接上篇《19、Python异常处理》
上一篇我们学习了Python中有关异常(捕获异常、处理异常等)的知识。从本篇开始,我们进入Python的实战教程,学习爬虫的相关技术,本篇主要讲解要爬取的HTML页面的结构。
一、一个场景
假设一个场景,我们即将使用Python爬虫来抓取京东商城的页面信息,主要是首页左边导航栏的数据,以此来分析京东主要经营哪些品类的商品: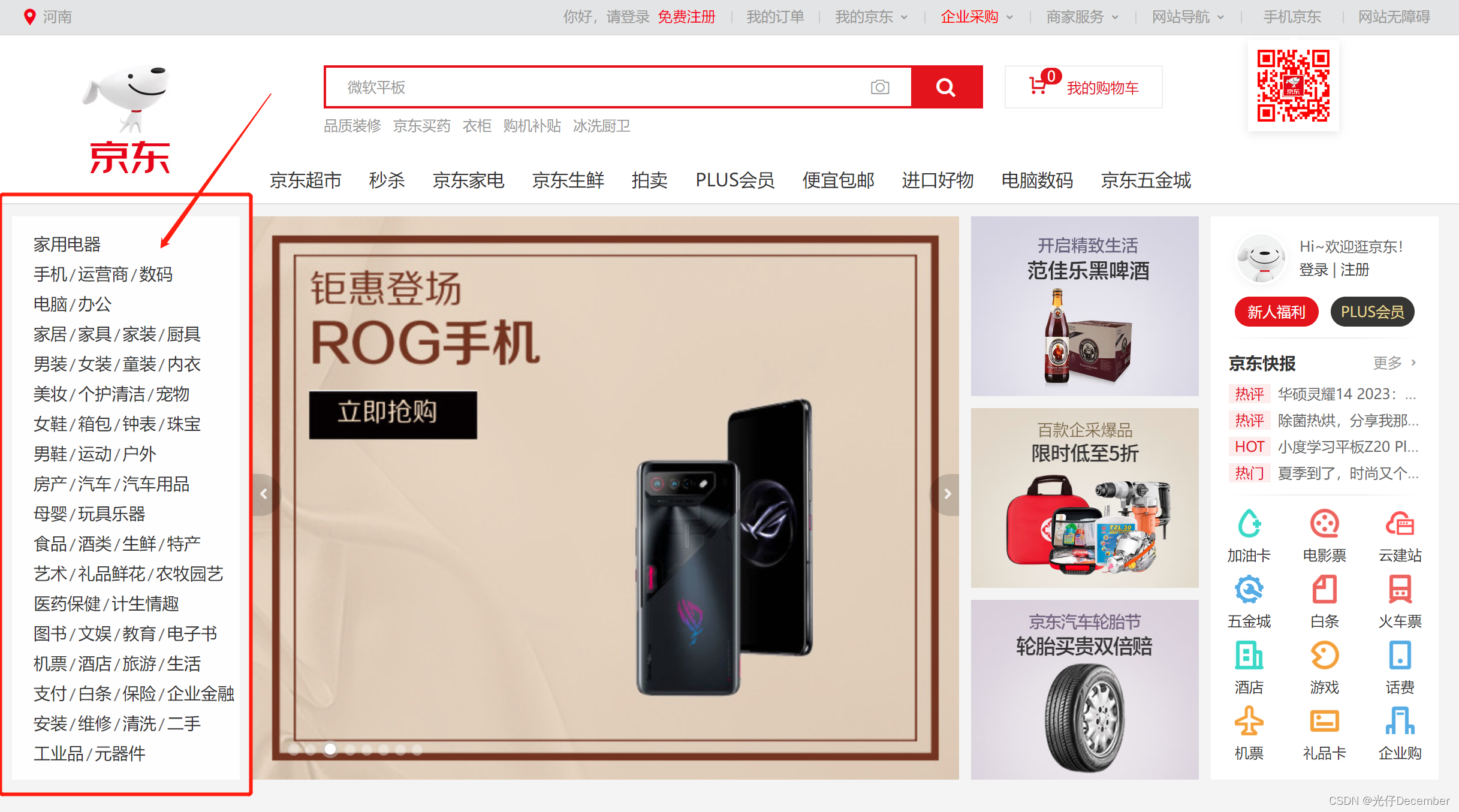
这里我们就要梳理清楚我们的实际需求,我们只是需要首页的左侧导航栏的数据,即这个页面的部分数据,而不是所有数据,我们鼠标点击右键,选择检查: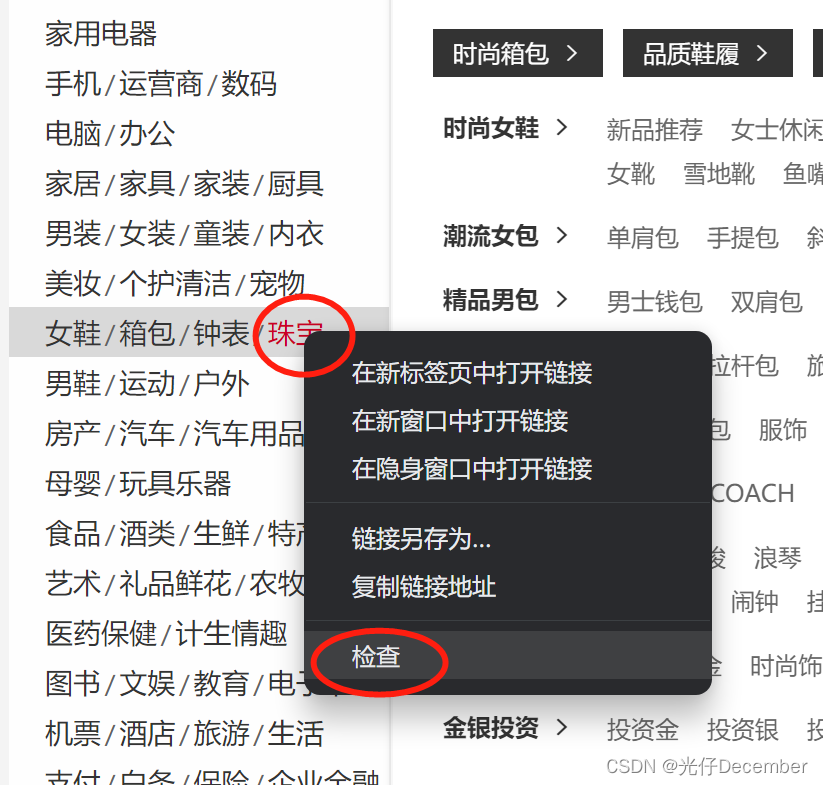
可以看到整个页面的HTML源码,这里面的信息有太多太多: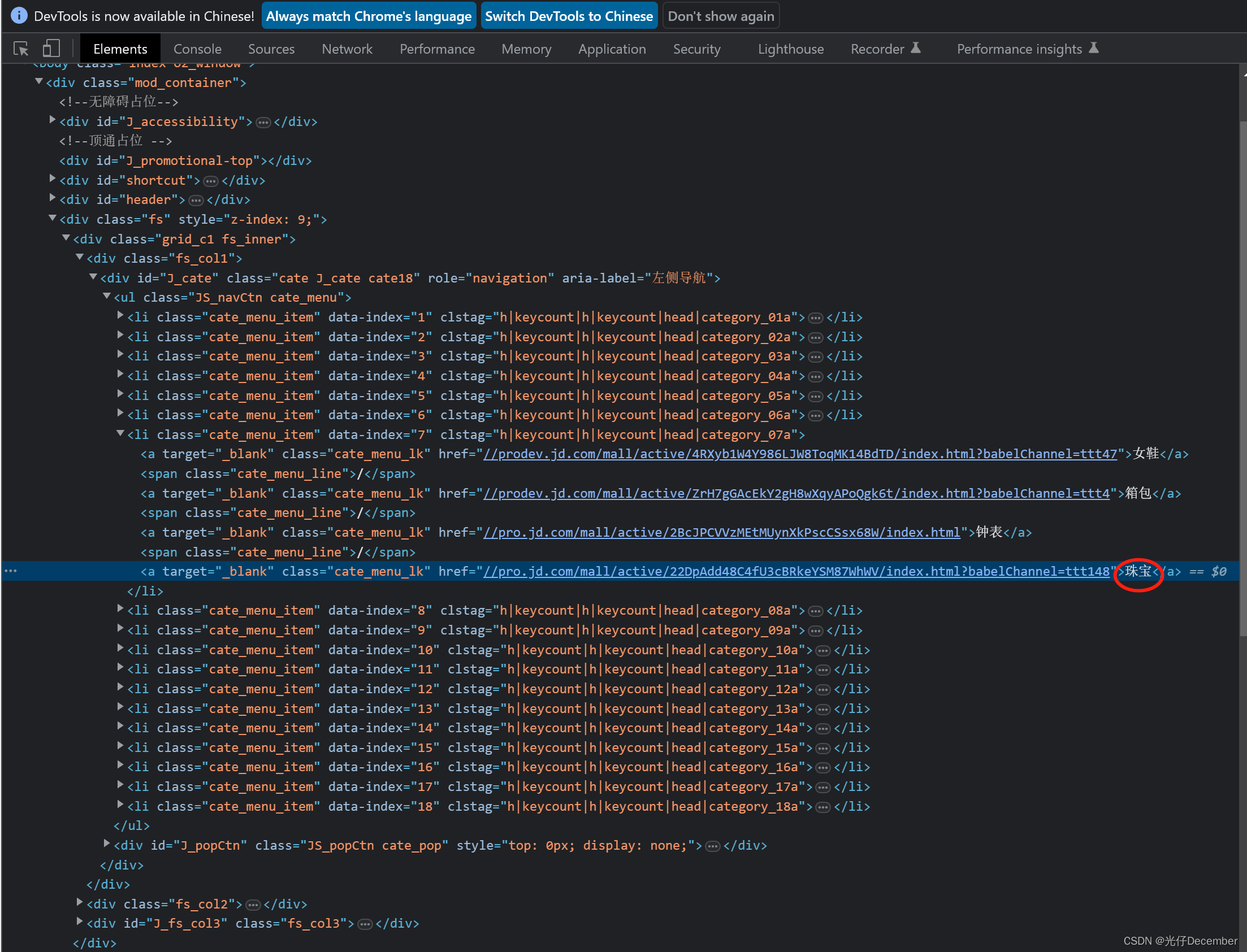
而我们只想要里面的商品分类汉字,不需要里面的HTML标签。我们要实现这个目标,就要清晰的知道这个页面间的标签结构。
所以,学习Python爬虫之前,我们要了解我们爬取的目标,即整个HTML文档的结构是什么样的,我们怎么去爬这种结构的文档。
二、HTML页面结构
我们在编辑器新建一个HTML格式的文件:
然后我们可以看到新建好的HTML文件,已经为我们预写好了一些代码: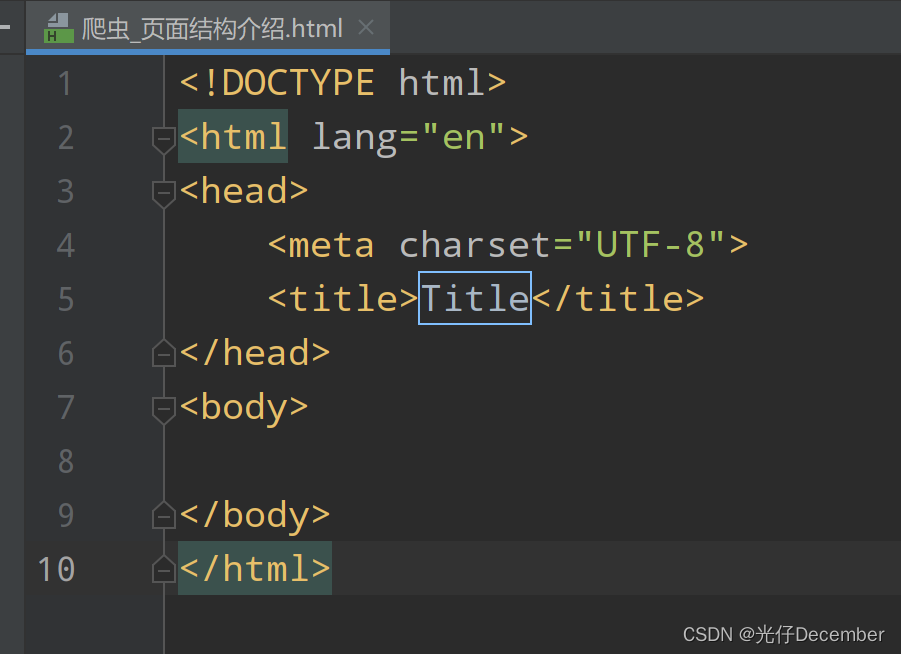
这里面的代码就是HTML代码,这个结构就是HTML的主体结构,我们下面来介绍一下HTML的主体结构。
最上面是一个<!DOCTYPE html>描述,然后主体代码里,最外面被<html></html>标签包裹,里面包含了两个大模块,分别是<head></head>和<body></body>。他们的含义分别如下:
(1)<!DOCTYPE html>:这一行代码的作用是告诉浏览器该文档使用的是HTML5标准。在HTML5中,该声明已经被简化为一个固定的格式,即 “<!DOCTYPE html>”。
(2)<html>:这个标签表示HTML文档的根元素,它包含了整个HTML文档的内容,从头到尾只有一个。在<html>标签内部应该包含两个子元素:<head>和<body> 。
(3)<head>:这个标签包含了一些用于描述文档的元数据,比如网页标题,引入CSS样式表等等,这些数据对用户来说是不可见的。
(4)<body>:这个标签包含了网页上显示给用户的所有内容,比如文本、图像、链接等等。可以在<body>标签中插入多个子元素以形成更复杂的页面布局。
除了这些基本的元素,还有许多其他的HTML标记可以用来丰富文档结构,并增强内容的语义和可访问性。
三、HTML一些简单的标签
我们后面使用爬虫抓取HTML页面的时候,主要是针对<body>标签中的一些子元素进行分析,为了便于我们后续学习,我们来了解一下一些爬虫经常需要抓取的<body>标签子元素,以及其概念。
1、表格
可以使用<table>标签来创建表格。表格由行和列组成,每个单元格都可以包含文本或其他元素。
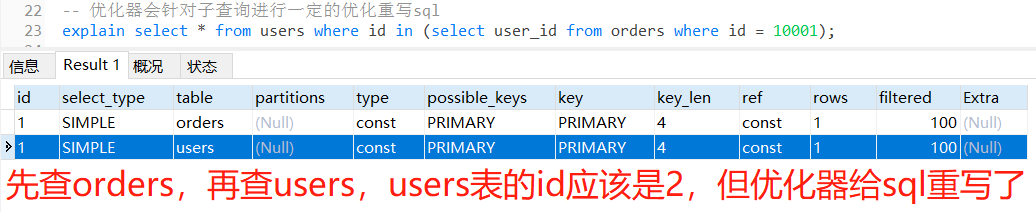
其中<table>标签表示整个表格,<tr>表示表格中的一行,<th>和<td>分别表示表头和单元格。
下面是一个基本的表格示例:
<table>
<tr>
<th>姓名</th>
<th>年龄</th>
<th>性别</th>
</tr>
<tr>
<td>张三</td>
<td>25</td>
<td>男</td>
</tr>
<tr>
<td>李四</td>
<td>30</td>
<td>女</td>
</tr>
</table>效果:
还可以通过给<table>增加一个控制边框宽度的属性,给它加个1像素,solid格式,#ddd颜色的表格边框:
<table border="1px solid #ddd">效果:
通过在表格中嵌套多个行和列元素,我们可以创建更复杂的表格设计。同时,我们也可以通过CSS来对表格进行样式化。
2、无序列表和有序列表
<ul>和<ol>是HTML中常用的列表标签,它们可以用来创建无序列表和有序列表。
(1)<ul>
<ul>标签表示无序列表,通常会对列表项目添加一个圆点符号或其他的符号来表示每个列表项。例如:
<ul>
<li>苹果</li>
<li>香蕉</li>
<li>橙子</li>
</ul>效果:
在这个例子中,<ul>标签表示整个无序列表,每个<li>标签表示一个列表项。浏览器将自动在每个列表项前添加圆点符号。
<li>标签本身不会产生任何可见的效果,但是它是列表中的关键元素。列表项中可以包含任何其他HTML元素,例如图像、链接等等。
(2)<ol>
除了无序列表,我们还可以使用<ol>标签来创建有序列表。与无序列表类似,有序列表也由多个列表项组成,不同之处在于浏览器将自动为每个列表项添加数字或字母编号。例如:
<ol>
<li>第一步</li>
<li>第二步</li>
<li>第三步</li>
</ol>效果:
在这个例子中,<ol>标签表示整个有序列表,每个<li>标签表示一个列表项。浏览器将自动为每个列表项添加数字编号。
总之,<ul>和<ol>标签是HTML中非常实用的标记,可用于创建各种类型的列表。它们使得在文档中展示信息更加清晰、易读和易于理解。这两个列表标记,在爬虫使用的场景中非常多。
3、超链接
<a>标签是HTML中常用的链接标签,它可以用来创建指向其他页面、文档、位置或任何其他URL的超链接。
下面是一个基本的<a>标签的示例:
<a href="http://www.baidu.com">点击这里访问百度网站</a>效果:

在这个示例中,<a>标签定义了一个超链接,并使用href属性指定了要链接到的URL。用户点击该链接时,浏览器将会打开指定的URL。
总之,<a>标签是HTML中非常实用的标签,它提供了一种链接到其他内容和页面的方法,使得Web页面更加富有交互性和可访问性。
在我们爬虫的时候,会经常遇到<a>标签,有时候我们还需要去分析<a>标签指向的下一个地址,便于我们更深一步的爬取下一层的页面。
4、容器
<div>标签是HTML中常用的容器标签,它可以用来将HTML文档中的一组元素组合在一起,并为这些元素提供一个共同的父级元素。
<div>元素本身不会产生任何可见的效果,但是它可以被用来创建网页布局、调整样式和分组相关元素。对于CSS和JavaScript开发人员,<div>标签也是非常有用的,因为它允许它们轻松地选择和操作页面上的多个元素。
以下是一个<div>标签的示例:
<div class="container">
<h1>欢迎来到我的网站!</h1>
<p>这里是我的个人博客,我将分享我的经验和知识。</p>
</div>效果:
在这个示例中,<div>标签用作一个容器元素,包含了标题和段落两个子元素。我们还使用了class属性来为该<div>标签添加一个类名,使得我们可以轻松地对它应用样式。
除此之外,<div>标签还可以与其他HTML元素一起使用,以创建更复杂的网页结构。例如,我们可以将一个表单元素放置在<div>容器中,然后使用CSS来设计表单的外观和交互性。
总之,<div>标签是HTML中非常实用的标签,它提供了一种简单而有效的方法来组合和控制HTML元素,并让我们更好地管理Web页面的结构和样式。
四、回顾场景
我们回顾一下刚刚那个京东的界面,我们将导航栏那部分的代码选中,可以看到里面存在大量的容器、列表及超链接标签: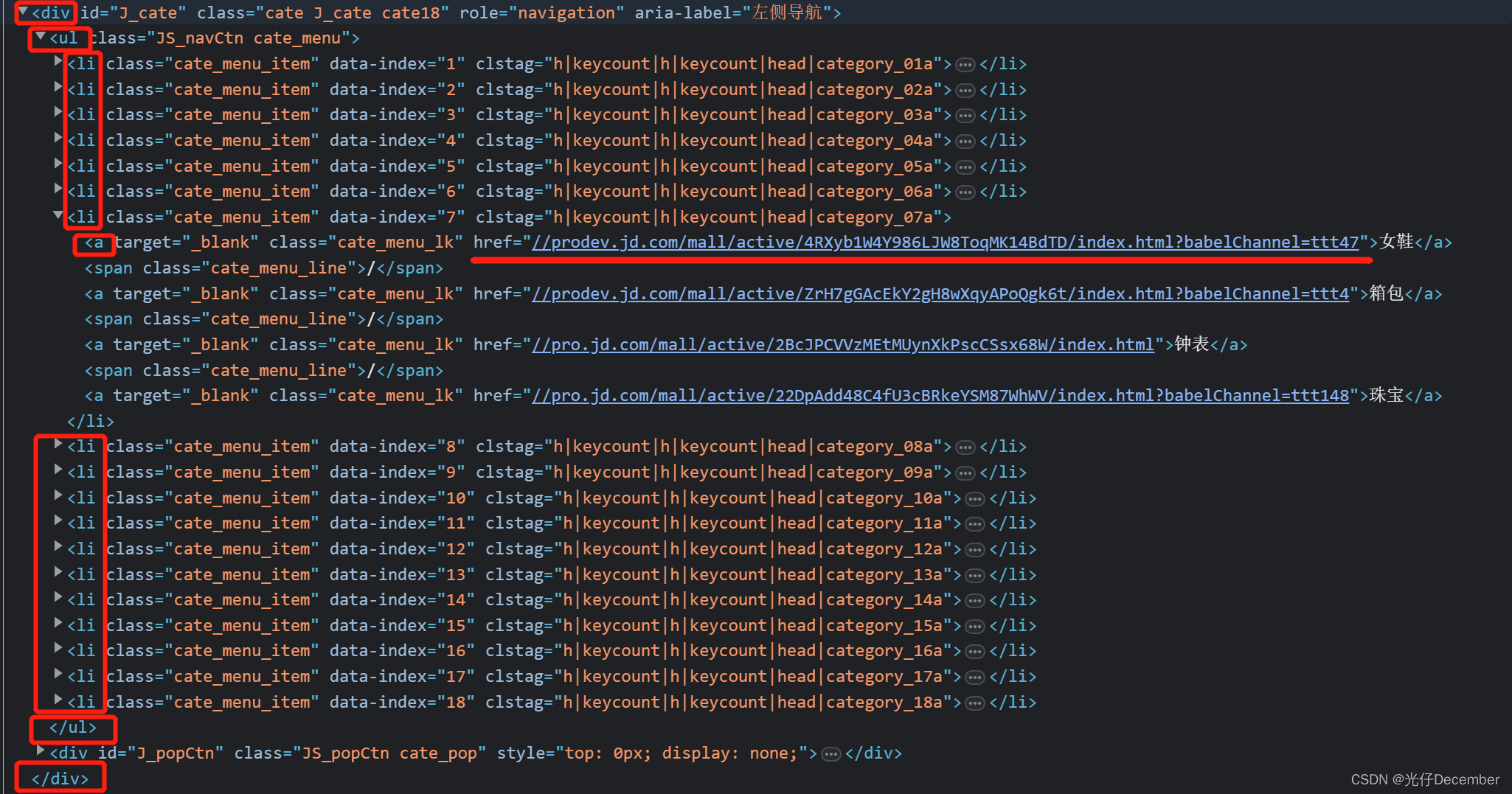
我们后面学习爬虫技术后,就可以根据结构进行分析,并过滤抓取到我们需要的目标内容。
关于HTML页面结构的基本介绍就到这里了,下一篇我们来正式介绍爬虫的基本概念。
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://blog.csdn.net/acmman/article/details/130790505