1. 存储过程概念
能够将完成特定功能的SQL指令进行封装(SQL指令集),编译之后存储在数据库服务器上,并且为之取一个名字,客户端可以通过名字直接调用这个SQL指令集,获取执行结果。
2. 存储过程优缺点
2.1 优点
(1)SQL指令无需经客户端编写通过网络传送,可以节省网络开销,同时避免使用SQL指令在网络传输过程中被恶意篡改从而保证安全性;
(2) 存储过程是经过编译创建并保存在数据库中的,执行过程无需重复的进行编译操作,对SQL指令的执行过程进行了性能提升;
(3)存储过程中多个指令之间可以存在逻辑关系,支持流程控制语句(分支、循环),能够实现较为复杂的业务。
2.2 缺点
(1)存储过程是根据不同的数据库进行编译、创建并存储在数据库中;但当需要切换到其他的数据库产品时,需要重新编写针对于新数据库的存储过程;
(2)存储过程受限于数据库产品,如果需要高性能的优化则会成为一个问题;
(3)在互联网项目中,如果需要数据库的高并发访问,使用存储过程会增加数据库的连接执行时间(因为将复杂业务交给了数据库进行处理)。
3. 创建存储过程
3.1 基本语法
CREATE PROCEDURE pro_name( [IN/OUT/INOUT param_name type] )
BEGIN
// ... 此处书写处理过程
END;
-- 创建存储过程
create procedure test1(IN a int, IN b int, OUT c int)
BEGIN
SET c = a + b;
END;
-- 调用存储过程
set @total = 0;
call test1(2,4,@total);
-- 查询变量total值
select @total from dual;
3.2 存储过程中变量的使用
存储过程中的变量分为2种:局部变量 和 用户变量。
(1)局部变量
定义在存储过程中的变量,只能在存储过程的内部使用。
语法:DECLARE 变量名 变量类型 [default value];
-- 计算输入参数的平方和输入参数/2 之和
create procedure test2(IN a int, OUT sum int)
begin
declare x int default 0;
declare y int default 0;
set x = a*a;
set y = a/2;
set sum = x + y;
end;
set @sum = 0;
call test2(4, @sum);
select @sum from dual;
(2)用户变量
相当于全局变量,定义的变量可以通过select @变量名 from dual;进行查询。
用户变量会存储在mysql数据库的数据字典中(dual)。
用户变量使用set关键字直接定义,格式 SET @变量名 = 值;
set @good = 111;
select @good from dual;
-- 创建存储过程
create procedure test1(IN a int, IN b int, OUT c int)
BEGIN
SET c = a + b;
END;
-- 调用存储过程
set @total = 0;
call test1(2,4,@total);
-- 查询变量total值
select @total from dual;
(3)为变量赋值
无论是局部变量还是用户变量,都是适应set关键字进行赋值。
(4)使用select...into...给变量赋值
将查询结果赋值给变量。
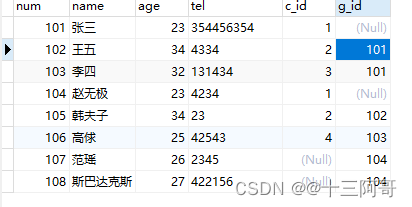
// 将查询的结果赋值给变量
// set res = select count(num) from student;
// 以上写法错误; 需通过select ... into... 语法来完成;
create procedure get_stu_count(OUT res int)
begin
select count(num) INTO res from student;
end;
set @count = 0;
call get_stu_count(@count);
select @count from dual;
3.3 存储过程中的参数
MySQL存储过程中一共有三种参数:IN、OUT、INOUT。
/* person表 */
/*
Navicat Premium Data Transfer
Source Server : localhost_3306
Source Server Type : MySQL
Source Server Version : 80016
Source Host : localhost:3306
Source Schema : tempdb
Target Server Type : MySQL
Target Server Version : 80016
File Encoding : 65001
Date: 21/05/2023 20:03:29
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for person
-- ----------------------------
DROP TABLE IF EXISTS `person`;
CREATE TABLE `person` (
`num` int(11) NULL DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`sex` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
(1)IN 参数
输入参数,在调用存储过程中传递数据给存储过程的参数,在调用过程中传递时必须为 具有实际值的变量 或 字面值。
-- 创建存储过程, 插入记录
create procedure add_person(IN stu_num int, IN stu_name varchar(10), IN stu_sex varchar(10))
begin
INSERT INTO person(num, name, sex) VALUES(stu_num, stu_name, stu_sex);
end;
call add_person(101, 'zhang', '男');
(2)OUT参数
输出参数,将存储过程中产生的数据返回给过程调用者,类似于java/c/c++中的函数的返回值,不同的是一个存储过程可以有多个输出参数。
-- 创建存储过程, 根据num查询学生姓名
create procedure get_person_by_num(IN stu_num int, OUT stu_name varchar(10))
begin
SELECT name INTO stu_name FROM student WHERE num = stu_num;
end;
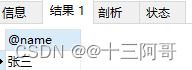
set @name = "";
call get_person_by_num(101, @name);
select @name from dual;
(3)INOUT参数
表示此参数既可以作为输入参数来使用,也可以作为输出参数来使用。
不推荐使用,阅读性较差。
-- 创建存储过程,根据名字查询性别
create procedure get_sex_by_name(INOUT temp varchar(10))
begin
select sex INTO temp from person where name = temp;
end;
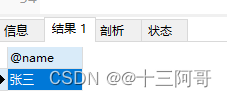
set @name = "张三";
call get_sex_by_name(@name);
select @name from person;
4. 存储过程中的流程控制
在存储过程中是 支持流程控制语句的, 用于实现逻辑的控制, 实现复杂的业务处理。
4.1 分支语句
(1)if…then…else…endif
if 条件 then
// SQL1
end if;
if 条件 then
// SQL1
else
// SQL2
end if;
-- 创建存储过程
-- 如果参数为1, 插入一条: 否则插入2条
create procedure test1(IN a int)
begin
if a=1 then
insert into person(num, name) values(102, "李四");
else
insert into person(num, name) values(105, "李四");
insert into person(num, name) values(106, "王五");
end if;
end;
call test1(1);
call test1(2);
(2)case语句
case 表达式
when 值1 then
-- SQL1
when 值2 then
-- SQL2
else
-- SQL3
end case;
-- 创建存储过程
create procedure test2(IN a int)
begin
case a
when 1 then
insert into person(num, name) values(1022, "李四四");
when 2 then
insert into person(num, name) values(1055, "毛五五");
insert into person(num, name) values(1066, "望六六");
else
update person set num=1011111 where name = 'zhang';
end case;
end;
call test2(1);
call test2(2);
call test2(3);
4.2 循环语句
(1)while语句
while 条件表达式 do
-- SQL1
-- SQL2
-- ...
end while;
-- 创建存储过程, 利用while循环批量插入数据
create procedure test3(IN count int)
begin
declare i int ;
set i = 111;
while i<count do
insert into person(num, name) values(i, '...');
set i = i + 1;
end while;
end;
call test3(115);
(2)repeat语句
repeat
-- SQL1
-- SQL2
until 条件表达式
end repeat;
-- 创建存储过程, 利用repeat循环批量插入数据
create procedure test4(IN count int)
begin
declare i int ;
set i = 116;
repeat
insert into person(num, name) values(i, '...');
set i = i + 1;
until i>count
end repeat;
end;
call test4(120);
(3)loop语句
// loop_label表示表注名;
// 通过leave关键字来退出loop循环;
loop_label: loop
-- SQL1
-- SQL2
-- ...
if 表达式 then
leave loop_label;
end if;
end loop;
-- 创建存储过程, 利用loop循环批量插入数据
create procedure test5(IN count int)
begin
declare i int ;
set i = 125;
MyLoop: loop
insert into person(num, name) values(i, '...');
set i = i + 1;
if(i>count) then
leave MyLoop;
end if;
end loop;
end;
call test5(130);
5. 存储过程管理操作
存储过程是隶属于某个数据库的,只能在创建它的数据库中去操作它。
5.1 查询存储过程
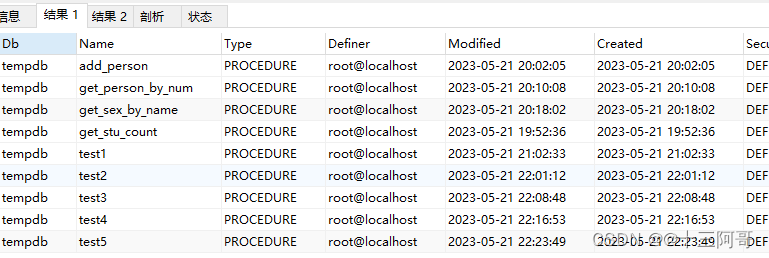
-- 查询指定数据库中的所有存储过程
show procedure status where db='tempdb';
-- 查询存储过程的创建细节
show create procedure tempdb.test1;

5.2 修改存储过程
指的是修改存储过程的特征/特性。
alter procedure 名字 特征1[特征2,特征3...]
存储过程的特征参数:
(1)CONTAINS SQL 表示⼦程序包含 SQL 语句,但不包含读或写数据的语句
(2)NO SQL 表示⼦程序中不包含 SQL 语句
(3)READS SQL DATA 表示⼦程序中包含读数据的语句
(4)MODIFIES SQL DATA 表示⼦程序中包含写数据的语句
(5)SQL SECURITY { DEFINER |INVOKER } 指明谁有权限来执⾏
DEFINER 表示只有定义者⾃⼰才能够执⾏
INVOKER 表示调⽤者可以执⾏
(6)COMMENT 'string' 表示注释信息
alter procedure test1 READS SQL DATA;
5.3 删除存储过程
drop procedure 名字;
-- 删除存储过程 test1
drop procedure test1;
6. 存储过程案例讲解
使用存储过程完成借书操作。
/*
Navicat Premium Data Transfer
Source Server : localhost_3306
Source Server Type : MySQL
Source Server Version : 80016
Source Host : localhost:3306
Source Schema : book_db
Target Server Type : MySQL
Target Server Version : 80016
File Encoding : 65001
Date: 21/05/2023 23:08:51
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for books
-- ----------------------------
DROP TABLE IF EXISTS `books`;
CREATE TABLE `books` (
`book_id` int(11) NOT NULL AUTO_INCREMENT,
`book_name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`book_author` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`book_price` decimal(10, 2) NOT NULL,
`book_stock` int(11) NOT NULL,
`book_desc` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`book_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of books
-- ----------------------------
INSERT INTO `books` VALUES (1, 'Java无难事', '孙鑫', 38.80, 12, '零基础讲解java');
INSERT INTO `books` VALUES (2, 'linux就该这么学', '鸟哥', 44.40, 9, '跟我从零开始学linux');
-- ----------------------------
-- Table structure for records
-- ----------------------------
DROP TABLE IF EXISTS `records`;
CREATE TABLE `records` (
`rid` int(11) NOT NULL AUTO_INCREMENT,
`snum` char(4) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`bid` int(11) NOT NULL,
`borrow_num` int(11) NOT NULL,
`is_return` int(11) NOT NULL,
`borrow_date` date NOT NULL,
PRIMARY KEY (`rid`) USING BTREE,
INDEX `FK_RECORDS_STUDENTS`(`snum`) USING BTREE,
INDEX `FK_RECORDS_BOOKS`(`bid`) USING BTREE,
CONSTRAINT `FK_RECORDS_BOOKS` FOREIGN KEY (`bid`) REFERENCES `books` (`book_id`) ON DELETE RESTRICT ON UPDATE RESTRICT,
CONSTRAINT `FK_RECORDS_STUDENTS` FOREIGN KEY (`snum`) REFERENCES `students` (`stu_num`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for students
-- ----------------------------
DROP TABLE IF EXISTS `students`;
CREATE TABLE `students` (
`stu_num` char(4) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`stu_name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`stu_gender` char(2) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`stu_age` int(11) NOT NULL,
PRIMARY KEY (`stu_num`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of students
-- ----------------------------
INSERT INTO `students` VALUES ('1001', '张三', '男', 20);
INSERT INTO `students` VALUES ('1002', '李四', '男', 20);
INSERT INTO `students` VALUES ('1003', '王五', '男', 20);
-- 实现借书业务:
-- 参数1: a 输入参数 学号
-- 参数2: b 输入参数 图书编号
-- 参数3: m 输入参数 借书的数量
-- 参数4: state 输出参数 借书的状态(1 借书成功,2 学号不存在,3 图书不存在,4 库存不足)
create procedure proc_borrow_book(IN a char(4), IN b int, IN m int, OUT state int)
begin
declare stu_count int default 0;
declare book_count int default 0;
declare stock int default 0;
-- 判断学号是否存在:根据参数 a 到学⽣信息表查询是否有stu_num=a的记录
select count(stu_num) INTO stu_count from students where stu_num=a;
if stu_count>0 then
-- 学号存在
-- 判断图书ID是否存在:根据参数b 查询图书记录总数
select count(book_id) INTO book_count from books where book_id=b;
if book_count >0 then
-- 图书存在
-- 判断图书库存是否充足?查询当前图书库存,然后和参数m进行比较
select book_stock INTO stock from books where book_id=b;
if stock >= m then
-- 执行借书
-- 操作1:在借书记录表中添加记录
insert into records(snum,bid,borrow_num,is_return,borrow_date) values(a,b,m,0,sysdate());
-- 操作2:修改图书库存
update books set book_stock=stock-m where book_id=b;
-- 借书成功
set state=1;
else
-- 库存不足
set state=4;
end if;
else
-- 图书不存在
set state = 3;
end if;
else
-- 不存在
set state = 2;
end if;
end;
-- 调用存储过程借书
set @state=0;
call proc_borrow_book('1001',1,2,@state);
select @state from dual;

7. 游标
游标可以⽤来依次取出查询结果集中的每⼀条数据——逐条读取查询结果集中的记录。
就类似于c++、java中的迭代器。
7.1 使用步骤
(1)声明游标
declare 游标名 cursor for select_statemnt;
(2)打开游标
open 游标名;
(3)使用游标
fetch 游标名 into var_name[,var_name] ... {参数名称};
(4)关闭游标
close 游标名;
-- 游标使用案例
create procedure use_cursor(OUT res varchar(100))
begin
declare bname varchar(20);
declare bauthor varchar(20);
declare bprice decimal(10, 2);
declare count int default 0;
declare i int default 0;
declare string varchar(100);
select count(1) INTO count from books;
-- 声明游标
declare MyCursor cursor for select book_name, book_author, book_price from books;
-- 打开游标
open MyCursor;
while i < count do
-- 使用游标, 提取游标当前指向的记录(提取后, 游标自动向下移)
fetch MyCursor INTO bname, bauthor, bprice;
set i = i + 1;
-- set string = CONCAT_WS('#', bname, bauthor, bprice);
select CONCAT_WS('#', bname, bauthor, bprice) INTO string;
set res = CONCAT_WS(',', res, string);
end while;
-- 关闭游标
close MyCursor;
end;
set @temp="";
call use_cursor(@temp);
select @temp from dual;

8. 存储函数
8.1 基本语法
CREATE FUNCTION fun_name([arg1,arg2...])
RETURNS 类型
[characteristic...]
BEGIN
// ... 此处书写处理过程
END;
// RETURNS 表示函数返回数据的类型,
// RETURNS 子句只能对FUNCTION做指定, 对于函数而言, 这是强制的;
// 它用来指定函数的返回类型, 而且函数体必须包含一个RETURN value语句;
// FUNCTION中参数总是默认为IN类型的, 不能是其他类型的(OUT/INOUT), 也不能显式的指定为IN类型的, 否则报错;
// 如何调用函数?
// 在MySQL中, 存储函数的使用方法与MySQL内部函数的使用方法是一致的.
-- 根据id查询对应的书名
drop function if exists test_fun1;
create function test_fun1(id int)
returns varchar(100)
READS SQL DATA
begin
declare name varchar(20);
select book_name INTO name from books where book_id=id;
return name;
end;
select test_fun1(1);
select test_fun1(2);
select test_fun1(22);