发现,由于type表数据大于book表数据,MySQL选择将type作为被驱动表。





1.4 join语句原理
join方式连接多个表,本质就是各个表之间数据的循环匹配。MySQL5.5版本之前,MySQL只支持一种表间关联方式,就是嵌套循环(Nested Loop Join)。如果关联表的数据量很大,则join关联的执行时间会很长。在MySQL5.5以后的版本中,MySQL通过引入BNLJ算法来优化嵌套执行。
1. 驱动表和被驱动表
驱动表就是主表,被驱动表就是从表、非驱动表。
- 对于内连接来说:
SELECT * FROM A JOIN B ON ...
A一定是驱动表吗?不一定,优化器会根据你查询语句做优化,决定先查哪张表。先查询的那张表就是驱动表,反之就是被驱动表。通过explain关键字可以查看。
- 对于外连接来说:
SELECT * FROM A LEFT JOIN B ON ...
# 或
SELECT * FROM B RIGHT JOIN A ON ...
通常,大家会认为A就是驱动表,B就是被驱动表。但也未必。测试如下:
CREATE TABLE a(f1 INT, f2 INT, INDEX(f1)) ENGINE=INNODB;
CREATE TABLE b(f1 INT, f2 INT) ENGINE=INNODB;
INSERT INTO a VALUES(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
INSERT INTO b VALUES(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
SELECT * FROM b;
# 测试1
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) WHERE (a.f2=b.f2);
# 测试2
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) AND (a.f2=b.f2);
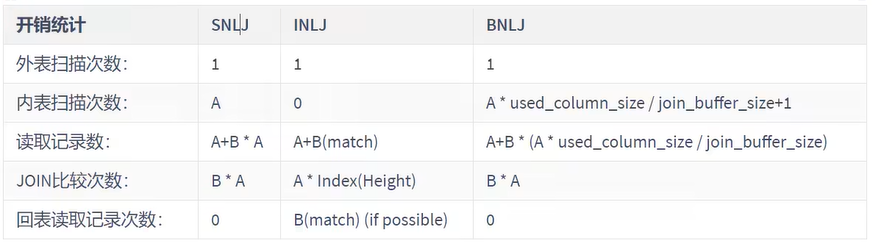
2. Simple Nested-Loop Join (简单嵌套循环连接)
算法相当简单,从表A中取出一条数据1,遍历表B,将匹配到的数据放到result.. 以此类推,驱动表A中的每一条记录与被驱动表B的记录进行判断:

可以看到这种方式效率是非常低的,以上述表A数据100条,表B数据1000条计算,则A*B=10万次。开销统计如下:
| 开销统计 | SNLJ |
|---|---|
| 外表扫描次数 | 1 |
| 内表扫描次数 | A |
| 读取记录数 | A+B * A |
| JOIN比较次数 | B * A |
| 回表读取记录次数 | 0 |
当然mysql肯定不会这么粗暴的去进行表的连接,所以就出现了后面的两种对Nested-Loop Join优化算法。
3. Index Nested-Loop Join (索引嵌套循环连接)
Index Nested-Loop Join其优化的思路主要是为了减少内存表数据的匹配次数,所以要求被驱动表上必须有索引才行。通过外层表匹配条件直接与内层表索引进行匹配,避免和内存表的每条记录去进行比较,这样极大的减少了对内存表的匹配次数。

驱动表中的每条记录通过被驱动表的索引进行访问,因为索引查询的成本是比较固定的,故mysql优化器都倾向于使用记录数少的表作为驱动表(外表)。

如果被驱动表加索引,效率是非常高的,但如果索引不是主键索引,所以还得进行一次回表查询。相比,被驱动表的索引是主键索引,效率会更高。
4. Block Nested-Loop Join(块嵌套循环连接)

注意:
这里缓存的不只是关联表的列,select后面的列也会缓存起来。
在一个有N个join关联的sql中会分配N-1个join buffer。所以查询的时候尽量减少不必要的字段,可以让join buffer中可以存放更多的列。

参数设置:
- block_nested_loop
通过show variables like '%optimizer_switch% 查看 block_nested_loop状态。默认是开启的。
- join_buffer_size
驱动表能不能一次加载完,要看join buffer能不能存储所有的数据,默认情况下join_buffer_size=256k。
mysql> show variables like '%join_buffer%';
join_buffer_size的最大值在32位操作系统可以申请4G,而在64位操作系统下可以申请大于4G的Join Buffer空间(64位Windows除外,其大值会被截断为4GB并发出警告)。
5. Join小结
1、整体效率比较:INLJ > BNLJ > SNLJ
2、永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量)(小的度量单位指的是表行数 * 每行大小)
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100; # 推荐
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100; # 不推荐
3、为被驱动表匹配的条件增加索引(减少内存表的循环匹配次数)
4、增大join buffer size的大小(一次索引的数据越多,那么内层包的扫描次数就越少)
5、减少驱动表不必要的字段查询(字段越少,join buffer所缓存的数据就越多)
6. Hash Join
从MySQL的8.0.20版本开始将废弃BNLJ,因为从MySQL8.0.18版本开始就加入了hash join默认都会使用hash join
-
Nested Loop:
对于被连接的数据子集较小的情况,Nested Loop是个较好的选择。
-
Hash Join是做大数据集连接时的常用方式,优化器使用两个表中较小(相对较小)的表利用Join Key在内存中建立散列表,然后扫描较大的表并探测散列表,找出与Hash表匹配的行。
- 这种方式适合于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。
- 在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要求有较大的临时段从而尽量提高I/O的性能。
- 它能够很好的工作于没有索引的大表和并行查询的环境中,并提供最好的性能。大多数人都说它是Join的重型升降机。Hash Join只能应用于等值连接(如WHERE A.COL1 = B.COL2),这是由Hash的特点决定的。

2. 子查询优化:拆开查询或优化成连接查询
MySQL从4.1版本开始支持子查询,使用子查询可以进行SELECT语句的嵌套查询,即一个SELECT查询的结果作为另一个SELECT语句的条件。 子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作 。
子查询是 MySQL 的一项重要的功能,可以帮助我们通过一个 SQL 语句实现比较复杂的查询。但是,子查询的执行效率不高。原因:
① 执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表 ,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
② 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都 不会存在索引 ,所以查询性能会 受到一定的影响。
③ 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
在MySQL中,可以使用连接(JOIN)查询来替代子查询。连接查询 不需要建立临时表 ,其 速度比子查询 要快 ,如果查询中使用索引的话,性能就会更好。
举例1:查询学生表中是班长的学生信息
- 使用子查询
# 创建班级表中班长的索引
CREATE INDEX idx_monitor ON class(monitor);
EXPLAIN SELECT * FROM student stu1
WHERE stu1.`stuno` IN (
SELECT monitor
FROM class c
WHERE monitor IS NOT NULL
)
- 推荐使用多表查询
EXPLAIN SELECT stu1.* FROM student stu1 JOIN class c
ON stu1.`stuno` = c.`monitor`
WHERE c.`monitor` is NOT NULL;
举例2:取所有不为班长的同学
- 不推荐
EXPLAIN SELECT SQL_NO_CACHE a.*
FROM student a
WHERE a.stuno NOT IN (
SELECT monitor FROM class b
WHERE monitor IS NOT NULL
);
执行结果如下:

- 推荐:
EXPLAIN SELECT SQL_NO_CACHE a.*
FROM student a LEFT OUTER JOIN class b
ON a.stuno = b.monitor
WHERE b.monitor IS NULL;

结论:尽量不要使用NOT IN或者NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代