CIDER全名:Learning Inverse Depth Regression for Multi-View Stereo with Correlation Cost Volume,AAAI 2020(CCF A)
本文是MVSNet系列的第6篇,建议看过【论文精读1】MVSNet系列论文详解-MVSNet之后再看便于理解。
一、问题引入
- 针对问题:还是可扩展性(scalability),即代价体构建和正则化消耗的内存资源过大。
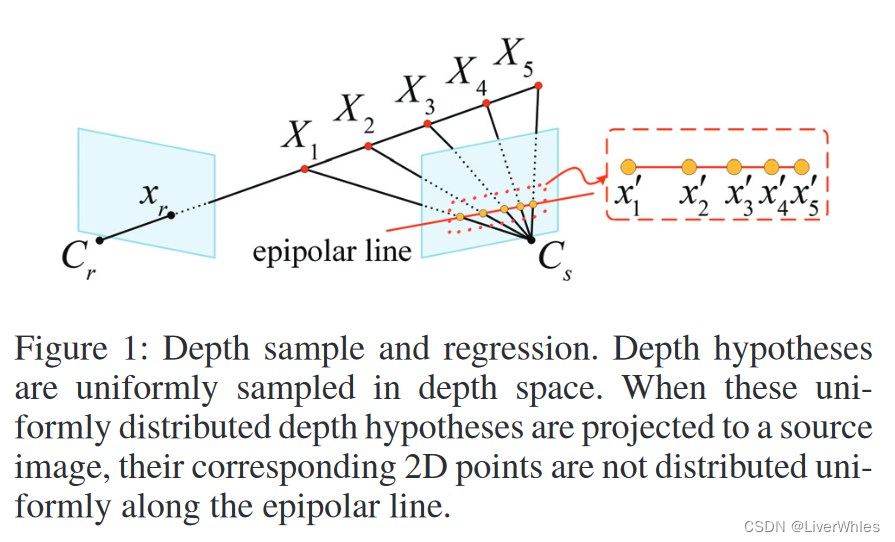
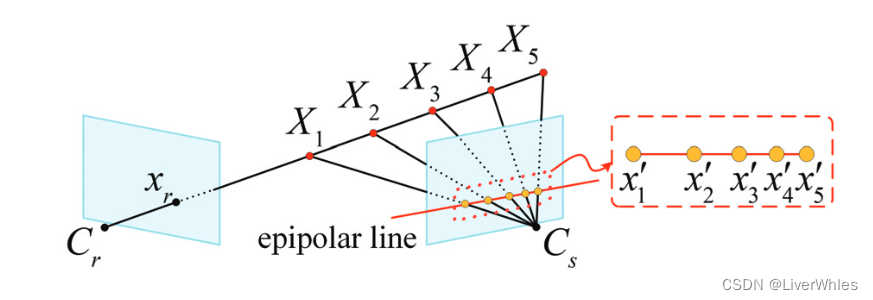
- 如上图所示,深度回归问题设定(depth regression)下存在的不鲁棒问题——将深度推断看作深度回归问题,在深度空间均匀采样深度平面,但其在成像平面级线上所对应的点并非均匀分布。
- 靠近相机中心的深度假设,其对应的特征可能不在源图像的深度特征中
- 多个远离相机中心的深度假设,所对应的源图像特征可能是同一个非常相似的,因为距离越远采样点逐渐逼近
二、创新点
- 受立体匹配(stereo matching)当中组相关(group-wise correlation)方法的启发,提出了一个平均组相关相似性度量(average group-wise correlation similarity measure)来构建一个轻量级代价体。不仅减少了内存消耗,同时降低了在代价体滤波时的计算压力。
- 基于以上有效的代价体表示,提出一个级联(cascade) 3d Unet模块以正则化代价体来提高性能。
- 先前方法将深度图推断看作一个深度回归问题或是逆深度分类问题(inverse depth classification problem),本文将其改为一个逆深度回归任务(inverse depth regression task),从而实现亚像素精度估计(sub-pixel estimation)同时可以被应用到更大尺度的场景。
- 深度回归(depth regression),在深度空间均匀采样深度平面且能达到亚像素精度,但不鲁棒
- 逆深度分类(inverse depth classfication),无法达到亚像素精度,经常导致阶梯效应
三、论文模型
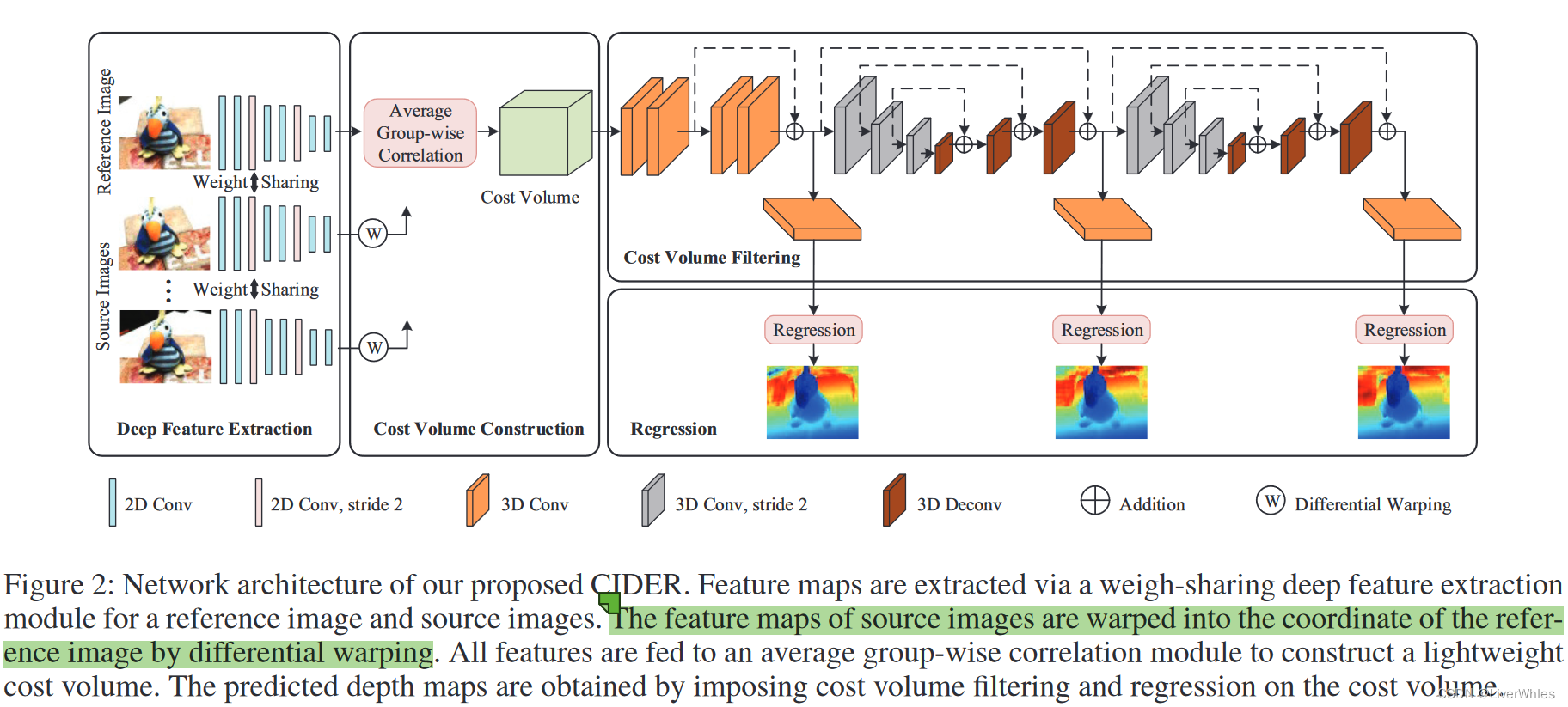
1.深度特征提取
与MVSNet一样采用权重共享的深度网络提取特征。
2.代价体构建
- 首先指出原始MVSNet在代价体进行正则化时第一步是将特征通道数由32->8,且有人实验发现8通道即可达到相似精度,因此直接构建8通道代价体减少计算量和内存消耗
- 本质上该步骤还是计算相似度,但将MVSNet中的方差计算相似度替代为内积计算相似度。
- 方差是所有源、参考特征图对应位置都平等参与计算得到方差,方差越小越相似;
- 平均组关联则是对32通道特征分为8组,让源视图的各组与所有源视图的对应组做内积计算出相似度图,最后在利用均值方法把各组某个深度下的相似度计算平均值
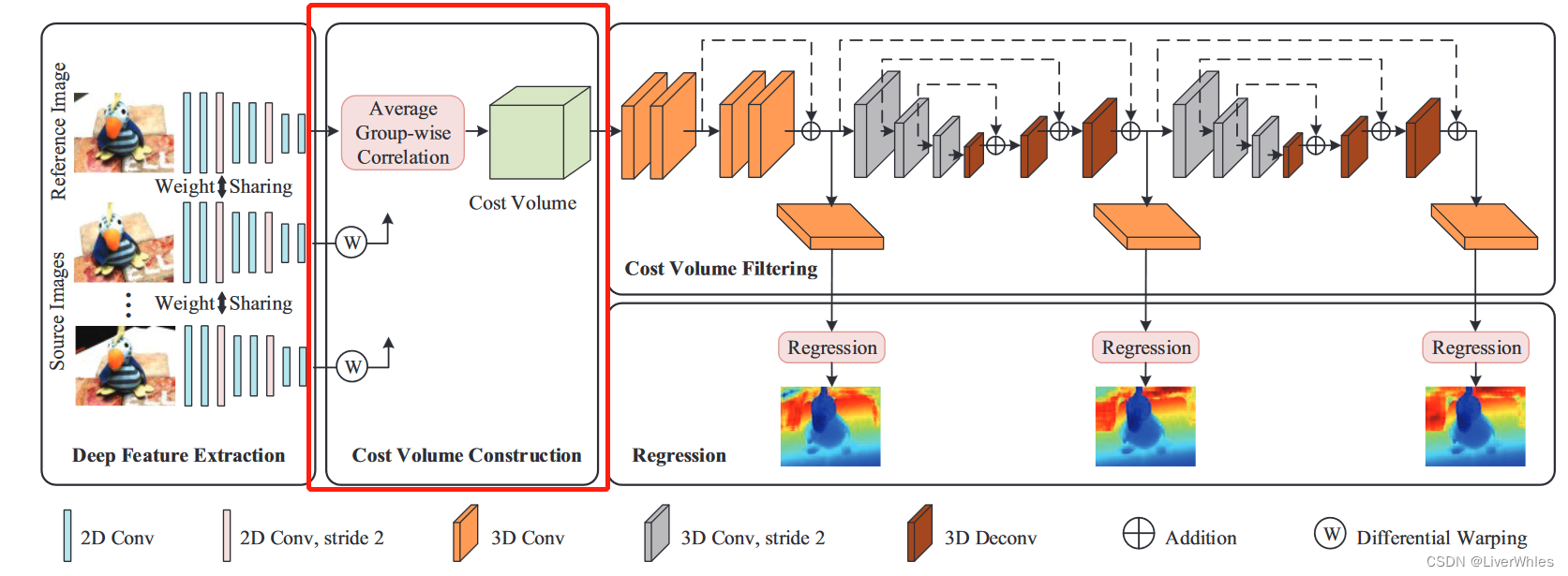
2.1 单应变换
详细讲述了MVSNet中代价体构建的真正过程,即将参考图上各像素坐标转为源视图下的坐标值(变量是参考视图的深度d),并将源视图下对应坐标的深度特征值赋给参考图的对应坐标下。建议看原论文加深理解。
2.2 平均组关联度量(average group-wise correlation similarity measure)
S i , j g = 1 32 / G ⟨ F r e f g , F ~ i , j g ⟩ S^{g}_{i,j}=\frac{1}{32/G}\langle{F^{g}_{ref}},{\tilde{F}^{g}_{i,j}}\rangle Si,jg=32/G1⟨Frefg,F~i,jg⟩
首先,将源视图和参考视图的32通道深度特征的分为G组(g=1,2,…,G),Frefg代表参考视图在第g组的特征,Fi,jg‘代表源视图下对应的组特征,i代表第i张源视图,j代表深度,<>代表内积操作,因此对参考视图的每个假设深度j下,其第g组特征对应源视图i可计算组相似度图Si,jg。
2.3 代价体生成
(1)利用2.2的组关联相似度量,对每张源视图i,在每个深度j下可构建G张相似度图Si,jg,则对于D个深度平面下最终构成代价体Vi尺度为 [G, H/4, W/4, D];
(2)为了适应任意张源视图输入采用平均的方式将N-1张源视图特征体通过各组上平均获取最终的代价体(尺度不变),即
V
=
1
N
−
1
∑
i
=
1
N
−
1
V
i
V=\frac{1}{N-1}\sum^{N-1}_{i=1}V_{i}
V=N−11i=1∑N−1Vi
3.代价体滤波(Cost Volume Filtering)
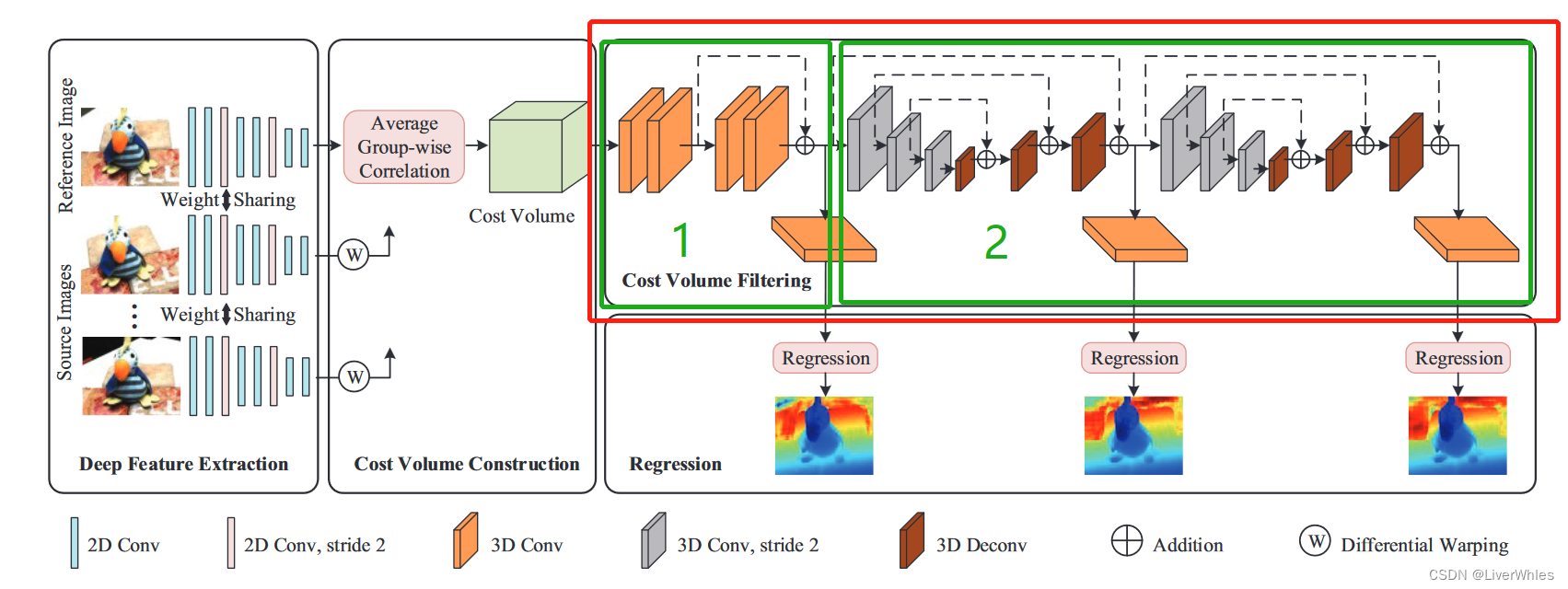
- 使用一个级联的3D Unet网络来正则化代价体以获取概率体,包含两个模块
- 一个残差模块和回归模块来学习更好的特征表示
- 两个级联的Unet,通过自顶向下/自底向上的重复处理结构学习更多的上下文信息
- 论文强调,由于代价体表示带来的巨大内存消耗,之前的MVSNet和R-MVSNet都没有用过这样的结构,因而使得他们聚合的上下文信息有限。
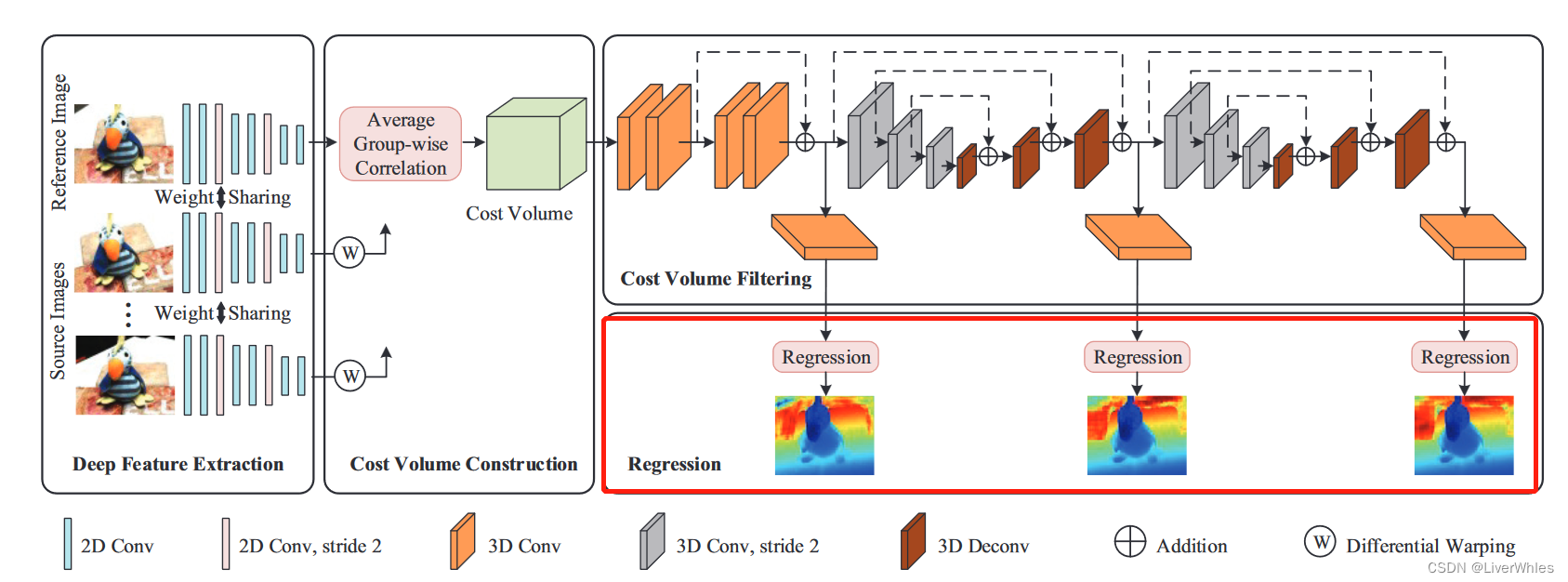
4.逆深度回归(Inverse Depth Regression)
这部分本质上是改变了选取深度采样值的方法(均匀深度采样->逆深度采样)
4.1 深度均匀采样存在的问题
论文指出,MVSNet通过将深度图推断看作深度回归问题均匀采样深度平面,并使用soft argmin的方式实现了亚像素估计(深度值连续,简单理解就是包含小数点),但这还是存在问题的——深度空间的均匀采样在成像平面的级线上对应的像素点距离并不均匀,如下图所示,距离相机平面越远,同样距离的3D点对应在另一视角下的2D点间距离逐渐逼近,这就导致了文首提到的两个问题
- 靠近相机中心的深度假设,其对应的特征可能不在源图像的深度特征中
- 多个远离相机中心的深度假设,所对应的源图像特征可能是同一个非常相似的,因为距离越远采样点逐渐逼近
4.2 逆深度采样
为了解决上图当中的深度均匀、像素距离不均匀的问题,使分布在源视图级线上的像素点尽可能均匀分布,在深度采样时使用离散的inverse depth采样方式来选取深度假设平面,公式表述为:
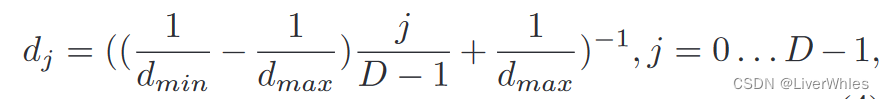
通过这样选取的深度值与原来相比,最小最大深度不变,深度样本数不变,改变的是当中每一个深度假设的值——原来可能是在【1,100】上均匀采样得到【1,2,3…100】,但这种采样结果可能为【1,3,5.5,8…100】,虽然深度间隔不一致了,但是它们在对应深度对应到源视图上各点的像素距离是逼近均匀分布的,而这种采样方式就称为“逆深度设置”(inverse depth setting)
4.3 逆深度回归
通过4.2的逆深度方式对深度假设值进行采样后,通过正常的单应变换以及组相关代价体的构建、滤波得到概率体,随后进行各像素点的回归深度。
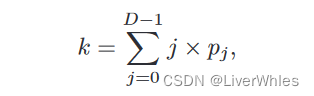
这一步骤不是直接求各像素点上概率与当前深度假设的期望,而是先用期望求一个亚像素序数k(代表最终的期望深度层)
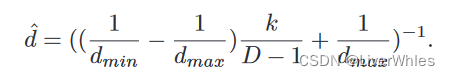
然后再利用该序数k代表的期望深度层,代入逆深度采样的公式来求得最终的深度值。
引入这个亚像素序数K,就是先判断当前像素点期望属于第几个逆深度采样的层(可能带小数),然后再代入逆深度公式确定最终深度;与直接对深度期望感觉没有很大的区别或者是必要性??希望理解的朋友留言提醒一下😢😢
5.损失函数
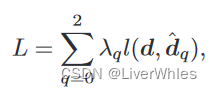
还是使用平均绝对误差计算推测深度图和真实深度图的损失,只不过对3个阶段输出的深度图损失做了一个甲醛。
四、实验效果
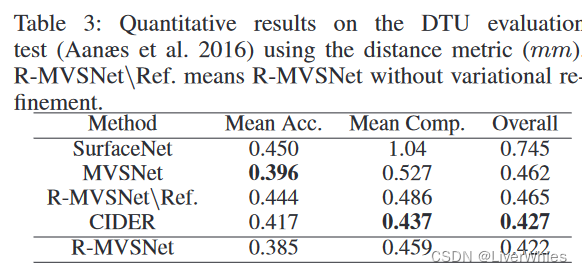

在DTU数据集上取得了最佳的完整度和overall,但精度还不如MVSNet。
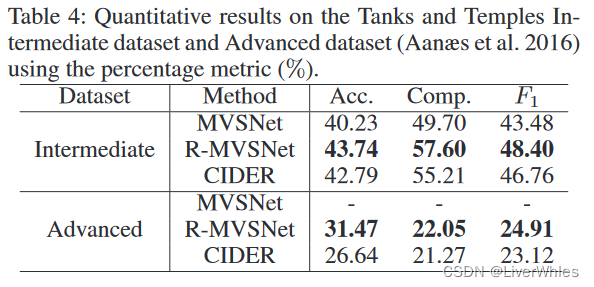
在Tanks数据集上效果都不如R-MVSNet,尽管论文说这是R-MVSNet在网络输出之后细分优化所带来的加成。
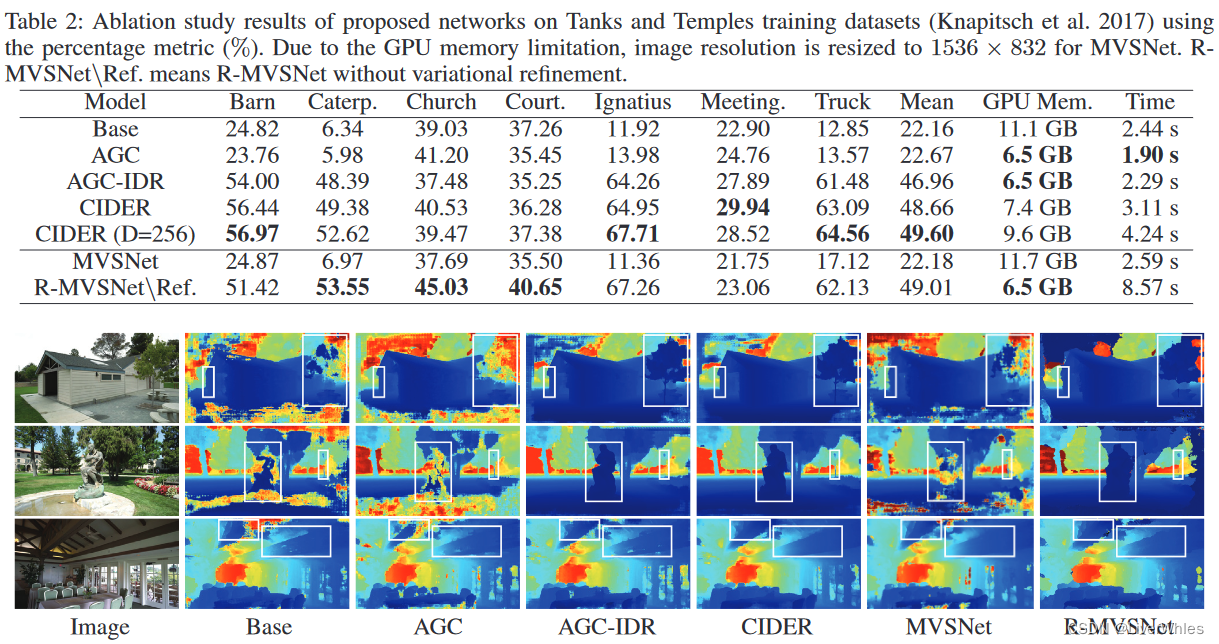
- AGC是指加了Average Group-wise Correlation,IDR是指加了Inverse Depth Regression
- 在Tanks数据集上的消融实验结果如上图,从数据上来说并不比R-MVSNet好,内存消耗相比MVSNet小但比R-MVSNet大
- 论文指出亮点在于相比R-MVSNet,CIDER对于边缘部分和模糊区域的重建效果更好(比如雕塑、树的边缘部分,以及深度均匀的区域)
五、总结
- 从理论上看,这篇论文观察并指出了“深度均匀采样并不代表对应搜索像素点均匀分布”的现象,并使用逆深度采样的方式减轻这样的问题
- 但个人理解,其实这个现象(离相机越远,同样的深度间隔对应的两个搜索点间距离变小)是摄影几何本身的一个特点,并不会影响重建的精度——当你均匀采样深度平面且到了深度较大时候(在另一个视角下靠近视平面右边缘),同样深度间隔对应的像素点本身就很相似,你使用逆深度采样、只是采样的深度间隔改变了,但并不会使这个对应过程更精确。
- 反映在DTU数据集上,使用逆深度采样的方法精度甚至不如初始的MVSNet,说明这个理解应该是合理的。
- 那么这个逆采样的作用在哪?它在于提升了搜索不同特征像素点的个数。即均匀采样到后期深度其实都是对应到很近似特征的几个点上,而逆采样保证你所“试探”的深度值对应的二维像素点的特征都是不同的(相隔较远),因此提高了可试探特征的数量,更容易找到真实的深度对应。
- 反映在DTU数据集上,逆深度采样的方法较高的提高了重建完整度,我认为就是因为它的搜索范围增大带来的提升。
- 从结果上来看,DTU精度不如MVSNet,但完整度、overall最佳;Tanks上比不过RMVSNet(尽管说是由于后续细分优化),内存消耗、时间消耗也都说不上是最好,只是在边缘区域的重建效果更好一些;
- 作为2020年的一篇MVSNet优化,在效果上也未与2019另外几篇好的(PointMVSNet、P-MVSNet、MVSCRF)作比较
- 可能是因为AAAI比较偏向与理论型选手?这篇论文的组平均相关度量构建代价体当然算一个创新点,但其中的分组、内积代表相似度其实并不是太新,重点在于强调为什么需要逆深度采样(两个均匀),但逆深度好像也是之前就有的?最好效果上也只是提高了完整度,内存消耗和时间上没有太大提升😢😢

![[附源码]JAVA毕业设计机房预约系统(系统+LW)](https://img-blog.csdnimg.cn/6d1443d06f64410ca995f97ceffa0cfb.png)




![php万年历源代码!源代码![上一年、上一月、下一月、下一年、附加当天日期加背景颜色]-私聊源码](https://img-blog.csdnimg.cn/d4b168e82c414a2f85f8ee4015d51b5c.png)