前言:
兄弟们如果本文让你感觉能学到东西就麻烦各位动动发财的手来个一键三连,听说点赞,收藏,评论,关注的兄弟已经跳槽涨薪发财了哦。
【文章末尾给大家留下了大量的福利】

1:json模块的使用
字典是一种存储类型,json是一种格式(完全不同) json.loads()函数是将json字符串转化为字典(dict) json.dumps()函数是将字典转化为json字符串 json.dump()和json.load()主要用来读写json文件函数
2:接口自动化测试概叙
什么是接口测试: 前后端不分离:淘宝网站(响应的数据在页面,访问响应的数据是html的)返回的是一整个html(做接口难,需要解析数据,因为返回的是整个html代码) 前后端分离,前端和后端通过api(接口交互),返回的只是数据本身(App可能并不需要后端返回一个HTML网页) (市面上主流项目前后端分离走json格式的) 发请求以json数据格式返回的,通过api接口协议前后端进行交互的
3:swagger工具能导出接口文档的
4:前端页面:
安卓或者ios app,网页统层为前端展示(数据展示和用户的交互), 前端框架:html,js,css,vue(展示漂亮),nodejs
5:后端:
后台数据处理,校验,下订单等等业务处理(c语言,c++,java(大型都走java),go,python)
6:前端和后端的数据交互(接口)通过接口
有些问题前端可能屏蔽,但是后端没有做限制,校验都没有做的,绕过前端,抓包发请求的方式攻破后端,项目可能出现问题
7:接口的概念
接口是应用程序之间的相互调用 接口是实体或者软件提供给外界的一种服务 软件接口:api,微信提现调用银联的接口实现数据交互 一种是内部接口: 1:方法与方法之间的交互 2:模块与模块之间的交互 一种调用对外部包装的接口 web接口:http,https,webserver(目前大多做web接口) 应用程序接口:soket接口 走的tcp/ip协议的 数据库接口:
8:常用的接口方式(协议)
1:webservice :走soap协议通过http传输,请求报文和返回报文都是xml格式的,xml格式(soapui抓包)老项目(政府和银行) 还要解析数据,麻烦,而且速度可能有降低,通信比较严格 2:http协议:超文本传输协议(百分之70-80都走的http协议) get post delete put四种主要的请求方式 3:https协议:并非是应用层的一种新协议,只是http通信接口部分用ssl和tls协议代替而已
9:什么是接口测试:
项目需需求 案例:一个登录接口 场景:产品上规定用户名6-10个字符串下划线 测试人员在前端做了校验,通过 后端开发人员没有做校验 风险:直接抓包取篡改你的接口,然后绕过验证,通过sql注入直接随意登录 危害:公司损失 接口测试是市场的主流需求
10:接口测试目标
可以发现客户端没有发现的bug,(隐藏的bug)(提交订单,前端屏蔽了后端没有,可以随便乱填的) 及早爆出风险(保证质量正常上线) 接口稳定了,前端随便改 最重要加内存系统安全性,稳定性
11:接口自动化测试概叙(怎么做) (接口跑的是协议层。ui定位的是元素)
1:项目业务(了解项目业务) 2:接口文档(api文档) 3:接口用例 4:自动化脚本(根据接口文档和接口用例) 5:pytest框架 重点 6:调试执行 重点 7:allure报告 8:结果分析 9:持续集成
12:http协议概述
一:http响应报文包含四部分:如上图 1:请求行:主要包含信息:POST (请求方法)/search(请求url) HTTP/1.1 (http协议及版本)
二:http请求报文包含四部分:如上图 1:请求行: POST (请求方法)/search(请求url) HTTP/1.1 (http协议及版本) 2:请求头 请求头,项目可能有防爬操作,python等语言请求被屏蔽,所以可能需要加头伪装 3:请求空行 4:请求体(请求正文)

三:通过谷歌浏览器F12分析http报文(如上图) Host : 主机ip地址或域名 User-Agent :用户客户端,比如说操作系统或者浏览器的版本信息, (客户端相关信息,如操作系统,浏览器信息)可能拿到User-Agent去做兼容的, 服务器拿到User-Agent服务器生成兼容客户端的文本 浏览器需要服务器发回兼容我浏览器的版本,服务器拿到信息作一个判断, Accept: 接收的意思,指定客户端接收信息的类型,(我想接收的是一个图片还是html还是json还是一个xml文档告诉服务器,服务器对应返回) 如imag/jpg/,text/html,有时候我们一个接口给很多系统公司去用,这个系统可能想要的xml就告诉服务器你给我传递xml数据 有些公司想要的是json数据(主流都是json格式)告诉服务器你给我json 这里可以在请求头域设置Accept告诉服务器我需要的内容的格式 Accept-Charset :客户端接收的字符集,客户端接收字符集告诉服务器:如gb2312,iso-8859-1,utf-8 Accept-Encoding: 可接受内容的编码,如:gzip压缩格式, deflate (为了方便进行内容的传输,节省传输时间,提供传输效率,可能进行一些编码和压缩,节省传输流量) Accept-Language:接受的语言,如Accept-Language: zh-CN,zh;q=0.9 ,做国际化可以识别这里,中文环境给我中文数据 Authorization:客户端提供给服务端,进行权限认证的信息(进行权限认证的,请求的话有个鉴权的这样的功能, 不是说想什么服务器就发给什么,有可能需要进行一些基本的认证,认证信息可以放在这里) Cookie:携带的cookie信息 非常重要的字段(我登录成功之后就会在本地保存一些cookie,保存一些文本, 下一个请求的时候直接把cookie发给服务器,告诉服务器我已经登录了,有一个证明在这里cookie携带回去)做校验的 Referer:当前文档的URL,即从哪个链接过来的(我这个请求到底从那个连接过来的) 比如:Referer: http://test.lemonban.com/ningmengban/app/login/login.html登录的这个连接 是从login/login.html从我们这个网站的首页来的,防止盗链,把这个链接盗取了用到自己网站去, 或者说可以统计我这样的一个请求到底来自于那个页面, Content - Type:请求体内容类型,请求构建以什么形式传递参数的,如:x-www-form-urlencoded表单形式 (往服务器提交内容,告诉服务器我提交的内容是什么格式的,表单,json格式,xml格式) Content - Length:数据长度 ,(提交内容的数据长度有多少个字节告诉服务器,防止进行请求的篡改) Cache-Control:缓存机制,如Cache-Control:no-cache :别给我缓存 ,有些请求会缓存到本地的, Pragma:防止页面被缓存,和Cache-Control:no-cache作用一样(1.0中间的,为了兼容和1.0)
四:cookie 第一次访问网站,如果网站有cookie机制,访问第一个请求的时候返回set-cookie set-cookie设置cookie值,通过响应数据的头,响应头里面通过set-cookie把值给客户端,获取cookie里面对应的值
13:fiddler(抓包工具的使用)
fidder的使用技巧(能抓包,查看抓包数据): 能抓取https要设置证书:(免费的,开源的,能抓很多对应消息,app的也可以) fidder是一款免费,灵活,操作简单,功能强大的http代理工具,是目前最常用的http抓包工具之一 可以抓取所有的http/https包,过滤会话,分析请求详细内容,伪造客户端请求,篡改服务器响应,重定向,网络限速,断点调试等功能 fiddler的工作原理: 正向代理(正向代理服务器,通过浏览器发送请求以前是直接发给服务器,fidder转发(代理服务器), 浏览器请求发给fidder代理服务器,fidder代理服务器转发给服务器, 服务器数据转发给fidder代理服务器,代理服务器发给浏览器 正向代理: 转发浏览器的请求和响应,抓包工具 对客户端透明 反向代理: nginx——负载均衡的——性能 一个服务器 tomcat db(现在用户级别很大,一个tomcat搞不定,需要帮手,三个tomcat分担流量(怎么协调加nginx--负载均衡)) 浏览器发请求过来,不知道请求发给谁,请求量很大,通过nginx把请求分发到各个tomcat里面去,避免的一个tomcat承受不住
下面分享我整理的这份2023年可能是最全的自动化测试工程师发展方向知识架构体系图。
码尚教育软件测试全职业生涯进阶从零到测试开发VIP课程| ProcessOn免费在线作图,在线流程图,在线思维导图
如果对你有帮助的话,点个赞收个藏,给作者一个鼓励,也方便你下次能够快速查找,感谢。
如果你想获取该文章配套的视频视频教程以及练手的接口。请狠狠点击文章末尾推广小卡片
并把所需的资料的文章链接发给我即可领取
如果你想获取简历模板+面试技术宝典+求职视频+上千份测试真题,
请狠狠点击文章末尾推广小卡片
并把所需的资料的文章链接发给我即可领取
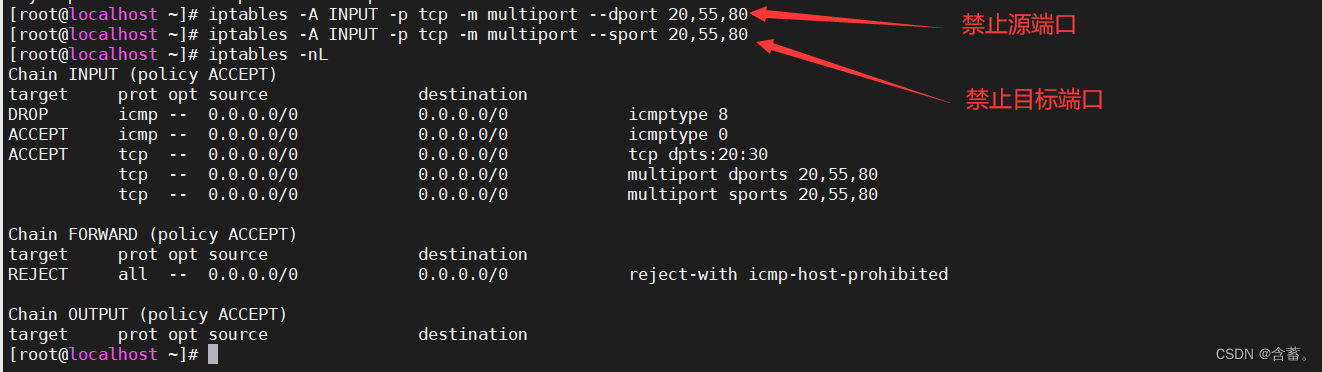
14:接口工具对比:(掌握fidder)
fidder 免费的http查看工具,系统代理,工作在应用层 独立运行(是) 支持移动设备(是) 是否收费(否) wireshark 网络抓包,监听网卡,工作在网络接口层 独立运行(是) 支持移动设备(否) 是否收费(否) httpwatch 集成到IE,chrome中的网页数据分析工具 独立运行(否) 支持移动设备(否) 是否收费(基础版/专业版) charles http代理,http监控,http反代理,查看http通讯查看信息工具 独立运行(是) 支持移动设备(是) 是否收费(是) ByrpSuite http代理,用于工具web应用程序的集成平台, 独立运行(是) 支持移动设备(是) 是否收费(是) 包含了很多工具,抓包,漏扫,爆破,黑客必备工具之 wireshark--底层,网络层--用这个
15:websocket: (和http一样是传输协议)
websocket传输协议实时性强 使用场景: 聊天系统 股权交易 直播--部分业务
16:cookie详解
服务器发给客户端:请求的响应数据 响应头:Set-cookies 本地存放cookies攻击 cookie缓存身份的概念:a请求发给服务器,a第一个请求没有带cookie,比如登录操作一开始请求不带cookie的,服务器响应把cookie放到响应头:set-cookie 浏览器拿到set-cookie会自己进行处理,然后第二个请求发出去,就会带上cookie进行校验 浏览器访问里面自己传递,但是接口请求是不会自己带cookie的,需要提取cookie a响应头里面把cookie拿出来,放到一个变量,下一个b请求把cookie放到请求头 不同用户的cookie不一样的,不然会冲突的 cookie里面包含很多内容:但是最常见的是sessionid(会话id) 简单项目里面有cookie就差不多了,但是有的项目里面cookie里面带token-复杂点 cookie是分站点的,站点和站点之间的cookie是相互独立的 浏览器的cookie是保存在浏览器的某个位置 服务器端可以通过:响应头中的set-cookie参数,对客户端的cookie进行管理 浏览器的每次请求,都会把该站点的cookie发送给服务器进行匹配校验 实现登录:cookie+session配合使用 cookie不是只有登录,发送请求访问首页都有cookie。 cookie放在浏览器本地的(缓存里面),sessionid放在服务器的上 sessionid必须寄生在cookie里面,搭配cookie一起使用(sessionid值一般在cookie里面传过去的)
17:sessionid:翻译为会话id
sessionid就是会话id 身份验证-存放到 服务器 session是一个对象,是服务器产生的,保存在服务器中, session有自己的管理机制,包括session产生,销毁,超时等 session id是session对象的一个属性,是全局唯一的,永远不会重复
18:cookie和sessionid合作流程(常见的方式)
一:快速理解 用户登录成功服务器创建session,返回给客户端,客户端浏览器把session保存到它的cookie里 二:过程描述 登录成功服务器立马创建session,并通过(响应头)中的set-cookie属性把session返回给客户端 浏览器把响应头中的set-cookie内容保存起来,存在浏览器自己的cookie中 以后浏览器每次发送请求时,都会把该站点的全部cookie封装到请求头中,传递给服务器
19:tooken:令牌
token: 令牌(令牌代表身份信息,身份标识----身份校验(数据库db校验,每发个请求就需要校验很麻烦,避免频繁访问数据库,token就表示身份)) cookie和token(cookie里面最关键的就是session id值) cookie里面有时候有sessionid和token值 一般为了减少对数据库的访问,校验,数据库的账号密码, 做个令牌:token需要身份校验,账号密码校验,获取token值(返回token字符串)) token也是由服务器参数的,存在服务器的内存或者硬盘中 有一套产生规则,会涉及到加密算法 用token来实现登录 开发提供一个获取token接口,根据用户名+密码,获取一个token值--返回一个token(字符串) token值服务器通过什么发给客户端 通过响应头传给客户端 次要 通过响应消息体传给客户端 主要 通过cookie传递给客户端 很少 token使用场景: 服务器访问的同时,vip学员访问服务器,怎么保证vip学员的权限,普通用户也能访问,vip学员的访问的时候加一个验证,vip访问的同时加个验证, 访问网站同时校验身份,必须去vip官网去认证,通过vip账号密码拿到token值,去访问服务器时候时候token带上。 做二次校验,身份的校验,不是每个人都能访问这个网站,只有vip学员才可以, 访问之前vip学员拿vip账号去网站认证一下,获取到token值然后每次访问都带上这个token就可以了, 这个token可以在cookie里面,token放头headers里面和cookie里面都可以,这时候token值,cookie里面自行加token值,自行组装 额外增加某些校验参数,cookie里面可以加一些值,如token值,自行封装cookie 认证的时候token身份二次校验,token放cookie里面和头里面都行(校验是不是vip学员)
19:接口测试数据格式
一:接口自动化测试数据源(测试用例来源哪里)测试用例一般存放在哪里
1:excel测试用例
2:yaml格式用例
3:csv
二:自动化脚本中的数据类型:
1:表单格式:
[urlencoded格式]:又叫form格式,或者是x-www-form-urlencoded格式(type类型为表单形式,传数据表单形式)
表单格式是键值对组成的,键和值之间用=,多个值之间用& 如:name=zhengsan&age=16
2:json格式(str字符串:键值对类型的字符串)
json有对象,数组两种结构,有字符串,数字,逻辑值,空值四种数据类型
用大括号{}表示对象,对象由属性组成的,属性由键值对组成的,键和值用冒号隔开,属性之间用逗号隔开,键必须用双引号引起来
用中括号[]表示数组,数组由单独的值组成
json灵活,json可以嵌套
20:json格式详解
对象:大括号表示,对象由属性组成,属性由键值对组成,键和值对之间用冒号隔开,属性之间用逗号隔开,另外键必须双引号
{"姓名":"姚明","年龄":38}
数组:用中括号表示
["小明","小李","小百"]
[{"姓名":"姚明","年龄":38}]
嵌套:对象中可以再嵌套对象和数组
{"姓名":"姚明","年龄":38,"家禽":["小明","小李","小百"]}
21:了解教管系统:(在线管理系统)(前后端分离的) 什么框架,什么配置
项目描述: 教师管理系统是一款在线管理学生课程的一款软件 主要功能包括: 课程:包含了所有课程名和课程详情 老师:可以查看老师姓名,授课内容及授课班级 学生:包括班级号,班级包含课程,所属学生和班级学生进度 框架结构: 后端架构:cherrypy与django结合 diango:包含了所有的课程名和课程详情 cherrypy:使用cherrypy作为diango的development server 数据库: sqlite 前端: html,js,css
22:python自动化过程中配置文件格式:
配置文件格式:text(很少用),cnf,ini,yaml,excel(很少用),.py也可以
23:简单的接口测试源代码
config.py #配置文件
#time:2020/10/5
HOST="http://127.0.0.1:80" #等同localhost,但是建议写localhost,写url全称,项目换了环境只要改这个配置url就行
http://127.0.0.1:80/mgr/login/login.html
http://127.0.0.1:80/mgr/login/login.html
http: // localhost / mgr / login / login.html
账号和密码:auto / sdfsdfsdf
login.py
# 登录接口
import requests #请求库使用request
import json
from api接口自动化.teachTest.config import HOST
#user_headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"}
# 2:url路径--考虑可维护性(各个环境ip不同,不同环境测试,增加配置文件)
url =f"{HOST}/api/mgr/loginReq"
#3:头部,请求头---头都是字典类型的
header={"Content-Typ":"application/x-www-form-urlencoded"} #type类型
#4--请求体body,最常用都是字典写的(传表单形式可以字典来做)
payload={"username":"auto","password":"sdfsdfsdf"}
print(type(payload))
#5--发送请求
#def post(url, data=None, json=None, **kwargs):
'''
url:必填
data=None #请求体的参数---默认表单类型---写的参数默认转成表单传递给客户端---application/x-www-form-urlencoded(传表单就是传data)
传data就不用传type---因为传的时候默认header头格式是表单格式
json=None #请求体的参数---默认json格式---写的参数默认转成json传递---application/json (传json格式就传json)
**kwargs #关键字可变数量参数,传 变量=值(一般传递:头headers,cookies,proxy代理,ssl校验)
cookies,token--一般封装到头部。
'''
#reps=requests.post(url,data=payload,headers=header) #reps请求本身的对象
#
1:打印请求头 print(reps.request.headers)
2:打印请求体 print(reps.request.body) #username=auto&password=sdfsdfsdf
3:打印响应体 print(reps.text) #text这是查询str字符串类型,返回的类型:字符串
print(reps.json()) #也能查看响应体的,但是响应体必须是json,不是json就报错了--(返回的类型:字典)
print(json.loads(reps.text)["retcode"],type(reps.text)) #返回的类型:字符串,转字典json.loads()
4查看响应头 print(reps.headers) #访问接口,接口返回一个Set-Cookie,Set-Cookie是客户服务器给客户端的,在headers里面体现出来
cookie值如果后面接口需要就需要带上去(标识)
5--用json传输入,
reps=requests.post(url,json=payload,headers=user_headers) #这样写传入的数据是json格式,但是接口文档要求传入表单,肯定不会成功,
reps.encoding="unicode_escape" #编码设置,为了看到中文(设置响应的编码格式)
print(reps.text) 查看响应体
print(reps.request.headers) 查看请求头 输出:header={"Content-Typ","application/x-www-form-urlencoded"}
reps=requests.post(url,json=json.dumps(payload),headers=header) #指明头,传的格式是表单(这样还是不行,后期自己研究)
reps.encoding="unicode_escape"
# print(reps.request.headers)
# print(reps.text)
#6:这样发请求fidder抓不到包(发给服务的没有经过fidder代理,fidder没有中转)
#如果需要fiddler抓包需要加个代理参数proxies:fiddler抓包需要请求经过他,---设置代理(设置代码发请求到fidder)
fiddler_porxies={
"http":"http://127.0.0.1:8888",
"https":"http://127.0.0.1:8888"
} #写fiddler的端口号+fiddler的路径, 抓包两个协议,http和https(都走的http所以下面的不用改成https)
reps=requests.post(url,data=payload,headers=header,proxies=fiddler_porxies) #porxies=porxies加到代理专门参数
reps.encoding="unicode_escape"
print(reps.request.headers)
print(reps.text)
lesson.py
#time:2020/10/6
import requests
import json
from api接口自动化.teachTest.config import HOST
lesson_url =f"{HOST}/api/mgr/sq_mgr/"
Host = 'http://127.0.0.1:80'
api_url = f'{Host}/api/mgr/sq_mgr/'
header = {'Content-Type': 'application/x-www-form-urlencoded'}#字典
payload={
"action":"add_course",
"data":'''{"name":"初中化学",
"desc":"初中化学课程",
"display_idx":"4"
}'''
}
print(type(payload)) #根据接口文档data里面要是个json,现在这么写{"name":"初中化学", "desc":"初中化学课程","display_idx":"4"}是个字典
#加三引号'''{"name":"初中化学", "desc":"初中化学课程","display_idx":"4"}''',表达是个json
reps = requests.post(lesson_url,data=payload)
reps.encoding = 'unicode_escape'
print(reps.request.headers)
print(reps.text)
'''
# type--json
#参数 payload2
1- json参数---建议使用 reps = requests.post(api_url,json=payload2)
2- data参数 import json
reps = requests.post(api_url,data=json.dumps(payload2),headers = header)
使用data参数传递json,(接口本身接收的数据是json)data写json---头也要指定json格式,使用data默认是表单,所以要改成json,
json.dumps()用于将字典形式的数据转化为字符串
data=json格式----headers=json格式(两边都要转,麻烦)
'''
24:requests.post方法:data和json参数区别(重点)
一:params参数, 如果传入的是字典,自动编码为表单,针对的是get方法, 一般get请求需要---def get(url, params=None, **kwargs):----只有get请求传有params,其他请求没有 二:data参数。 如果传入是字典,自动编码为表单形式传递, 针对的是post/put方法 三:data参数, 如果传入的是字符串,按原格式直接发布出去 针对的是post/put方法 四:json参数, 如果传入的是字典,自动编码为json字符串 针对的是post/put方法 五:json格式, 如果传入的是字符串,按原格式基础上添加双引号发布出去 针对的是post/put方法 六:headers参数, 传递的是字典格式,针对的是所有方法 data=json.dumps(dictpayload)等同于json=dictpayload dictpayload是一个字典 (data=payload)所以data和json传递数据最好以字典形式去做,payload请求体最好构建成字典,也可以构建成字符串,看具体情况 用data还是json取决接口本身的type类型,
25:requests库请对应的方法和相应的参数:(request库最基本的四种方法)
参数\函数 get post(提交) put(修改) delete(删除) url 有 有 有 有 params 有 data 有 有 有 json 有 headers 有 有 有 有 cookies 有 有 有 有 params参数是get方法独有的
26:requests库响应消息体四种格式:(打印的信息)
四种返回格式: 说明 用处 r.text:文本响应内容 返回字符串类型 获取页面html r.content:字节响应内容 返回字节类型(byte) 下载图片或者文件,r.content返回的是字节流 r.json:json解码响应内容 返回字典格式 明确服务器返回json数据才能用 r.raw:原始响应内容 返回原始格式(和fiddler一样,抓取源数据)
27:request库的使用,查看请求信息和响应信息,设置编码等
r.status_code 得到响应状态码 r.headers 打印出响应头,获取一个字典 r.cookies 获取cookies reps.text 打印响应体 reps.json() 查看响应体,返回一个json格式 r.request.headers 打印请求头 r.request.body 打印请求体 reps.encoding="unicode_escape" 编码设置,为了看到中文(设置响应的编码格式)
28:get可以post来提交,get参数写到/后面去,
29:cookie值的获取和传递操作实战
一:直接获取cookie对象操作,如果不需要对cookie进行任何操作封装直接这样取值
reps.cookies 获取的是一个cookie对象,不能改
在login函数里面把reps.cookies获取到的的cookie对象return返回出去给调用的函数使用
外面拿到这个cookie对象后直接cookies=cookie这样传递就行,不需要二次封装
reps=requests.post(lesson_url,data=payload,cookies=cookie)
logim.py
import requests
import json
from api接口自动化.teachTest.config import HOST
def login(inData):
url = f"{HOST}/api/mgr/loginReq"
header = {"Content-Typ": "application/x-www-form-urlencoded"} #表单传递
payload = inData #后面账号密码可能变化,写成参数
reps = requests.post(url, data=payload, headers=header)
reps.encoding = 'unicode_escape'
return reps.cookies #直接可以取响应的cookie对象,
#return reps.headers # 返回是个字典
#return reps.headers['Set-Cookie'] #返回:sessionid=twenk9lrxixxplrlfqjusmlq6m1dxvfs; HttpOnly; Path=/(返回sessionid=“”)
#return reps.cookies['sessionid'] #通过cookie对象取值sessionid值(cookie对象本身带sessionid的)
#通过cookie对象本身的键取获取sessionid值
if __name__ == '__main__':
res=login({"username":"auto","password":"sdfsdfsdf"})
print(res)
lesson.py
import requests
import json
from api接口自动化.teachTest.config import HOST
from login import login
#cookie值获取了怎么用 cookies=cookie,直接传的cookie对象,cookies=cookie就行,cookie对象传递不需要cookie封装到头
#如果是获取的cookie的值,字符串类型那就需要封装到头
#固定的cookie对象,不需要二次封装,直接取cooke,获取得cookie对象,就可以直接cookies=cookie传递
cookie=login({"username":"auto","password":"sdfsdfsdf"}) #直接获取cookie对象得方法
lesson_url =f"{HOST}/api/mgr/sq_mgr/"
Host = 'http://127.0.0.1:80'
api_url = f'{Host}/api/mgr/sq_mgr/'
header = {'Content-Type': 'application/x-www-form-urlencoded'}
payload={
"action":"add_course",
"data":'{"name":"初中化学01","desc":"初中化学课程","display_idx":"4"}'
}
reps=requests.post(lesson_url,data=payload,cookies=cookie)
reps.encoding = 'unicode_escape'
print(reps.text)
二:通过响应头headers里面的set_cookie获取sessionid值
通过响应头获取cookie里最重要的sessionid来封装cookie,如果cookie需要做二次封装,自带的cooike不够,可以这样做
cookie在响应头里面 a=reps.headers 返回的是一个字典
import requests
import json
from api接口自动化.teachTest.config import HOST
def login(inData):
url = f"{HOST}/api/mgr/loginReq"
header = {"Content-Typ": "application/x-www-form-urlencoded"} #表单传递
payload = inData #后面账号密码可能变化,写成参数
reps = requests.post(url, data=payload, headers=header)
reps.encoding = 'unicode_escape'
return reps.headers['Set-Cookie'] #得到的是一个 sessionid=md31vzd54tvqut8eaxohxl9pjedeujk8; HttpOnly; Path=/这种类型
#后面还要自己转化
三:通过cookie对象获取sessionid值
获取set-cookie的sessionid值或者cookies的sessionid值来自行封装cookie(cookie需要加东西可以这么做),
二次封装cookie这样搞,cookie里面最关键的sessionid值取出来需要自行封装cookie,
reps.headers 返回是个字典,我们要的sessionid在set-cookie里面,
login函数return reps.headers[ 'Set-Cookie'] 得到sessionid=md31vzd54tvqut8eaxohxl9pjedeujk8; HttpOnly; Path=/
return reps.cookies['sessionid'] 也能直接获取sessionid的值,
cookie对象本身带sessionid的,通过键本身获取得到:bm2k2n3eyo0r09jpuie8kkcjjd63gzob sessionid的值
取得干净地sessionid值,reps.cookies['sessionid']这种方法最方便,不需要任何处理,
得到sessionid值自己封装cookie:
user_sessionid=login({"username":"auto","password":"sdfsdfsdf"})
user_sessionid=bm2k2n3eyo0r09jpuie8kkcjjd63gzob 获取用户得sessionid值
sessionid一般在cookie里面的,sessionid是cookie得一部分,把user_sessionid值封装成一个cookie
user_cookie={"sessionid":user_sessionid} 这就把cookie封装好了 先获取sessionid然后自行封装的
如果cookie需要加东西,这样直接自己在封装cookie里添加: user_cookie={"sessionid":user_sessionid,"name":"ywt"}怎么加都行,灵活,
这时候直接发送请求附加自己组装的cookie:
reps=requests.post(lesson_url,data=payload,cookies=user_cookie)
import requests
import json
from api接口自动化.teachTest.config import HOST
def login(inData):
url = f"{HOST}/api/mgr/loginReq"
header = {"Content-Typ": "application/x-www-form-urlencoded"} #表单传递
payload = inData #后面账号密码可能变化,写成参数
reps = requests.post(url, data=payload, headers=header)
reps.encoding = 'unicode_escape'
return reps.cookies.['sessionid']
30:一般头部header和cookie等都封装成字典,灵活,字符串不一定能识别(请求头和响应头一般都是字典)
31:token值得获取和传递操作实战
一:获取简单的token,不加密的token(明码的token)
import requests
from random import randint
import json
import pprint # 这个函数只能完美打印字典的数据类型
HOST = "http://47.96.181.17:9090" # 主机地址
# 简单的token,不加密的token(明码的token)
# 1获取token值
def get_token():
token_url = f"{HOST}/rest/toController"
header = {"Content-Type": "application/json"} # 头部字典类型
payload = {"userName": "J201903070064", "password": "362387359"}
reps = requests.post(token_url, json=payload, headers=header)
# pprint.pprint(reps.json()) #字典类型可以使用pprint完美打印
return reps.json()['token']
# 2新增用户
def add_user():
adduser_url = f"{HOST}/rest/ac01CrmController"
token = get_token()
print(token)
header = {"Content-Type": "application/json", "X-AUTH-TOKEN": token}
payload = {"aac003": "张三",
"aac004": "1",
"aac011": "21",
"aac030": f"135{randint(11111111, 99999999)}", # 随机传入号码值
"aac01u": "88002255",
"crm003": "1",
"crm004": "1",
"crm00a": "2018-11-11",
"crm00b": "aaaaaa",
"crm00c": "2019-02-28",
"crm00d": "bbbbbb"
} # 字典类型
# token一般在头部传递,
reps = requests.post(adduser_url, json=payload, headers=header)
return reps.json()
if __name__ == '__main__':
pprint.pprint(add_user())
二:加密的token token加密+上传文件接口
上传文件接口请求头需要Cookie: token=通过获取 token 接口获取(cookie里面放sessionid还是token都可以,看开发和接口文档) 如果判断不了,可以使用fiddler抓个包查看
import requests, json
import hashlib # 这是加密库
def get_md5_data(psw): # MD5加密--password String md5(‘zr’+111111 +‘hg’)
password = f"zr{psw}hg"
md5 = hashlib.md5() #1:创建一个md5对象
md5.update(password.encode("utf-8")) #2:完成加密,updata方法加密 对象.方法(需要加密的对象.encode("utf-8")),加密时候最好设置编码
# 对字符串进行编码后再进行一个加密
# md5(b"zr111111hg") #也可以传二进制数据直接进行编码:如下
# import hashlib
# md5 = hashlib.md5()
# md5.update(b'zr11111111hg')
# print(md5.hexdigest())
# 方法二:一行也可以写
# print(hashlib.md5(b'zr11111111hg')).hexdigest()---这样写也可以,(传bytes类型。可以这么写)
# 3要输出结果,return
return md5.hexdigest()
# 1:获取接口需要的token
HOST = "http://121.41.14.39:2001"
def get_token(inname, inpsw):
token_url = f"{HOST}/token/token" # url
header = {"Content-Type": "application/x-www-form-urlencoded"} # 请求头,封装成字典
# password String md5(‘zr’+111111 +‘hg’)----password需要md5加密
# 打开md5加密网页(百度查询) 把“zr111111hg”加密码提取出来:5c4fcc5add5d087de1e8534189c687f7
# md5加密网站;http://tools.jb51.net/password/CreateMD5Password/
payload = {"mobile": inname, "password": get_md5_data(inpsw)}
reps = requests.post(token_url, data=payload, headers=header)
return reps.json()["data"] # 这里的data就是我们要的token
# 2:文件上传接口
# post方法,文件上传接口,先抓个包
# Content-Type: multipart/form-data; boundary=WebKitFormBoundaryLpsjAVSe95yonybu--文件上传有个随机参数boundary,算法可以做
# 做文件接口一般不带这个type,也不带头,除非真的校验,要去找对应的算法---麻烦(传type会有问题)
# 文件body---
# ------WebKitFormBoundaryLpsjAVSe95yonybu
# Content-Disposition: form-data; name="file"; filename="QQ图片20201009011422.png"
# Content-Type: image/png
# name="file"---你传给那个变量,文件名
# filename="QQ图片20201009011422.png"---文件对象
# Content-Type: image/png 文件类型
# 文件不要写绝对路径(写相对路径)---不然代码移植很麻烦
def file_doUpload():
file_url = f"{HOST}/user/doUpload"
# {变量:(文件名,文件对象,文件的类型)} ----文件对象需要open打开,open函数返回文件对象---文件对象有三个部分
# 文件的打开不能用read,会乱码,只能用rb模式打开,二进制模式打开,读出是bytes字节的
# 传文件的话一般这样做的需要--文件变量(文件对象)--组装好
payload = {"file": ("QQ图片20201009011422.png", open("../data/QQ图片20201009011422.png", "rb"), "jpg/png/gif")}
reps = requests.post(file_url, files=payload)
print(reps.json())
file_doUpload()
32:测试用例的设计
大部分是功能的用例:中文描述很多,用例为人设计,前置条件---步骤--预取结果--实际结果 自动化用例设计不同 用例为代码设计(代码好处理才行) 用例需要数据分离 用例设计需要了解功能,有哪些模块得知道,
33:自动化测试用例设计:代码好处理,接口来说,需要
1:url 2:body 3:预期结果 4:请求方式 5:路径 6:接口名称 7:用例名称 8:模块 9:用例id 10:请求参数类型 11:请求参数) 代码构建请求可能用到的,自动化测试用例要让代码容易解读, 为什么需要用例名称:如果一个模块有很多接口,比如新增,列出,删除课程,一般按照顺序来测试, 如果不按照顺序(有名称可以自动识别用例模块,那个接口的,接口用例写的时候打乱,有用例名称 可以自己识别组装成列表)---一般接口用例按照模块顺序写,方便

34:前后端分离项目才好做接口测试,api接口交互来做的,(接口返回对应数据json比较多)
前后端不分离发一个接口数据返回在html页面,数据很多,n个单词,不知道接口数据在哪里(可能在某个元素里面)做起来麻烦 接口自动化偏向前后端分离的项目(返回数据格式比较适合,html捞取数据很麻烦)
35:接口用例
最关键的用例多少个取决于请求body不同,请求body里有必填,可选填,每个参数有指定的类型和长度 比如:要求name必须中文的,必填参数,不能有非法字符,有位数,个数,长度,编码设置(int,字符串都有现在)等限制 我们做用例很多时候针对接口用例的数据一般写字典,方便(data和json都能传字典,不需要代码里再转换) swager框架可以导出对应的接口文档,没有可以导出来--(如果什么都没有,自己写文档,)
36:接口项目代码大概框架如下

teach_sq 项目名称,项目根目录 data 放接口测试用例数据(用例和配置分开,如果还要配置文件放个config包) lib 放封装接口代码的(原代码),按照不同模块api,web的对应去封装 api_lib lesson.py login.py(登录模块) app_api web_ui report 测试报告文件夹 test_case 测试用例文件夹 tools tools:第三方封装工具代码 如加密或者算法模块 execlMethod.py excel用例表的读取和写入操作 get_MD5.py conf 配置文件 config.py log 日志模块
37:接口测试代码实战
一:tools文件夹源代码:封装第三方封装工具代码-如加密或者算法模块
execlMethod.py
import xlrd #读excel模块
from xlutils.copy import copy #写excel(复制excel)
# import xlutils
#1:_读取excel的数据(简单的功能可以直接写函数就行,没必要写成类),
def get_excelData(sheetName,startRow,endRow,body=6,reps=8):
'''
读取excel表函数 ,读取多行的body和reps参数,返回列表套元组的数据[(),(),()]
:param sheetName: 打开的表名
:param startRow: 读取excel开始行
:param endRow: 读取excel结束行
:param body: 读取excel的哪一列,获取body传参
:param reps: 读取excel的哪一列,获取预期响应数据
:return:
'''
excelDir="../data/测试用例-v1.4.xls"
workBook=xlrd.open_workbook(excelDir) #打开excel创建一个excel对象
#sheets=workBook.sheet_names() #看有几个表
#2取对应的表sheet来操作
worksheet=workBook.sheet_by_name(sheetName) #取哪个表传表名sheetName就行
#worksheet.row_values(0) #这是读取一excel表的一整行的,返回一个列表
#我们不需要读取一整行,只需要请求参数,和返回结果就行,读单元格
#获取单元格(单元格怎么获取---表.单元对应的值(行,列))
#return worksheet.cell(1,6).value #2行7列获取的是请求的body #.value代表单元格的值
#return worksheet.cell(1,8).value #2行9列获取的是预期的返回结果
#print(worksheet.nrows) #获取行数,获取所有的行(如果用例一个模块很多接口写在excel里面,新增课程,删除课程,各种用例在一起
#这种获取所有行不可行 )
#所以读取excel用例可以考虑传参,开始多少行和结束多少行
reslist=[]
for one in range(startRow-1,endRow):
#获取每个单元格
reslist.append((worksheet.cell(one,body).value,worksheet.cell(one,reps).value))
return reslist
#2:写入数据(现在没有用框架,把结果写在excel表里面)
def set_excelData(sheetIndex,startRow,endRow,colNum,inData,excelOutDir="../report/res.xls"): #inData传列表或者元组可迭代数据,写很多数据
excelDir="../data/松勤-教管系统接口测试用例-v1.4.xls"
workBook=xlrd.open_workbook(excelDir,formatting_info=True) #打开excel创建一个excel对象
#formatting_info=True,保证excel格式一致(不破坏原表格式)
#格式也复制过去(不破坏原表格式)
newWorkBook=copy(workBook) #把打开的excel复制一个全新的workBook对象 (有的只写不读,有的只读不写),另存其他文件这么写
newWorksheet=newWorkBook.get_sheet(sheetIndex) #newWorksheet全新的excel文件表对象,
#newWorkBook.get_sheet(sheetIndex)获取对应的编号(第一个表)
#获取全新的workbook对象的需要写结果的表对象(表名:sheetIndex传参)
idx=0
for one in range(startRow - 1, endRow): #如果写数据不是从2行开始,从10行开始,range(10,12),indata[one]会越界
newWorksheet.write(one,colNum,inData[idx]) #写单元格,表里面的write写,write(行,列,数据)
idx=idx+1
newWorkBook.save(excelOutDir) #保存路径(保存对象)
if __name__ == '__main__':
print(get_excelData('1-登录接口', 2, 5))
set_excelData('1-登录接口', 2, 5, 9, (1,2,3,4))
get_MD5.py
#time:2020/10/9
import hashlib # 这是加密库
def get_md5_data(psw): # 自己MD5加密--password String md5(‘zr’+111111 +‘hg’)
password = f"zr{psw}hg"
# 1:首先创建一个md5对象
md5 = hashlib.md5()
# 2:完成加密,updata方法加密
md5.update(password.encode("utf-8")) # 对象.方法(需要加密的对象.encode("utf-8"))----加密时候最好设置编码
# 对字符串进行编码后再进行一个加密
# md5(b"zr111111hg") #也可以传二进制数据直接进行编码:如下
# import hashlib
# md5 = hashlib.md5()
# md5.update(b'zr11111111hg')
# print(md5.hexdigest())
# 方法二:一行也可以写
# print(hashlib.md5(b'zr11111111hg')).hexdigest()---这样写也可以,(传bytes类型。可以这么写)
# 3要输出结果,return
return md5.hexdigest()
二:lib源代码文件夹
api_lib login.py import requests import json from config import HOST import json from tools.get_MD5 import get_md5_data #加密函数 class Login: def login(self,inData,inFlage=True): #登录方法,实例方法 url = f"{HOST}/api/mgr/loginReq" header = {"Content-Typ": "application/x-www-form-urlencoded"} payload = json.loads(inData) #多这步转换,万一inData需要转换,转成字符串还是什么 reps = requests.post(url, data=payload, headers=header) reps.encoding = 'unicode_escape' if inFlage ==True: #为true默认返回cookie的,这个登录的接口会作为后续接口的前置条件,需要返回cookie return reps.cookies["sessionid"] elif inFlage==False: #本身登录接口需要调用校验是否成功 return reps.json() if __name__ == '__main__': login1=Login() print(login1.login('{"username": "auto", "password": "sdfsdfsdf"}', False)) #现在调用函数需要传字符串,因为里面有payload = json.loads(inData) indata只能传字符串,里面再转成字典
三:test_case 现在还没有使用到pytest框架,直接把执行的结构写到excel文件夹里
test_login.py
#自动化执行excel表用例
#1:先获取对应的用例数据
import json
from tools.execlMethod import get_excelData,set_excelData
from lib.api_lib.login import Login
testData=get_excelData('1-登录接口', 4, 5)
# 2:数据请求获取对应的数据(跑数据)
reslist=[]
for line in testData:
#3构建登录请求
res =Login().login(line[0],inFlage=False)
#4:判断实际结果和预期结果 if
if res['retcode']==json.loads(line[1])['retcode']:
res="pass"
else:
res = "fail"
reslist.append(res)
#3:写数据到excel
set_excelData('1-登录接口',4,5,9,reslist)
38:接口api编写心得:
编写某个模块的源代码的时候,需要考虑这个模块有没有前置条件, 一个模块最好编写一个类函数,看这个类函数里面所有的接口函数特点(模块里面所有接口url是不是一样的,(可以创建课程对象的时候就创建出来,定义成实例对象) sessionid值,cookie需要sessionid封装---每个接口都需要sessionid(创建课程实例也可以传sessionid封装好一个cookie))
39:get请求两种写法
1:参数可以跟到url后面 2:params参数也可以做
40:面试自动化做到什么程度
1:规范流程 所有得代码传git——>git提交后通过ginkins去触发,自动化角度(脚本去触发,项目版本发布触发自动化脚本执行)) 需要搭建服务器(搭建持续集成服务器,cicd),所有的代码环境都在服务器里面 开发角度:版本迭代发布到git进行jinkins自动打包,触发自动化执行 自动化人员角度:通过git传自动化脚本,触发对应场景触发自动化脚本执行 版本变化+脚本变化(都能触发自动化脚本执行) 2:本机跑项目(没有上jinkins持续集成的线路) 代码跑完了生成报告后发邮件(代码仅一个人有) 线上 线下
41:http和web socket
有些接口不一定有requset库,用socket去发的,socket会话,通信(人工智能,物联网,通信比较多,实时性强)
42:yaml 专门用来做配置文件的
一:yaml格式简介(yaml文件非常简洁) yaml的意思是:yet anoter markup language(仍是一种置标语言)的缩写 yaml是专门用来写配置文件的语言,非常简洁强大,远比json格式方便 可以用yaml做自动化测试框架的配置文件或者用例文件 yaml作配置文件config file 比如说运行版本参数或者设置on和off都可以使用yaml来做 二:python搭建yaml环境: pyyaml是python的一个专门针对yaml文件操作的模块, pip install PyYaml 三:python操作yaml库 操作yaml文件主要两大步:读和写 pyyaml 5.1之后,通过禁止默认加载程序(FullLoader)执行任意功能,该load函数也变得更加安全
import yaml
yaml_str = """
name: xintian
age: 20
ob: Tester
"""
res_dict1 = yaml.load(yaml_str,Loader=yaml.FullLoader)
print(res_dict1)
print(type(res_dict1))
#控制台----输出
{'name': 'xintian', 'age': 20, 'job': 'Tester'}
<class 'dict'>
四:yaml实际操作 项目工程里面创建一个config文件夹 config文件夹:(配置参数文件 普通文件夹)python文件放包里面,其他文件放文件夹里面(一个有init一个没有) teach_sq config test.yaml yaml配置文件 五:yaml格式语法 基本规则: 大小写敏感 使用缩进表示层级关系(没有大括号或者小括号) 缩进时不允许使用Tab,只允许使用空格 缩进的空格数目不重要,只要相同层级的元素对齐即可 #表示注释,从它开始到行尾都被忽略 yaml中的值有以下基本类型 字符串 整形 浮点数 布尔型 null 时间 日期
六:yaml文件读取操作
test.yaml
#井号表示注释
#1:字典类型::表示字典:冒号后面必须加空格,通过键去取值(字典类型) {'name': 'tom', 'age': 20}
name: tom
age: 20
#2:列表类型 列表加 -横杠 [10, 20, 30]
- 10
- 20
- 30
#3:复杂的(嵌套的) [{'info': [10, 20, 30]}] 列表嵌套字典,字典再嵌套列表
- info :
- 10
- 20
- 30
info : #{'info': [10, 20, 30]}字 典嵌套列表
- 10
- 20
- 30
#4:模式选择,on代表代码执行某个逻辑,off代表代码不执行某个逻辑,数据代码分离(配置参数修改)
#{'mode': True, 'mode2': False} yaml里面on表示ture,off表示false
mode: on
mode2: off
#5:设置变量,(某些数据过长,又想一直再yaml里面用,可以这样定义,) #&var表示定义一个变量var,把‘我是变量 ’的值定义成var变量,变量var一直要用,而且很长的话可以定义成变量,后面可以使用变量名var #name也是一个值,把name的值定义成变量var,可以改名字 name: &var 我是变量 mode: on mode2: off data: *var #*var 表示使用变量var *代表取变量名 *var表示使用变量var &var表示定义变量var
yaml文件的读取
yamlTest.py
import yaml #导入yaml库
yamlDir="./config/test.yaml" #对文件操作都需要写路径
#1:打开操作,不管什么文件都需要一个open打开操作
fo=open(yamlDir,"r",encoding="utf-8") #以文件对象打开,r以字符串读取,打开的编码格式encoding="utf-8"(可以打开中文)
#fo返回文件对象
#2:使用yaml库操作(加载使用yaml库)load--加载--读取
res=yaml.load(fo,Loader=yaml.FullLoader) #yaml库.load方法(加载读取)-----加载文件对象
#Loader=yaml.FullLoader---加载方式,安全全部加载,yaml 5.1后面的版本必须写加载方式,不然警告
print(res)
八:yaml文件写入操作:dump去写
有些项目运行时候会把数据写到一个文件里面去
启动参数,运行参数,什么模式,什么状态写到一个文件,运行信息,运行日志---写入
写入会覆盖了前面写的内容,
python操作yaml库写入文件:字典--转换--字符串
写个简单的字典:python_obj = {"name": u"灰蓝","age": 0,"job": "Tester"},然后dump写进去就行
import yaml
python_obj = {"name": u"灰蓝","age": 0,"job": "Tester"}
f=open(yamlDir, 'w',encoding='utf-8')
y = yaml.dump(python_obj,f, default_flow_style=False) #default_flow_style 写的风格模式
print(y)
print(type(y))
def set_yaml(): #yaml文件的写入操作函数
python_obj = {"name": u"灰蓝", "age": 0, "job": "Tester"}
yamlDir='./test02.yaml'
with open(yamlDir, 'w',encoding='utf-8') as f:
yaml.safe_dump(python_obj, f)
open(yamlDir, 'w',encoding='utf-8') #换成a模式打开写入文件,不能出现同名的,w每次清空文件再写
九:多组yaml数据: yaml做配参和简单的用例如下:
#登录操作 下面每一个用例是列表 -是列表
- #test_01
url: /api/mgr/loginReq #路径
method: POST # 请求方法
detail: 正常登录
header:
content-Type: application/x-www-form-urlencoded
data:
username: auto
password: sdfsdfsdf
reps:
retcode: 0
- #test_02
url: /api/mgr/loginReq #路径
method: POST # 请求方法
detail: 没有账号,有密码
header:
content-Type: application/x-www-form-urlencoded
data:
username: ""
password: sdfsdfsdf
reps:
retcode: 1
reason: 账号密码错误
- #test_03
url: /api/mgr/loginReq #路径
method: POST # 请求方法
detail: 有账号,没有密码
header:
content-Type: application/x-www-form-urlencoded
data:
username: auto
password: ""
reps:
retcode: 1
reason: 账号密码错误
- #test_04
url: /api/mgr/loginReq #路径
method: POST # 请求方法
detail: 账号密码都没有
header:
content-Type: application/x-www-form-urlencoded
data:
username: ""
password: ""
reps:
retcode: 1
reason: 账号密码错误
读取上面这种yaml多个用例:
import yaml
import json
def get_yaml_data():#[(),()]
yamlDir = './config/test02.yaml' #路径
#1- 打开操作
fo = open(yamlDir,'r',encoding='utf-8')
#2- 使用库操作--load--加载--读取的概念
res = yaml.load(fo,Loader=yaml.FullLoader)
resList = [] #存放结果---[(),()]
for one in res:
resList.append((json.dumps(one['data']),json.dumps(one['reps'])))
return resList
print(get_yaml_data())
yaml文件:特殊字符\n,\t需要加引号,反斜杠,转义符什么的需要加引号,其他的不用
yaml文件,代码后面跟的注释需要加空格 如:xxxxxx #这是注释 不然会报错
七:多组yaml数据之间使用___三个下划线分开起来 如下
name: tom age: 20 --- - 10 - 20 - 30 ---
十:读取多个yaml数据使用yaml.load_all,如果yaml文件里只有一个数据使用yaml.load
def get_yamls(): #读取多个yaml数据,可以读很多组数据,用---分隔的yaml数据
fileobject = open(YamlDir, 'r', encoding='utf-8')
res = yaml.load_all(fileobject.read(),Loader=yaml.FullLoader) #返回迭代器:<generator object load_all at 0x000001F38C51BE08>
for one in res: #返回的这个代器可以使用list转成列表
print(one)
43:项目总结
test_case 里面有两个测试模块:test_login.py登录 test_lesson.py课程 整个test_case 跑起来有两种方法: 一般我们不会在pycham里面跑整个项目 方案一:pytest命令行去跑,cmd切到test_case目录里面: 输入pytest -sq (不打报告不干其他,只运行,运行所有的,运行cmd当前目录文件下的所有的测试用例,自动识别带test开头的模块) 方案二:ywt_api_run_浏览器模式.bat.bat批处理文件运行 ywt_api_run_浏览器模式.bat 文件 bat批处理文件(可以一键打开浏览器的)
@echo off
echo ywt自动化运行准备开始...... #基本的输出描述
@echo on
del /f /s /q G:\xxx\Python\Demo\teach_sq\report\tmp\*.json #删除项目中不需要的数据
del /f /s /q G:\xxx\Python\Demo\teach_sq\report\tmp\*.jpg
del /f /s /q G:\xxx\Python\Demo\teach_sq\report\report
@echo off
echo 环境文件删除工作完成,开始运行脚本......
@echo on
G:
cd G:/SongQin/Python/Demo/teach_sq/test_case #切换到testcase路径,理解里面pytest执行代码,生成allure报告
pytest -sq --alluredir=../report/tmp
allure serve ../report/tmp
@echo off
echo 接口自动化运行成功
pause
通过:ywt_api_run_浏览器模式.bat 文件一键执行脚本,生成报告(真正意义的自动化,本机执行)
44:allure报告优化
allure报告优化,按模块做个分层
报告做漂亮需要做allure标签:报告分层(引入allure标签,allure标签分层)
一:每个接口方法都加个注释(描述) ---报告里面都会体现
'''登录接口''',报告里面会看到这个注释(描述)
方法一:函数注释
方法二:写一个描述的单词:@allure.description("爱看书的急啊卡的金克拉") #接口信息描述
二:登录做成一个模块,大的标签---大的层
1层标签:@allure.feature("登录模块") ,大标签,对类来操作
2层标签:@allure.story("登录接口") , 对接口方法操作
3层标签:@allure.title("登录接口用例") ,对接口用例操作,针对每个用例
三:allure报告一些其他的描述,
1:allure报告上展示环境等属性,allure报告运行环境(报告怎么测试的,环境怎么样,报告描述,概要,描述整个项目的基本情况)
在report的tmp文件夹加一个environment.properties文件
teach_sq
report
tmp
environment.properties ----环境属性文件,配置文件,给报告用的,一般自己手写
tem文件夹里面放个:environment.properties文件,文件里面可以写这个项目环境的基本描述:如下写
python.version=3.6.5
projectUrl=127.0.0.1/login
Browser=FireFox_77.6
environment.properties 配置文件
那么版本运行的时候allure报告首页的:ENVIRONMENT栏会有相应的描述如下: ENVIRONMENT projectUrl 127.0.0.1/login python.version 3.6.5 Browser FireFox_77.6 2:allure报告的趋势,本地是没有的,pytest里面做history是有的,以前临时文件的都不能删除,留着 一般需要和jinkins结合来做的,jinkins自己会做,会有构建历史的,jikins有个插件allure,里面构建完了后会把allure每次运行结果放到趋势里面去 一:本地的:localhistory(tmp文件不能删除,移动到history里面去然后导入进来,) 自己学习
45:接口自动化代码写道后期需要加的三个步骤
1:yaml设计登录, 2:allure报告优化,做标签 3:xxx.bat批处理文件一键执行跑起来(windows是bat mac是:sh) jinkins最终用的就是命令行,怎么命令行启动,起各种服务,都是.命令行运行(需要掌握) 批处理文件执行整个自动化:环境清除+执行代码+生成allure报告 不是点run跑
46:mock技术的简介 mock(模拟技术)
一:什么是mock? 模拟后端代码,调试脚本,提高测试前置优势,测试工作前置先做,提高效率,让测试工程师尽早进入测试 在软件测试过程中,对于一些不容易构造、获取的对象,用一个虚拟的对象来替代它,以达到相同的效果,这个虚拟的对象就是Mock。 在前后端分离项目中,当后端工程师还没有完成接口开发的时候,前端开发工程师利用Mock技术, 自 己用mock技术先调用一个虚拟的接口,模拟接口返回的数据,来完成前端页面的开发。 其实,接口测试和前端开发有一个共同点,就是都需要用到后端工程师提供的接口。所以,当我们做接 口测试的时候, 如果后端某些接口还不成熟、所依赖的接口不稳定或者所依赖的接口为第三方接口、构造依赖的接口数据太复杂等问题时, 我们可以用mock的方式先虚拟这些接口返回来代替。提高工作效 率。 从底层到上层都有模拟技术:c语言调算法(模拟器) 一开始开发里面用mock的,后面引入到测试里面的 在前后端分离项目中,api文档定下来的,各自开发,现在为了加快测试速度,不等前后端开发完,测试就要介入,后端没有开发完,接口无法进行测试, 使用模拟技术,调试自动化脚本,提前介入自动化测试,加快进度。 api文档定下来:通过技术手段模拟后台(发什么回什么),调试自动化脚本,做功能。 二:怎么实现mock(技术很多,大的概念,各种语言都可以实现)只要能把后台逻辑模拟出来的系统就是mock技术 1:python,java 写后端 2:python+flask/django编程 写一个简易的系统(请求响应后台服务,不需要前端)需要编码能力 3:现成的mock平台 moco框架(java包) 所有的配置使用json文件(一般采用第三种,不需要代码编程技术,只要改json配置文件 三:模拟技术不同的命名 mock技术 挡板技术 ---很大的概念,挡板是mock里面的一种 线下系统 沙河 沙箱测试 四:mock技术是敏捷开发的一个体现(测试提前介入,推动项目进度) 五:moco介绍 (mock技术实现方法,很多) 实现mock的技术很多,这些技术中,可以分为两类,mock数据和mock服务: mock数据:即 mock 一个对象,写入一些预期的值,通过它进行自己想要的测试。常见的有: EasyMock、Mockito 、WireMock、JMockit。主要适用于单元测试。 mock 服务:即mock 一个 sever,构造一个依赖的服务并给予他预期的服务返回值,适用范围 广,更加适合集成测试。如 moco框架。 Moco是类似一个 Mock 的工具框架,一个简单搭建模拟服务器的程序库/工具,下载就是一个JAR包。 有如下特点: 只需要简单的配置 request、response 等即可满足要求 支持 http、https、socket 协议,可以说是非常的灵活性 支持在 request 中设置 Headers , Cookies , StatusCode 等 对 GET、POST、PUT、DELETE 等请求方式都支持 无需环境配置,有 Java 环境即可 修改配置后,立刻生效。只需要维护接口,也就是契约即可 (边改边生效) 支持多种数据格式,如 JSON、Text、XML、File 等 可与其他工具集成,如 Junit、Maven等 六: moco环境搭建 1:我们可以直接去github上获取moco的jar包,当前版本是:V1.1.0。 地址:https://github.com/dreamhead/moco 这里展示了关于moco的介绍和源码,我们可以点击箭头 处直接下载它的jar包 2:java -jar moco-runner-1.1.0-standalone.jar http -p 9999 -c test.json cmd输入前面命令,起java进程,这是开启的http协议模拟 java -jar moco-runner-1.1.0-standalone.jar https -p 9999 -c test.json 这样也可以模拟https协调 jar包的名称可根据自己下载的jar包版本来写 http代表这个模拟的是http请求 -p 9090定义是端口号 -c test.json 是我们编辑的那个json文件名(构建模拟请求需要.json文件构建,写接口请求什么样子,响应什么样子,只需要修改这个就行)
七:test.json编辑文本里面写的内容如下
{
"description":"demo1=约定URI", ----接口的描述
"request":{ ----request表示request请求的组建
"uri":"/ywt_sq"
},
"response":{ ----response响应的组建
"text":"Hello,ywt"
}
},
三部分:接口的描述,request请求的组建,response响应的组建 mock下面4种格式都支持: params get方法 data json file forms 表单
47:支付电商+异步接口(结合mock技术)
现在很多行业都会使用调用第三方的接口,了解支付接口有什么参数,(查看支付宝开源的对外接口)
vip对接微信接口,告诉学员什么时候上课,什么时候签到,推送信息 vip对接微信接口,第三方接口一般都是会开放的,对接微信公众号的接口
这种第三方接口都是现成的能够使用的,短信接口,微信和支付宝的接口都是现成提供使用的,不需要测试
测试支付接口:支付沙箱(就是测试环境,里面钱都是自定的,一般的第三方支付平台,支付宝的接口,
京东对应的的京东接口都是有沙箱环境的,沙盒,沙箱就是个测试环境)
项目里面可以调用这个环境,模拟扣款付款整个流程--不需要真金白银去测试,
沙箱环境是第三方支付平台推出的,除了跟真实账户去绑定,其他功能都是一模一样的,行业认可的真实度的
支付宝推出支付宝的沙箱环境,电商和第三方调用支付接口的都需要知道什么是沙箱,
也能自己从支付宝或者第三方平台库能找到整个环境,现成的
一:支付接口简易接口,
路径
方式
请求参数
头
body
小额的金额支付真实环境测试的,最后调试会看一下,大额的金额支付一般都是沙箱测试
沙箱做完之后基本没什么问题,第三方支持的,除了额度其他基本都一样
二:支付接口的mock模拟:.son文件内容如下:
{
"description":"支付接口-mock", 描述
"request":{
"method":"POST", post请求
"uri":"/trade/purchase", 路径
"headers":{ 头
"Content-Type":"application/json"
},
"json":{ 请求体
"out_trade_no":"20150320010101001",
"auth_code":"28763443825664394",
"buyer_id":"2088202954065786",
"seller_id":"2088102146225135",
"subject":"Iphone6",
"total_amount":"88.88"
}
},
"response":{ 响应数据
"headers":{ 响应头
"Content-Type":"application/json"
},
"status":200, 响应状态
"json":{ json为响应体数据
"code":"40004",
"msg":"Business Failed",
"sub_code":"ACQ.TRADE_HAS_SUCCESS",
"sub_msg":"交易已被支付",
"trade_no":"2013112011001004330000121536",
"out_trade_no":"6823789339978248"
}
}
}
这就是一个支付的,实际业务层是支付,但是接口用的时候跟我们差不多
请求代码:
#time:2020/11/3
import requests
url="http://127.0.0.1:9999/trade/purchase"
headers={"Content-Type":"application/json"}
data={"out_trade_no":"20150320010101001",
"auth_code":"28763443825664394",
"buyer_id":"2088202954065786",
"seller_id":"2088102146225135",
"subject":"Iphone6",
"total_amount":"88.88"
}
response=requests.post(url,headers=headers,json=data)
print(response.json())
48:同步接口和异步接口(教官系统里面的接口都是同步接口)
同步接口:我给你东西,就等你东西,发请求给你,就等你响应就行ok了,不来就超时或者一直等着,请求等你响应,你不来我就等着不动了,你不动我不动 这样就很尴尬,银行办事情,前面需要拿号,号没拿到办不了事情,这是同步的,拿号操作后才能往后面走,否则走不了 异步接口: 增加商品:增加归增加,增加完之后我立马增加请求发出去之后, 服务端立马回一个id号(跟踪userid号)放在队列里面做的,告诉你我已经再队列里处理你的请求 后面你来查就行了,哪怕中间很慢很慢没关系,它来处理,等会来查就行了, 银行办事:三个窗口,第一个窗口办完之后给凭证,然后告诉我看到这里面好了就来拿东西, 体检:很多项目,验完血之后给个单子,让你等多少时间来拿化验报告就行, 接着做下面的项目 这就是异步 (工作人员化验你的血液),我们正常去体检其他项目,等做完之后看到结果出来去拿结果就行了,定时让朋友去问问定时查询体检动作--不等 很重要:现在教官系统都是同步的,发一个请求等一个,如果请求没有响应会发现我们一直等着那边不会释放,请求没有结束是不会释放的,采取异步操作 理解异步和同步操作 异步一般两个步骤:一个操作,一个是get的 1:请求接口 2:get接口:get结果-查result结果
49:mock模拟技术+异步接口代码:
订单的例子: 先创建订单,订单有没有创建成功需要等待后台服务响应完之后才能知道结果, 先创建订单接口,创建完之后后面又有一个获取订单接口 两步:一步是获取订单接口,一步是我们创建订单接口(两个操作) 异步的,我增加订单归增加,增加完之后后台给我返回一个id号,追踪的id号,后面查就行, 查到了就是增加订单成功,不需要等订单增加的结果,保证接口定时查询就行---这就是所谓的异步操作 工作里面很多---高性能,体验度好的都是异步接口,不是同步的 异步接口创建成功会有响应:响应并不是一个是否成功,异步一般不会直接返回结果的, 只告诉你消息我已经放在队列里面处理了,告诉你队列号,或者处理的id号,你等结果就行 以后根据id等号码查询就知道状态是否完成
一:mock的json文件内容:
[
{
"description":"创建订单接口-mock",
"request":{
"method":"POST",
"uri":"/api/order/create/",
"headers":{
"Content-Type":"application/json"
},
"json":{
"user_id": "sq123456",
"good_id": "20200818",
"num": 1,
"amount": 200.6
}
},
"response":{
"headers":{
"Content-Type":"application/json"
},
"status":200,
"json":{
"order_id": "6666"
}
}
},
{
"description":"查询订单接口-mock",
"request":{
"method":"GET",
"uri":"/api/order/get_result/", #查询不是json,不写headers,不写就是表单,get没法用json去做,不好做,去掉headers,get请求的params不能写成json
"queries":{
"order_id": "6666"
}
},
"response":{
"headers":{
"Content-Type":"application/json"
},
"status":200,
"json":{
"user_id": "sq123456",
"good_id": "20200818",
"num": 1,
"amount": 200.6
}
}
}
]
二:mock技术+异步接口实例代码:
Host='http://127.0.0.1:9999'
import requests
import time
#异步接口(数据和结果不在一个接口里面,分开几个接口来做的,这个接口只表明提交成功的,接口到底有没有成功需要看后面)
#1增加订单操作
def create_order():
url=f'{Host}/api/order/create/'
payload={
"user_id": "sq123456",
"good_id": "20200818",
"num": 1,
"amount": 200.6
}
reps=requests.post(url,json=payload) #json传递参数默认带"Content-Type":"application/json"
return reps.json() #立马返回一个追踪的操作id号--给后续的查询使用的,
2:查询订单接口,异步接口,只做查询功能,把id的订单号传进去查询
查询和创建订单接口不同,异步,增加完之后拿到id号,后面定时查询就行,其他不需要管
异步接口肯定不是一步,2步或者两步以上,正常的也就2.3步,看接口复杂程度,一个就是同步接口,发接口等结果这种就是同步的
必须等结果,不等没有结果
异步概念:有些接口很慢的。创建一个订单需要很长时间响应,同步体验感很差,等半天--异步性能高
办业务点击提交时候立即出现您的业务已经提交然后两分钟之后过来显示,很多软件这样搞得
比如贷款申请房产申请就是这么做的,出结果的这几分钟用户可以进行其他操作,到时候来查询结果就行
比如支付宝转账,
def get_order_result(orderid,timeout=20,interval=1): #超时时间:timeout=10,轮巡周期:interval=1 1s查询一次
#这是个机制,不可能查一天,需要定时查询,隔多少时间查一次,然后多少时间没有查到就认为结果失败了 轮巡思路
'''查询订单接口,查询结果,一般有个超时机制,不是无限等待'''
#构建查询的接口代码,查询接口并不是立马就回结果,需要轮询,需要一直发,隔多少查一次,查到结束
url=f"{Host}/api/order/get_result/"
payload={
"order_id": orderid #做成形参,查某个写某个,方法就能通用了
}
stattTime=time.time() #开始时间
endTime=stattTime+timeout #结束时间等于开始时间+超时时间,时间到了就要停止
cnt=1 #轮询的次数
#轮巡操作--是需要定时发送查询请求的,
while time.time() < endTime: #如果当前时间小于结束时间,一直轮询
reps=requests.get(url,params=payload)
time.sleep(interval) #发了之后需要查,当前时间小于结束时间的时候一种查询,发一次休眠个轮询时间,
#发一次隔多少时间发一次,定时轮询,定时查询
print(f'当前第{cnt}次查询')
cnt=cnt+1
if reps.json(): #判断是否有数据返回,如果有返回值的话,停止轮询,查到就退出.如果整个时间没有查到,
break
else: #如果时间到了都没有查询到,返回空的数据
return None
return reps.text
上面就是一个简单异步接口操作,创建得到一个订单id号,但是查询里面设置查询周期和超时机制 理论就是这样的
时间没到就定时查询,时间到了就退出来,wihle else操作,while条件运行完了没有return话,那么就会到else里面return None空
wihle else:如果while超时还是没有返回值,那么就回进入else代码块,return None,后面的return reps.text不会执行
最后不管怎么样把结果返回去return reps.text 怎么都有值的
轮询有结果才会退出,没有不能退出,时间没到不能返回为空,直到超时才结束
要求查询10s,10s内一种查询,每隔ls查询一次, 10s过了后
工作很常见的,直到所有的时间走完所有timeout时间结束之后我们才决定不查,只要时间没到我们一种查,每隔1s查一次,查到结果结束
思路分析:直到怎么封装这种异步接口
这种场景在我们公司里面特别多,
异步接口:类似体检,验血,验血完后,给一个小票,编号,拿到编号不需要你在这边等,去检查其他体检项目
可以让朋友看一下验血好了没有,当id号完成有报告了再回来取结果, 多次查询,每做完一个项目看一次,轮询查结果
不影响工作,正常操作就行,但是保证查询接口一直在跑在查询,省的阻塞不动
同步接口:一手交钱一手交货,给钱了不给货,死等不动,同步的
订单和申请的操作一般很多都素异步接口,需要等的
如何模拟这种情况:两个接口
1:创建订单接口,整个服务端采用mock技术来做,mock技术做的时候创建好mock,发送请求,得到追踪的id号
增加订单完成后可以干其他的事情了,但是我后面可以轮询取查询,轮询周期自己设置一下,性能好很多
2:get_order_result接口去查询订单结果,轮询异步操作封装函数特点:1:查多少时间timeout 2:轮询周期interval
多少时间轮询一次
构建查询请求url,payload,stattTime开始时间,endTime结束时间根据当前时间+超时时间
然后里面做个循环while time.time() < endTime:然后每次循环都去requests发出请求,然后轮询1s(形参对外开放,可以修改)
查询周期特点:如果查询周期范围内一旦有结果,就结束循环,break,然后 return reps.text查询结果
如果到超时时间也没有查询到,while循环已经退出了,这时候没有结果的,返回空,
可以做断言assert断言返回结果---pytest判别响应的结果,没有区别--查询结果需要轮询操作--根据接口本身的特性来
设置合理的周期和频率,
模板
if __name__ == '__main__':
#1:创建订单--获取id
orId=create_order()["order_id"]
print(get_order_result(orId, timeout=20))
四:mock 技术的局限性: 自动化需要环境初始化和环境清除,mock做不了,mock只能针对调试接口逻辑比较合适,做不了接口的关联性,做不了后台服务, 比如要清除添加的设备,或者添加设备初始化操作搞不定 五:token通过接口获取的,不算异步,死等token值, 异步:第一个请求立马会有数据回给你,但是这个数据不是我们想要的数据,叫异步, 发的一个临时的号码牌,去干其他的操作,等数据这个对应的队列 结束完之后会返回数据,查这个id号- 获取token,cookie都是同步的,在一些业务逻辑里面会有一些异步的操作 不是关联就是异步的,不仅仅是是关联,业务操作上的问题
50:基于复用的二次封装:requests与log比翼双飞,基于复用的二次封装,
接口测试失败了,是测试的问题还是开发的问题 请求报错了,怎么去排查,谁的问题, 代码测试:必须保证自己的代码没有bug
my_log.py
#日志处理,日志库
import logging
import os
log_path='.\log\log.log'
def create_log(log_path):
logger=logging.getLogger(os.path.split(log_path)[1]) #创建一个日志对象
#os.path.split(log_path)[1]指定日志名字
logger.setLevel(logging.INFO) #设置日志记录级别 info及以上的级别才会记录
fh = logging.FileHandler(log_path,encoding='utf-8') #打开指定的文件,并将其作为日志记录的位置---日志记录流
#记录日志文件的位置 一般做配置文件
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
#定义日志输出格式 设置asctime时间
#name 文件名 日志级别levelname
fh.setFormatter(formatter) #当定义的格式和日志流绑定生效
logger.addHandler(fh) #往logger中对象添加输出方式
return logger #最终操作日志通过logger对象
apiLog=create_log(r'.\log\api.log') #创建一个日志对象apiLog
def decoratelog(func): #传函数名称
'''日志装饰器,func是被装饰函数的函数名,函数功能是'''
def wrapper(*args,**kwargs):
logger=create_log(log_path)
try:
func(*args,**kwargs)
except Exception as e:
#记录异常
err=f"异常发送在:{func.__name__},内容:{e}" #查看异常发生的函数名字
logger.exception(err) #特别适合记录异常信息的一个方法
return wrapper
if __name__ == '__main__':
log_path = '.\log\log.log'
lo=create_log(log_path)
lo.info('这一行是测试日志')
my_requests
import requests
from day1.my_log import apiLog #导入apiLog对象
from day1.my_log import decoratelog
#基于接口请求复用的一个二次封装
class myRequests: #重写requests,
def __init__(self,url):
self.session=requests.session() #session这个类可以帮忙记住一些持久性的信息:cookie,连接池,配置
#可以记录每一次接口请求的cookie
self.url=url #path:url请求路径
self.timeout=10 #超时时间
self.errorMsg="" #错误消息,初始化空的字符串
@decoratelog #装饰器,当尝试调用被装饰函数的时候,如果发生异常,捕捉异常并记录下来
def post(self, bodydata=None, bodyjson=None, **kwargs):
#针对原始post的一个二次封装,重写post函数
response=''
try:
response=self.session.post(self.url, data=bodydata, json=bodyjson, timeout=self.timeout,**kwargs)
apiLog.info('请求参数:%s'% bodydata if bodydata else bodyjson)
#三元运算符 如果bodydata为真就填写bodydata,如果bodydata为假,走bodyjson
apiLog.info('请求结果:%s'% response.text) #记录请求结果
except Exception as e: #报错捕捉e错误信息
self.errorMsg=str(e)
raise Exception(f'http请求异常,异常信息\n{self.errorMsg}',)
return response
if __name__ == '__main__':
r=myRequests('https://api.binstd.com/shouji/query')
payload = {
"appkey":"your_appkey_here",
"shouji":"18163606916"
}
r.post(bodydata=payload)