以下用形状来描述矩阵。对于向量,为了方便理解,也写成了类似(1,64)这种形状的表示形式,这个你理解为64维的向量即可。下面讲的矩阵相乘都是默认的叉乘。
词嵌入矩阵形状:以BERT_BASE为例,我们知道其有12层Encoder,12个Head。对于中文版的BERT_BASE来说,词嵌入矩阵的形状为(21128,768),其中21128就是词典的大小,768是词典中的每个字对应的维度。
需要注意的是这个维度其实可以是其他值,只不过官方恰巧给的是768=64×12(12个head,每个head是64维),对于Transformer的Encoder来说,这个维度是512,这个时候512≠64×6(6个head,每个head为64维)。一般来说Encoder层数越多,该词向量维度也应该越大,毕竟整个网络参数数量增大之后,有能力学习更多维度的信息。
词向量维度:然后我们知道,每个位置x的输入其实一开始是一个序数,通过这个序数便可以在上述词嵌入矩阵中查找到相应的词向量,每个位置x的词向量维度为(1,768)。对于整个BERT序列来说,其序列长度为512,所以BERT序列的形状为(512,768)。
Q、K、V向量的维度:这个是论文中固定的,维度都是(1,64)。而由词向量x到Q、K、V向量是分别乘以一个权重矩阵(Wq、Wk、Wv)得到的,所以权重矩阵的形状为(768,64)。上述都是一个head的情况,扩展到12个head,那么整个权重矩阵的形状就变成了(768,768)。这样词向量x和这个权重矩阵相乘后得到维度为(1,768)维度的向量,然后经过切分在单个head上为(1,64)维度的向量。
注意力计算后的维度:注意力的计算如下,这里盗个图,链接为:
https://zhuanlan.zhihu.com/p/48508221
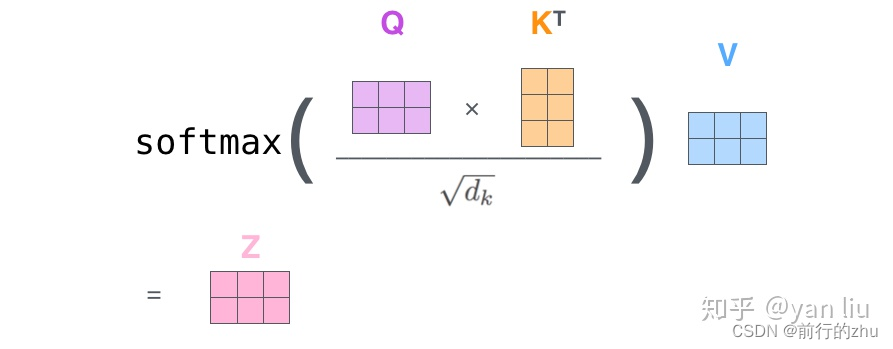
可知Q向量(1,64)和K的转置(64,1)相乘后其实就变成了一个数,该数再和V向量进行数乘得到的z向量,维度和V一样,为(1,64)。多个head中的z向量进行拼接得到(1,768)维的Z’向量。Z’向量再乘以一个转换矩阵Wo(768,768)得到最终的Z向量(1,768)。
需要注意的是,上述图中的Q、K、V向量均有两个,最终得到两个z向量。并且这里公式没有考虑掩码的情况,但是掩码并不影响矩阵的形状。
前馈神经网络(FFNN)的形状:前馈神经网络用一句话概括就是对于多头注意力的输出先进行线性变化,然后经过激活函数之后再进行线性变换。前馈神经网络的维度为3072,由于单个时刻多头注意力的输出维度为(1,768),第一个线性变换的矩阵形状为(768,3072),第二个线性变换矩阵的形状为(3072,768)。
BERT输入以及权重矩阵形状解析
news2026/4/12 9:51:36
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/550582.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

记录--Vue中如何导出excel表格
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 一、导出静态数据 1、安装 vue-json-excel npm i vue-json-excel注意,此插件对node有版本要求,安装失败检查一下报错是否由于node版本造成! 2、引入并注册组件(以全…

【CSS语法应用在Qt中的QSS和文本】第一天
CSS语法应用在Qt中的QSS和文本 【1】CSS语法【1】QSS使用以上CSS语法【1.1】QTextBrowser设置样式表【1.2】QTextBrowser使用CSS语法设置文本样式 【1】CSS语法 💛💛💛💛💛💛💛💛&am…

Redis的五大类型
一、String数据类型
概述:String是redis最基本的类型,最大能存储512MB的数据,String类型是二进制安全的,即可以存储任何数据、比如数字、图片、序列化对象等
1. SET/GET/APPEND/STRLEN:
append命令:append key valu…
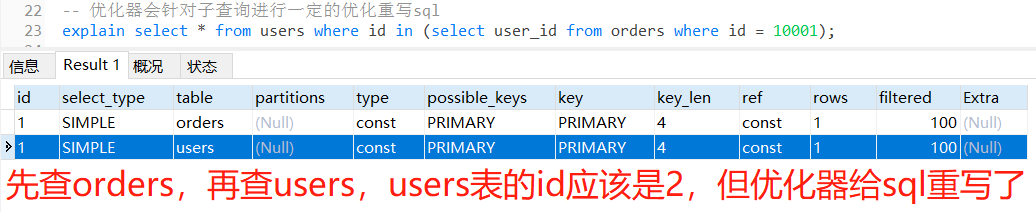
【mysql】explain执行计划之id列
目录 一、说明二、示例2.1 id相同,执行顺序从上到下2.2 id不相同,id值越大越先执行2.3 既有id相同也有id不同的情况,先执行序号大的,再同级从上往下执行2.4 id列显示为null的最后执行。表示结果集,不需要使用它来进行查…

记录一次windows mysql5.7安装失败的过程
首先下载mysql安装包 windows版本 https://dev.mysql.com/downloads/installer/ 接着 在执行安装mysql msi安装包最后一步的时候,显示 Failed to start service MySQL57. 只有在任务处于完成状态(RanToCompletion、Fau 这时候 检查要么windows下面mysql的卸载残留没…

AUTOSAR-文档命名说明
文章目录 AUTOSAR_TR_PredefinedNamesAutosar验收测试基本说明 AUTOSAR_TR_PredefinedNames
AUTOSAR_TR_PredefinedNames(Predefined Names in AUTOSAR).pdf对基础软件标准规范文档的分类信息做出了介绍,其中常用的文档包括EXP、PRS、RS、SR…

【C++】类和对象(中)---取地址及const取地址操作符重载、const成员函数的使用
个人主页:平行线也会相交💪 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【C之路】💌 本专栏旨在记录C的学习路线,望对大家有所帮助🙇 希望我们一起努力、成长&…
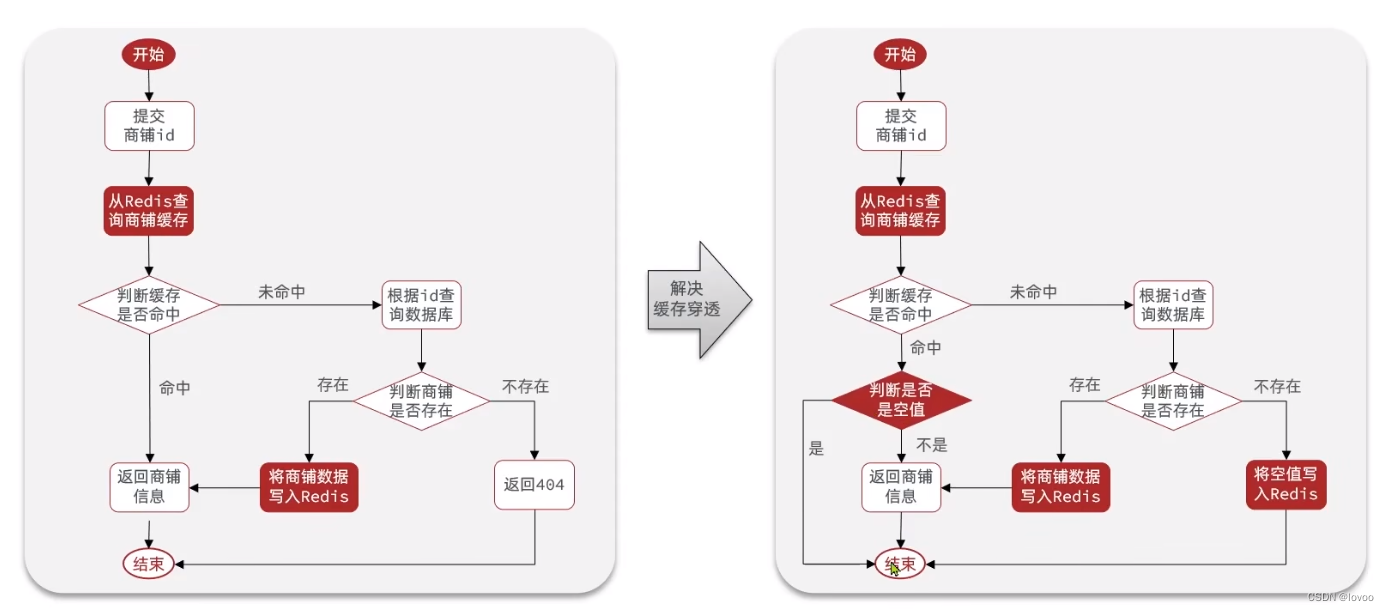
缓存穿透的解决办法有哪些?
一、概述
缓存穿透是指查询一个不存在的数据,由于缓存和数据库都没有命中,导致每次请求都需要从数据库中读取数据,增加了数据库的负担。解决缓存穿透的方法有以下几种: 布隆过滤器(Bloom Filter):使用位数组来表示一个集合&#…
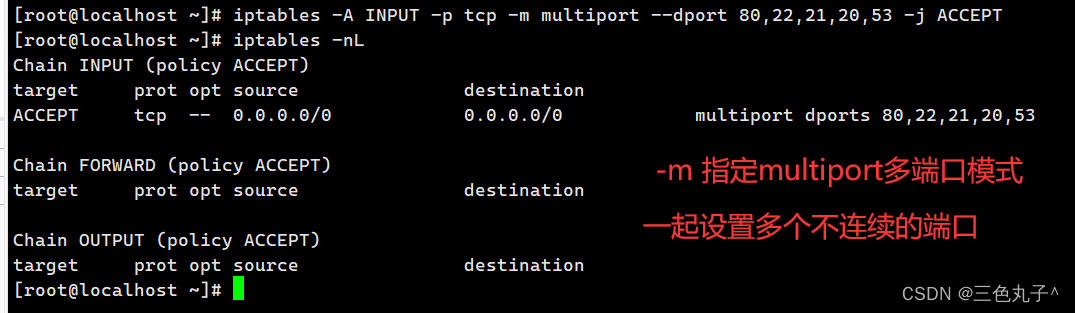
iptables防火墙概念
iptables防火墙 一、iptables概述1.netfilter 与 iptables 的关系1)netfilter2)iptables 2.四表五链1)四表2)五链3)表的匹配优先级4)规则链之间的匹配顺序5)规则链内的匹配顺序 二、iptables防火…
国外大神用 ChatGPT 成功打造一个「虚拟空间传送」系统!
公众号关注 “GitHubDaily” 设为 “星标”,每天带你逛 GitHub! 相信大家小时候躺在床上,都曾设想过这么一个场景: 当你闭上眼睛时,感觉身心十分安宁,物理世界慢慢淡出,身体也随着变得飘逸&…

【mysql】explain执行计划之select_type列
目录 一、说明二、示例2.1 simple:简单表,不使用union或者子查询2.2 primary:主查询,外层的查询2.3 subquery:select、where之后包含了子查询,在select语句中出现的子查询语句,结果不依赖于外部…

5.21下周黄金走势分析及开盘独家交易策略
近期有哪些消息面影响黄金走势?下周黄金多空该如何研判?
黄金消息面解析:周五(5月19日)美市尾盘,现货黄金收报1977.54美元/盎司,大幅上升19.99美元或1.02%,日内最高触及1984.22美元/盎司,最低…

【LeetCode: 10. 正则表达式匹配 | 暴力递归=>记忆化搜索=>动态规划 】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…
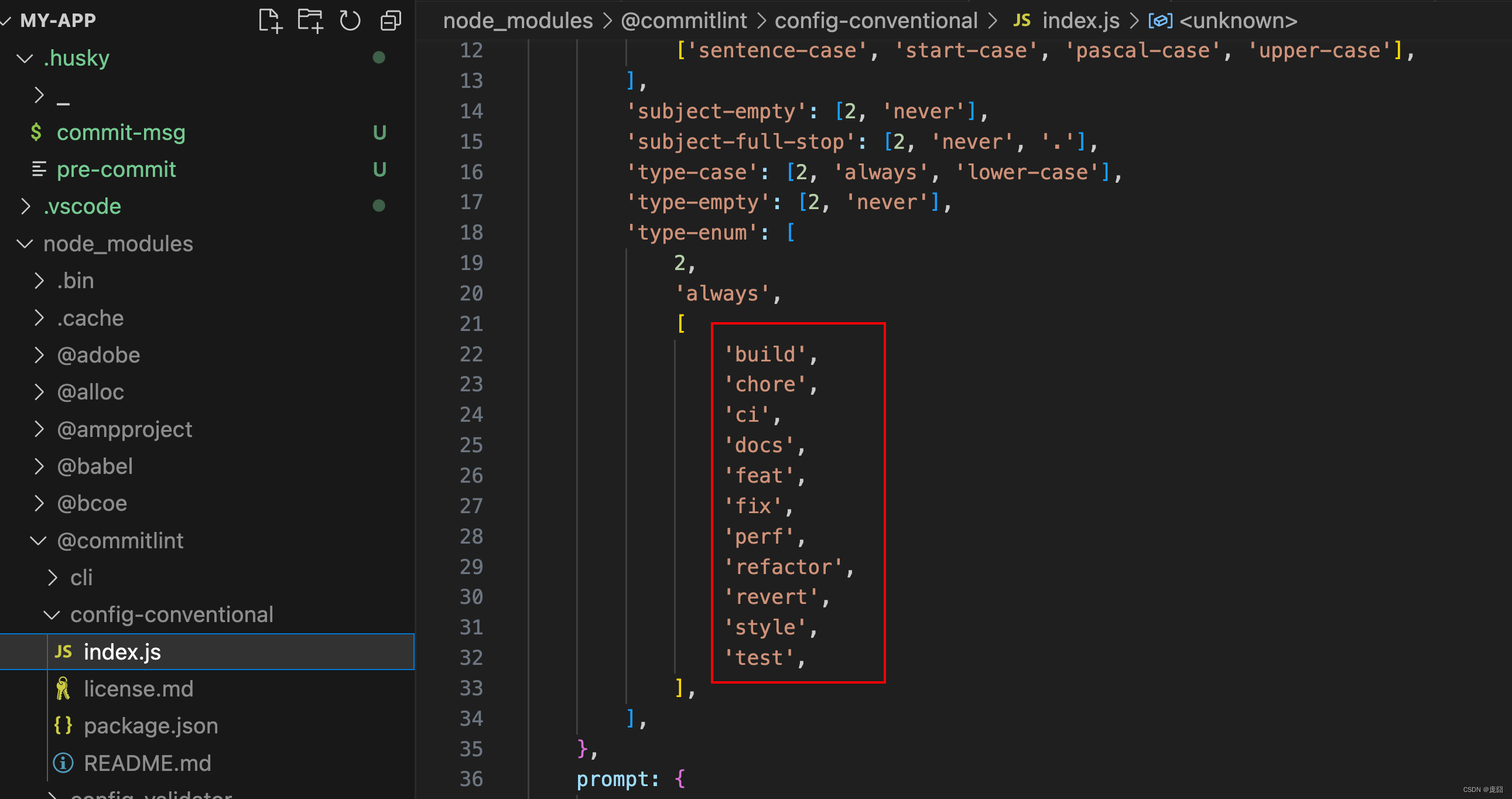
【工程化】记录在react工程中eslint、prettier等formatter以及git提交等规范的知识点
文章目录 前言创建eslint安装prettier安装.eslintrc.js完善独立的vscode设置到这一步要重启vscodehuskycommit-lint一切准备就绪,开干! 前言
由于使用ACR的方式创建react工程时,并不会像vue一样有每一步的安装提示,需要我们在创建…
用爬虫分析沪深300指数超长走势
我们知道,一个股市里面有非常多的股票,我们如何能够量化整个股市整体的行情呢,答案是通过一些综合性的指数。本文所选用的沪深300就是这类指数中的一个。我们先来看一下百度百科对于沪深300的解释。 由于股票价格起伏无常, 投资者…
跟姥爷深度学习6 卷积网络的数学计算
一、前言
前面简单用TensorFlow的全连接网络做了气温预测然后深入了解了一下全连接网络的数学计算,接着用CNN(卷积)网络做了手写数字识别,本篇就接着这个节奏来看卷积网络的数学计算。
二、卷积网络回顾
前面我们使用卷积网络时…
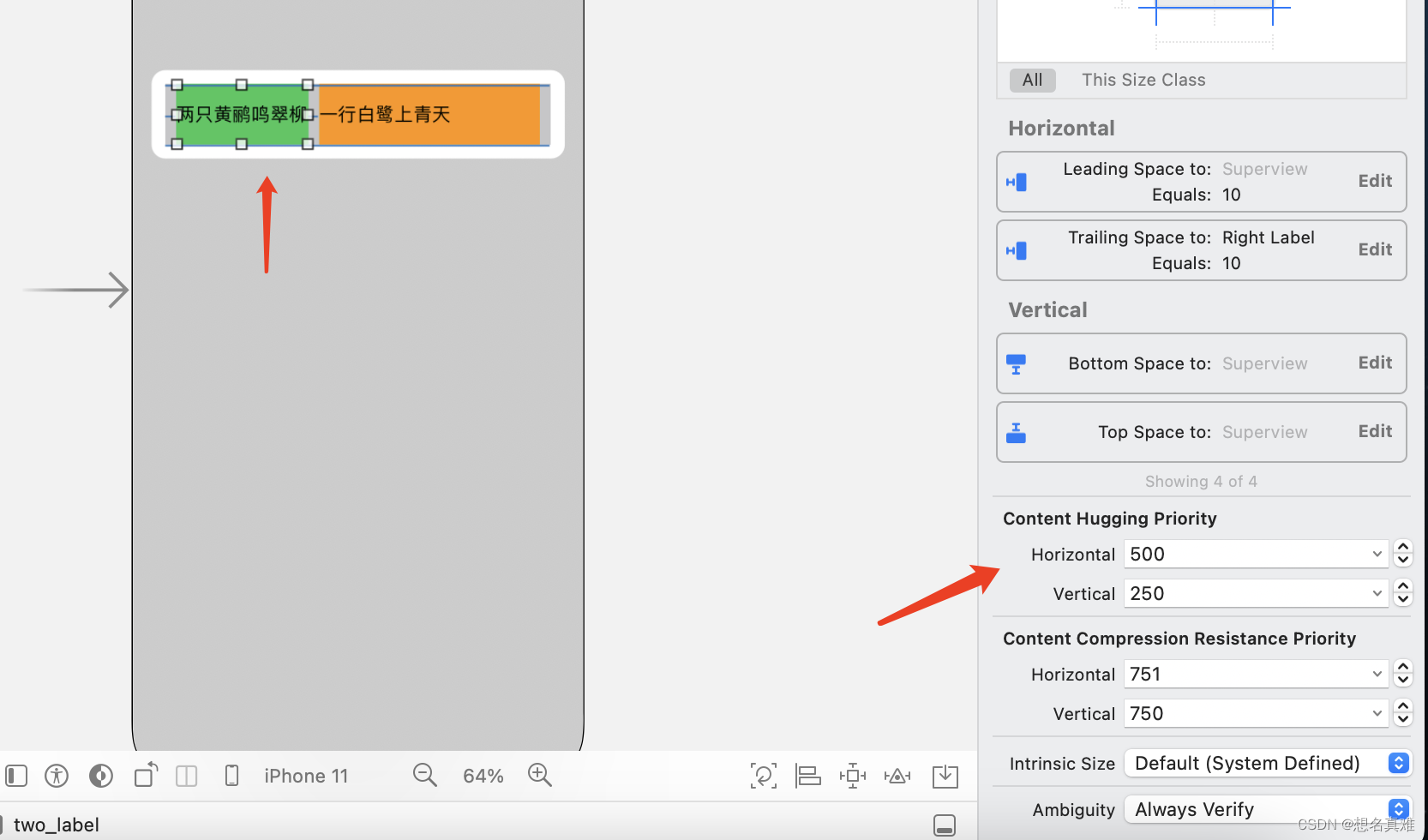
setContentHuggingPriority和setContentCompressionResistancePriority的使用
需求:
两个label并排显示,文字内容由服务器返回,label宽度以文字内容自适应,label之间间距大于等于10. 需要考虑以下情况:
当两个label的宽度和 < 屏幕宽度时,各自设置约束,无需处理&#…
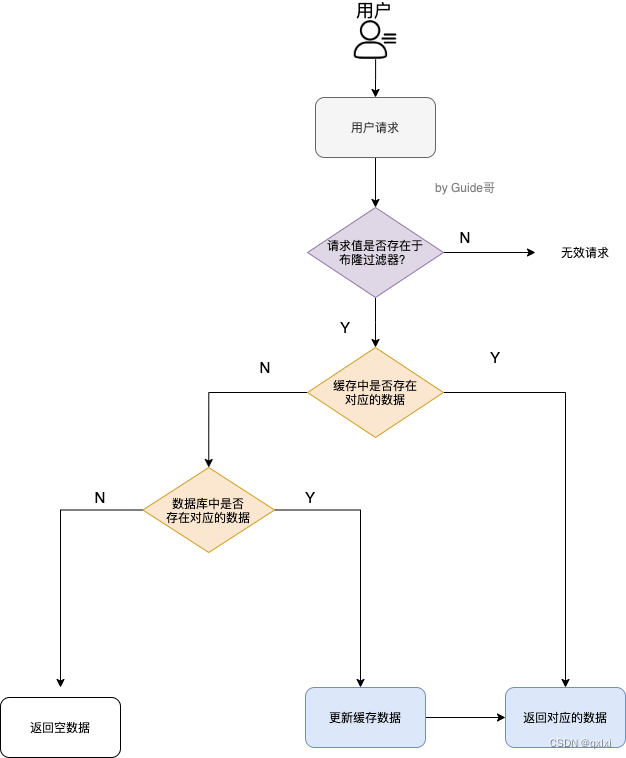
【数据结构】Bloom Filter 布隆过滤器
背景
在分布式系统中,比如缓存Redis中,当出现缓存击穿问题,同时访问缓存和数据库都查询不到数据时,对缓存和数据库压力比较大,那么有没有好的数据结构可以快速查询一个数据是否在数据库中,而这个就是大名鼎…
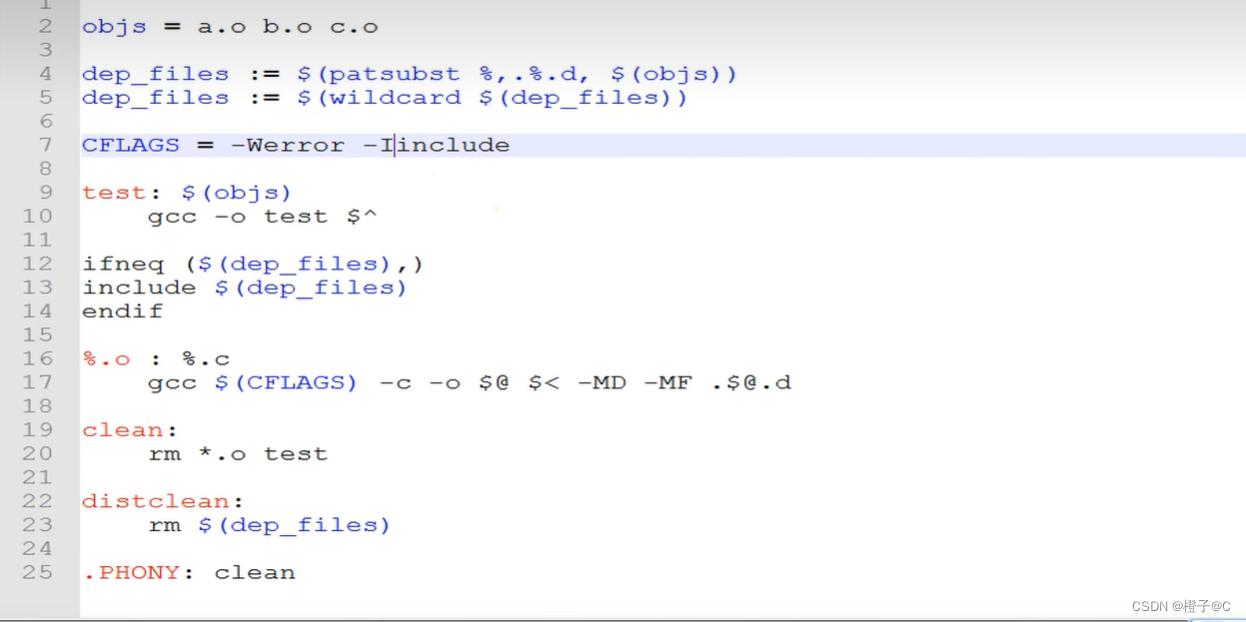
韦东山驱动大全:第四篇 基础-Makefile
1、mount -t nfs -o nolock,vers3 192.168.1.137:/home/book/nfs_rootfs(服务器目录) /mnt(板子目录) 2、gcc -o hello hello.c -v
3、 4、

golang 微服务中的断路器 hystrix
之前说到过微服务容错处理,可以使用 断路器
使用断路器的原因是:
当下游的服务因为过载或故障,无法提供服务,我们需要及时的让上游服务知悉,且暂时 熔断 调用方和提供方的调用链,这是为了避免服务雪崩现象…