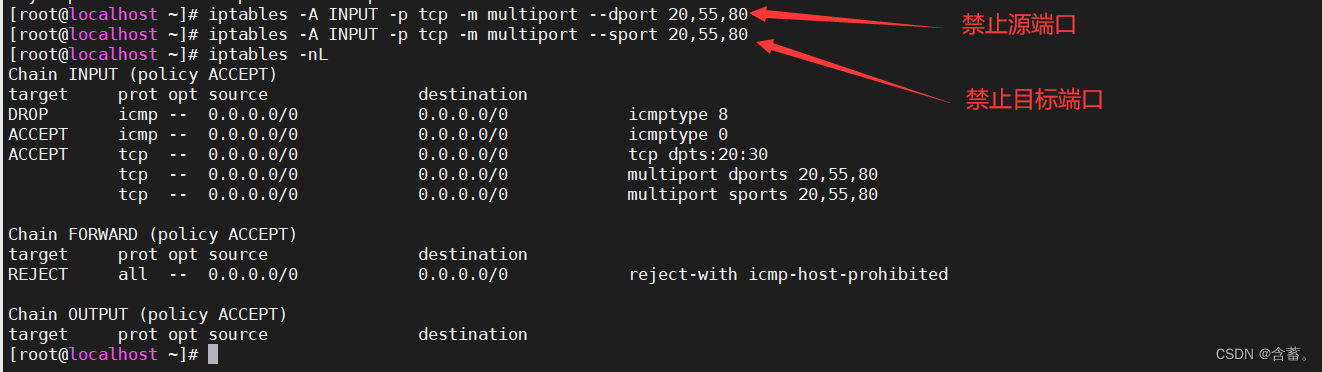
MMDetection 3D入门

文章目录
- MMDetection 3D入门
- 介绍
- 架构
- 模块
- 核心模块与相关组件
- 公共基础模块
- 依赖
- 安装
- 最佳实践
- 验证安装
- 测试数据
- create_data.py
- 修改数据目录
- train.py
- 整体流程
- 命令行参数
- 配置文件中为什么传入参数是 dict
- Runner函数中参数含义
- 结合图示来理清其中数据的流向与格式约定
- dataloader、model 和 evaluator 之间的数据格式约定
- 预处理模块及数据流变化
- train pipeline
- CenterPoint model
- 从注册表中生成model实例过程
- 生成的model结构体
- 生成epoch文件
- 欢迎关注公众号【三戒纪元】
介绍
最大的感受就是 MMDetection 3D 太强大了。一个强大的框架,融合了多种模型和训练方法,使用起来也很方便。
MMEngine 是一个基于 PyTorch 实现的,用于训练深度学习模型的基础库,支持在 Linux、Windows、macOS 上运行。它具有如下三个特性:
- 通用且强大的执行器:
- 支持用少量代码训练不同的任务,例如仅使用 80 行代码就可以训练 ImageNet(原始 PyTorch 示例需要 400 行)。
- 轻松兼容流行的算法库(如 TIMM、TorchVision 和 Detectron2)中的模型。
- 接口统一的开放架构:
- 使用统一的接口处理不同的算法任务,例如,实现一个方法并应用于所有的兼容性模型。
- 上下游的对接更加统一便捷,在为上层算法库提供统一抽象的同时,支持多种后端设备。目前 MMEngine 支持 Nvidia CUDA、Mac MPS、AMD、MLU 等设备进行模型训练。
- 可定制的训练流程:
- 定义了“乐高”式的训练流程。
- 提供了丰富的组件和策略。
- 使用不同等级的 API 控制训练过程。
架构
MEngine 在 OpenMMLab 2.0 中的层次。MMEngine 实现了 OpenMMLab 算法库的新一代训练架构,为 OpenMMLab 中的 30 多个算法库提供了统一的执行基座。其核心组件包含训练引擎、评测引擎和模块管理等。

模块
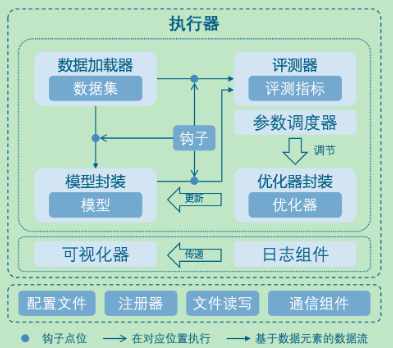
MMEngine 将训练过程中涉及的组件和它们的关系进行了抽象,如上图所示。不同算法库中的同类型组件具有相同的接口定义。
核心模块与相关组件
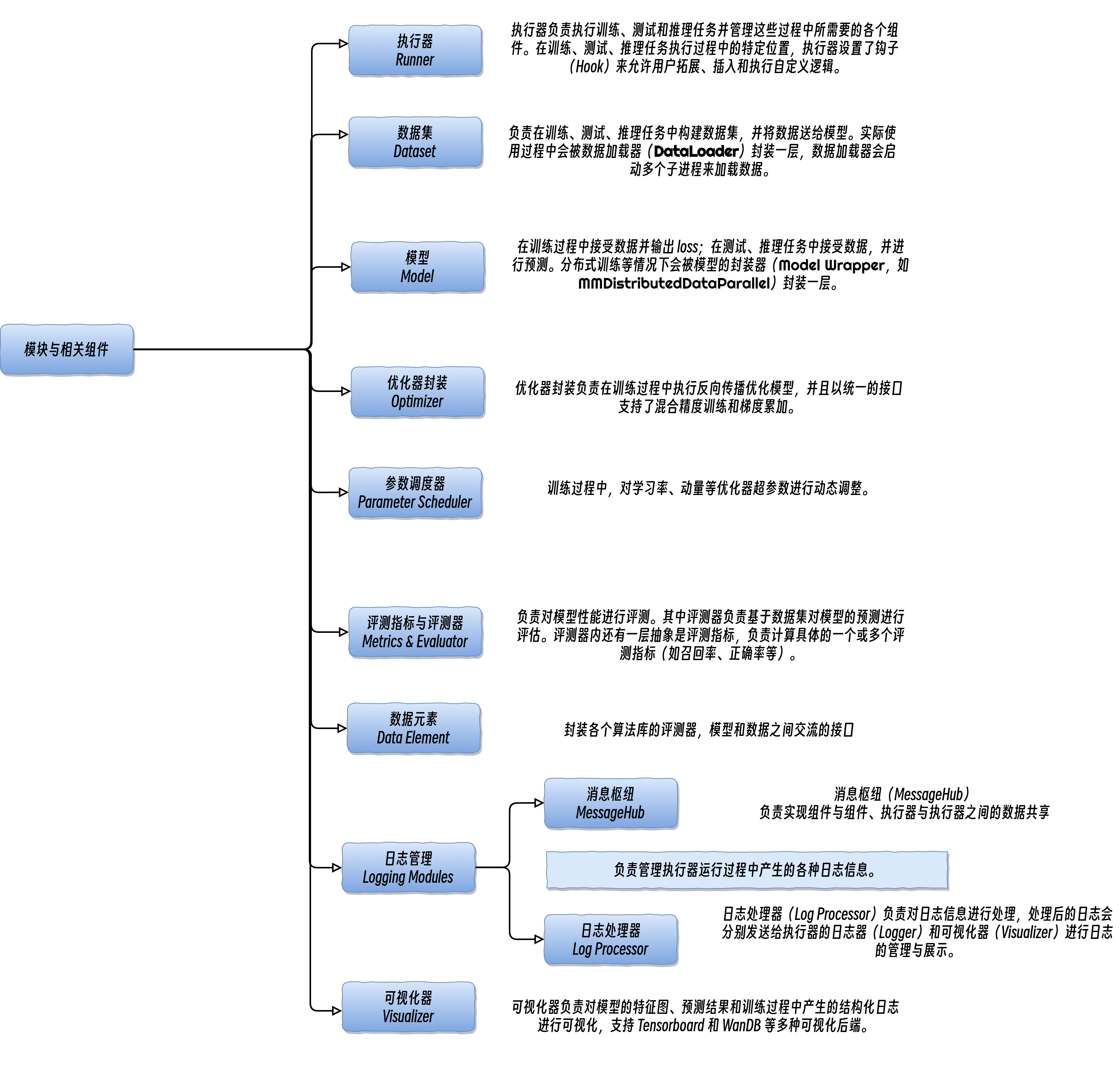
训练引擎的核心模块是执行器(Runner)。执行器负责执行训练、测试和推理任务并管理这些过程中所需要的各个组件。在训练、测试、推理任务执行过程中的特定位置,执行器设置了钩子(Hook)来允许用户拓展、插入和执行自定义逻辑。执行器主要调用如下组件来完成训练和推理过程中的循环:
- 数据集(Dataset):负责在训练、测试、推理任务中构建数据集,并将数据送给模型。实际使用过程中会被数据加载器(DataLoader)封装一层,数据加载器会启动多个子进程来加载数据。
- 模型(Model):在训练过程中接受数据并输出 loss;在测试、推理任务中接受数据,并进行预测。分布式训练等情况下会被模型的封装器(Model Wrapper,如
MMDistributedDataParallel)封装一层。 - 优化器封装(Optimizer):优化器封装负责在训练过程中执行反向传播优化模型,并且以统一的接口支持了混合精度训练和梯度累加。
- 参数调度器(Parameter Scheduler):训练过程中,对学习率、动量等优化器超参数进行动态调整。
公共基础模块
MMEngine 中还实现了各种算法模型执行过程中需要用到的公共基础模块,包括
- 配置类(Config):在 OpenMMLab 算法库中,用户可以通过编写 config 来配置训练、测试过程以及相关的组件。
- 注册器(Registry):负责管理算法库中具有相同功能的模块。MMEngine 根据对算法库模块的抽象,定义了一套根注册器,算法库中的注册器可以继承自这套根注册器,实现模块的跨算法库调用。
- 文件读写(File I/O):为各个模块的文件读写提供了统一的接口,以统一的形式支持了多种文件读写后端和多种文件格式,并具备扩展性。
- 分布式通信原语(Distributed Communication Primitives):负责在程序分布式运行过程中不同进程间的通信。这套接口屏蔽了分布式和非分布式环境的区别,同时也自动处理了数据的设备和通信后端。
- 其他工具(Utils):还有一些工具性的模块,如 ManagerMixin,它实现了一种全局变量的创建和获取方式,执行器内很多全局可见对象的基类就是 ManagerMixin。
依赖
MMDetection3D 可以安装在 Linux, MacOS, (实验性支持 Windows) 的平台上,它具体需要下列安装包:
- Python 3.6+
- PyTorch 1.3+
- CUDA 9.2+ (如果你从源码编译 PyTorch, CUDA 9.0 也是兼容的。)
- GCC 5+
- MMCV
安装
最佳实践
步骤 0. 使用 MIM 安装 MMEngine,MMCV 和 MMDetection。
pip install -U openmim
mim install mmengine
mim install 'mmcv>=2.0.0rc4'
mim install 'mmdet>=3.0.0'
注意:在 MMCV-v2.x 中,mmcv-full 改名为 mmcv,如果您想安装不包含 CUDA 算子的 mmcv,您可以使用 mim install "mmcv-lite>=2.0.0rc4" 安装精简版。
步骤 1. 安装 MMDetection3D。
方案 a:如果您开发并直接运行 mmdet3d,从源码安装它:
git clone https://github.com/open-mmlab/mmdetection3d.git -b dev-1.x
# "-b dev-1.x" 表示切换到 `dev-1.x` 分支。
cd mmdetection3d
pip install -v -e .
# "-v" 指详细说明,或更多的输出
# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。
方案 b:如果您将 mmdet3d 作为依赖或第三方 Python 包使用,使用 MIM 安装:
mim install "mmdet3d>=1.1.0rc0"
验证安装
为了验证 MMDetection3D 是否安装正确,我们提供了一些示例代码来执行模型推理。
步骤 1. 我们需要下载配置文件和模型权重文件。
mim download mmdet3d --config pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car --dest .
下载将需要几秒钟或更长时间,这取决于您的网络环境。完成后,您会在当前文件夹中发现两个文件 pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py 和 hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth。
步骤 2. 推理验证。
方案 a:如果您从源码安装 MMDetection3D,那么直接运行以下命令进行验证:
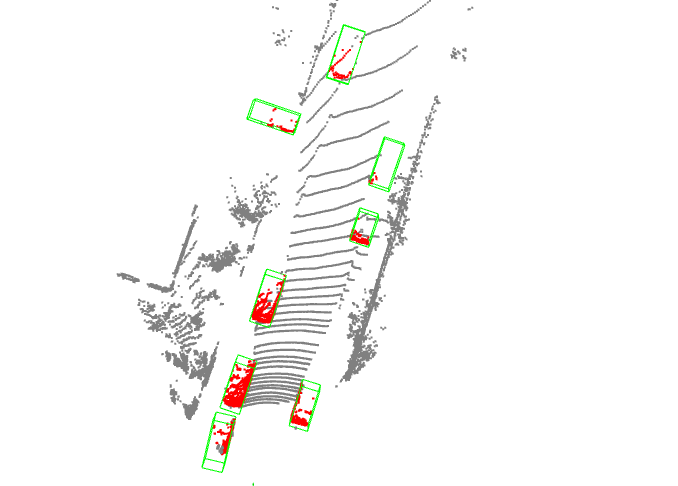
python demo/pcd_demo.py demo/data/kitti/000008.bin pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py hv_pointpillars_secfpn_6x8_160e_kitti-3d-car_20220331_134606-d42d15ed.pth --show
您会看到一个带有点云的可视化界面,其中包含有在汽车上绘制的检测框。
步骤 3. 导入头文件验证
(mmdetection3d_randy) qiancj@qiancj-HP-ZBook-G8:~/codes/download/mmdetection3d$ python
Python 3.8.16 (default, Mar 2 2023, 03:21:46)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import mmdet3d
>>> print(mmdet3d.__version__)
1.1.0
>>> quit()
测试数据
.
├── 1212_pkl
│ ├── infos_test_rela.pkl
│ └── infos_val_rela.pkl
├── data
└── test
├── 1619514624.158707857.bin
├── 1619514665.967276335.bin
├── 1619515577.366736174.bin
├── 1619515927.231983900.bin
├── 1619516334.708499432.bin
└── 1636101084.089.bin
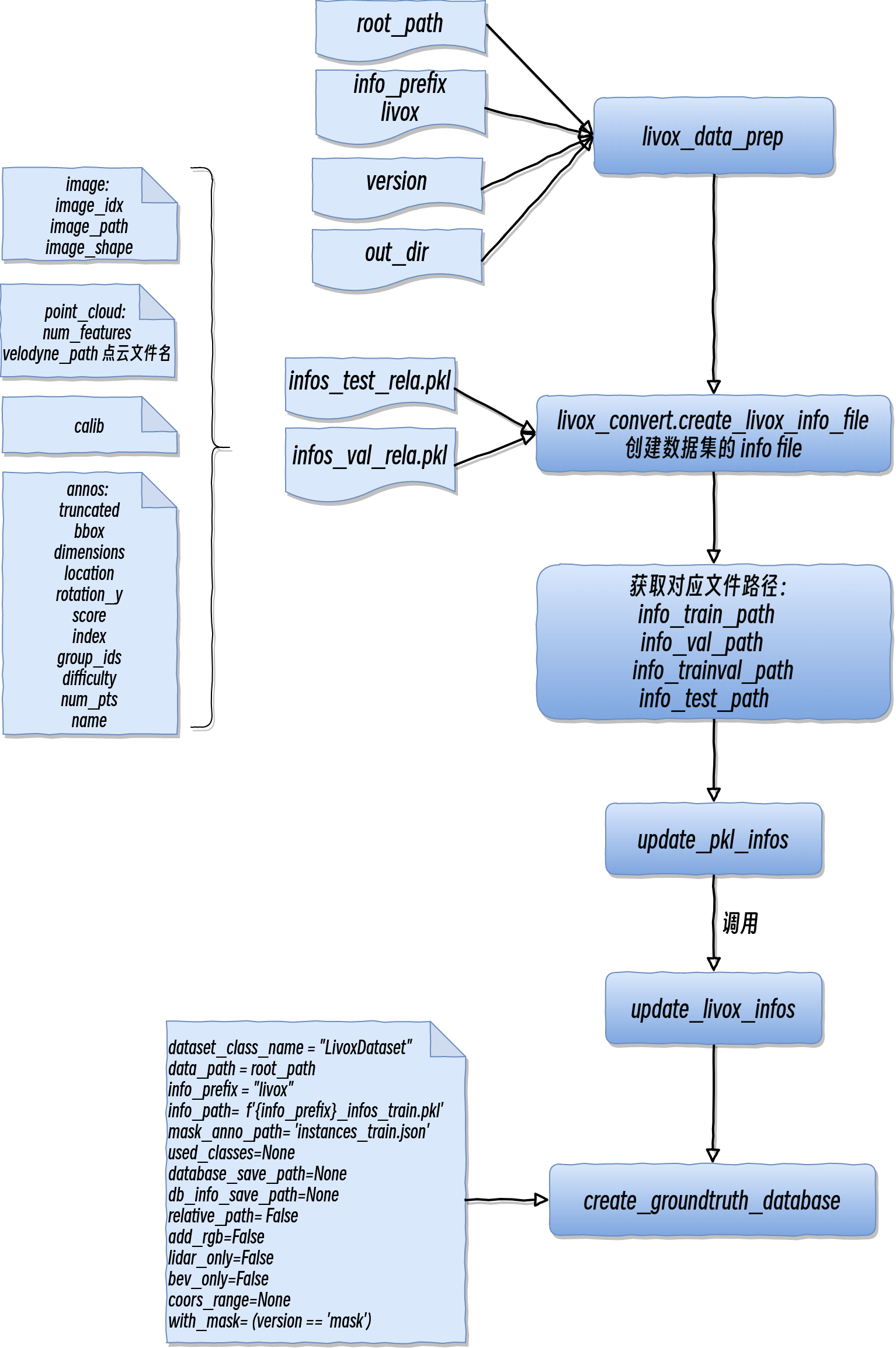
create_data.py
将已有的数据,整合成训练所需要的数据格式
命令行参数
python /home/qiancj/codes/mmdet3d_lidar/tools/create_data.py livox --root-path /home/qiancj/Documents/data/centerpoint_demo_data/l3_data/data --out-dir /home/qiancj/Documents/data/centerpoint_demo_data/l3_data/data --extra-tag livox
参数:livox --root-path /home/qiancj/Documents/data/centerpoint_demo_data/l3_data/data --out-dir /home/qiancj/Documents/data/centerpoint_demo_data/l3_data/data --extra-tag livox
def livox_data_prep(root_path, info_prefix, version, out_dir)
| 入参 | 含义 |
|---|---|
| root_path (str) | Path of dataset root |
| info_prefix (str) | The prefix of info filenames |
| version (str) | Dataset version |
| out_dir (str) | Output directory of the groundtruth database info |
| with_plane (bool, optional) | Whether to use plane information,Default: False |
修改数据目录
codes/mmdet3d_20220512/mmdetection3d/tools/dataset_converters/fawlidar_converter.py
文件中修改:
pkl_root = "/home/qiancj/Documents/data/centerpoint_demo_data/l3_data/1212_pkl"
train_anno = os.path.join(pkl_root, "infos_test_rela.pkl")
val_anno = os.path.join(pkl_root, "infos_val_rela.pkl")
pkl_root = "/home/carolliu/data/M1_data/train/new/"
train_anno = os.path.join(pkl_root, "infos_train_100t.pkl")
val_anno = os.path.join(pkl_root, "infos_train_100t.pkl")
// 生成test pkl
filename = save_path / f'{pkl_prefix}_infos_test.pkl'
print(f'FAWLiDAR info test file is saved to {filename}')
mmengine.dump(fawlidar_infos_test, filename)
生成文件:
fawlidar_infos_test.pkl
fawlidar_infos_train.pkl
fawlidar_infos_trainval.pkl
fawlidar_infos_val.pkl
train.py
整体流程
命令行参数
python /home/qiancj/codes/mmdet3d_lidar/tools/train.py /home/qiancj/codes/mmdet3d_lidar/configs/centerpoint/centerpoint_pillar02_second_secfpn_8xb4-cyclic-20e_livox.py
参数:/home/qiancj/codes/mmdet3d_lidar/configs/centerpoint/centerpoint_pillar02_second_secfpn_8xb4-cyclic-20e_livox.py
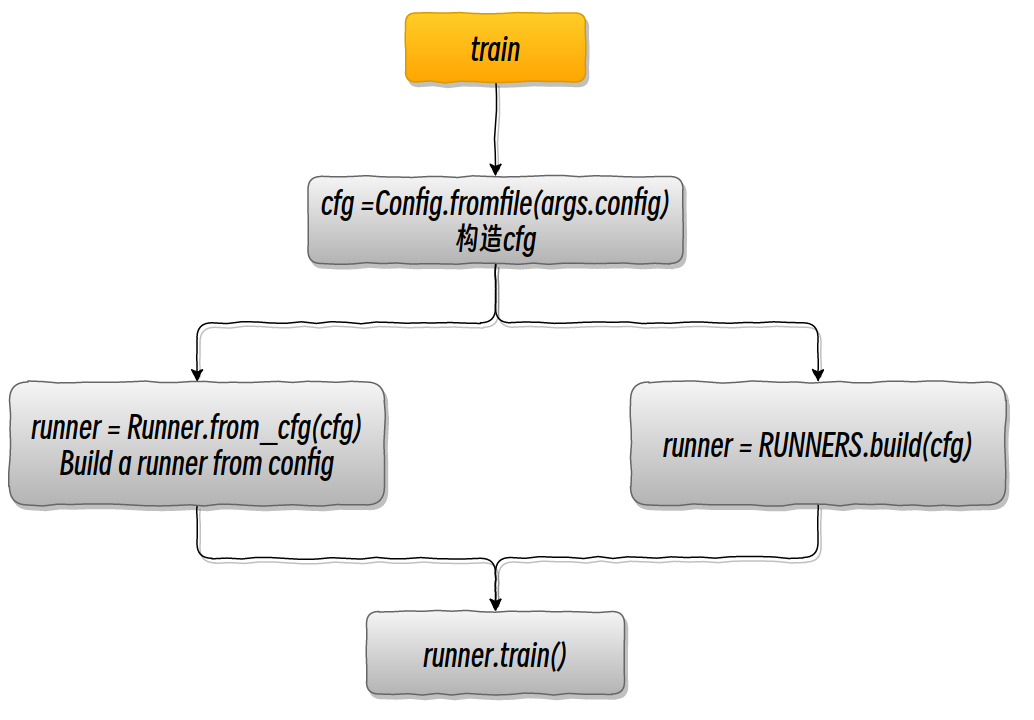
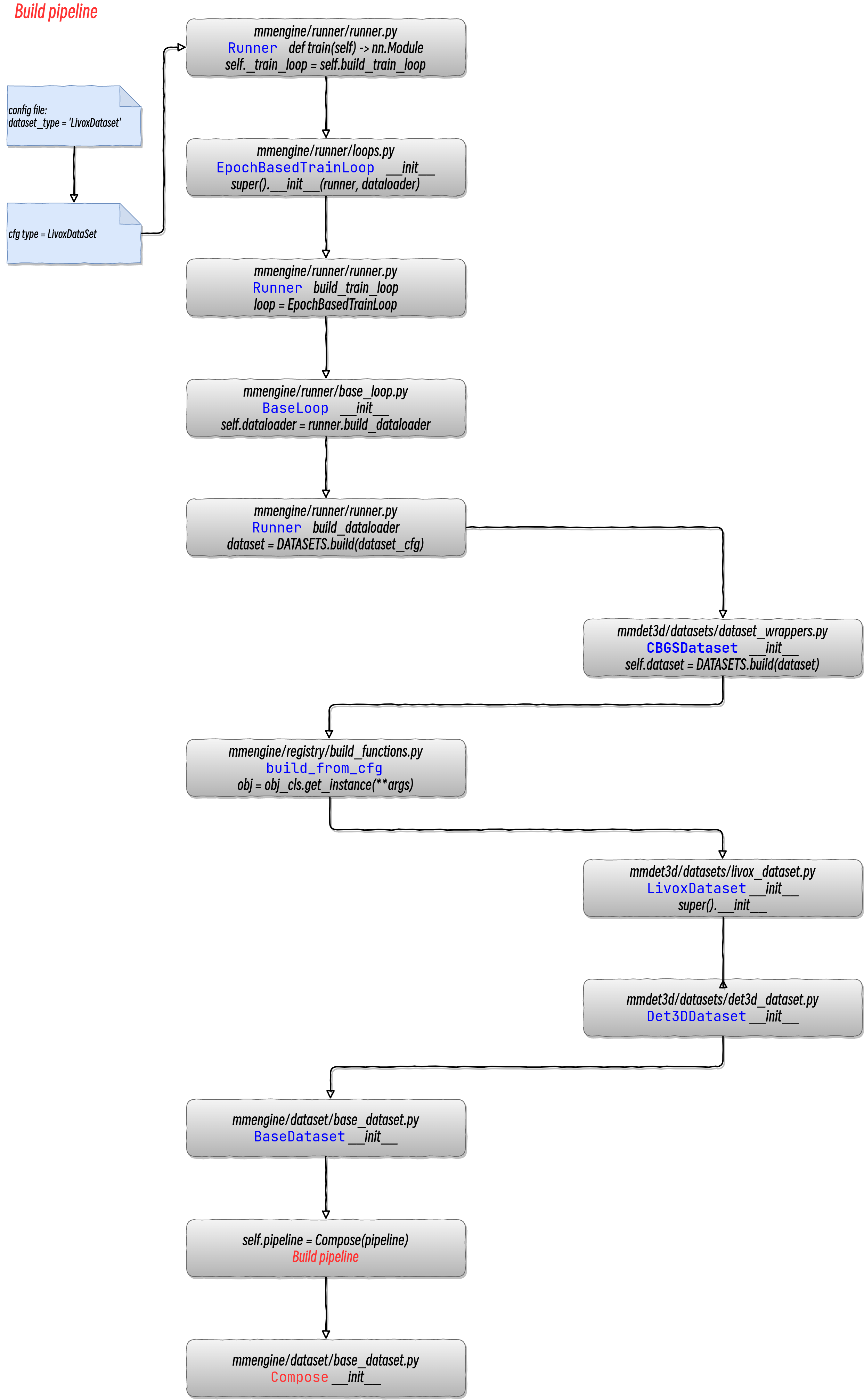
配置文件中为什么传入参数是 dict
在MMEngine 中提供了两种不同风格的执行器构建方式:
-
基于手动构建的
-
基于注册机制的。
请看下面的例子:
from mmengine.model import BaseModel
from mmengine.runner import Runner
from mmengine.registry import MODELS # 模型根注册器,你的自定义模型需要注册到这个根注册器中
@MODELS.register_module() # 用于注册的装饰器
class MyAwesomeModel(BaseModel): # 你的自定义模型
def __init__(self, layers=18, activation='silu'):
...
# 基于注册机制的例子
runner = Runner(
model=dict(
type='MyAwesomeModel',
layers=50,
activation='relu'),
...
)
# 基于手动构建的例子
model = MyAwesomeModel(layers=18, activation='relu')
runner = Runner(
model=model,
...
)
两种写法基本是等价的,区别在于:前者以 dict 作为输入时,该模块会在需要时在执行器内部被构建;而后者是构建完成后传递给执行器。
核心思想是:注册器维护着模块的构建方式和它的名字之间的映射。
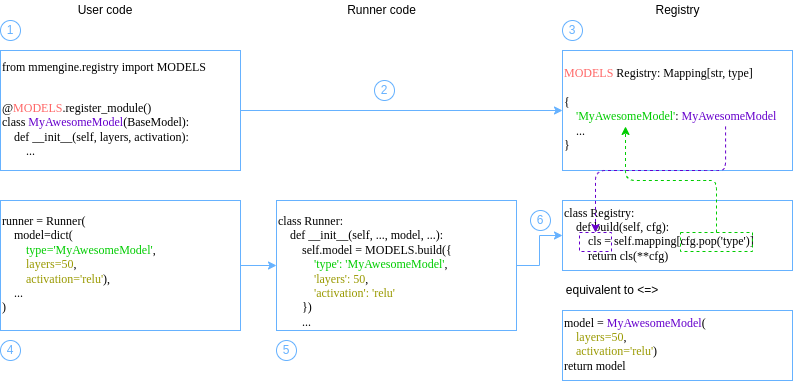
所以,当同一种方法有多种实现方式时,通过配置文件,就可以轻易在代码中选用不同实现代码,只需修改配置文件即可,而不用修改源代码。
Runner函数中参数含义
具体含义可见 /home/qiancj/anaconda3/envs/mmdetection3d_randy/lib/python3.8/site-packages/mmengine/runner/runner.py 中 Runner类的解释
- model – 要运行的模型。 它可以是用于构建模型的字典。
- work_dir - 保存检查点的工作目录。 日志将保存在名为 timestamp 的 work_dir 子目录中
- train_dataloader - 用于构建数据加载器的数据加载器对象或字典。 如果给出“无”,则意味着跳过训练步骤。 默认为无。
- val_dataloader - 用于构建数据加载器的数据加载器对象或字典。 如果给出“无”,则意味着跳过验证步骤。 默认为无。
- test_dataloader - 用于构建数据加载器的数据加载器对象或字典。 如果给出“无”,则意味着跳过验证步骤。 默认为无。
- train_cfg – 建立训练循环的命令。 如果它没有提供“type”键,它应该包含“by_epoch”来决定应该使用哪种类型的训练循环EpochBasedTrainLoop或IterBasedTrainLoop。 如果指定了 train_cfg,则还应指定 train_dataloader。 默认为无。
- val_cfg – 用于构建验证循环的指令。 如果不提供“type”键,则默认使用 ValLoop。 如果指定了
val_cfg,则还应指定 val_dataloader。 如果 ValLoop 是用 fp16=True 构建的,runner.val() 将在 fp16 精度下执行。 默认为无。 有关详细信息,请参阅 build_val_loop()。 - test_cfg – 用于构建测试循环的指令。 如果不提供“type”键,默认使用TestLoop。 如果指定了
test_cfg,则还应指定 test_dataloader。 如果 ValLoop 是用 fp16=True 构建的,runner.val() 将在 fp16 精度下执行。 默认为无。 有关详细信息,请参阅 build_test_loop()。 - auto_scale_lr – 配置自动缩放学习率。 它包括
base_batch_size和enable。base_batch_size是优化器 lr 所基于的批量大小。enable是打开和关闭该功能的开关。 - optim_wrapper – 计算模型参数的梯度。 如果指定,还应指定 train_dataloader。 如果需要自动混合精度或梯度累积训练。
optim_wrapper的类型应该是 AmpOptimizerWrapper。 有关示例,请参见 build_optim_wrapper()。 默认为无。 - param_scheduler – 用于更新优化器参数的参数调度器。 如果指定,还应指定
optimizer。 默认为无。 有关示例,请参见 build_param_scheduler()。 - val_evaluator – 用于计算验证指标的评估器对象。 它可以是一个字典或一个字典列表来构建一个评估器。 如果指定,还应指定 val_dataloader。 默认为无。
- test_evaluator – 用于计算测试步骤指标的评估器对象。 它可以是一个字典或一个字典列表来构建一个评估器。 如果指定,还应指定 test_dataloader。 默认为无。
- default_hooks – 挂钩以执行默认操作,例如更新模型参数和保存检查点。 默认挂钩是
OptimizerHook、IterTimerHook、LoggerHook、ParamSchedulerHook和CheckpointHook。 默认为无。 - custom_hooks – 执行自定义操作的挂钩,例如可视化管道处理的图像。 默认为无。
- data_preprocessor –
BaseDataPreprocessor的预处理配置。 如果model参数是一个字典并且不包含键data_preprocessor,则将参数设置为model字典的data_preprocessor。 默认为无。 - load_from – 要从中加载的检查点文件。 默认为无。
- resume – 是否恢复训练。 默认为假。 如果
resume为 True 且load_from为 None,则自动从work_dir中查找最新的检查点。 如果未找到,则恢复不会执行任何操作。 - launcher – 启动器多进程的方式。 支持的发射器是“pytorch”、“mpi”、“slurm”和“none”。 如果提供“无”,将启动非分布式环境。
- env_cfg – 用于设置环境的字典。 默认为 dict(dist_cfg=dict(backend=‘nccl’))。
- log_processor – 用于格式化日志的处理器。 默认为无。
- log_level – MMLogger 处理程序的日志级别。 默认为“信息”。
- visualizer – Visualizer 对象或字典构建 Visualizer 对象。 默认为无。 如果未指定,将使用默认配置。
- default_scope – 用于重置注册表位置。 默认为“mmengine”。
- randomness – 一些设置使实验尽可能可重现,如种子和确定性。 默认为
dict(seed=None)。 如果 seed 为 None,则将生成一个随机数,如果在分布式环境中,它将被广播到所有其他进程。 如果env_cfg中的cudnn_benchmark为True但randomness中的deterministic为True,则torch.backends.cudnn.benchmark的值最终将为False。 - experiment_name – 当前实验的名称。 如果未指定,时间戳将用作“experiment_name”。 默认为无。
- cfg – 完整配置。 默认为无。
运行器对象可以通过“runner = Runner.from_cfg(cfg)”从配置构建其中“cfg”通常包含与训练、验证和测试相关的内容用于构建相应组件的配置。我们通常使用用于启动训练、测试和验证任务的相同配置。然而同时只需要其中一些组件,例如,测试模型不需要与训练或验证相关的组件。
为避免重复修改配置,“Runner”的构造采用延迟初始化,仅在组件将要初始化时对其进行初始化使用。因此,模型始终在开始时初始化,并且仅初始化训练、验证和测试相关组件’‘runner.train()’', '‘runner.val()’ 和 ‘‘runner.test()’’ 时分别调用。
结合图示来理清其中数据的流向与格式约定
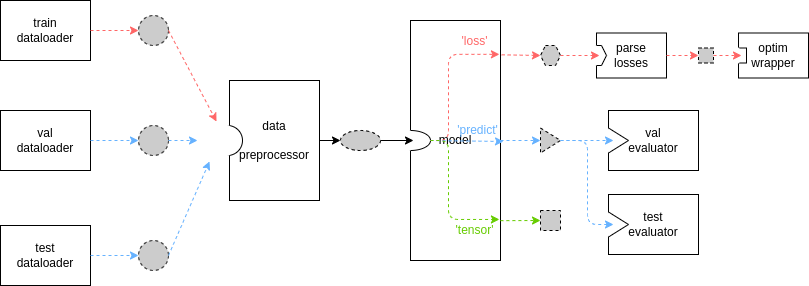
上图是执行器的基本数据流,其中虚线边框、灰色填充的不同形状代表不同的数据格式,实线方框代表模块或方法。由于 MMEngine 强大的灵活性与可扩展性,你总可以继承某些关键基类并重载其中的方法,因此上图并不总是成立。只有当你没有自定义 Runner 或 TrainLoop ,并且你的自定义模型没有重载 train_step、val_step 与 test_step 方法时上图才会成立(而这在检测、分割等任务上是常见的)。
dataloader、model 和 evaluator 之间的数据格式约定
# 训练过程
for data_batch in train_dataloader:
data_batch = data_preprocessor(data_batch)
if isinstance(data_batch, dict):
losses = model.forward(**data_batch, mode='loss')
elif isinstance(data_batch, (list, tuple)):
losses = model.forward(*data_batch, mode='loss')
else:
raise TypeError()
# 验证过程
for data_batch in val_dataloader:
data_batch = data_preprocessor(data_batch)
if isinstance(data_batch, dict):
outputs = model.forward(**data_batch, mode='predict')
elif isinstance(data_batch, (list, tuple)):
outputs = model.forward(**data_batch, mode='predict')
else:
raise TypeError()
evaluator.process(data_samples=outputs, data_batch=data_batch)
metrics = evaluator.evaluate(len(val_dataloader.dataset))
预处理模块及数据流变化
train pipeline
根据配置文件会生成 训练所用的pipeline
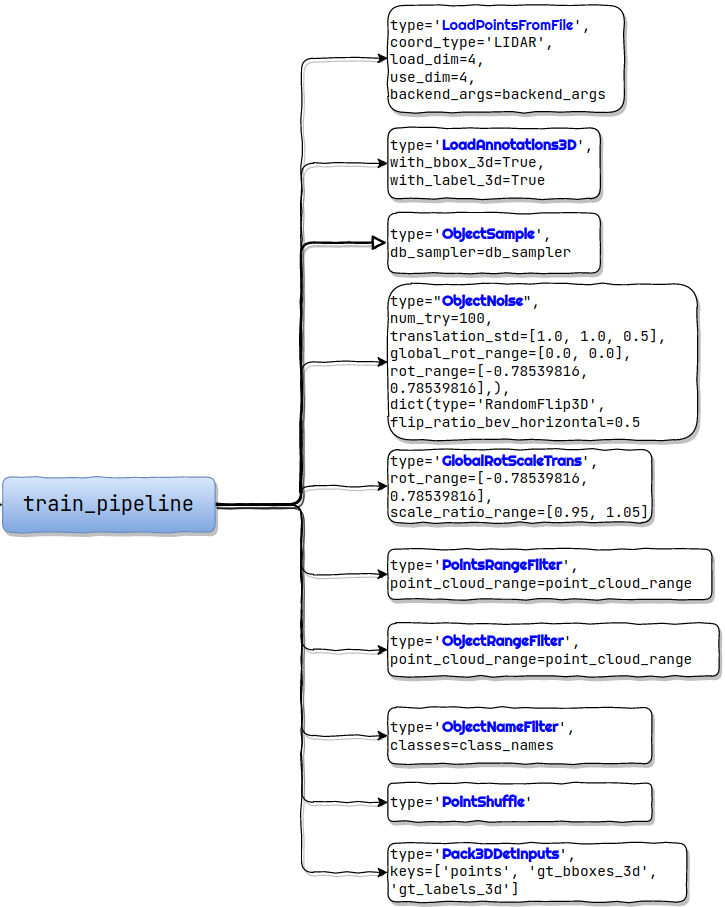
而代码中会将这些 pipeline 整合(Compose)到一起,然后循环调用
/home/qiancj/anaconda3/envs/mmdetection3d_randy/lib/python3.8/site-packages/mmengine/dataset/base_dataset.py
class Compose:
"""Compose multiple transforms sequentially.
Args:
transforms (Sequence[dict, callable], optional): Sequence of transform
object or config dict to be composed.
"""
def __init__(self, transforms: Optional[Sequence[Union[dict, Callable]]]):
self.transforms: List[Callable] = []
if transforms is None:
transforms = []
# Randy: 这里将pipeline进行了整合
for transform in transforms:
# `Compose` can be built with config dict with type and
# corresponding arguments.
if isinstance(transform, dict):
transform = TRANSFORMS.build(transform)
if not callable(transform):
raise TypeError(f'transform should be a callable object, '
f'but got {type(transform)}')
self.transforms.append(transform)
elif callable(transform):
self.transforms.append(transform)
else:
raise TypeError(
f'transform must be a callable object or dict, '
f'but got {type(transform)}')

CenterPoint model
从注册表中生成model实例过程

生成的model结构体
CenterPoint(
(data_preprocessor): Det3DDataPreprocessor(
(voxel_layer): VoxelizationByGridShape(voxel_size=[0.2, 0.2, 12], grid_shape=[512, 512, 1], point_cloud_range=[-51.2, -51.2, -5.0, 51.2, 51.2, 3.0], max_num_points=10, max_voxels=(300, 400), deterministic=True)
)
(pts_voxel_encoder): PillarFeatureNet(
(pfn_layers): ModuleList(
(0): PFNLayer(
(norm): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(linear): Linear(in_features=10, out_features=64, bias=False)
)
)
)
(pts_middle_encoder): PointPillarsScatter()
(pts_backbone): SECOND(
(blocks): ModuleList(
(0): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
)
(1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(17): ReLU(inplace=True)
)
(2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(17): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Kaiming', 'layer': 'Conv2d'}
(pts_neck): SECONDFPN(
(deblocks): ModuleList(
(0): Sequential(
(0): Conv2d(64, 128, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(1): Sequential(
(0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(2): Sequential(
(0): ConvTranspose2d(256, 128, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
)
init_cfg=[{'type': 'Kaiming', 'layer': 'ConvTranspose2d'}, {'type': 'Constant', 'layer': 'NaiveSyncBatchNorm2d', 'val': 1.0}]
(pts_bbox_head): CenterHead(
(loss_cls): GaussianFocalLoss()
(loss_bbox): L1Loss()
(shared_conv): ConvModule(
(conv): Conv2d(384, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(task_heads): ModuleList(
(0): SeparateHead(
(reg): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(height): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(dim): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(rot): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(vel): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(heatmap): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
init_cfg={'type': 'Kaiming', 'layer': 'Conv2d'}
(1): SeparateHead(
(reg): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(height): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(dim): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(rot): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(vel): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(heatmap): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
init_cfg={'type': 'Kaiming', 'layer': 'Conv2d'}
(2): SeparateHead(
(reg): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(height): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(dim): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(rot): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(vel): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(heatmap): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
init_cfg={'type': 'Kaiming', 'layer': 'Conv2d'}
(3): SeparateHead(
(reg): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(height): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(dim): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(rot): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(vel): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(heatmap): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
init_cfg={'type': 'Kaiming', 'layer': 'Conv2d'}
(4): SeparateHead(
(reg): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(height): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(dim): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(rot): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(vel): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(heatmap): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
init_cfg={'type': 'Kaiming', 'layer': 'Conv2d'}
)
)
)
生成epoch文件
work_dirs路径:
/home/qiancj/codes/mmdet3d_20220512/mmdetection3d/tools/work_dirs
work_dirs
└── centerpoint_pillar02_second_secfpn_8xb4-cyclic-20e_livox
├── 20230506_101711
│ ├── 20230506_101711.log
│ └── vis_data
│ ├── 20230506_101711.json
│ ├── config.py
│ └── scalars.json
├── centerpoint_pillar02_second_secfpn_8xb4-cyclic-20e_livox.py
├── epoch_20.pth
└── last_checkpoint
epoch_20.pth结构为:
.
└── archive
├── data
│ ├── 0
│ ├── ...
│ ├── 10
│ └── 99
├── data.pkl
└── version