前言
在阅读这篇文章的时候,我花费了近一周的时间在将其基本消化理解,至于为什么花费如此长的时间,我发现主要原因是我对transformer一知半解,所以在transformer中提出的名词,例如:Postion-Wise Feed-Forward、PE编码等都不了解,最终导致论文看起来比较吃力,如果你也想理解这篇论文的话,你最好对transformer有一个比较全面的了解
论文地址
代码地址
文章目录
- 前言
- @[TOC](文章目录)
- 一、本论文解决了什么
- 二、Scene Text Telescope (SST)模型框架
- 三、Pixel-Wise Supervision Module 像素级超分辨率模块
- 四、Position-Aware Module位置感知模块
- 五、Content-Aware Module内容感知模块
- 六、源码测试
文章目录
- 前言
- @[TOC](文章目录)
- 一、本论文解决了什么
- 二、Scene Text Telescope (SST)模型框架
- 三、Pixel-Wise Supervision Module 像素级超分辨率模块
- 四、Position-Aware Module位置感知模块
- 五、Content-Aware Module内容感知模块
- 六、源码测试
一、本论文解决了什么
在本论文提出之前,所用到解决文本超分辨率的方法均是使用通用的超分辨率框架来处理场景文本图像,忽略了文本特定的属性。
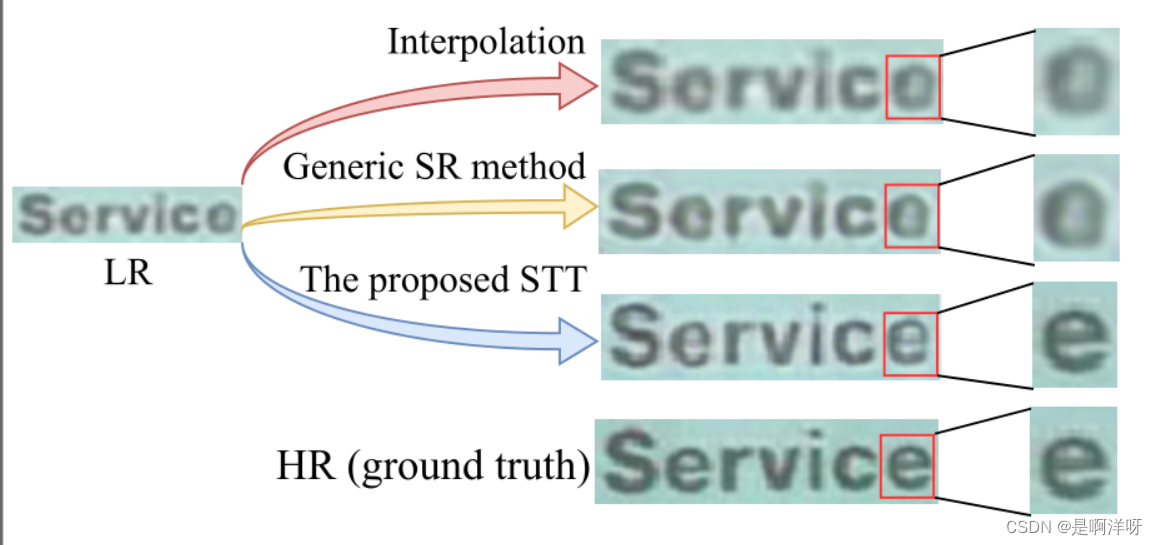
本论文考虑了文本特定的属性设计了一个用于改善低焦距拍摄造成的文本图像模糊的超分辨率框架 Scene Text Telescope (STT),其主要的作用是将低分辨率(low-resolution)的文本图像,转化为超分辨率的图像(super-resolution)。如下图文本中的“Service”的最后一个单词“e”,在LR的情况下很容易被识别成“o”,经过SST的恢复,将模糊的文本变的很清晰。
二、Scene Text Telescope (SST)模型框架
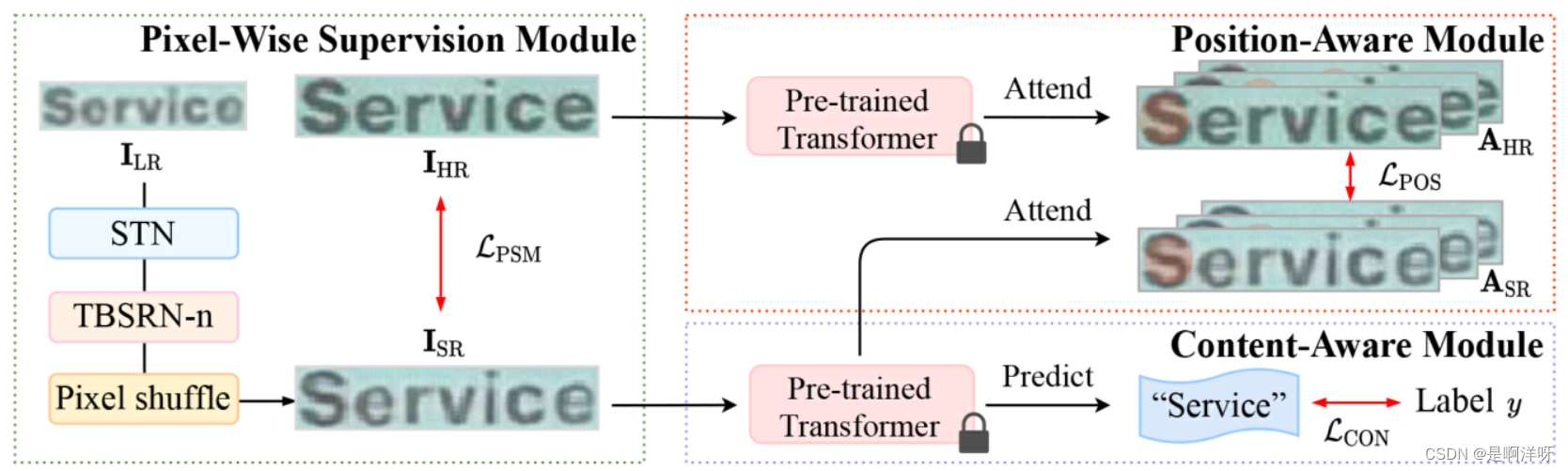
SST的总体框架如下图所示,主要由像素级超分辨率模块(Pixel-Wise Supervision Module)、位置感知模块(Position-Aware Module)、内容感知模块(Content-Aware Module)三部分组成,下面对这三部分模块进行分析
三、Pixel-Wise Supervision Module 像素级超分辨率模块
Pixel-Wise Supervision Module是SST的核心部分。其处理文本的流程为:文本首先让一张低分辨率的文本图像首先放入Spatial Transformer Network(STN)中进行矫正,来增加模型对于空间变化的鲁棒性,简单来说就是,STN可以将倾斜、移位等出现空间几何变换的图像矫正,示意图如下:

紧接着将矫正后的图片,放入基于transformer的超分辨率网络(Transformer-Based Super-Resolution Network )(TBSRNT)
该TBSRN网络主要使用了Self-attention模块和一个Position-Wise Feed-forward模块,模型图如下:
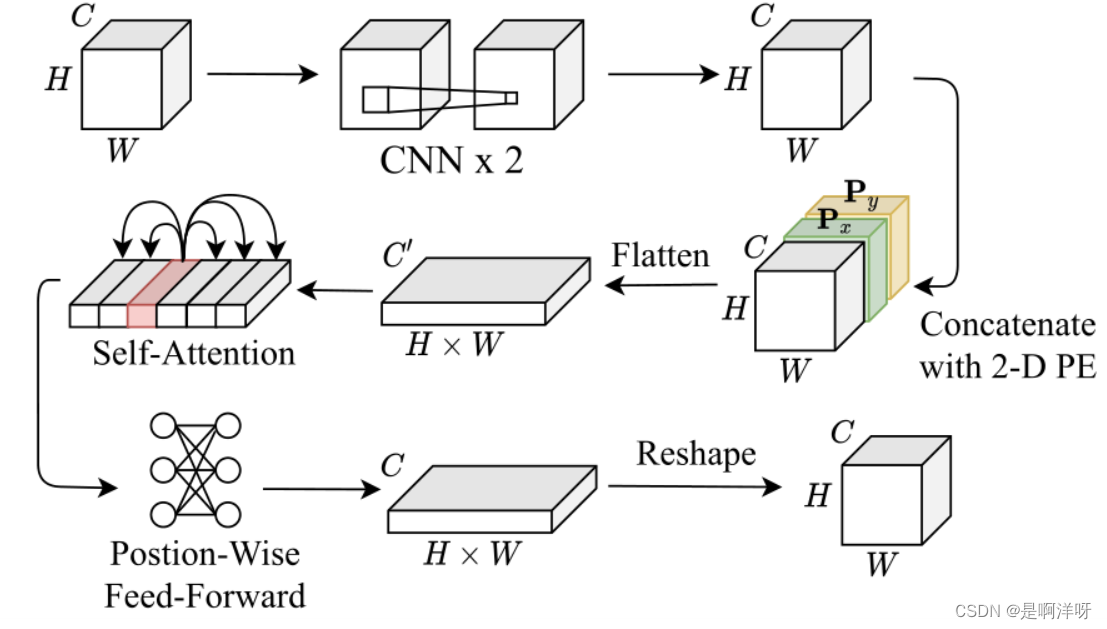
TBSRNT首先是将图W×H×C的三维图像矩阵通过两个连续的CNN来提取特征,然后通过二维PE编码,生成位置信息,并将位置信息矩阵和图像矩阵加在一起,之后做了一个Flatten操作,将三维矩阵转化为二维后,通过自注意力使其更专注文本区域,然后将自注意力生成的序列通过Postion-Wise Feed-Forward进行语义转化后,通过Reshape得到一张feature map。
之后通过pixel shuffle的上采样方式,得到超分辨率图像
四、Position-Aware Module位置感知模块
本质上提前将识别模型进行预训练,从而使其能更好的感知图像的文本位置信息。作者通过Syn90k和SynthText两个数据集进行预训练attention maps模型
五、Content-Aware Module内容感知模块
与Position-Aware Module相同,也是利用一个文本数据集EMNIST,来预训练Transformer模型,首先使用EMNIST训练一个变分自动编码器VAE,获得每个字符的位置编码,这里的VAE可以理解为训练26个英文字母和10个数字放在一个二维的表格中,外表越像的,例如“0”和“o”、“c”和“e”,之间的距离就会越近。
然后,作者采用了交叉熵损失函数,使模型更关注外表相近的字母
这里Cij=1/欧氏距离,也就是说,当两个文字在上面的二维表中,距离越近时,aj就越大
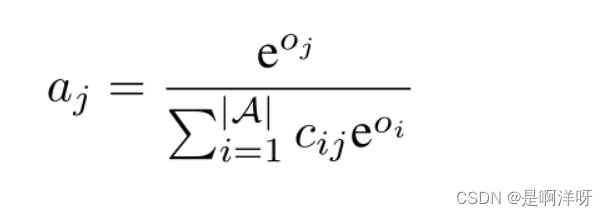
紧接着作者设置了损失函数,这样的话,训练模型就会更加关注长得接近的文字
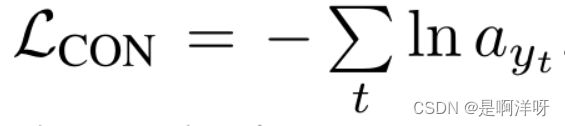
六、源码测试
我将作者给的源码和训练好的模型下载出来跑了一下,本以为代码是效果图,代码跑通后只显示了测试集的精度,如果想将测试图片可视化,需要修改代码。




![[附源码]JAVA毕业设计机房预约系统(系统+LW)](https://img-blog.csdnimg.cn/6d1443d06f64410ca995f97ceffa0cfb.png)




![php万年历源代码!源代码![上一年、上一月、下一月、下一年、附加当天日期加背景颜色]-私聊源码](https://img-blog.csdnimg.cn/d4b168e82c414a2f85f8ee4015d51b5c.png)