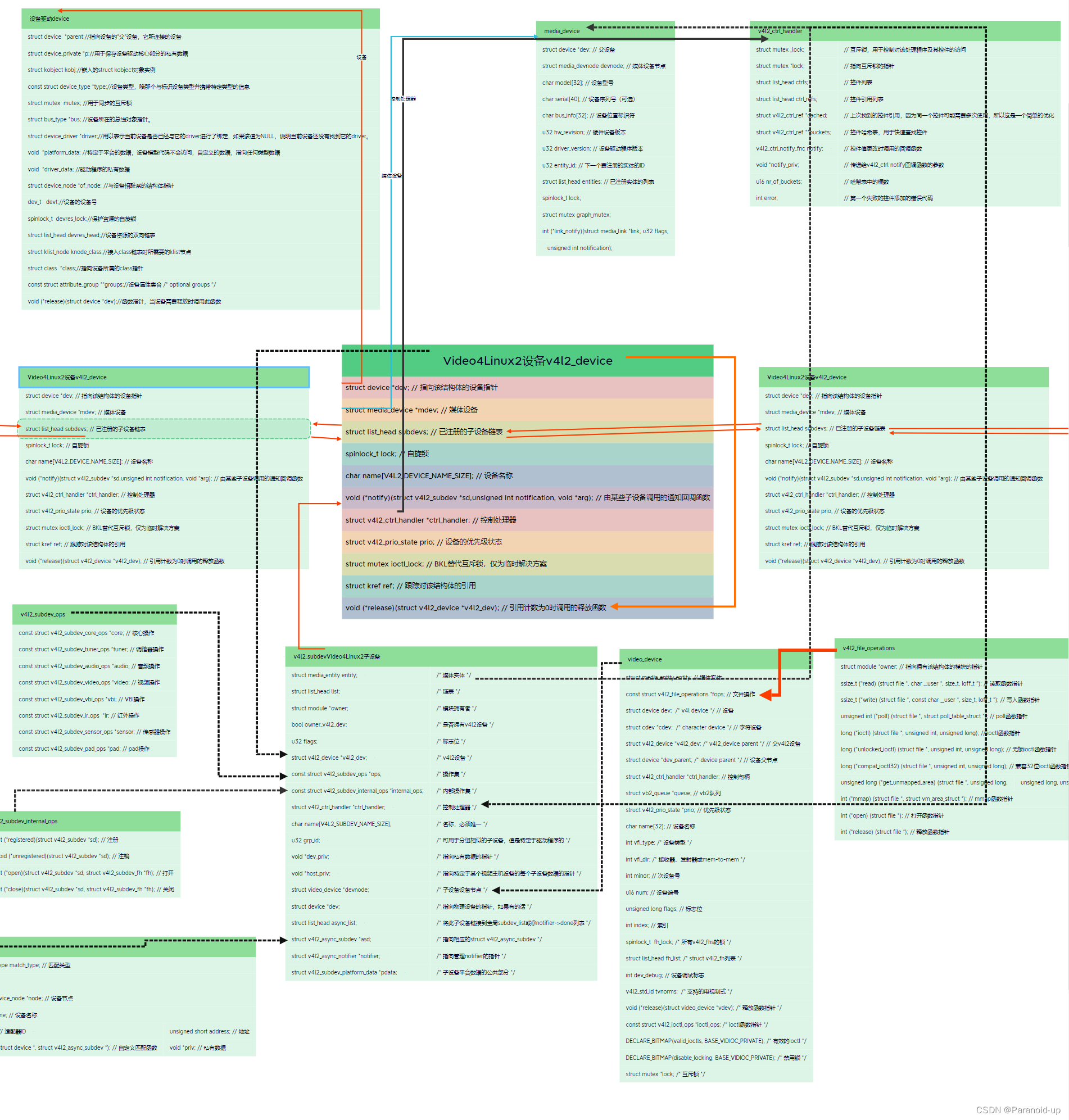
背景
在分布式系统中,比如缓存Redis中,当出现缓存击穿问题,同时访问缓存和数据库都查询不到数据时,对缓存和数据库压力比较大,那么有没有好的数据结构可以快速查询一个数据是否在数据库中,而这个就是大名鼎鼎的布隆过滤器。核心就是通过判断一个数据是否存在。以及在面试的时候,如果面试官问怎么查询在50亿个电话号码中,现有的10万个电话号码,黑名单校验,安全连接网址的判断等,这个时候就需要使用布隆过滤器。
原理
这里我们考虑一下,如果使用链表 O(N)、二叉树O(logn)、哈希表 O(1) 判断一个元素是否存在是否可以,答案是可以,但是当数据量过大时,本身这些数据结构就需要随着数据量越来越大,存储空间也就越大,无法支持大数据量的快速检索。
核心原理
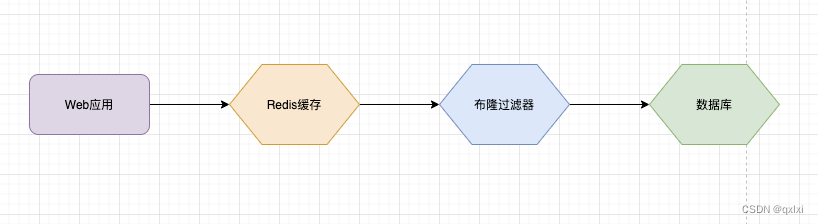
布隆过滤器由一个初始值为0的bit数组和N个哈希函数组成,可以用来快速判断某个数据是否存在。
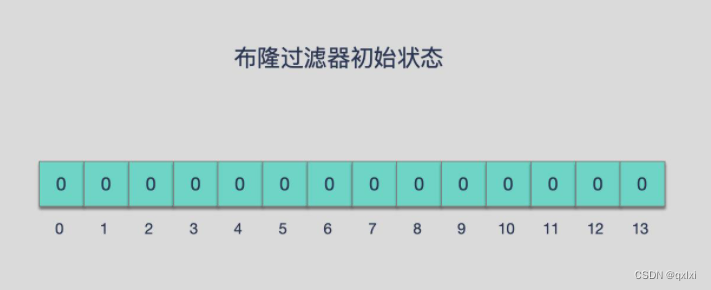
标记数据存在:
- 1.将数据通过N个哈希函数,计算出对应的Hash值
- 2.将对应的hash值对bit数组长度求余数
- 3.找到对应的数组余数,将对应位置设置为1
查询数据不存在
除了上述的1.2过程。会查询到对应的数组位置 如果全部为1,则数据可能存在DB中,如果有一个不为0,那么数据一定不存在。
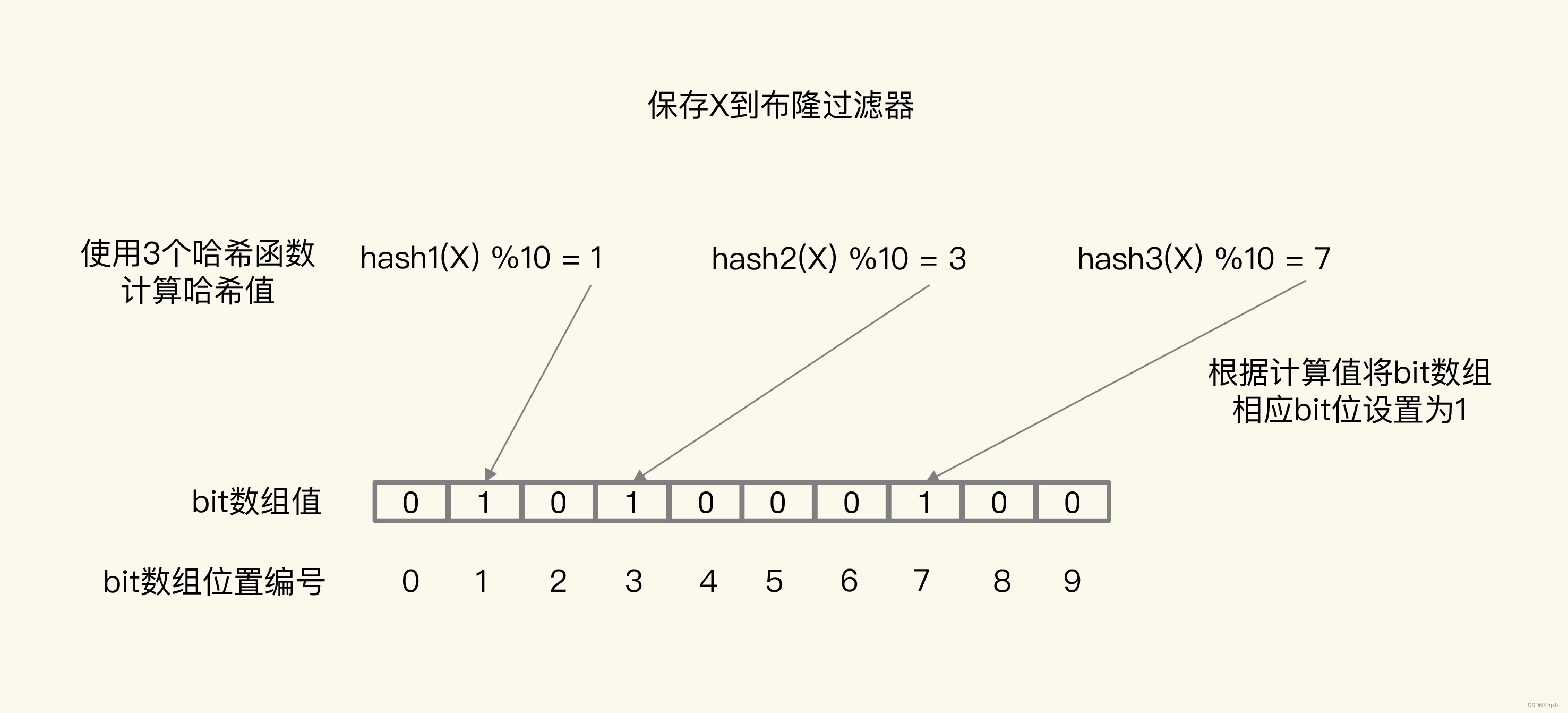
如上我们将X保存在bit数据中,计算出对应的1、3、7位置为1。当查询的时候如果1、3、7有一个不为1,那么数据一定不存在。
优点:空间效率和查询时间远远超过一般的算法。
缺点:在数据存在的情况下有一定的误识别率和删除困难。
这里重点说一下为什么不能删除数据,因为如果删除数据,可能会对已经存在的数据标记的1设置为0,那么如果请求过来这个数据判断数据是否存在数据不准确。
应用场景
1.Redis 缓存击穿
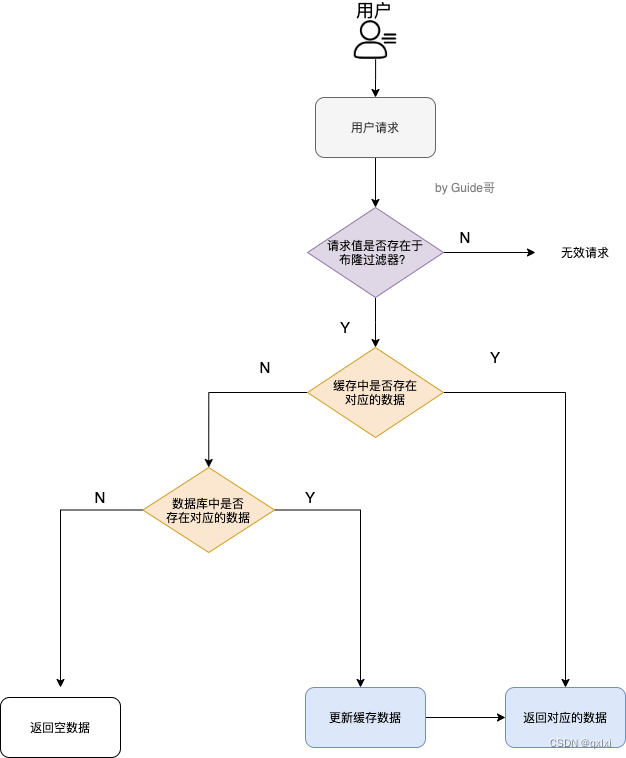
因为布隆过滤器高效的数据判断数据是否存在,所以可以在缓存或者数据库之前,先用布隆过滤器进行判断一下,如果数据存在,那么在请求,如果数据不存在的话,直接拦截请求。这样可以降低非法的数据访问,以及来降低缓存和数据库层的负载压力。
- 网页爬虫对URL的去重,避免爬取相同的URL地址
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱