- Elastic-Job
- 作业类型
- 创建任务并执行 :
- 启动流程
- 弹性分布式实现
Elastic-Job
elastic-job(quartz的扩展)使用了quartz的调度机制,内部原理一致,使用注册中心(zookeeper)替换了quartz的jdbc数据存储方式,支持分片等特殊功能
zk部署在有状态容器中会增加运维成本(或者可以先部署在非容器中)
- 分布式调度协调,去中心化(主节点选举机制)
- 无数据库瓶颈,性能高,任务数大且要求低延迟时,一般不需要做二次分发(只要划分更多的分片,分片粒度更细)
- 弹性扩容缩容
- 失效转移
- 错过执行作业重触发
- 作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
- 支持单独配置单个任务的策略配置
- 支持脚本任务
作业类型
- Simple 类型作业:Simple 类型用于一般任务的处理,只需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行,与Quartz原生接口相似。
- Dataflow 类型作业:Dataflow 类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
- Script类型作业:Script 类型作业意为脚本类型作业,支持 shell,python,perl等所有类型脚本。只需通过控制台或代码配置 scriptCommandLine 即可,无需编码。执行脚本路径可包含参数,参数传递完毕后,作业框架会自动追加最后一个参数为作业运行时信息
创建任务并执行 :
1)需要先设置zk的基本信息,Elastic-Job使用zookeeper来进行分布式管理,如选主、元数据存储与读取、分布式监听机制等。
2)创建一个执行任务的Job类,以Simple 类型作业为例,创建一个继承SimpleJob的类,在这个类中实现execute函数。
3)设置作业的基本信息,在JobCoreConfiguration 中设置作业的名称(jobName),作业执行的时间表达式(cron),总的分片数(shardingTotalCount);然后在SimpleJobConfiguration 中设置执行作业的Job类,最后定义Lite作业根配置
4)创建JobScheduler(作业调度器)实例,然后JobScheduler的init()方法中执行作业的初始化,这样作业就开始运行了。
启动流程
当多个节点运行时,先选择一个主节点,当到达执行时间后,每个实例开始执行任务,主节点负责分片的划分,其它节点等待划分完成,主节点将划分后的结果存放到zookeeper中,然后每个节点再从zookeeper中获取划分好的分片项,将分片信息作为参数,传入到本地的任务函数中,从而执行任务。
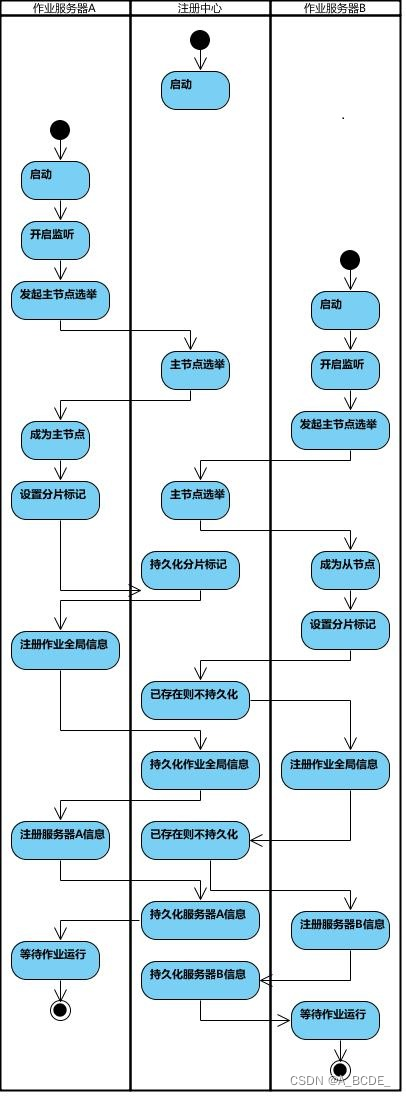
quartz内部定时器定时触发,获取本机的分片任务,执行分片任务,内部实现采用内存缓存和监听zookeeper事件来维护主节点和分片信息。
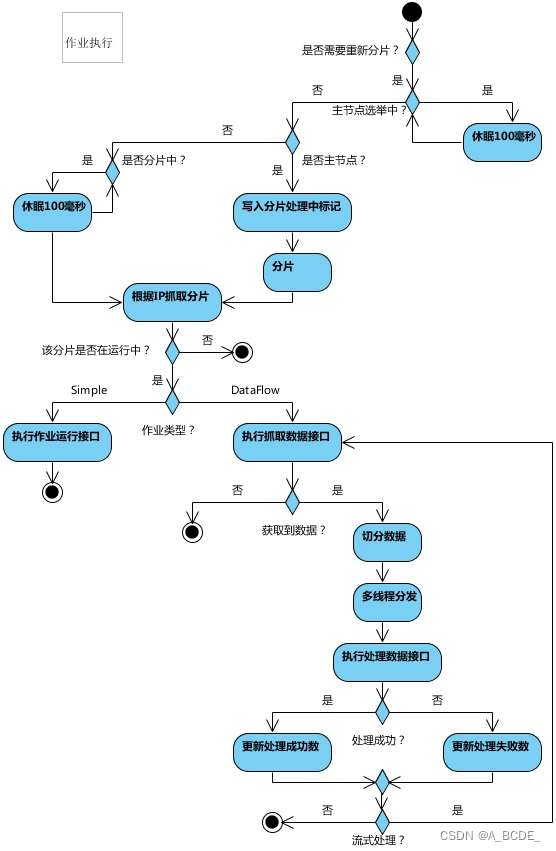
弹性分布式实现
第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
某作业服务器上线/下线时会自动将服务器信息注册/更新到注册中心
主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。