- 🍨 本文为🔗365天深度学习训练营 内部限免文章(版权归 K同学啊 所有)
- 🍦 参考文章地址: 🔗第P3周:天气识别 | 365天深度学习训练营
- 🍖 作者:K同学啊 | 接辅导、程序定制
文章目录
- 我的环境:
- 一、前期工作
- 1. 设置 GPU
- 2. 导入数据
- 3. 划分数据集
- 二、构建简单的CNN网络
- 三、训练模型
- 1. 设置超参数
- 2. 编写训练函数
- 3. 编写测试函数
- 4. 正式训练
- 四、结果可视化
我的环境:
- 语言环境:Python 3.6.8
- 编译器:jupyter notebook
- 深度学习环境:
- torch==0.13.1、cuda==11.3
- torchvision==1.12.1、cuda==11.3
一、前期工作
1. 设置 GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms,datasets
import os,PIL,pathlib
device = torch.device("cuda" if torch.cuda.is_available() else "cp")
device
device(type='cuda')
2. 导入数据
import os,PIL,random,pathlib
data_dir = 'D:/jupyter notebook/DL-100-days/datasets/weather_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("\\")[5] for path in data_paths]
classNames
['cloudy', 'rain', 'shine', 'sunrise']
total_datadir = 'D:/jupyter notebook/DL-100-days/datasets/weather_photos/'
train_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225])
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1125
Root location: D:/jupyter notebook/DL-100-days/datasets/weather_photos/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
torch.Size([32, 3, 32, 32])
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset,test_dataset = torch.utils.data.random_split(total_data,[train_size,test_size])
train_dataset,test_dataset
(<torch.utils.data.dataset.Subset at 0x2700e413988>,
<torch.utils.data.dataset.Subset at 0x2700e413848>)
train_size,test_size
(900, 225)
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X,y in test_dl:
print("Shape of X [N,C,H,W]: ",X.shape)
print("Shape of y: ",y.shape,y.dtype)
break
Shape of X [N,C,H,W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
二、构建简单的CNN网络
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn,self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=12,kernel_size=5,stride=1,padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12,out_channels=12,kernel_size=5,stride=1,padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(12)
self.conv4 = nn.Conv2d(in_channels=12,out_channels=24,kernel_size=5,stride=1,padding=0)
self.bn1 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24,out_channels=24,kernel_size=5,stride=1,padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*50*50,len(classNames))
def forward(self,x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1,24*50*50)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
model
Using cuda device
Network_bn(
(conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(bn1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): MaxPool2d(kernel_size=12, stride=12, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))
(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc1): Linear(in_features=60000, out_features=4, bias=True)
)
三、训练模型
1. 设置超参数
loss_fn= nn.CrossEntropyLoss() #创建损失函数
learn_rate = 1e-4#学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
2. 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
3. 编写测试函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
4. 正式训练
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
Epoch: 1, Train_acc:61.4%, Train_loss:0.986, Test_acc:72.0%,Test_loss:0.865
Epoch: 2, Train_acc:76.7%, Train_loss:0.674, Test_acc:83.6%,Test_loss:0.558
Epoch: 3, Train_acc:80.8%, Train_loss:0.561, Test_acc:88.4%,Test_loss:0.447
Epoch: 4, Train_acc:83.6%, Train_loss:0.485, Test_acc:90.2%,Test_loss:0.431
Epoch: 5, Train_acc:86.3%, Train_loss:0.423, Test_acc:89.8%,Test_loss:0.354
Epoch: 6, Train_acc:86.3%, Train_loss:0.418, Test_acc:88.4%,Test_loss:0.306
Epoch: 7, Train_acc:87.6%, Train_loss:0.389, Test_acc:88.4%,Test_loss:0.401
Epoch: 8, Train_acc:90.0%, Train_loss:0.340, Test_acc:92.9%,Test_loss:0.488
Epoch: 9, Train_acc:90.7%, Train_loss:0.321, Test_acc:92.4%,Test_loss:0.260
Epoch:10, Train_acc:91.0%, Train_loss:0.316, Test_acc:92.9%,Test_loss:0.240
Epoch:11, Train_acc:92.6%, Train_loss:0.288, Test_acc:93.3%,Test_loss:0.254
Epoch:12, Train_acc:91.3%, Train_loss:0.291, Test_acc:92.4%,Test_loss:0.231
Epoch:13, Train_acc:93.9%, Train_loss:0.238, Test_acc:92.4%,Test_loss:0.226
Epoch:14, Train_acc:93.9%, Train_loss:0.255, Test_acc:93.3%,Test_loss:0.200
Epoch:15, Train_acc:93.7%, Train_loss:0.239, Test_acc:94.7%,Test_loss:0.236
Epoch:16, Train_acc:93.4%, Train_loss:0.224, Test_acc:93.3%,Test_loss:0.201
Epoch:17, Train_acc:94.1%, Train_loss:0.265, Test_acc:94.7%,Test_loss:0.187
Epoch:18, Train_acc:93.7%, Train_loss:0.222, Test_acc:94.2%,Test_loss:0.193
Epoch:19, Train_acc:95.4%, Train_loss:0.224, Test_acc:93.8%,Test_loss:0.199
Epoch:20, Train_acc:95.1%, Train_loss:0.201, Test_acc:93.3%,Test_loss:0.175
Done
四、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
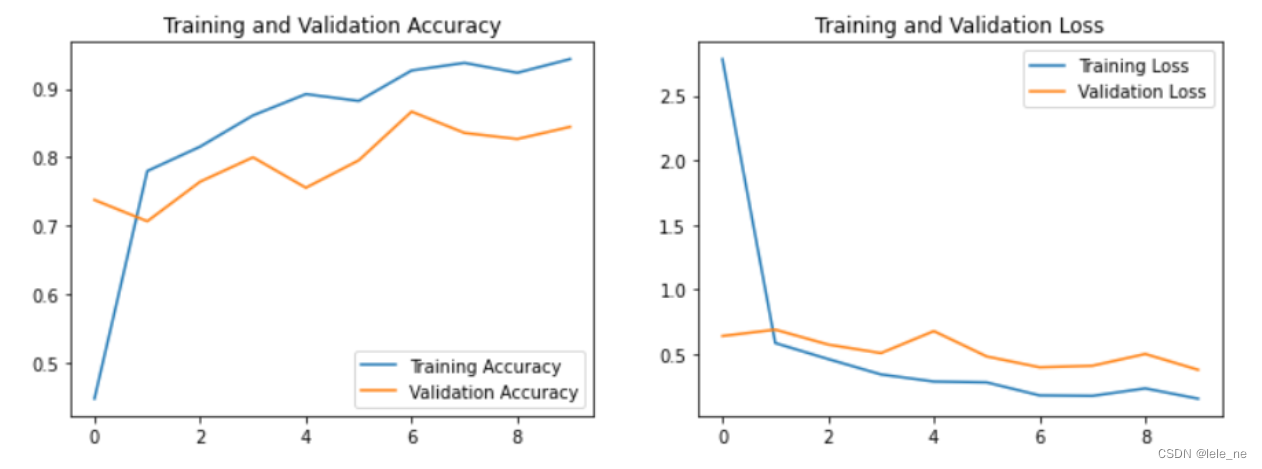
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()




![[附源码]JAVA毕业设计机房预约系统(系统+LW)](https://img-blog.csdnimg.cn/6d1443d06f64410ca995f97ceffa0cfb.png)




![php万年历源代码!源代码![上一年、上一月、下一月、下一年、附加当天日期加背景颜色]-私聊源码](https://img-blog.csdnimg.cn/d4b168e82c414a2f85f8ee4015d51b5c.png)