1 Python多线程
1.1 GIL
其他语言,CPU是多核时是支持多个线程同时执行。但在Python中,无论是单核还是多核,同时只能由一个线程在执行。其根源是GIL的存在。GIL的全称是Global Interpreter Lock(全局解释器锁),来源是Python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个Python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。
而目前Python的解释器有多种,例如:
- CPython:CPython是用C语言实现的Python解释器。 作为官方实现,它是最广泛使用的Python解释器。
- PyPy:PyPy是用RPython实现的解释器。RPython是Python的子集, 具有静态类型。这个解释器的特点是即时编译,支持多重后端(C, CLI, JVM)。PyPy旨在提高性能,同时保持最大兼容性(参考CPython的实现)。
- Jython:Jython是一个将Python代码编译成Java字节码的实现,运行在JVM (Java Virtual Machine) 上。另外,它可以像是用Python模块一样,导入并使用任何Java类。
- IronPython:IronPython是一个针对 .NET 框架的Python实现。它可以用Python和 .NET framework的库,也能将Python代码暴露给 .NET框架中的其他语言。
GIL只在CPython中才有,而在PyPy和Jython中是没有GIL的。
每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。这就导致打印线程执行时长,会发现耗时更长的原因。
并且由于GIL锁存在,Python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,Python 的多线程效率并不高的根本原因。
1.2 创建多线程
Python提供两个模块进行多线程的操作,分别是thread和threading,前者是比较低级的模块,用于更底层的操作,一般应用级别的开发不常用。
- 方法1:直接使用
threading.Thread()
import threading
# 这个函数名可随便定义
def run(n):
print("current task:", n)
if __name__ == "__main__":
t1 = threading.Thread(target=run, args=("thread 1",))
t2 = threading.Thread(target=run, args=("thread 2",))
t1.start()
t2.start()
- 方法2:继承threading.Thread来自定义线程类,重写run方法
import threading
class MyThread(threading.Thread):
def __init__(self, n):
super(MyThread, self).__init__() # 重构run函数必须要写
self.n = n
def run(self):
print("current task:", n)
if __name__ == "__main__":
t1 = MyThread("thread 1")
t2 = MyThread("thread 2")
t1.start()
t2.start()
1.3 join函数
在Python中,join()方法用于等待线程执行完毕。它使主线程等待其他子线程完成任务后再继续执行。join()方法被调用时,主线程会阻塞,直到调用它的线程执行完毕。
以下是一个例子,演示了join()方法的作用:
import threading
import time
def task():
print("Thread started")
time.sleep(2) # 模拟线程执行耗时操作
print("Thread finished")
if __name__ == "__main__":
t = threading.Thread(target=task)
t.start()
print("Main thread continues executing")
t.join() # 等待线程t执行完毕
print("Main thread resumed after thread t finished")
在上面的例子中,我们创建了一个子线程t,并在主线程中启动它。子线程执行task()函数,在函数中模拟了一个耗时操作time.sleep(2)。主线程在启动子线程后会立即继续执行,并打印出"Main thread continues executing"。
然而,我们在主线程的下一个步骤中调用了t.join()。这意味着主线程会等待子线程执行完毕后再继续执行。在本例中,主线程会阻塞,直到子线程执行完毕。
当子线程完成任务后,会打印出"Thread finished"。此时主线程会继续执行,并打印出"Main thread resumed after thread t finished"。
通过调用t.join(),我们确保了主线程等待子线程完成后再继续执行,这对于需要线程之间协调和同步的情况非常有用。
1.4 线程同步与互斥锁
线程之间数据是共享的。当多个线程对某一个共享数据进行操作时,就需要考虑到线程安全问题。在Python的threading模块中,Lock类是用于创建锁对象的工具,它允许线程之间进行同步。
下面是一个使用Lock类的例子:
import threading
shared_resource = 0 # 共享资源
lock = threading.Lock() # 创建一个锁对象
def increment():
global shared_resource
for _ in range(100000):
lock.acquire() # 获取锁
shared_resource += 1
lock.release() # 释放锁
if __name__ == "__main__":
threads = []
for _ in range(5):
t = threading.Thread(target=increment)
threads.append(t)
t.start()
for t in threads:
t.join()
print("Final value of shared_resource:", shared_resource)
在上面的例子中,我们创建了一个共享资源shared_resource,它的初始值为0。我们还创建了一个Lock对象lock。
然后,我们定义了一个increment函数,它通过循环多次增加共享资源的值。在每次增加之前,我们使用lock.acquire()获取锁,以确保当前线程独占对共享资源的访问。完成增加后,我们使用lock.release()释放锁。
在主程序中,我们创建了5个线程,并将它们添加到一个线程列表中。然后,我们启动这些线程,并等待它们执行完毕。
最后,我们打印出最终的shared_resource的值。由于使用了锁来保护共享资源的访问,每个线程都会依次获取锁并增加共享资源的值,从而保证了最终结果的正确性。
通过使用Lock类,我们可以在多线程环境中实现对共享资源的安全访问和修改,避免了竞态条件(race condition)的发生。
1.4.1 竞态条件
竞态条件(Race Condition)是指多个并发执行的线程或进程在访问共享资源或执行操作时的不确定性和不可预测性。竞态条件会导致程序在多线程环境下产生错误的结果或出现异常行为。
竞态条件发生的原因是由于多个线程或进程在没有正确同步的情况下同时访问共享资源或执行操作,且其执行顺序无法确定。具体来说,当多个线程或进程对共享资源进行读写操作时,其执行顺序可能导致互相干扰、相互覆盖或产生不一致的结果。
以下是一个简单的竞态条件示例:
import threading
counter = 0
def increment():
global counter
for _ in range(100000):
counter += 1
if __name__ == "__main__":
threads = []
for _ in range(5):
t = threading.Thread(target=increment)
threads.append(t)
t.start()
for t in threads:
t.join()
print("Final value of counter:", counter)
在上述示例中,我们创建了一个全局计数器counter并定义了一个increment函数,该函数使用循环递增计数器的值。我们创建了5个线程,每个线程都会调用increment函数。
由于多个线程同时对counter进行写操作(递增),竞态条件就会出现。因为线程之间的执行顺序是不确定的,可能会发生如下情况:
- 线程 A 读取counter的值为 0。
- 线程 B 读取counter的值为 0。
- 线程 A 递增counter的值为 1。
- 线程 B 递增counter的值为 1。
- 最终的结果是counter的值为 1,而不是预期的 2。
这个示例展示了竞态条件的问题,多个线程并发地修改共享资源导致最终结果的不确定性。
https://blog.csdn.net/zong596568821xp/article/details/99678390
1.5 可重入锁(递归锁)
为了满足在同一线程中多次请求同一资源的需求,Python提供了可重入锁(RLock)。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire 的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。具体用法如下:
2 Python 多进程
2.1 创建多进程
Python要进行多进程操作,需要用到muiltprocessing库,其中的Process类跟threading模块的Thread类很相似。所以直接看代码熟悉多进程。
- 方法1:直接使用Process, 代码如下:
from multiprocessing import Process
def show(name):
print("Process name is " + name)
if __name__ == "__main__":
proc = Process(target=show, args=('subprocess',))
proc.start()
proc.join()
- 方法2:继承Process来自定义进程类,重写run方法, 代码如下:
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name):
super(MyProcess, self).__init__()
self.name = name
def run(self):
print('process name :' + str(self.name))
time.sleep(1)
if __name__ == '__main__':
for i in range(3):
p = MyProcess(i)
p.start()
for i in range(3):
p.join()
2.2 多进程通信
进程之间不共享数据的。如果进程之间需要进行通信,则要用到Queue模块或者Pipe模块来实现。
- Queue
Queue是多进程安全的队列,可以实现多进程之间的数据传递。它主要有两个函数put和get。
put() 用以插入数据到队列中,put还有两个可选参数:blocked 和timeout。如果blocked为 True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出 Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
get()可以从队列读取并且删除一个元素。同样get有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且 timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常。
具体用法如下:
from multiprocessing import Process, Queue
def put(queue):
queue.put('Queue 用法')
if __name__ == '__main__':
queue = Queue()
pro = Process(target=put, args=(queue,))
pro.start()
print(queue.get())
pro.join()
- Pipe
Pipe的本质是进程之间的用管道数据传递,而不是数据共享,这和socket有点像。pipe() 返回两个连接对象分别表示管道的两端,每端都有send()和recv()函数。如果两个进程试图在同一时间的同一端进行读取和写入那么,这可能会损坏管道中的数据,具体用法如下:
from multiprocessing import Process, Pipe
def show(conn):
conn.send('Pipe 用法')
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
pro = Process(target=show, args=(child_conn,))
pro.start()
print(parent_conn.recv())
pro.join()
2.3 进程池
创建多个进程,我们不用傻傻地一个个去创建。我们可以使用Pool模块来搞定。Pool 常用的方法如下:
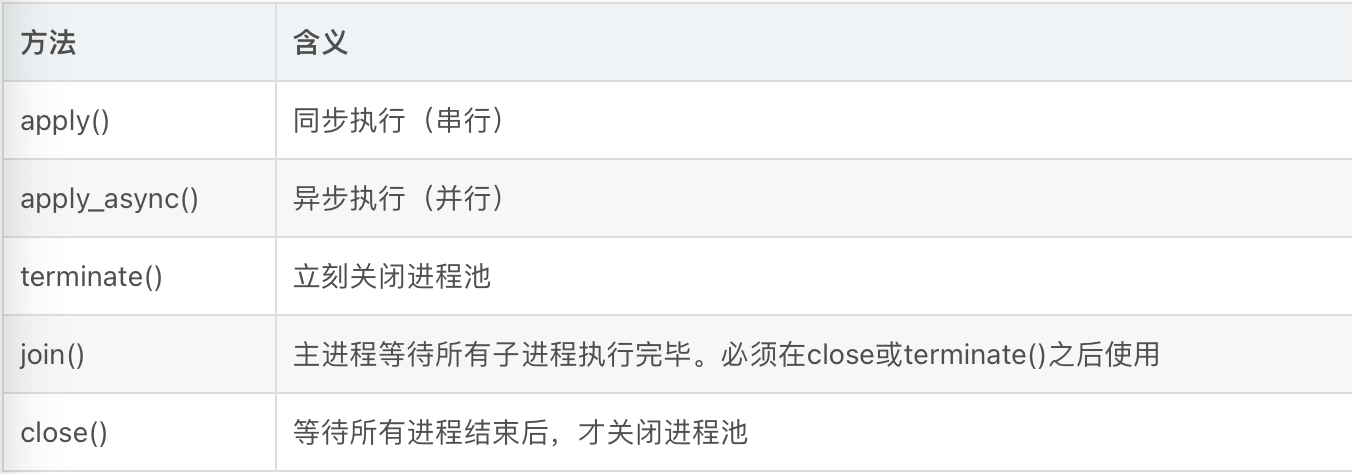
具体用法见示例代码:
#coding: utf-8
import multiprocessing
import time
def func(msg):
print("msg:", msg)
time.sleep(3)
print("end")
if __name__ == "__main__":
# 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool = multiprocessing.Pool(processes = 3)
for i in range(5):
msg = "hello %d" %(i)
# 非阻塞式,子进程不影响主进程的执行,会直接运行到 pool.join()
pool.apply_async(func, (msg, ))
# 阻塞式,先执行完子进程,再执行主进程
# pool.apply(func, (msg, ))
print("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~")
# 调用join之前,先调用close函数,否则会出错。
pool.close()
# 执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
pool.join()
print("Sub-process(es) done.")
如上,进程池Pool被创建出来后,即使实际需要创建的进程数远远大于进程池的最大上限,p.apply_async(test)代码依旧会不停的执行,并不会停下等待;相当于向进程池提交了10个请求,会被放到一个队列中;
当执行完p1 = Pool(5)这条代码后,5条进程已经被创建出来了,只是还没有为他们各自分配任务,也就是说,无论有多少任务,实际的进程数只有5条,计算机每次最多5条进程并行。
当Pool中有进程任务执行完毕后,这条进程资源会被释放,pool会按先进先出的原则取出一个新的请求给空闲的进程继续执行;
当Pool所有的进程任务完成后,会产生5个僵尸进程,如果主线程不结束,系统不会自动回收资源,需要调用join函数去回收。
join函数是主进程等待子进程结束回收系统资源的,如果没有join,主程序退出后不管子进程有没有结束都会被强制杀死;
创建Pool池时,如果不指定进程最大数量,默认创建的进程数为系统的内核数量.
3 选择多线程还是多进程?
在这个问题上,首先要看下你的程序是属于哪种类型的。一般分为两种:CPU密集型和I/O密集型。
- CPU 密集型:程序比较偏重于计算,需要经常使用CPU来运算。例如科学计算的程序,机器学习的程序等。
- I/O 密集型:顾名思义就是程序需要频繁进行输入输出操作。爬虫程序就是典型的I/O密集型程序。
如果程序是属于CPU密集型,建议使用多进程。而多线程就更适合应用于I/O密集型程序。
![[MySQL]事务的浅谈](https://img-blog.csdnimg.cn/5581e9d77725491cb28fc1be522442e5.png)