一、概述
缓存穿透是指查询一个不存在的数据,由于缓存和数据库都没有命中,导致每次请求都需要从数据库中读取数据,增加了数据库的负担。解决缓存穿透的方法有以下几种:
-
布隆过滤器(Bloom Filter):使用位数组来表示一个集合,并通过哈希函数将元素映射到数组上。在查询数据时,先判断该数据是否存在于布隆过滤器中,如果存在则直接返回结果,否则再从数据库中查询数据。
-
缓存空对象:在缓存中存储空对象,当查询一个不存在的数据时,直接返回空对象,而不是默认值或者错误信息。
-
设置热点数据永不过期:对于一些热点数据,可以设置永不过期,这样即使缓存未命中,也不会影响数据的一致性。
-
使用分布式锁:在查询数据前先使用分布式锁进行加锁,保证只有一个线程能够访问数据库,其他线程需要等待锁释放后才能进行查询。
-
使用数据库的缓存机制:一些数据库提供了自己的缓存机制,可以将查询结果缓存到内存中,减少对数据库的访问次数。
二、布隆过滤器
1、原理
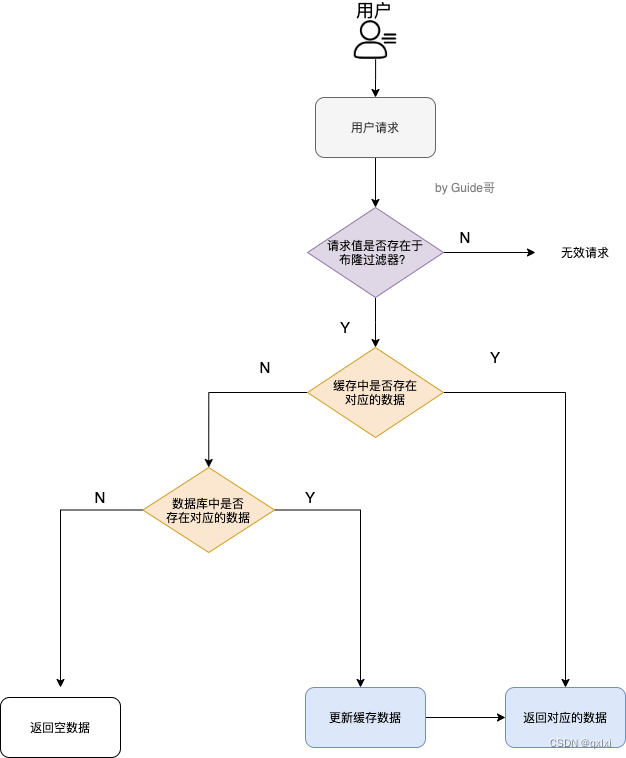
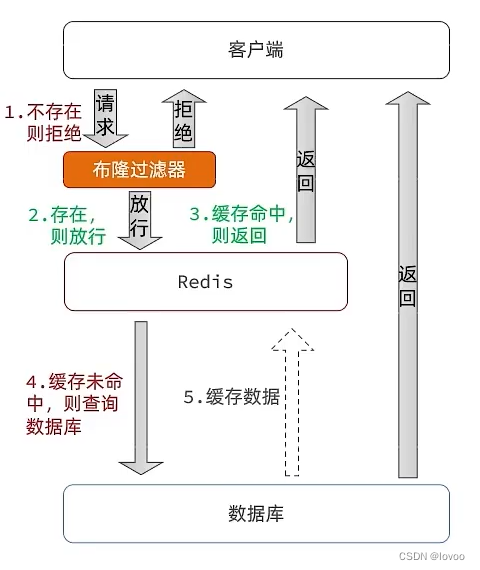
布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,
假设布隆过滤器判断这个数据不存在,则直接返回
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突
2、优缺点
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
3、流程图
三、缓存空对象
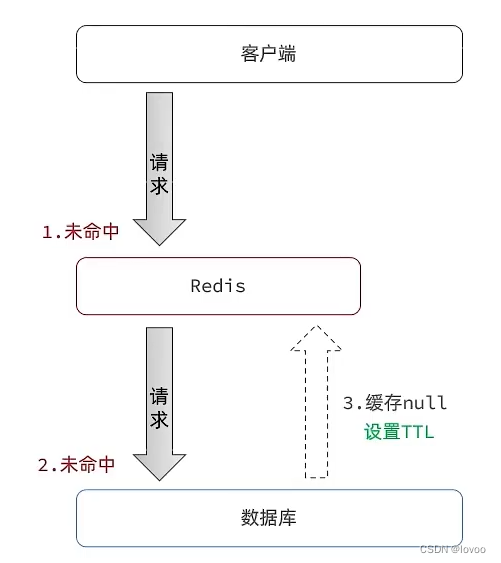
1、缓存空对象思路分析
当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了
2、优缺点
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
3、流程图:
四、设置热点数据永不过期
1、说明
对于缓存穿透问题,设置热点数据永不过期是一种解决方法。热点数据指的是被频繁访问的数据,如果将这些数据的过期时间设置为永久或者相对较长的时间,即使缓存未命中,也不会影响数据的一致性。
2、具体实现方式:
- 定义一个包含热点数据的 Map 对象,使用 synchronized 关键字保证并发安全。
private static Map<String, Object> hotDataMap = new ConcurrentHashMap<>();
- 在添加热点数据时,设置过期时间为永久:
hotDataMap.put("key", value);
hotDataMap.put("key", value); // 可以重复添加
- 在查询数据时,先从缓存中获取热点数据,如果缓存中不存在,则从数据库中查询并加入缓存:
Object value = hotDataMap.get("key");
if (value == null) {
// 从数据库中查询数据
value = getValueFromDatabase();
hotDataMap.put("key", value);
}
- 将热点数据放入缓存中:
cache.put(key, value);
需要注意的是:
如果设置了热点数据的永不过期,需要定期清理缓存中的无用数据,以避免占用过多内存。
五、使用分布式锁
1 说明
使用分布式锁可以解决缓存穿透问题。缓存穿透是指查询一个不存在的数据,由于缓存和数据库都没有命中,导致每次请求都需要从数据库中读取数据,增加了数据库的负担。而分布式锁可以在多台服务器之间协调对某个资源的操作,保证同一时间只有一个线程可以对该资源进行操作。
2 实现步骤
-
引入分布式锁框架,如 Redis 的分布式锁、Zookeeper 等。
-
在查询数据前先使用分布式锁进行加锁,保证只有一个线程能够访问数据库,其他线程需要等待锁释放后才能进行查询。
-
如果查询结果为空,则释放锁并返回空对象;如果查询结果不为空,则将结果存入缓存中。
-
在更新数据时,也需要使用分布式锁进行加锁,保证只有一个线程能够对缓存进行更新。
-
在释放锁时,需要确保所有线程都已经完成了对数据的处理。
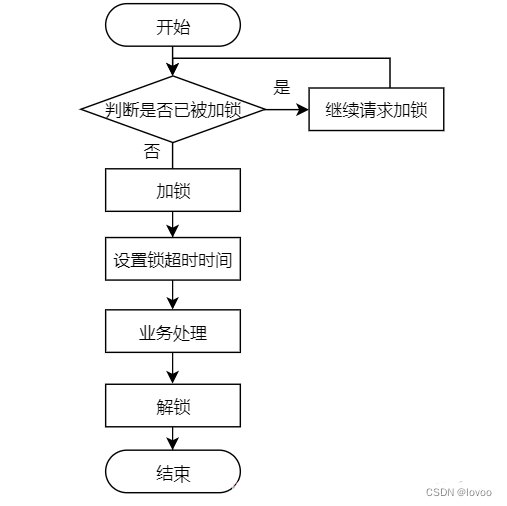
3 Redis分布式锁的基本流程:
-
客户端尝试获取锁,向Redis服务器发送SETNX命令(SET if Not eXists)。
-
Redis服务器收到SETNX命令,尝试为客户端设置锁,如果该锁不存在,Redis会将锁设置为1,表示客户端获取了锁;否则,Redis返回0,表示客户端未能获取锁。
-
客户端收到Redis服务器返回的结果,如果结果为1,则表示客户端已经成功获取了锁,可以执行后续操作;如果结果为0,则表示客户端未能获取锁,需要再次尝试获取或者等待其他客户端释放锁。
-
客户端在执行完任务后,需要释放锁,向Redis服务器发送DEL命令,告诉Redis服务器该客户端已经完成任务,锁不再需要。
-
Redis服务器收到DEL命令,将该客户端的锁删除,其他客户端可以继续尝试获取锁。
需要注意的是,在分布式环境中,需要使用带有超时时间的锁,以防止锁死。在获取锁时,需要设置一个超时时间,如果在指定时间内未能成功获取锁,则需要放弃获取锁。同时,在释放锁时,需要检查该锁是否属于当前客户端,避免误删其他客户端的锁。
4、缺点
- 使用分布式锁会增加系统的复杂度和运行成本。
- 分布式锁也有可能出现死锁等问题,需要进行合理的设计和调试。
六、具体运用
1、从没有使用到使用缓存NULL值的流程变化
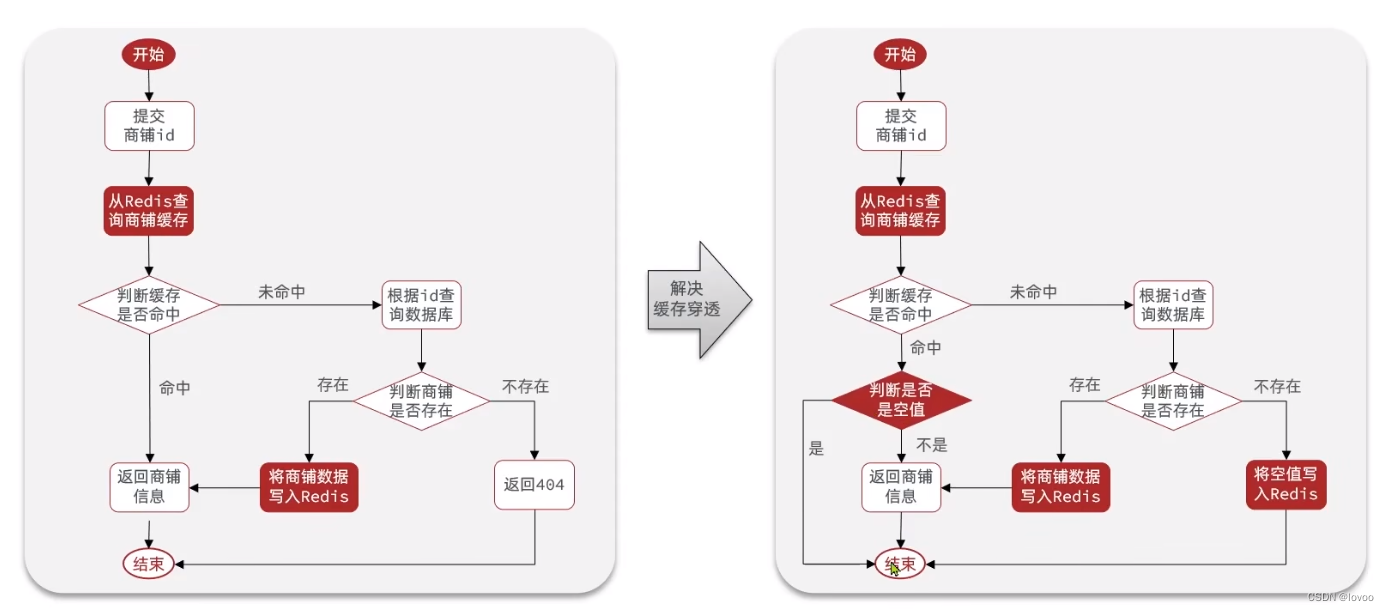
2、未使用缓存NULL时的代码
@Override
public Result queryShopById(Long id) {
//1 从redis获取
String shopStr = redisTemplate.opsForValue().get(RedisKey.CACHE_SHOP_PRE + id);
if (MyStrUtil.isNotEmpty(shopStr)) {
return Result.ok(JSONUtil.toBean(shopStr, Shop.class));
}
Shop shop = this.getById(id);
if (shop == null) {
return Result.fail("店铺不存在");
}
redisTemplate.opsForValue().set(RedisKey.CACHE_SHOP_PRE + id, JSONUtil.toJsonStr(shop), 30, TimeUnit.MINUTES);
return Result.ok(shop);
}
3、使用缓存NULL时的代码
@Override
public Result queryShopById(Long id) {
//1 从redis获取
String shopStr = redisTemplate.opsForValue().get(RedisKey.CACHE_SHOP_PRE + id);
if (StringUtils.isNotBlank(shopStr)) {
return Result.ok(JSONUtil.toBean(shopStr, Shop.class));
}
//空字符串
if(shopStr != null){
return Result.fail("店铺不存在");
}
Shop shop = this.getById(id);
if (shop == null) {
redisTemplate.opsForValue().set(RedisKey.CACHE_SHOP_PRE + id, "", 1, TimeUnit.MINUTES);
return Result.fail("店铺不存在");
}
redisTemplate.opsForValue().set(RedisKey.CACHE_SHOP_PRE + id, JSONUtil.toJsonStr(shop), 30, TimeUnit.MINUTES);
return Result.ok(shop);
}
七、源码下载:
gitee.com/charlinchenlin/koo-erp