什么是子事务?
一般事务只能整体提交或回滚,而子事务允许部分事务回滚。
SAVEPOINT p1 在事务里面打上保存点标记。不能直接提交子事务,子事务也是通过事务的提交而提交。不过可以通过ROLLBACK TO SAVEPOINT p1回滚到该保存点。
子事务在大批量数据写入的时候很有用。如果事务中存在多个子事务,而其中一小段子事务失败,只需要重做这小部分数据就行,而不需要整个事务数据全部重做。
子事务在SQL语句中的使用
SAVEPOINT savepoint_name
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
RELEASE [ SAVEPOINT ] savepoint_name
注意:
- savepoints语句必须在事务块中
- savepoint执行保存点;rollback回滚到指定保存点;release擦除保存点,不会回滚子事务数据
- cursor不会被savepoint事务影响
sql中的子事务示例:
lzldb=# begin;
BEGIN
lzldb=*# insert into lzl1 values(0);
INSERT 0 1
lzldb=*# savepoint p1;
SAVEPOINT
lzldb=*# insert into lzl1 values(1);
INSERT 0 1
lzldb=*# savepoint p2;
SAVEPOINT
lzldb=*# insert into lzl1 values(2);
INSERT 0 1
lzldb=*# savepoint p3;
SAVEPOINT
lzldb=*# insert into lzl1 values(3);
INSERT 0 1
lzldb=*# rollback to savepoint p2;
ROLLBACK
lzldb=*# commit;
COMMIT
lzldb=# select xmin,xmax,cmin,a from lzl1;
xmin | xmax | cmin | a
------+------+------+---
731 | 0 | 0 | 0
732 | 0 | 1 | 1
(2 rows)
--回滚到p2时,p3也被回滚
lzldb=# select * from vlzl1;
t_ctid | lp | lp_flags | t_xmin | t_xmax | t_cid | raw_flags | combined_flags
--------+----+-----------+--------+--------+-------+------------------------------------------------------+----------------
(0,1) | 1 | LP_NORMAL | 731 | 0 | 0 | {HEAP_HASNULL,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
(0,2) | 2 | LP_NORMAL | 732 | 0 | 1 | {HEAP_HASNULL,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
(0,3) | 3 | LP_NORMAL | 733 | 0 | 2 | {HEAP_HASNULL,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(0,4) | 4 | LP_NORMAL | 734 | 0 | 3 | {HEAP_HASNULL,HEAP_XMIN_INVALID,HEAP_XMAX_INVALID} | {}
(4 rows)
--子事务infomask跟一般事务区别不大,同一个事务中多个命令通过cid和HEAP_XMIN_INVALID等就可以判断可见性
--子事务产生写入同样会消耗transaction id,而且cid在父事务框架下增加
其他场景中产生子事务
即使不用savepoint,也有其他方法产生子事务
EXCEPTION语句会触发子事务,这在一些工具或架构中常见,也很容易被忽略。每次EXCEPTION都会产生一个子事务。
语法如:BEGIN / EXCEPTION WHEN .. / END
参考:https://fluca1978.github.io/2020/02/05/PLPGSQLExceptions.html
- PL/Python代码引用plpy.subtransaction()
子事务SLRU缓存
子事务提交日志在pg_xact,父子对应关系在pg_subtrans存储子事务缓存subXID和父XID的映射。当PostgreSQL需要查找subXID时,它会计算这个ID驻留在哪个内存页中,然后在内存页中进行搜索。如果页面不在缓存中,它会驱逐一个页面,并将所需的页面从pg_subtrans加载到内存中。大量的子事务cache miss会消耗系统的IO和cpu。
子事务用的buffer只有32个并在源码中写死
源码src/include/access/subtrans.h
/* Number of SLRU buffers to use for subtrans */
\#define NUM_SUBTRANS_BUFFERS 32
buffer默认为8k,xid是32位占4个bytes,所以
SUBTRANS_BUFFER大小为32*8k=256k
SUBTRANS_BUFFER能存储最多32*8k/4=65536个xid

通过transactionid找到子事务的在page中的位置
源码src/backend/access/transam/subtrans.c
/* We need four bytes per xact */
#define SUBTRANS_XACTS_PER_PAGE (BLCKSZ / sizeof(TransactionId))
//每个页面最多存储8k/4bytes=2048个子事务id
#define TransactionIdToPage(xid) ((xid) / (TransactionId) SUBTRANS_XACTS_PER_PAGE)
//通过子事务xid计算page号=xid/2048
#define TransactionIdToEntry(xid) ((xid) % (TransactionId) SUBTRANS_XACTS_PER_PAGE)
//通过子事务xid计算在page中的offset=xid%2048
子事务xid在page中不一定是紧凑的,一个page可能少于2048个子事务id
子事务的危害
- PGPROC_MAX_CACHED_SUBXIDS溢出
PGPROC_MAX_CACHED_SUBXIDS不是GUI参数,在源码中写死,只能通过改源码修改该参数。
源码src/include/storage/proc.h
/*
*每个backend都有子事务cache上限PGPROC_MAX_CACHED_SUBXIDS。
*我们必须跟踪cache是否溢出(比如,事务至少有一个缓存不了的子事务)
*如果一个cache都没有溢出,我们可以确认没有在pgproc array中xid一定不是一个运行中的事务。
*(没有在任何proc,又没有溢出,说明没有跑)
*如果有溢出,我们必须查看pg_subtrans
*/
#define PGPROC_MAX_CACHED_SUBXIDS 64 /* XXX guessed-at value */
struct XidCache
{
TransactionId xids[PGPROC_MAX_CACHED_SUBXIDS];
};
阅读这段源码,得到两个重要信息
- 每个backend都有子事务cache为
PGPROC_MAX_CACHED_SUBXIDS,固定64个子事务 - 超过64个子事务会溢出到
pg_subtrans目录
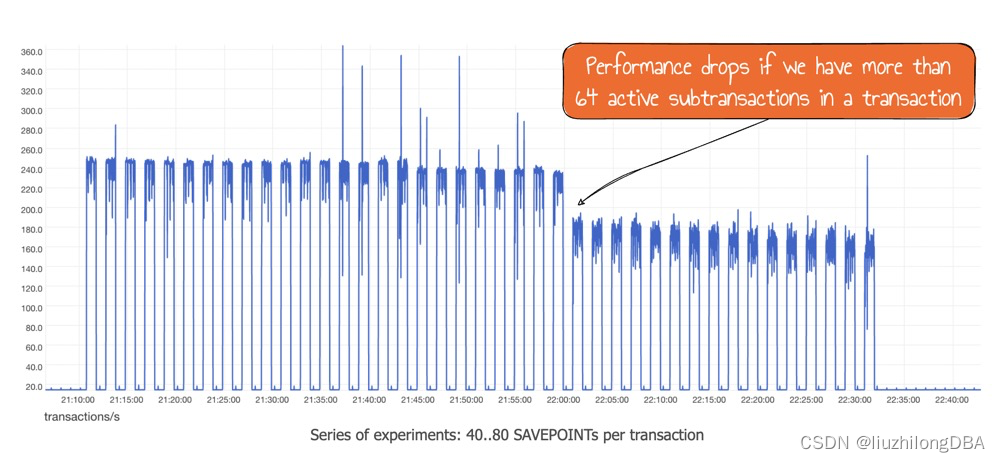
copy大佬压测:子事务刚好超过64个的时候,性能下降。所以,每个会话的子事务最好不要超过64个
- 子事务导致multixact异常等待
原文:https://buttondown.email/nelhage/archive/notes-on-some-postgresql-implementation-details/
for update本身是行级排他锁,本身不应该产生multixact id,但在此场景中产生了多个MultiXact等待,导致数据库性能断崖
- LWLock:MultiXactMemberControlLock
- LWLock:MultiXactOffsetControlLock
- LWLock:multixact_member
- LwLock:multixact_offset
后来发现在Django框架中有子事务语句
SELECT [some row] FOR UPDATE;
SAVEPOINT save;
UPDATE [the same row];
- 从库性能急剧下降
原文:https://about.gitlab.com/blog/2021/09/29/why-we-spent-the-last-month-eliminating-postgresql-subtransactions/
一个长事务和一个savepoint子事务也可能造成查询库性能断崖
如果读取发生在主库的快照上,则生成的快照包含xmin,xmax,txip事务列表,subxip保存一个在进行的子事务列表。但是,无论是原数组还是快照都不会直接与从库共享,从库从WAL中读取所需的所有数据。
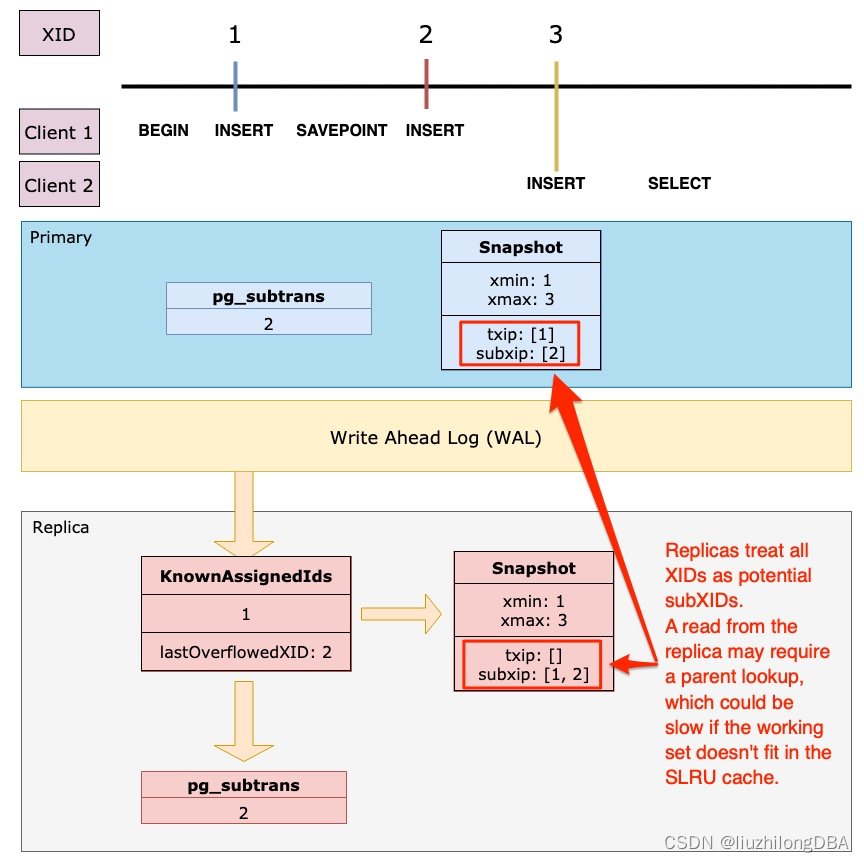
当存在子事务时,一个长事务的运行会使从库性能断崖式下滑
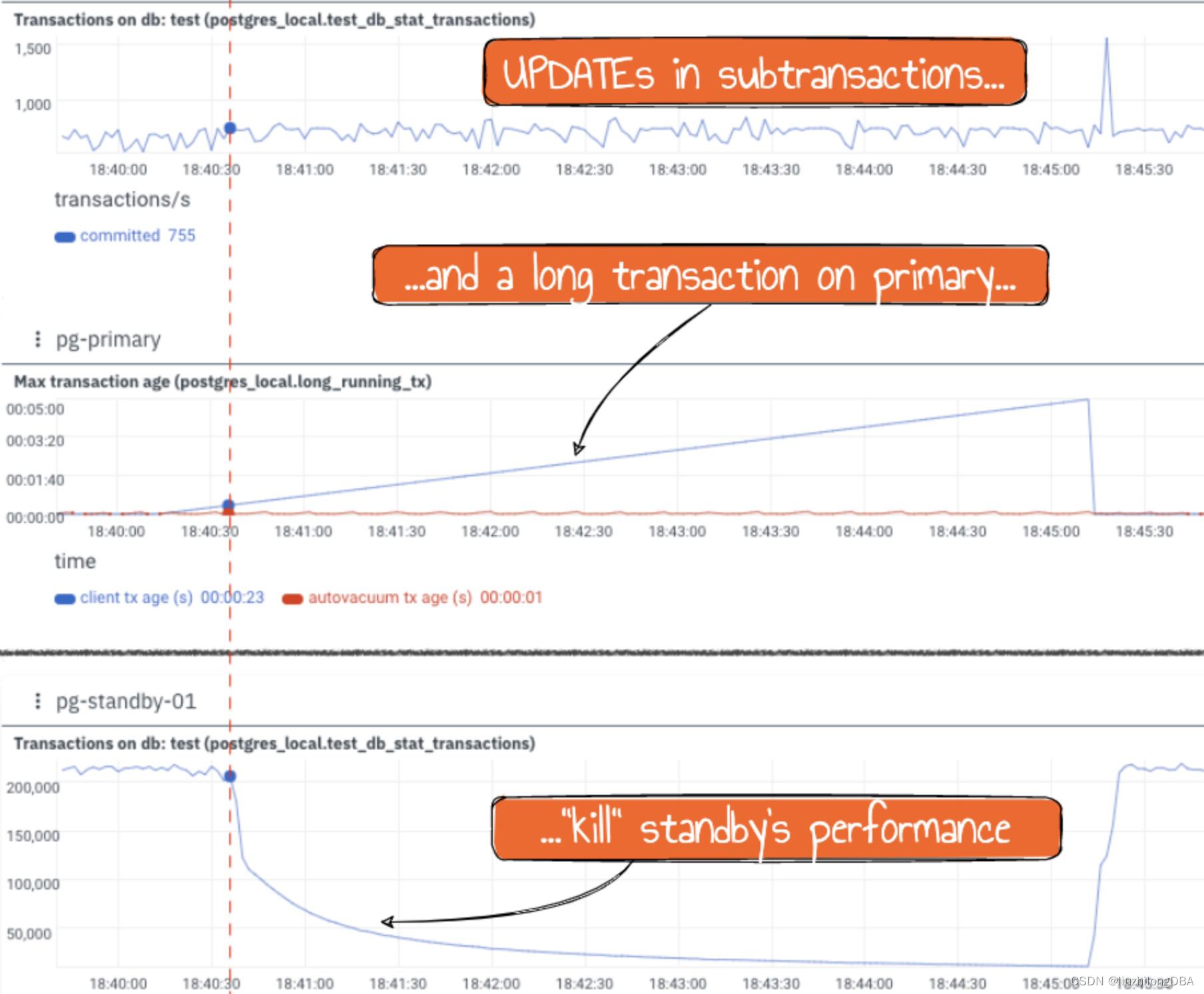
- 生产性能急剧下降
当数据库运行繁忙,又存在较多子事务时,性能可能急剧下降,并伴随子事务的等待事件。这个场景即使每个会话子事务没有超过64,而且不是在从库而是在主库上时,也会发生。
我们发现工具(OGG)中默认是50个子事务,此时我们将工具中的子事务数据量降低到10-20个时,数据库性能得到缓解。
子事务的使用建议
- 除了显示savepoint使用子事务,excetpion、框架、工具中同样会产生子事务
- 如果有从库查询业务,禁止使用子事务。
- 谨慎使用行锁。for update+子事务同样会引起multixactid的问题
- 如果仍有子事务,子事务设置不要超过64个,最好是更低
子事务已经在国内外生产环境造成了非常多问题,有许多案例和问题分析。引用一下“Subtransactions are basically cursed. Rip em out.”
子事务参考
https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
https://www.cybertec-postgresql.com/en/subtransactions-and-performance-in-postgresql/
https://fluca1978.github.io/2020/02/05/PLPGSQLExceptions.html
https://about.gitlab.com/blog/2021/09/29/why-we-spent-the-last-month-eliminating-postgresql-subtransactions/
https://buttondown.email/nelhage/archive/notes-on-some-postgresql-implementation-details/