文章目录
- 一、论文说明
- 二、前言
- 三、论文理解
- 四、实验
- 4.1 定性评估
- 4.2 定量评估
- 4.3 讨论
一、论文说明

2023年5月18日提交的论文,华人一作。
论文地址:
https://arxiv.org/pdf/2305.10973.pdf
项目地址:
https://vcai.mpi-inf.mpg.de/projects/DragGAN/

代码地址为:
https://github.com/XingangPan/DragGAN
具体代码将会在六月开源!
二、前言
在图像生成领域,以 Stable Diffusion 为代表的扩散模型已然成为当前占据主导地位的范式。但扩散模型依赖于迭代推理,这是一把双刃剑,因为迭代方法可以实现具有简单目标的稳定训练,但推理过程需要高昂的计算成本。
GAN(生成对抗网络)是一种深度学习模型,由生成器(Generator)和判别器(Discriminator)组成。GAN的目标是训练生成器来生成逼真的数据样本,同时训练判别器来区分生成器生成的样本和真实样本。
生成器和判别器通过对抗的方式进行训练。生成器的任务是将随机噪声作为输入,生成与真实样本相似的数据样本。判别器的任务是对给定的样本进行分类,判断它是生成器生成的假样本还是真实样本。随着训练的进行,生成器逐渐学习生成更逼真的样本,而判别器逐渐学习更准确地区分真实样本和生成样本。
GAN的核心思想是通过两个网络之间的对抗来推动模型的学习。生成器和判别器相互竞争,驱使彼此不断提高,从而达到生成逼真样本的目的。生成器试图通过欺骗判别器来生成更真实的样本,而判别器则试图通过准确地判断样本的真实性来区分生成样本和真实样本。
GAN的应用非常广泛,包括图像生成、图像修复、图像转换、语音合成等。通过训练生成器生成逼真的图像,GAN可以用于生成艺术作品、虚拟场景和人物,甚至可以应用于视频游戏、虚拟现实和增强现实等领域。
然而,GAN的训练过程相对复杂且不稳定,需要合适的网络架构和超参数设置,以及大量的训练样本和计算资源。近年来,研究者们提出了许多改进的GAN模型,如条件GAN、Wasserstein GAN、CycleGAN等,以解决GAN训练过程中的一些问题和改进生成效果。
在 Stable Diffusion 之前,生成对抗网络(GAN)是图像生成模型中常用的基础架构。相比于扩散模型,GAN 通过单个前向传递生成图像,因此本质上是更高效的。但由于训练过程的不稳定性,扩展 GAN 需要仔细调整网络架构和训练因素。因此,GAN 方法很难扩展到非常复杂的数据集上,在实际应用方面,扩散模型比 GAN 方法更易于控制,这是 GAN 式微的原因之一。
当前,GAN 主要是通过手动注释训练数据或先验 3D 模型来保证其可控性,这通常缺乏灵活性、精确性和通用性。然而,一些研究者看重 GAN 在图像生成上的高效性,做出了许多改进 GAN 的尝试。
来自马克斯・普朗克计算机科学研究所、MIT CSAIL 和谷歌的研究者们研究了一种控制 GAN 的新方法 DragGAN,能够让用户以交互的方式「拖动」图像的任何点精确到达目标点。
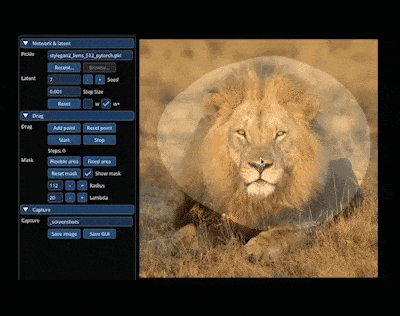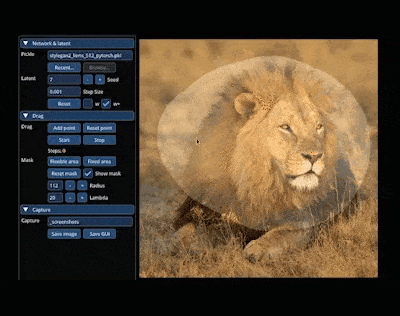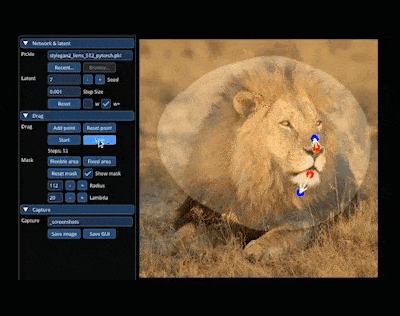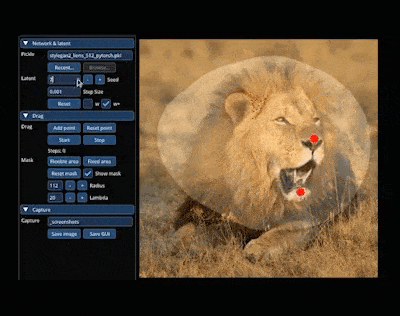
这种全新的控制方法非常灵活、强大且简单,有手就行,只需在图像上「拖动」想改变的位置点(操纵点),就能合成你想要的图像。
例如,让狮子「转头」并「开口」:
还能轻松让小猫 wink:
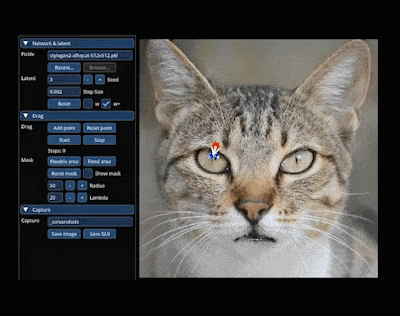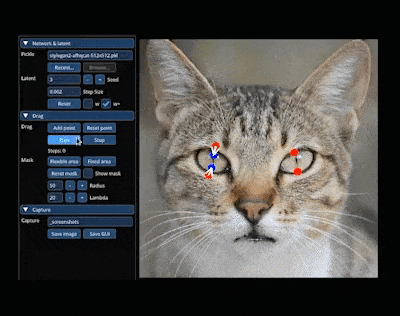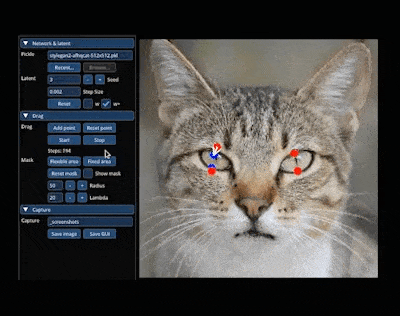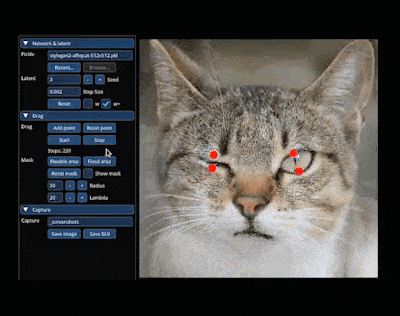
再比如,你可以通过拖动操纵点,让单手插兜的模特把手拿出来、改变站立姿势、短袖改长袖。
如果你也接到了「把大象转个身」的 P 图需求,不妨试试:
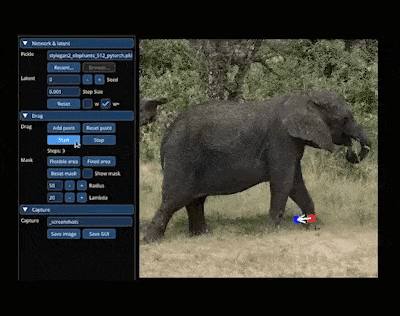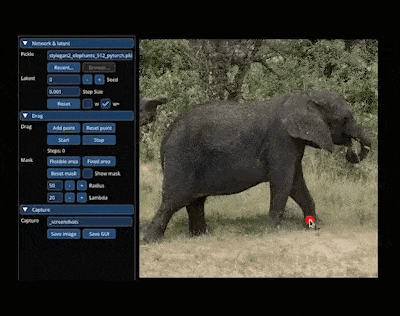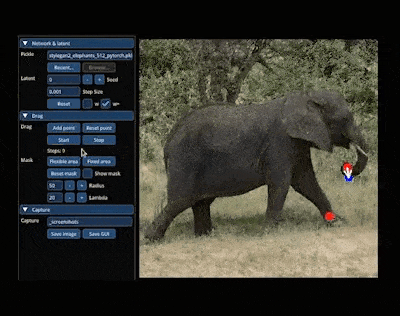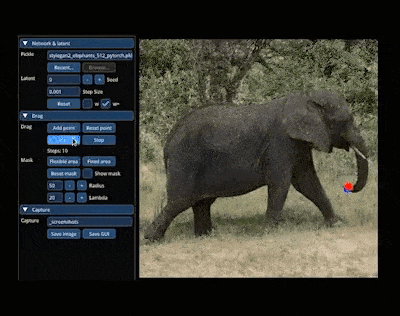
整个图像变换的过程就主打一个「简单灵活」,图像想怎么变就怎么变,因此有网友预言:「PS 似乎要过时了」。
更多示例请看:
https://vcai.mpi-inf.mpg.de/projects/DragGAN/
那么,DragGAN 是如何做到强大又灵活的?我们来看一下该研究的技术方法。
三、论文理解
该研究提出的 DragGAN 主要由两个部分组成,包括:
- 基于特征的运动监督,驱动图像中的操纵点向目标位置移动;
- 一种借助判别型 GAN 特征的操纵点跟踪方法,以控制点的位置。
第一部分理解:
这句话描述了一种基于特征的运动监督的方法,该方法用于驱动图像中的操纵点移动到目标位置。
首先,让我们理解一些关键术语:
- 特征:在图像中,特征可以是诸如边缘、角点、纹理等可识别的结构或模式。
- 操纵点:图像中的操纵点是用户定义或预先确定的位置点,可以是感兴趣区域的中心或其他关键点。
- 目标位置:在图像中,目标位置是操纵点所需移动到的位置,可以由用户指定或根据特定任务设定。
基于特征的运动监督方法的目标是通过分析图像中的特征,以监督并驱动操纵点从其当前位置移动到目标位置。这种方法通常包括以下步骤:
- 特征提取:从输入图像中提取出适合任务的特征。例如,可以使用计算机视觉技术(如边缘检测、角点检测、纹理特征提取等)来获取图像中的特征信息。
- 特征匹配:将当前图像中提取的特征与目标位置附近的特征进行匹配。这可以通过比较特征描述符或计算特征之间的相似性来实现。
- 运动估计:基于特征匹配的结果,估计操纵点需要移动的方向和距离。这可以通过计算操纵点与目标位置之间的几何关系或使用光流估计等方法来实现。
- 操纵点更新:根据运动估计的结果,将操纵点移动一定距离或在特定方向上更新。这样,操纵点逐渐靠近目标位置。
- 迭代过程:重复进行上述步骤,直到操纵点达到目标位置或达到停止条件。
通过这种基于特征的运动监督方法,可以实现对图像中的操纵点进行控制和驱动,使其按照预定的路径或目标位置移动。这种方法在许多计算机视觉和图像处理任务中具有广泛的应用,如目标跟踪、物体定位、图像配准等。
第二部分理解:
判别型生成对抗网络(Discriminative Generative Adversarial Networks,简称GAN)是一种深度学习模型,由生成器和判别器两个主要部分组成。生成器负责生成新样本,而判别器则负责区分生成的样本和真实的样本。
操纵点跟踪方法是指在一个给定的任务中,通过控制点的位置来实现目标控制或优化的方法。这种方法可以用于图像处理、计算机视觉、机器人控制等领域。
在借助判别型GAN特征的操纵点跟踪方法中,可以理解为利用GAN模型中的判别器部分提取特征,并将这些特征应用于点跟踪任务中。具体来说,可以将生成器部分用于生成操纵点的位置或变换,并利用判别器部分来评估生成的点位置的合理性或真实性。
例如,在图像处理任务中,可以使用GAN模型来生成新的图像样本。然后,将这些生成的图像输入到判别器中,判断它们是否看起来像真实的图像。在操纵点跟踪任务中,可以将待跟踪的点作为生成器的输入,生成新的点位置,并通过判别器评估这些点位置是否合理。
这种方法的好处在于,通过借助GAN的生成器和判别器,可以融合生成和判别的能力来实现更准确的点跟踪。生成器可以提供丰富的样本变换能力,而判别器可以提供对生成的结果的评估和反馈,从而指导生成器的调整和优化。
总之,借助判别型GAN特征的操纵点跟踪方法是一种结合生成和判别能力的技术,通过控制点的位置来实现特定任务的方法。这种方法可以根据具体的任务需求进行调整和优化,从而达到更好的效果。
DragGAN 能够通过精确控制像素的位置对图像进行改变,可处理的图像类型包括动物、汽车、人类、风景等,涵盖大量物体姿态、形状、表情和布局,并且用户的操作方法简单通用。
GAN 有一个很大的优势是特征空间具有足够的判别力,可以实现运动监督(motion supervision)和精确的点跟踪。
具体来说,运动监督是通过优化潜在代码的移位特征 patch 损失来实现的。每个优化步骤都会导致操纵点更接近目标,然后通过特征空间中的最近邻搜索来执行点跟踪。重复此优化过程,直到操纵点达到目标。
DragGAN 还允许用户有选择地绘制感兴趣的区域以执行特定于区域的编辑。由于 DragGAN 不依赖任何额外的网络,因此它实现了高效的操作,大多数情况下在单个 RTX 3090 GPU 上只需要几秒钟就可以完成图像处理。这让 DragGAN 能够进行实时的交互式编辑,用户可以对图像进行多次变换更改,直到获得所需输出。
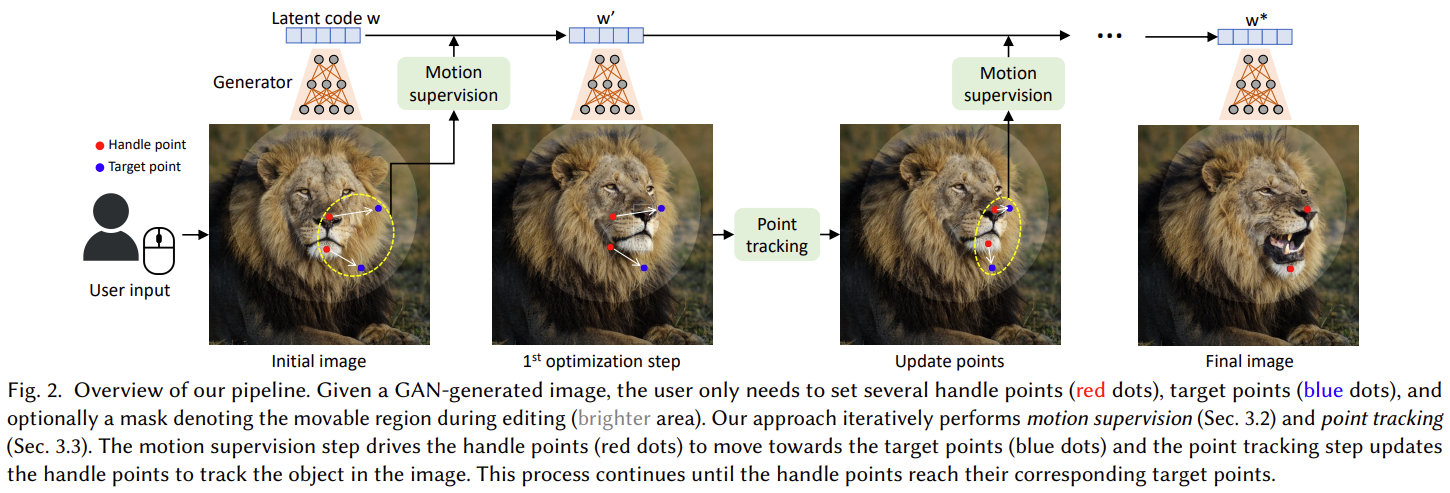
如下图所示,DragGAN 可以有效地将用户定义的操纵点移动到目标点,在许多目标类别中实现不同的操纵效果。与传统的形变方法不同的是,本文的变形是在 GAN 学习的图像流形上进行的,它倾向于遵从底层的目标结构,而不是简单地应用扭曲。例如,该方法可以生成原本看不见的内容,如狮子嘴里的牙齿,并且可以按照物体的刚性进行变形,如马腿的弯曲。


此外,通过与 GAN 反转技术相结合,本文方法还可以作为一个用于真实图像编辑的工具。
一个非常实用的用途是,即使合影中某些同学的表情管理不过关,你也可以为 Ta 换上自信的笑容:

顺便提一句,这张照片正是本篇论文的一作潘新钢,2021 年在香港中文大学多媒体实验室获得博士学位,师从汤晓鸥教授。目前是马克斯普朗克信息学研究所博士后,并将从 2023 年 6 月开始担任南洋理工大学计算机科学与工程学院 MMLab 的任助理教授。
这项工作旨在为 GAN 开发一种交互式的图像操作方法,用户只需要点击图像来定义一些对(操纵点,目标点),并驱动操纵点到达其对应的目标点。
这项研究基于 StyleGAN2,基本架构如下:
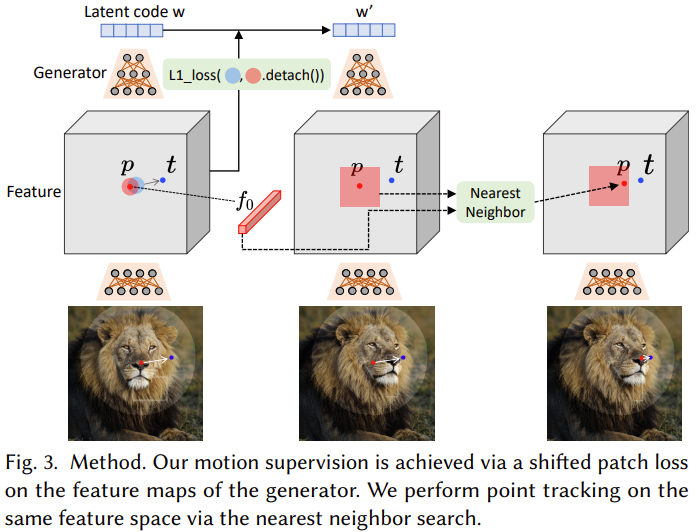
在 StyleGAN2 架构中,一个 512 维的潜在代码𝒛∈N(0,𝑰)通过一个映射网络被映射到一个中间潜在代码𝒘∈ R 512 \R^{512} R512 中。𝒘的空间通常被称为 W。然后,𝒘被送到生成器𝐺,产生输出图像 I = 𝐺(𝒘)。在这个过程中,𝒘被复制了几次,并被送到发生器𝐺的不同层,以控制不同的属性水平。另外,也可以对不同层使用不同的𝒘,在这种情况下,输入将是 ω ∈ R l × 512 = ω + \omega \in \R^{l \times 512} = \omega^{+} ω∈Rl×512=ω+,其中𝑙是层数。这种不太受约束的 ω + \omega^{+} ω+ 空间被证明是更有表现力的。由于生成器𝐺学习了从低维潜在空间到高维图像空间的映射,它可以被看作是对图像流形的建模。
四、实验
为了展示 DragGAN 在图像处理方面的强大能力,该研究展开了定性实验、定量实验和消融实验。实验结果表明 DragGAN 在图像处理和点跟踪任务中均优于已有方法。
4.1 定性评估
下图是本文方法和 UserControllableLT 之间的定性比较,展示了几个不同物体类别和用户输入的图像操纵结果。本文方法能够准确地移动操纵点以到达目标点,实现了多样化和自然的操纵效果,如改变动物的姿势、汽车形状和景观布局。相比之下,UserControllableLT 不能忠实地将操纵点移动到目标点上,往往会导致图像中出现不想要的变化。

如下图所示,它也不能像本文方法那样保持未遮盖区域固定不变。


下图提供了与 PIPs 和 RAFT 之间的比较,本文方法准确地跟踪了狮子鼻子上方的操纵点,从而成功地将它拖到了目标位置:

真实图像编辑。使用 GAN inversion 技术,将真实图像嵌入 StyleGAN 的潜空间,本文方法也可以用来操作真实图像。
其他图像案例请详细看论文!
4.2 定量评估
研究者在两种设置中下对该方法进行了定量评估,包括人脸标记点操作和成对图像重建。
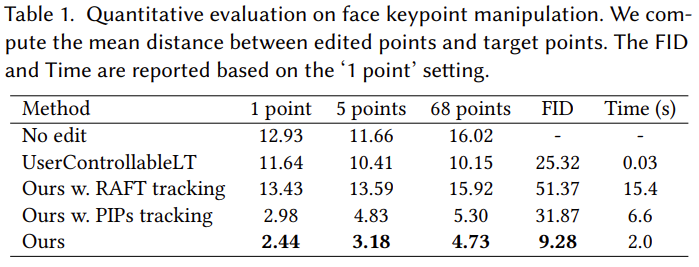
人脸标记点操作。如表 1 所示,在不同的点数下,本文方法明显优于 UserControllableLT。特别是,本文方法保留了更好的图像质量,正如表中的 FID 得分所示。
这种对比在下图中可以明显看出来,本文方法打开了嘴巴并调整下巴的形状以匹配目标脸,而 UserControllableLT 未能做到这一点。

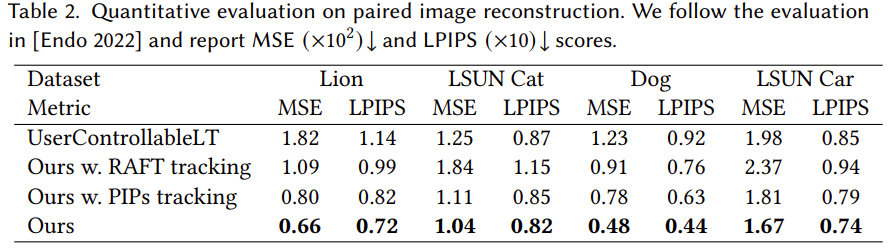
成对图像重建。如表 2 所示,本文方法在不同的目标类别中优于所有基线。
4.3 讨论
掩码的影响。本文方法允许用户输入一个表示可移动区域的二进制掩码,图 8 展示了它的效果:

Out-of-distribution 操作。从图 9 可以看出,本文的方法具有一定的 out-of-distribution 能力,可以创造出训练图像分布之外的图像,例如一个极度张开的嘴和一个大的车轮。

研究者同样指出了本文方法现存的局限性:尽管有一些推断能力,其编辑质量仍然受到训练数据多样性的影响。
如图 14(a)所示,创建一个偏离训练分布的人体姿势会导致伪影。
此外,如图 14(b)和(c)所示,无纹理区域的操纵点有时会在追踪中出现更多的漂移。因此,研究者建议尽可能挑选纹理丰富的操纵点。