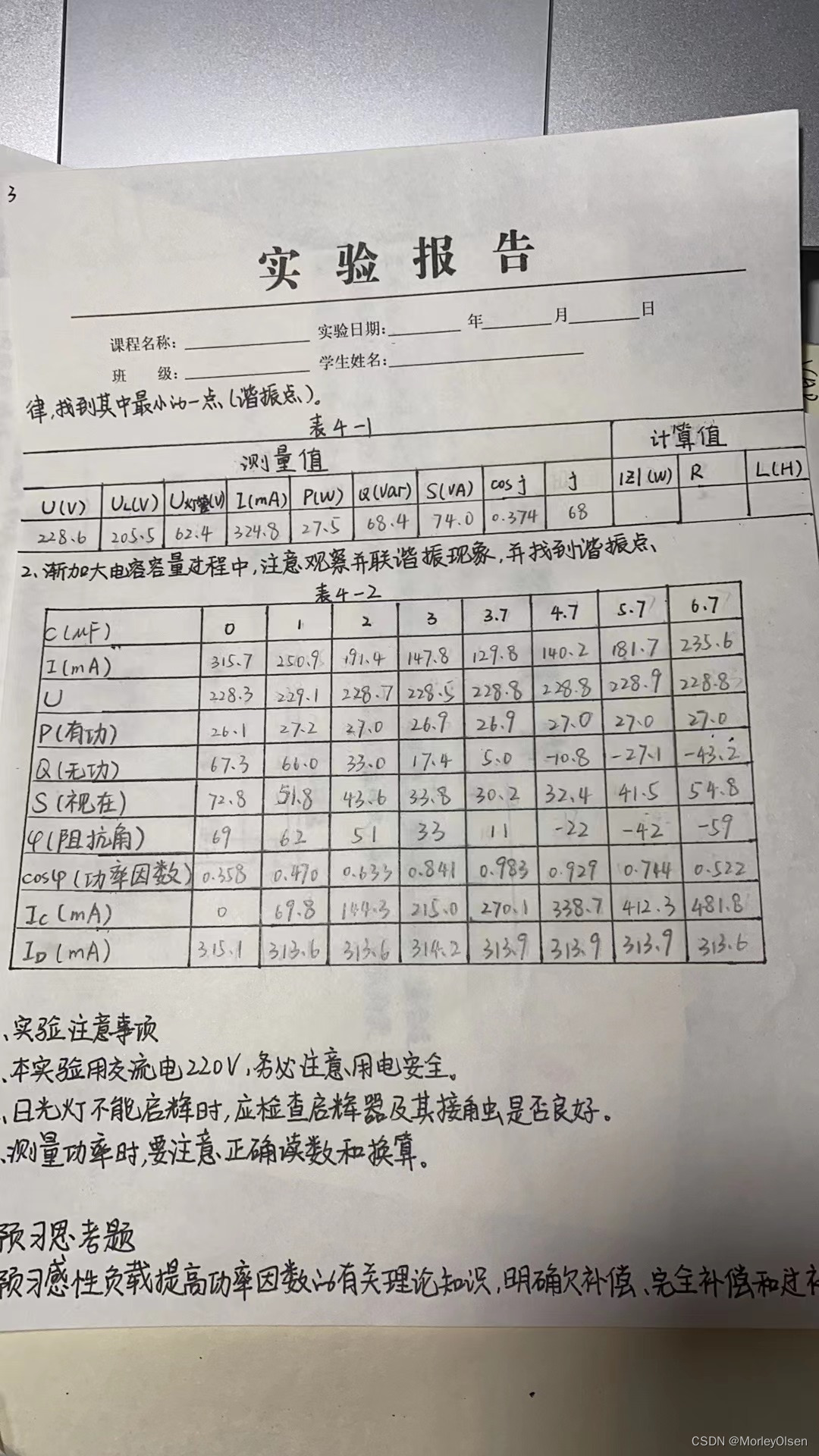
抓取规划问题是指确定物体与手指间的一系列接触位置,使得手指能抵抗任意外力且灵活操作物体的能力。传统的基于分析的抓取规划需要根据已知的被抓物体模型根据力闭合的条件判断抓取的好,这种方法只适合对已知的物体进行抓取。
然而日常生活中有很多相似物体(如圆柱,长方体),没有必要为每一个物体都建立精确的模型,因此可以用相似性匹配的方法解决这类物体的抓取。随着人工智能的发展,人工神经网络可以从大量的已知物体的抓取中提取出有用的抓取基元,从而实现对未知物体的抓取。这样做的好处是不必为每个被抓物体建立几何模型,让机器人智能抓取操作物体。2013 年以前的工作可以参考 [1],下面就近几年的基于数据的机器人抓取概览如下。
1. 基于 RGB 图片的抓取
美国加州大学伯克利分校提出了利用大量的物体三维模型和分析的方法生成抓取数据集,并利用深度图和卷积神经网络(GQ-CNN)对抓取进行分类 [2]。他们首先把抓取简化为一个从上至下的夹取(top-down grasp),根据输入的点云生成上百个成对的抓取候选,再利用 CNN 对候选抓取进行快速评分,从而得到最好的抓取。与之前的基于数据的抓取不同的是,他们没有使用费时费力的人工标定抓取的方式或机器人随机抓取来采集数据集,而是利用力闭合的原理通过分析的方式计算出抓取的好坏(是否力闭合)。这样的好处是可以低成本的生成大量的数据集。
2. 基于点云的抓取
美国西北大学进一步使用点云在不同方向的投影作为人工神经网络的输入对抓取进行评分并把抓取数据集扩展到 6D 位姿抓取 [3]。利用点云的好处是可以让网络得到更丰富的信息。不同于 Dex-Net,这个工作使用的是 6D 抓取位姿作为抓取的表示。在生成抓取候选上,该文使用了一些设计好的策略。这个策略基于物体的曲面形状。首先随机在物体表面采样一点,以这个点所在的曲面法向作为抓取候选的朝向(下图 b 红色箭头表示),“主成分” 方向作为两个夹爪连线的方向(下图 b 中蓝色箭头表示)。并通过基于该抓取的旋转和平移扩充抓取候选的个数。通过这种采样方式,可以增加抓取候选中好抓取的比例(无后续人工神经网络分类的情况下可达 53% 抓取成功率)。得到抓取候选后,经过对抓取点云的投影得到网络的输入如下图(c-e)所示。经过 CNN 对抓取候选的分类后,最高可达 93% 抓取成功率(动态点云)。
进一步,德国汉堡大学张建伟教授团队和清华大学孙富春教授团队共同提出了对上述工作的改进 [4]。对于数据集的生成,通过在给抓取打分时不断调整夹爪和物体之间的摩擦系数得到一个更细化的抓取分数(摩擦系数越小,抓取分数越高)。这样的数据集可以得到一个带分数的抓取,从而可以让网络学得更细分的抓取分类。对于网络结构上,他们使用了 PointNet,这样的好处是可以直接使用点云作为输入,不需要对点云进行投影。更大的保留了点云的几何信息。
不同于首先生成抓取候选,再对抓取分类、评分的思路,英伟达公司的机器人研究团队提出了直接根据输入的物体点云生成抓取 [5]。在数据集生成上,他们使用了纯物理引擎仿真抓取的方式。这种方法的好处是可以生成用特定规则生成抓取[3.4] 得不到的抓取。这是因为通常分析的方法生成抓取数据集把抓取简化成了两个点。而在实际抓取中,机器人通常具有两个平行的手指作为夹爪。另一个原因是抓圆环物体如带柄的马克杯时,力闭合原理无法生成 “Caging” 的抓取。因此用物理引擎可以完全模拟真实中的抓取情形,生成更多样化的抓取。在网络上,他们把被抓物体点云和夹爪点云一起作为输入,使用 PointNet++ 网络和自编码机的结构生成好的抓取,并利用一个网络优化生成的抓取。
3. 基于多模态的抓取
基于多模态的抓取通常是指通过不同的指尖力传感器在正式抓取前通过 “预抓取” 判断抓取的稳定性,从而决定是继续抓取还是调整一个新的抓取姿态。清华大学孙富春教授团队提出使用视觉来生成抓取,并用指尖的触觉判断抓取的稳定性 [6]。为此,他们采集了一个视觉、触觉抓取数据集,并分别用两个网络对抓取进行生成和稳定性判断。该团队又与 Intel 中国研究院合作,建立了一个视觉、触觉、力等多模态的机器人抓取数据集,通过视触融合实现抓取稳定判断[7]。清华大学孙富春教授团队也是利用多模态信息实现的机器人智能抓取,而赢得了“IROS2019 机器人灵巧抓取操作比赛” 物流分拣项目的冠军。

加州大学伯克利分校提出了利用一个基于视觉的触觉传感器—GelSight 来进行多模态抓取任务 [8]。得益于他们使用的基于视觉的触觉传感器,可以天然的使用广泛应用的视觉处理神经网络(CNN),通过与抓取,机器人判断抓取的好坏并生成下一步的动作。这样这个机器人系统可以自主的根据触觉反馈调整抓取策略而不需要人工干预。
4. 多指抓取
二指抓取的好处是对抓取的表达比较简单,但是抓取通常并不是机器人操作的最终目的,人们往往希望通过手内改变被抓物体的姿态和位置完成一些操作任务。如使用工具。 美国马里兰大学的研究者提出了一个端到端的多指抓取生成网络 [9]。 这个网络使用点云作为输入,使用 3DCNN 网络直接生成 Shadow 多指手的抓取规划。
美国麻省理工学院的学者针对多指抓取生成过程中网络不能适应不同的多指手的问题提出了解决方案 [10]。他们提了一个统一的多指抓取模型以适应不同的机械手。首先,他们把爪子和被抓物体的特征映射到一个低维空间。然后用一个点云选择网络去生成接触点,通过接触点继而生成一个无障碍的抓取。
5. 基于任务的抓取
上面的工作都是与任务无关的无序抓取,但是在机器人操作上抓取通常是有目的的。如转移物体,递给其他机器人 / 人,使用抓取的物体。在这一领域最新的工作是西安交通大学的机器人课题组 [11]。他们在一个有重叠的场景下完成了基于任务的抓取。首先,他们建立了一个合成的堆叠物体的数据集,并使用条件随机场(CRF)建立了物体的语义模型。这个模型可以的推导过程用 RNN 来表示,这样整个基于任务的模型可以端到端进行训练。
6. 基于功能可用性的抓取
在人机交互中,还有一种机器人抓取操作,是基于功能可用性的。想象一下这样一个场景:人给机器人一个模糊的指令,机器人理解这个指令并做出一定的动作。汉堡大学张建伟团队考虑了如下两个情况 [12]:
1)人说:嗨,机器人,我想学习。这时,机器人理解到人想让机器人递给他一个可以玩的物体,通过功能可用性网络,结合输入图片,机器人递给人一本书。
2)人说:嗨,机器人,给我左边的苹果。这时桌上有两个苹果,机器人理解语义并递给人左边的苹果。
机器人的智能抓取已经成为研究热点,也逐渐在物流快件、工件、食品等分拣行业中凸显了重要性。未来如何实现机器人认知的智能抓取操作将会成为重点研究问题。
参考文献
[1] Bohg J, Morales A, Asfour T, et al. Data-driven grasp synthesis—a survey. IEEE Transactionson Robotics, 2013, 30(2): 289-309.
[2] Mahler, J., Liang, J., Niyaz, S., Laskey, M., Doan, R., Liu, X., … Goldberg, K. (2017). Dex-Net 2.0: DeepLearning to Plan Robust Grasps with Synthetic Point Clouds and Analytic GraspMetrics. Robotics: Science and Systems (RSS), 37(3), 301–316.
[3] ten Pas, A., Gualtieri, M., Saenko, K.,& Platt, R. (2017). Grasp Pose Detection in Point Clouds. The InternationalJournal of Robotics Research, 36(13–14), 1455–1473.
[4] Liang, H., Ma, X., Li, S., Grner, M., Tang, S., Fang, Bin Fang, … Zhang, J. (2019). PointNetGPD: Detecting GraspConfigurations from Point Sets. In International Conference on Robotics andAutomation (ICRA) (pp. 3629–3635).
[5] Mousavian, A., Eppner, C., & Fox, D. (2019). 6-DOF GraspNet: Variational Grasp Generation for ObjectManipulation. ICCV 2019
[6] Guo, D., Sun, F., Fang, B., Yang, C., & Xi, N. (2017). Roboticgrasping using visual and tactile sensing. Information Sciences, 417, 274–286.
[7] Tao Wang, Chao Yang, Frank Kirchner, Peng Du, Fuchun Sun, Bin Fang*, Multimodal grasp data set: a novelvisual-tactile data set for robotic manipulation. International Journal ofAdvanced Robotic Systems, 2019, 16(1):1-10.
[8] Calandra, R., Owens, A., Jayaraman, D., Lin, J., Yuan, W., Malik, J., … Levine, S. (2018). More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch. In IROS2018.
[9] Liu, M., Pan, Z., Xu, K., Ganguly, K.,& Manocha, D. (2019). Generating Grasp Poses for a High-DOF Gripper UsingNeural Networks. IROS 2019.
[10] L. Shao et al., “UniGrasp:Learning a Unified Model to Grasp With Multifingered Robotic Hands,” inIEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 2286-2293, April 2020.
[11] C. Yang, X. Lan, H. Zhang, N. Zheng, “Task-oriented Grasping in Object Stacking Scenes with CRF-based SemanticModel,” 2019 IEEE/RSJ International Conference on Intelligent Robots andSystems (IROS), Macau, China, 2019, pp. 6427-6434.
[12] Jinpeng Mi, Song Tang, et al. Object Affordance based MultimodalFusion for Natural Human-Robot Interaction. Cognitive Systems Research,54:128–137, 2019.
来自:梁洪濯,方斌 CAAI 认知系统与信息处理专委会 ,激光天地转载
1、Vision-based Robotic Grasping From Object Localization, Object Pose Estimation to Grasp Estimation for Parallel Grippers: A Review(2019)
本文对基于视觉的机器人抓取技术进行了综述。总结了基于视觉的机器人抓取过程中的三个关键任务:目标定位、目标姿态估计和抓取估计。其中,目标定位任务包括不分类的目标定位、目标检测和目标实例分割。此任务在输入数据中提供目标对象的区域。目标位姿估计任务主要是对6D目标位姿的估计,包括基于通信的方法、基于模板的方法和基于投票的方法,为已知目标提供抓取位姿的生成。抓取估计任务包括二维平面抓取方法和6DoF抓取方法,其中二维平面抓取方法约束从一个方向抓取。这三个任务可以通过不同的组合完成机器人抓取。许多目标位姿估计方法都不需要目标定位,而是将目标定位和目标位姿估计联合起来进行。许多抓取估计方法都不需要物体定位和物体姿态估计,并且采用端到端的方式进行抓取估计。本文详细回顾了传统的基于RGB-D图像输入的深度学习方法和最新的基于RGB-D图像输入的深度学习方法。并对相关数据集和最新方法的比较进行了总结。此外,还指出了基于视觉的机器人抓取面临的挑战和未来的发展方向。
2、Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects(2018)
使用合成数据训练用于机器人操作的深度神经网络,有望获得几乎无限数量的预先标记训练数据,这些数据可以安全地在安全的地方生成。迄今为止,合成数据的关键挑战之一是弥合所谓的现实差距,以便在面对现实数据时,基于合成数据训练的网络能够正确运行。我们探索现实差距的背景下,已知对象的6自由度姿态估计从一个单一的RGB图像。我们表明,对于这个问题,现实差距可以成功跨越一个简单的领域随机和逼真的数据组合。使用以这种方式生成的合成数据,我们引入了一个一次性深度神经网络,它能够与基于真实数据和合成数据组合训练的最先进的网络进行竞争。据我们所知,这是第一个仅在合成数据上训练的深度网络,能够在6自由度物体姿态估计上实现最先进的性能。我们的网络还可以更好地推广到包括极端光照条件在内的新颖环境,我们对这些环境给出了定性结果。利用该网络,我们演示了一个实时系统,该系统对物体的姿态进行了足够准确的估计,以实现真实机器人对已知杂乱物体的语义抓取。
3、 Grasp Pose Detection in Point Clouds(2017)——GPD
代码:GitHub - atenpas/gpd: Detect 6-DOF grasp poses in point clouds
近年来,许多抓取检测方法被提出,可用于直接从传感器数据定位机器人抓取构型,而无需估计目标姿态。其基本思想是将抓取感知类比于计算机视觉中的目标检测。这些方法以噪声和部分遮挡的RGBD图像或点云作为输入,并产生作为输出的可行抓手的姿态估计,而不假设对象的已知CAD模型。虽然这些方法能够很好地将掌握的知识推广到新对象,但它们还没有被证明足够可靠,可以广泛应用。许多抓取检测方法的抓取成功率(抓取成功率为抓取尝试总数的一部分)在75%到95%之间,对于孤立地或轻杂波中呈现的新对象。这些成功率不仅对于实际的抓取应用来说太低,而且评估的轻杂波场景往往不能反映真实世界的抓取情况。本文提出了一些创新,共同导致了抓取检测性能的显著提高。我们的每一项贡献所带来的具体性能改进都可以在仿真或机器人硬件上进行定量测量。最终,我们报告了一系列机器人实验,平均93%的端到端抓取成功率在密集的杂波中呈现的新物体。
4、High precision grasp pose detection in dense clutter(2016)——GPG
本文研究点云中的抓取位姿检测问题。我们遵循一个通用的算法结构,首先生成一个大的6自由度抓取候选集合,然后将它们分别归类为好的抓取或坏的抓取。我们在本文中的重点是通过使用来自大型在线数据集的深度传感器扫描来训练卷积神经网络来改进第二步。我们提出了两种新的抓取候选对象表示,并量化了使用两种形式的先验知识(被抓取对象的实例或类别知识)的效果,并根据理想化CAD模型获得的模拟深度数据对网络进行预训练。我们的分析表明,信息量更大的抓取候选表示以及预训练和先验知识显著提高了抓取检测。我们在Baxter研究机器人上评估了我们的方法,并证明在密集的杂波中平均抓取成功率为93%。这比我们之前的工作提高了20%。
5、Grasp2Vec: Learning Object Representations from Self-Supervised Grasping (2018)
代码:tensor2robot/research/grasp2vec at master · google-research/tensor2robot · GitHub
结构良好的视觉表示可以使机器人学习速度更快,提高泛化能力。在本文中,我们研究了如何利用机器人与环境的自主交互,在没有人类标记的情况下,获得有效的以对象为中心的机器人操作任务表示。随着机器人积累了更多的经验,这种表征学习方法可以受益于表征的不断细化,使它们能够在没有人类干预的情况下有效地缩放。我们的表征学习方法基于对象持久性:当机器人从场景中移除一个对象时,该场景的表征应该根据被移除对象的特征而改变。我们制定一个从这个观察计算特征向量之间的关系,并使用它来学习的表示场景和对象,然后可以用来识别对象实例,本地化的现场,执行目标导向把握任务的机器人必须从本检索命令对象。同样的抓取过程也可以用来为我们的方法自动收集训练数据,通过记录场景的图像,抓取和移除一个物体,并记录结果。我们的实验表明,这种任务抓取的自我监督方法大大优于直接强化图像学习和先前的表示学习方法。
6、Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning(2018)
代码:GitHub - andyzeng/visual-pushing-grasping: Train robotic agents to learn to plan pushing and grasping actions for manipulation with deep reinforcement learning.
https://github.com/jhu-lcsr/good_robot
熟练的机器人操作得益于非抓握(如推)和抓握(如抓)动作之间的复杂协同作用:推可以帮助重新排列杂乱的物体,为手臂和手指腾出空间;同样,抓取可以帮助移动物体,使推动运动更精确和无碰撞。在这项工作中,我们证明了通过无模型深度强化学习从头发现和学习这些协同作用是可能的。我们的方法包括训练两个完全卷积的网络,从视觉观察映射到动作:一个推断出推动的作用,以密集像素级的方式对末端执行器的方向和位置进行采样,而另一个则对抓取进行相同的操作。这两个网络在一个Q-learning框架中联合训练,并完全通过试错进行自我监督,成功的掌握将提供奖励。通过这种方式,我们的政策学会了推动行动,使未来的掌握成为可能,同时也学会了利用过去的推动。在模拟和现实场景下的拾取实验中,我们发现我们的系统在杂乱的挑战情况下快速学习复杂行为,在短短几个小时的训练后,比基线方案获得了更好的拾取成功率和拾取效率。我们进一步证明了我们的方法能够推广到新的对象。定性结果(视频)、代码、预先训练的模型和模拟环境可以在http://vpg.cs.princeton.edu上找到
7、Deep Grasp: Detection and Localization of Grasps with Deep Neural Networks(2018)
代码:GitHub - ivalab/grasp_multiObject_multiGrasp: An implementation of our RA-L work 'Real-world Multi-object, Multi-grasp Detection'
GitHub - ivalab/grasp_multiObject: Robotic grasp dataset for multi-object multi-grasp evaluation with RGB-D data. This dataset is annotated using the same protocal as Cornell Dataset, and can be used as multi-object extension of Cornell Dataset.
提出了一种深度学习结构,用于预测机器人操作的可抓取位置。它考虑没有对象、一个或多个对象的情况。通过将学习问题定义为具有零假设竞争的分类而不是回归,具有RGB-D图像输入的深度神经网络在一次镜头中预测出单个或多个目标的多个抓取候选对象。该方法在康奈尔数据集上的图像分割和对象分割精度分别达到96.0%和96.1%,优于最先进的方法。在多对象数据集上的评估说明了该体系结构的泛化能力。对一组家用物品进行抓取实验,获得96.0%的抓取定位和88.0%的抓取成功率。从图像到计划的实时过程需要不到0.25秒
8、Object SLAM-Based Active Mapping and Robotic Grasping(2020)
代码:https://github.com/yanmin-wu/EAO-SLAMicon-default.png?t=M3K6https://github.com/yanmin-wu/EAO-SLAM
本文提出了第一个用于复杂机器人操作和自主感知任务的主动目标映射框架。该框架建立在目标SLAM系统的基础上,集成了同时进行的多目标位姿估计过程,以优化机器人抓取。为了减少对目标物体的观测不确定性,提高目标物体的位姿估计精度,我们还设计了一种对象驱动的探索策略来指导目标映射过程,实现自主映射和高层次感知。将测绘模块与探测策略相结合,可生成与机器人抓取相兼容的精确目标地图。定量评价也表明,该框架具有很高的映射精度。实验操作(包括物体抓取和放置)和增强现实显著地证明了我们提出的框架的有效性和优势。
9、Workspace Aware Online Grasp Planning(2018)
代码:https://github.com/scikit-fmm/scikit-fmmicon-default.png?t=M3K6https://github.com/scikit-fmm/scikit-fmm
本工作提供了一个工作空间感知的在线掌握计划器的框架。该框架通过在在线抓取规划过程中引入可达性的概念,大大提高了标准在线抓取规划算法的性能。脱机时,研究人员对一个包含数十万个不同末端执行器姿态的数据库进行了可行性查询。在运行时,我们的抓握规划器使用这个数据库使手偏向可到达的末端执行器配置。偏差使抓取规划器保持在规划场景的可访问区域,从而产生的抓取器可以根据手头的情况进行定制。这导致可达到的抓取百分比更高,成功执行抓取的百分比更高,并减少了计划时间。我们还提供了模拟和真实环境下的实验结果。
10、Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach(2018)
本文提出了一种实时的、与物体无关的、可用于闭环抓取的抓取综合方法。我们提出的生成抓取卷积神经网络(GG-CNN)在每个像素预测抓取的质量和姿态。这种来自深度图像的一对一映射克服了当前深度学习抓取技术的局限性,避免了抓取候选对象的离散采样和较长的计算时间。此外,我们的GGCNN在检测稳定抓手时比目前最先进的技术小了几个数量级。我们的GG-CNN轻量级和单次生成特性允许高达50Hz的闭环控制,在物体移动和机器人控制不准确的非静态环境中实现准确抓取。在现实世界的测试中,我们对一组以前不可见的具有对敌几何形状的物体的抓取成功率为83%,对一组在抓取过程中移动的家用物体的抓取成功率为88%。在动态杂波中抓取,准确率达81%。
11、ContactPose: A Dataset of Grasps with Object Contact and Hand Pose(2020)
抓取是人类的天性。然而,它涉及复杂的手部构型和软组织变形,这可能导致手部和物体之间复杂的接触区域。理解和建模这种接触可以潜在地改善手部模型、AR/VR体验和机器人抓取。然而,我们目前缺乏与其他数据模式配对的手-物接触数据集,这是开发和评估接触建模技术的关键。我们引入ContactPose,第一个手-物接触数据集,搭配手-物-姿和RGB-D图像。ContactPose拥有2306个独特的抓取器,50个参与者以2种功能意图抓取25个家用物品,以及超过2.9 M RGB-D抓取图像。对ContactPose数据的分析揭示了手部姿势和接触之间有趣的关系。我们使用这些数据严格评估各种数据表示、文献中的启发式和接触建模的学习方法。数据、代码和训练过的模型可以在https://contactpose.cc.gatech.edu上找到。
12、PointNetGPD: Detecting Grasp Configurations from Point Sets(2018)
在本文中,我们提出了一个端到端抓取评估模型,以解决直接从点云定位机器人抓取构型的挑战性问题。与最近基于手工深度特征和卷积神经网络(CNN)的抓取评估指标相比,我们提出的PointNetGPD是轻量级的,可以直接处理位于抓取器内的3D点云进行抓取评估。以原始点云为输入,即使点云非常稀疏,我们所提出的抓取评价网络也能捕捉到抓取器与物体接触区域的复杂几何结构。为了进一步改进我们提出的模型,我们生成了一个包含350k真实点云的更大尺度的抓取数据集,并使用YCB对象集进行抓取训练。在仿真和机器人硬件上对所提出模型的性能进行了定量测量。对目标抓取和杂波去除的实验表明,我们提出的模型对新目标具有良好的泛化能力,并优于现有的方法。
13、Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching(2017)
本文介绍了一种机器人拾取和放置系统,能够抓取和识别已知和新的对象在混乱的环境。该系统的关键新特性是,它可以处理广泛的对象类别,而不需要任何针对新对象的特定任务训练数据。为了实现这一目标,首先使用一种类别无关的可视性预测算法在四种不同的抓取原始行为中进行选择和执行。然后,它通过一个跨域图像分类框架识别选中的对象,该框架将观察到的图像与产品图像进行匹配。由于产品图像可用于广泛的对象(例如,从网络),该系统工作开箱即用的新对象,不需要任何额外的训练数据。详尽的实验结果表明,我们的多可视性抓取对杂波中各种各样的目标都有较高的成功率,我们的识别算法对已知和新抓取的目标都有较高的准确率。这种方法是麻省理工学院-普林斯顿团队系统的一部分,该系统在2017年亚马逊机器人挑战赛中获得了装载任务第一名。所有的代码、数据集和预先训练的模型都可以在http://arc.cs.princeton.edu上找到
14、Grasping Field: Learning Implicit Representations for Human Grasps(2020)
代码:GitHub - korrawe/grasping_fieldicon-default.png?t=M3K6https://github.com/korrawe/grasping_field_demo
近年来,家用机器人抓取技术取得了显著进展。然而,人类的抓地力仍然难以真实地合成。有几个关键原因:(1)人手自由度多(比机器人多);(2)合成的手应符合物体表面;(3)它应该以一种语义上和物理上可信的方式与物体互动。为了在这个方向上取得进展,我们从基于学习的三维对象重建隐式表示的最新进展中汲取灵感。具体来说,我们提出了一种高效且易于与深度神经网络集成的人类把握建模表达方法。我们的见解是,三维空间中的每一点都可以分别用到手表面和物体表面的符号距离来表征。因此,手、物体和接触区域可以用一个公共空间中的隐式曲面来表示,在这个空间中,手和物体之间的接近程度可以显式建模。我们将这种3D到2D的映射称为抓取场,用深度神经网络参数化它,并从数据中学习它。我们证明,提出的抓取领域是一个有效的和表达的人类抓取生成表示。具体来说,我们的生成模型能够合成高质量的人类抓取,只在3D对象点云上给出。大量的实验表明,我们的生成模型与一个强大的基线相比有优势,接近人类自然掌握的水平。我们的方法提高了手-物接触重建的物理可信性,并实现了与最先进的方法相比的三维手重建性能。
15、 GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping(2020)
物体抓取是许多应用的关键,也是一个具有挑战性的计算机视觉问题。然而,对于复杂场景,目前的研究存在训练数据不足和缺乏评价基准的问题。在这项工作中,我们贡献了一个具有统一评价系统的大规模的抓取姿态检测数据集。我们的数据集包含97280张RGB-D图像,有超过10亿个抓取姿势。同时,我们的评价系统通过分析计算直接报告抓取是否成功,可以在不完全标注地面真理的情况下评价任何类型的抓取姿态。此外,我们提出了一个端到端的抓取姿态预测网络,给出了点云输入,在那里我们以一种解耦的方式学习接近方向和操作参数。为了提高抓取的鲁棒性,设计了一种新的抓取亲和域。我们进行了大量的实验,以表明我们的数据集和评估系统可以很好地与现实世界的实验保持一致,我们提出的网络实现了最先进的性能。我们的数据集、源代码和模型可以在www.graspnet.net上公开。
17、Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network(2019)
代码:GitHub - skumra/robotic-grasping: Antipodal Robotic Grasping using GR-ConvNet. IROS 2020.icon-default.png?t=M3K6https://github.com/skumra/robotic-grasping
在本文中,我们提出了一个模块化机器人系统,以解决从场景的nchannel图像生成和执行未知物体的反足机器人抓取的问题。我们提出了一种新的生成式残差卷积神经网络(GR-ConvNet)模型,该模型可以在实时速度(~20ms)下从n通道输入产生鲁棒的对跖抓握。我们在标准数据集和不同的家庭对象集上评估所提出的模型架构。在Cornell和Jacquard抓取数据集上,我们分别取得了97.7%和94.6%的精确度。我们还证明了使用7自由度机械臂对家庭和对敌物体的抓取成功率分别为95.4%和93%。
18、Volumetric Grasping Network: Real-time 6 DOF Grasp Detection in Clutter(2021)
代码:GitHub - ethz-asl/vgn: Real-time 6 DOF grasp detection in clutter.icon-default.png?t=M3K6https://github.com/ethz-asl/vgn
一般的机器人在混乱中抓取需要合成抓取的能力,这种抓取对以前看不见的物体有效,并且对物理交互也很健壮,比如与场景中的其他物体的碰撞。在这项工作中,我们设计并训练了一个网络,该网络根据从车载传感器(如腕部深度相机)收集的3D场景信息预测6自由度抓取。我们提出的体积抓取网络(VGN)接受场景的截断符号距离函数(TSDF)表示,并直接输出预测的抓取质量,以及查询的3D体素中每个体素的相关抓取方向和开口宽度。我们表明,我们的方法可以在10毫秒内计划抓取,并能够清除92%的对象在真实世界的杂波去除实验中,而不需要明确的碰撞检查。这种实时能力为闭环抓取规划提供了可能性,允许机器人处理干扰、从错误中恢复并提供更高的鲁棒性。代码可以在https://github.com/ethz-asl/vgn上找到。
19、 6-DOF Grasping for Target-driven Object Manipulation in Clutter(2019)
在混乱的环境中抓取是一项基本但具有挑战性的机器人技能。它既需要对看不见的物体部分进行推理,也需要对与机械手的潜在碰撞进行推理。大多数现有的数据驱动方法通过将自己限制在自上而下的平面抓取中而避免了这个问题,这在许多现实场景中是不够的,并且极大地限制了可能的抓取。我们提出了一种方法,计划从部分点云观测在凌乱的场景中为任何想要的对象进行6自由度抓取。我们的方法获得了80.3%的抓取成功率,比基准方法高出17.6%,并在一个真实的机器人平台上清理了9个凌乱的桌面场景(其中包含23个未知对象和51个拾取)。通过使用我们学习过的碰撞检查模块,我们甚至可以推断出有效的抓取序列来检索不能立即访问的对象。补充视频可以在https://youtu.be/wOB5S-gCsJk找到。
20、Multi-View Picking: Next-best-view Reaching for Improved Grasping in Clutter(2019)
摄像机视点选择是视觉抓取检测的一个重要方面,特别是在有许多遮挡的杂波环境中。其他方法使用静态摄像机位置或固定数据收集例程,而我们的多视图拾取(MVP)控制器使用一种主动感知方法,直接基于实时的抓取姿态估计分布来选择信息丰富的视角,减少了由杂波和遮挡造成的抓取姿态中的不确定性。在从杂乱中抓取20个物体的试验中,我们的MVP控制器实现了80%的抓取成功率,比单视角抓取检测器的性能高出12%。我们还表明,我们的方法比考虑多个固定视点的方法更准确和更有效。
21、Robot Learning of Shifting Objects for Grasping in Cluttered Environments(2019)
在杂乱的环境中,机器人的抓取通常是不可行的,因为障碍物阻碍了可能的抓取。然后,像移动或推动物体这样的预抓取操作就变得必要了。我们开发了一种算法,它可以学习,除了抓取,以这样一种方式移动物体,以增加它们的抓取概率。我们的研究贡献有三个方面:首先,我们提出了一个算法来学习操作基元的最佳姿态,如夹紧或移动。第二,我们学习无法理解的动作,这明显增加了抓取的概率。让一种技能(移动)直接依赖于另一种技能(抓取),从而消除了对稀疏奖励的需求,从而导致更有效的数据学习。第三,我们将一个真实世界的解决方案应用于捡垃圾的工业任务,从而实现完全清空垃圾箱的能力。该系统以自我监督的方式进行培训,大约有25000个抓手和2500个换挡动作。我们的机器人每小时能抓取和归档274次。此外,我们证明了系统的能力,推广到新的对象。
22、 GanHand: Predicting Human Grasp Affordances in Multi-Object Scenes(2020)
代码:https://github.com/enriccorona/ganhandicon-default.png?t=M3K6https://github.com/enriccorona/ganhand
深度学习的兴起带来了从图像中估计手的几何形状的显著进展,而手是场景的一部分。本文关注的是一个迄今尚未探索的新问题,即在给定一个或多个物体的RGB图像的情况下,预测人类如何抓取这些物体。这是一个在增强现实、机器人或假肢设计等领域具有巨大潜力的问题。为了预测可行的抓取,我们需要理解图像的语义内容、几何结构以及与手部物理模型的所有潜在交互。为此,我们引入了一个生成模型,在所有这些层面上进行推理,1)回归场景中物体的3D形状和姿态;2)判断抓握类型;3)改进了51自由度的3D手模型,最大限度地减少了可抓取性损失。为了训练这个模型,我们构建了ycb -可视性数据集,其中包含了YCB-Video数据集中21个对象的超过133k幅图像。根据33类分类,我们已经用超过28M个可信的3D人类抓手对这些图像进行了注释。对合成和真实图像的全面评估表明,我们的模型可以稳健地预测真实的抓取,即使在有多个物体密切接触的混乱场景中也是如此。
23、PointNet++ Grasping: Learning An End-to-end Spatial Grasp Generation Algorithm from Sparse Point Clouds(2020)
抓取新物体对于非结构环境下的机器人操作具有重要意义。目前的研究大多需要一个抓取采样过程,结合深度学习的局部特征提取器来获取抓取候选对象。这个管道是耗时的,特别是当抓取点很稀疏的时候,比如在碗的边缘。在本文中,我们提出了一种端到端的方法来直接预测所有握拍的姿势、类别和得分(质量)。它以整个稀疏点云作为输入,不需要采样和搜索过程。此外,为了生成多目标场景的训练数据,我们提出了一种基于Ferrari Canny度量的快速多目标抓取检测算法。生成一个单对象数据集(来自YCB对象集的79个对象,23.7k抓取)和一个多对象数据集(20k带注释和掩码的点云)。提出了一种基于pointnet++结合多掩码丢失的网络来处理不同的训练点。我们的网络的整个权重大小只有11.6M,使用GeForce 840M GPU的整个预测过程大约需要102ms。实验结果表明,我们的工作取得了71.43%的成功率和91.60%的完成率,优于现有的技术水平。
24、Grasp Proposal Networks: An End-to-End Solution for Visual Learning of Robotic Grasps(2020)
从视觉观察中学习机器人抓握是一项很有前途但具有挑战性的任务。最近的研究表明,通过准备和学习大规模合成数据集,它具有巨大的潜力。针对目前比较流行的6自由度并联颌夹持器抓位设置问题,现有方法大多采用启发式抽样抓取候选抓位,然后利用学习到的评分函数对候选抓位进行评估的策略。该策略的局限性在于采样效率与最优抓手覆盖率之间的冲突。为此,我们在这项工作中提出了一个新颖的端到端lemph[抓握建议网络(GPNet)),以预测从单一和未知摄像机视角观察到的不可见物体的不同的6自由度抓握集合。GPNet基于抓取建议模块的关键设计,该模块在离散但规则的3D网格角上定义了lemph(抓取中心的锚点),可以灵活地支持更精确或更多样化的抓取预测。为了测试GPNet,我们提供了一个六自由度物体抓取的合成数据集;评估采用基于规则的标准、模拟测试和真实测试进行。比较结果表明,我们的方法比现有的方法有优势。值得注意的是,GPNet通过指定的覆盖范围获得了更好的模拟结果,这有助于在实际测试中实现现成的转换。我们将公开我们的数据集。
25、Category-agnostic Segmentation for Robotic Grasping(2022)
在这项工作中,我们介绍了DoPose,一个高度杂乱和紧密堆叠的对象数据集,用于分割和6D姿态估计。我们展示了如何使用精心选择的合成数据和微调我们的真实数据集,以及一个合理的训练,可以提高现有CNN架构的性能,对真实数据进行归纳,并产生与SOTA方法可比的结果,即使没有后处理或细化。我们的DoPose数据集,网络模型,管道代码和ROS驱动程序都可以在线获得。
26、A Visually Plausible Grasping System for Object Manipulation and Interaction in Virtual Reality Environments(2019)
代码:https://github.com/3dperceptionlab/unrealgraspicon-default.png?t=M3K6https://github.com/3dperceptionlab/unrealgrasp
26、在虚拟现实(VR)环境中进行交互是实现愉快的沉浸式体验的必要条件。目前大多数现有的VR应用,缺乏鲁棒的物体抓取和操作,这是交互系统的基石。因此,我们提出了一个现实的、灵活的和鲁棒的抓取系统,可以在虚拟环境中丰富和实时的交互。它在视觉上是逼真的,因为它是完全由用户控制的,它是灵活的,因为它可以用于不同的手部配置,它是健壮的,因为它允许操作对象,无论其几何形状,即手自动适应对象的形状。为了验证我们的建议,我们进行了详尽的定性和定量的性能分析。一方面,对手部运动真实感、交互真实感、运动控制等抽象方面进行定性评价;另一方面,在定量评价方面,提出了一种新的误差度量方法来直观地分析所执行的握把。这个度量是基于从手指指骨到物体表面上最近接触点的距离的计算。这些接触点可以用于不同的应用目的,主要是在机器人领域。综上所述,系统评估报告显示,有虚拟现实应用经验的用户和没有经验的用户的性能相似,学习曲线很陡。
27、ACRONYM: A Large-Scale Grasp Dataset Based on Simulation(2020)
代码:GitHub - NVlabs/acronym: This repository contains a sample of the grasping dataset and tools to visualize grasps, generate random scenes, and render observations. The two sample files are in the HDF5 format.icon-default.png?t=M3K6https://github.com/NVlabs/acronym
本文介绍了一个基于物理仿真的机器人抓取规划数据集ACRONYM。该数据集包含17.7M的平行颚抓手,涵盖262个不同类别的8872个物体,每个物体都使用物理模拟器获得的抓手结果进行标记。我们展示了这个大型和多样化的数据集的价值,使用它来训练两个最先进的基于学习的掌握规划算法。与原始较小的数据集相比,抓取性能显著提高。数据和工具可以访问https://sites.google.com/nvidia.com/graspdataset。
28、A Deep Learning Approach to Grasping the Invisible(2019)
代码:https://github.com/choicelab/grasping-invisibleicon-default.png?t=M3K6https://github.com/choicelab/grasping-invisible
我们研究了机器人操作中出现的“抓取无形物体”问题,机器人通过一系列的推和抓取动作来抓取最初不可见的目标物体。在这个问题中,需要push来搜索目标,并重新排列目标周围杂乱的物体,以实现有效的抓取。我们建议通过制定一个批判政策格式的深度学习方法来解决这个问题。通过深度q -学习,学习目标导向的运动评价,将视觉观察和目标信息映射到推和抓取运动原语的预期未来奖励。我们将问题划分为两个子任务,并通过结合评论家预测和相关领域知识,提出两种策略来解决每个子任务。基于贝叶斯的政策会计对过去的行动经验进行推动搜索目标;一旦目标被发现,基于分类器的策略结合面向目标的推抓,在杂乱中对目标进行抓取。运动评价器和分类器通过机器人与环境的相互作用以自我监督的方式进行训练。我们的系统在仿真中对两个子任务的任务成功率分别达到了93%和87%,在真实机器人实验中对整个问题的任务成功率达到了85%,大大超过了几个基线。补充材料可在https://sites.google.com/umn.edu/grasping-invisible上找到。
29、Contact-GraspNet: Efficient 6-DoF Grasp Generation in Cluttered Scenes(2021)
代码:GitHub - NVlabs/contact_graspnet: Efficient 6-DoF Grasp Generation in Cluttered Scenesicon-default.png?t=M3K6https://github.com/NVlabs/contact_graspnet
在无约束、杂乱的环境中抓取看不见的物体是机器人自主操作的一项基本技能。尽管最近在全六自由度抓取学习方面取得了进展,但现有的方法往往包含复杂的顺序管道,这些管道具有几个潜在的故障点和不适合闭环抓取的运行时。因此,我们提出了一种端到端网络,它可以直接从场景的深度记录中有效地生成6自由度平行颚抓取的分布。我们的新型抓取表示将记录的点云中的三维点作为潜在的抓取接触点。通过在观测点云中生根完整的6自由度抓取姿态和宽度,我们可以将我们的抓取表示降维为4自由度,大大方便了学习过程。我们的类不可知论方法训练了1700万个模拟抓取,并很好地推广到真实世界的传感器数据。在一个机器人抓取不可见物体的研究中,我们获得了超过90%的成功率,与最近最先进的方法相比,故障率减少了一半。
30、GraspME -- Grasp Manifold Estimator(2021)
无代码
在本文中,我们引入了一个抓取流形估计器(Grasp Manifold Estimator, GraspME)来直接检测二维相机图像中物体的抓取支持度。为了能够自主地执行操作任务,对机器人来说,拥有这种周围物体的可抓取性模型是至关重要的。把握流形的优点是提供连续无限多的把握,而使用其他把握表示(如预定义的把握点)则不是这样。例如,可以在运动优化中利用这个属性,将目标集定义为机器人配置空间中的隐式曲面约束。在这项工作中,我们限制自己的情况下,估计可能的末端执行器的位置直接从二维相机图像。在这方面,我们通过一组关键点定义了抓取流形,并使用掩码R-CNN骨干在图像中定位它们。使用学习到的特征可以泛化到不同的视角,潜在的噪声图像和不属于训练集的对象。我们只依赖模拟数据,在简单和复杂的物体上进行实验,包括看不见的物体。我们的框架在GPU上实现了11.5 fps的推断速度,关键点估计的平均精度为94.5%,平均像素距离仅为1.29。这表明我们可以很好地通过边界框和分割蒙板估计对象,以及近似正确地把握流形的关键点坐标。
31、ContactDB: Analyzing and Predicting Grasp Contact via Thermal Imaging(2019)
抓取和操纵物体是人类的一项重要技能。由于手与物体的接触是抓取的基础,捕捉它可以带来重要的见解。然而,由于遮挡和人手的复杂性,通过外部传感器观察接触具有挑战性。我们提出了ContactDB,一个新的家庭物品接触地图数据集,它捕捉了在抓取过程中发生的丰富的手-物体接触,通过使用热相机实现。在我们的研究中,参与者在抓取3D打印的物体时具有后抓取功能意图。ContactDB包含了50个家庭对象的3750个3D网格,这些对象带有接触贴图纹理,375K帧同步RGB-D+热图像。据我们所知,这是第一个大规模的数据集,记录了人类抓手的详细接触地图。对这些数据的分析显示了功能意图和物体大小对抓握、触摸/避免“活动区域”的倾向以及手掌和手指近端接触的高频率的影响。最后,我们训练了最先进的图像平移和3D卷积算法,以从物体形状预测不同的接触模式。数据、代码和模型可以在https://contactdb.cc.gatech.edu上找到。
32、Robust, Occlusion-aware Pose Estimation for Objects Grasped by Adaptive Hands(2020)
许多操作任务,如放置或手内操作,要求对象的姿态相对于机器人的手。当手明显遮挡物体时,这项任务就很困难。这对于适应手来说尤其困难,因为它不容易检测到手指的构型。此外,RGB-only方法面临无纹理对象或手和对象看起来相似的问题。本文提出了一个基于深度的框架,旨在鲁棒的姿态估计和短的响应时间。该方法在手模型与点云重叠最大的情况下,通过高效的并行搜索来检测自适应手的状态。对手的点云进行剪枝,进行鲁棒全局配准,生成目标姿态假设,并对其进行聚类。错误的假设通过物理推理被剔除。在与观测数据一致的情况下,对剩余姿态的质量进行评估。对合成和真实数据的广泛评估表明,当应用于具有挑战性的、高度遮挡的不同对象类型的场景时,该框架的准确性和计算效率。一项消融研究确定了框架的组件如何帮助提高性能。该工作也为手6D目标姿态估计提供了数据集。代码和数据集可以在:https://github.com/wenbowen123/icra20-hand-object-pose获得。