Elasticsearch 集群配置版本均为8以上
安装前准备
CPU 2C 内存4G或更多
操作系统: Ubuntu20.04,Ubuntu18.04,Rocky8.X,Centos 7.X
操作系统盘50G
主机名设置规则为nodeX.qingtong.org
生产环境建议准备单独的数据磁盘
主机名
#各自服务器配置自己的主机名
hostnamectl set-hostname es-node1.qingtong.org
关闭防火墙和SELINUX
#RHEL系列的系统执行下以下配置
[root@es-node1 ~]# systemctl disable firewalld
[root@es-node1 ~]# systemctl disable NetworkManager
[root@es-node1 ~]# sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
[root@es-node1 ~]# reboot
服务器配置本地域名解析可以选择做也可以不做
优化资源限制配置
内核参数 vm.max_map_count 用于限制一个进程可以拥有的VMA(虚拟内存区域)的数量
使用默认系统配置,二进制安装时会提示下面错误,包安装会自动修改此配置
#查看默认值
[root@es-node1 ~]#sysctl -a |grep vm.max_map_count
vm.max_map_count = 65530
#修改配置
[root@es-node1 ~]#echo "vm.max_map_count = 262144" >> /etc/sysctl.conf
[root@es-node1 ~]#echo "fs.file-max = 1000000" >> /etc/sysctl.conf
[root@es-node1 ~]#sysctl -p
vm.max_map_count = 262144
修改资源限制配置
[root@es-node1 ~]#vi /etc/security/limits.conf
* soft core unlimited
* hard core unlimited
* soft nproc 1000000
* hard nproc 1000000
* soft nofile 1000000
* hard nofile 1000000
* soft memlock 32000
* hard memlock 32000
* soft msgqueue 8192000
* hard msgqueue 8192000
安装Java环境(可选)
Elasticsearch 是基于java的应用,所以依赖JDK环境
注意: 安装7.X以后版本官方建议要安装集成JDK的包,所以无需再专门安装 JDK
关于JDK环境说明
1.x 2.x 5.x 6.x都没有集成JDK的安装包,也就是需要自己安装java环境
7.x的安装包分为带JDK和不带JDK两种包,带JDK的包在安装时不需要再安装java,如果不带JDK的包仍然需要自己去安装java
8.x的安装包默认不区分带JDK和不带JDK,所以8版本此处忽略
官网JAVA版支持说明:
https://www.elastic.co/cn/support/matrix#matrix_jvm
Elasticsearch 安装
!!! 推荐7.x及以上版本安装,避免手动配置JAVA环境出错 !!!
官方下载地址:
https://www.elastic.co/cn/downloads/elasticsearch
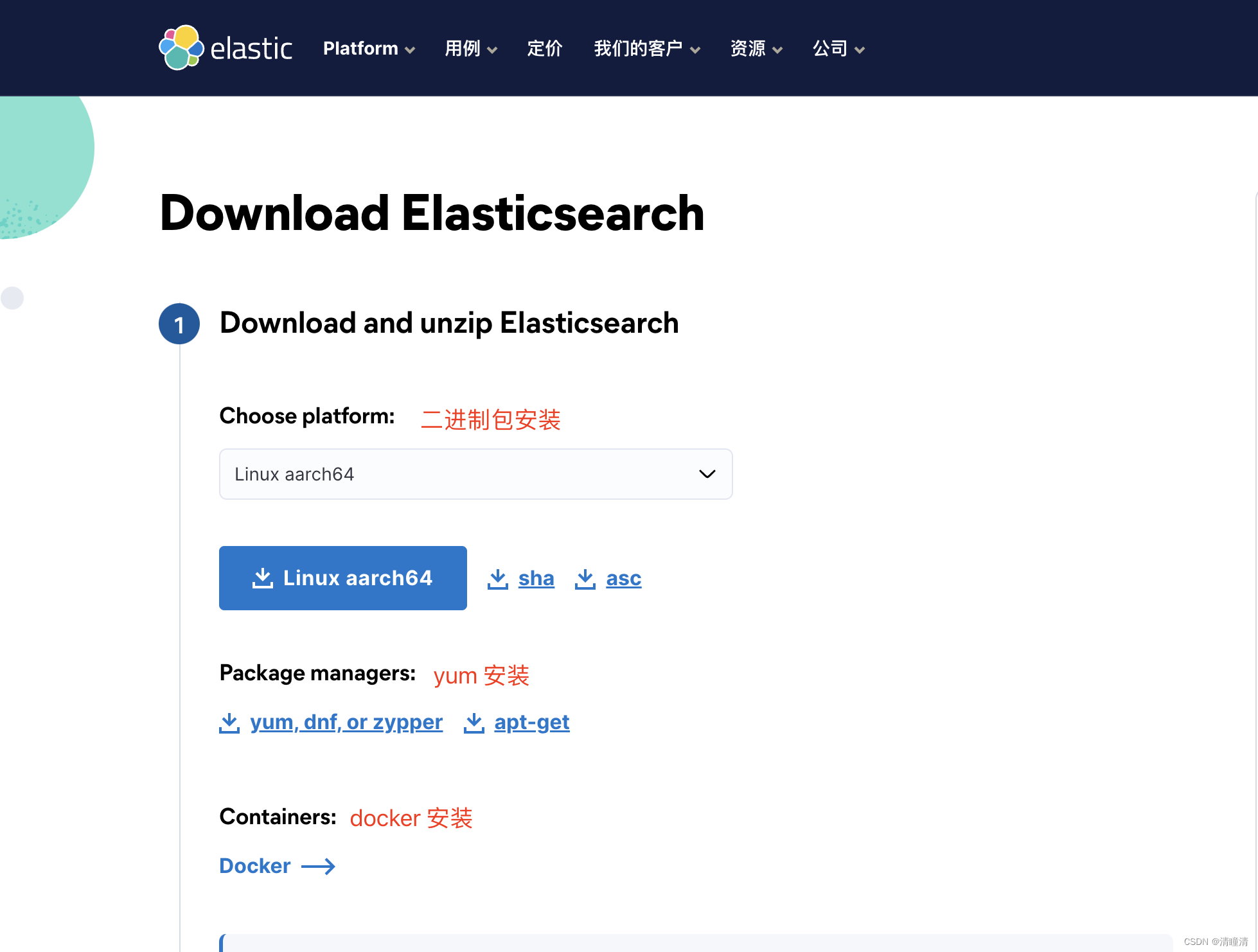
包安装
如果是 X86_64 版本可以考虑吧国内清华大学镜像源下载安装
https://mirrors.tuna.tsinghua.edu.cn/elasticstack/
# Centos安装
yum -y install elasticsearch-8.7.1-x86_64.rpm
# Ubuntu安装
dpkg -i elasticsearch-8.7.1-amd64.deb
如果是linux_arrch64 版本就设置官方的 yum 源来下载
https://www.elastic.co/guide/en/elasticsearch/reference/8.7/rpm.html#rpm-repo
按照官方的文档操作下载即可
1、下载并安装公共签名密钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2、手动创建 Elasticsearch.repo
cat << EOF > /etc/yum.repos.d/elasticsearch.repo
[elasticsearch]
name=Elasticsearch repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
EOF
3、安装
sudo yum install --enablerepo=elasticsearch elasticsearch
sudo dnf install --enablerepo=elasticsearch elasticsearch
二进制安装
官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/master/targz.html
下载二进制文件
https://www.elastic.co/cn/downloads/elasticsearch
范例:基于二进制包含JDK文件安装
1、下载解压安装包
[root@ubuntu1804 ~]#ls
elasticsearch-7.6.2-linux-x86_64.tar.gz
[root@ubuntu1804 ~]#tar xf elasticsearch-7.6.2-linux-x86_64.tar.gz -C
/usr/local/
[root@ubuntu1804 ~]#ls /usr/local/
bin elasticsearch-7.6.2 etc games include lib man sbin share src
[root@ubuntu1804 ~]#ln -s /usr/local/elasticsearch-7.6.2/
/usr/local/elasticsearch
[root@ubuntu1804 ~]#ls /usr/local/elasticsearch
bin config jdk lib LICENSE.txt logs modules NOTICE.txt plugins
README.asciidoc
2、编辑配置文件
编辑配置文件可参考下一个标题内的内容。8.X以下版本无需配置 Xpack
3、二进制安装需手动创建用户,在所有节点上创建用户
useradd -r elasticsearch
4、更改目录权限,配置方法参照下面
5、启动服务(在所有节点上配置)
[root@es-node1 ~]#echo 'PATH=/usr/local/elasticsearch/bin:$PATH' >
/etc/profile.d/elasticsearch.sh
[root@es-node1 ~]#. /etc/profile.d/elasticsearch.sh
[root@es-node1 ~]#tail -f /data/es-logs/es-cluster.log
#不能以root用户运行,切换用户
[root@es-node1 ~]#su - elasticsearch
6、验证端口
ss -ntl | grep java
7、创建service文件
[root@es-node1 ~]#cat /lib/systemd/system/elasticsearch.service
[Unit]
Description=Elasticsearch
Documentation=http://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
RuntimeDirectory=elasticsearch
PrivateTmp=true
Environment=PID_DIR=/var/run/elasticsearch
WorkingDirectory=/usr/local/elasticsearch
User=elasticsearch
Group=elasticsearch
ExecStart=/usr/local/elasticsearch/bin/elasticsearch -p
${PID_DIR}/elasticsearch.pid --quiet
# StandardOutput is configured to redirect to journalctl since
# some error messages may be logged in standard output before
# elasticsearch logging system is initialized. Elasticsearch
# stores its logs in /var/log/elasticsearch and does not use
# journalctl by default. If you also want to enable journalctl
# logging, you can simply remove the "quiet" option from ExecStart.
# Specifies the maximum file descriptor number that can be opened by this
process
LimitNOFILE=65535
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
# Built for packages-7.6.2 (packages)
[root@es-node1 ~]#systemctl daemon-reload
[root@es-node1 ~]#systemctl enable --now elasticsearch.service
基于docker部署
官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/docker.html
单节点部署
[root@ubuntu1804 ~]#docker run --name es-single-node -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.6.2
多节点集群部署
注意:此方式需要3G以上的内存,否则会出现OOM的告警
创建docker-compose.yml 文件
[root@ubuntu1804 ~]#cat docker-compose.yml
version: '2.2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
启动集群
[root@ubuntu1804 ~]#docker-compose up -d
编辑服务配置文件
配置文件说明
[root@es-node1 ~]# grep -Ev '#|^$'/etc/elasticsearch/elasticsearch.yml
#ELK集群名称,同一个集群内每个节点的此项必须相同,新加集群的节点此项和其它节点相同即可加入集群,而
无需再验证
cluster.name: ELK-Cluster
#当前节点在集群内的节点名称,同一集群中每个节点要确保此名称唯一
node.name: es-node1
#ES 数据保存目录
path.data: /data/es-data
#ES 日志保存目录
path.logs: /data/es-logs
#服务启动的时候立即分配(锁定)足够的内存,防止数据写入swap,提高启动速度
bootstrap.memory_lock: true
#指定监听IP,如果绑定了错误的IP,可将此修改为指定IP
network.host: 0.0.0.0
#监听端口
http.port: 9200
#8.x版本的新特性 xpack认证
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
#发现集群的node节点列表,可以添加部分或全部节点IP
#在新增节点到集群时,此处需指定至少一个已经在集群中的节点地址
discovery.seed_hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"] #集群初始化时指定希望哪些节点可以被选举为 master,只在初始化时使用,新加节点到已有集群时此项可不
配置
cluster.initial_master_nodes: ["10.0.0.101","10.0.0.102","10.0.0.103"] #一个集群中的 N 个节点启动后,才允许进行数据恢复处理,默认是1,一般设为为所有节点的一半以上,防止
出现脑裂现象
#当集群无法启动时,可以将之修改为1,或者将下面行注释掉,实现快速恢复启动
gateway.recover_after_nodes: 2 #设置是否可以通过正则表达式或者_all匹配索引库进行删除或者关闭索引库,默认true表示必须需要明确指
定索引库名称,不能使用正则表达式和_all,生产环境建议设置为 true,防止误删索引库。
action.destructive_requires_name: true
#不参与主节点选举
node.master: false
#存储数据,此值为false则不存储数据而成为一个路由节点
#如果将true改为false,需要先执行/usr/share/elasticsearch/bin/elasticsearch-node
repurpose 清理数据
node.data: true
#7.x以后版本下面指令已废弃,在2.x 5.x 6.x 版本中用于配置节点发现列表
discovery.zen.ping.unicast.hosts: ["10.0.0.101", "10.0.0.102","10.0.0.103"]
单节点配置
[root@ubuntu2004 ~]#grep -v '#' /etc/elasticsearch/elasticsearch.yml
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
node.name: node-1
network.host: 0.0.0.0
discovery.seed_hosts: ["10.0.0.100"]
cluster.initial_master_nodes: ["node-1"]
集群配置
cluster.name: es-cluster
node.name: es-node1
path.data: /data/es-data
path.logs: /data/es-logs
xpack.security.enabled: false #建议关闭
xpack.security.enrollment.enabled: false #建议关闭
xpack.security.http.ssl:
enabled: false #建议关闭
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: false #建议关闭
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.31.14","192.168.31.178","192.168.31.184"]
cluster.initial_master_nodes: ["192.168.31.14","192.168.31.178","192.168.31.184"]
将配置同步至其他集群节点
[root@es-node1 ~]# scp /etc/elasticsearch/elasticsearch.yml esnode2:/etc/elasticsearch/
[root@es-node2 ~]#grep -v "#" /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster
node.name: es-node2 #只需修改次行,每个节点都不能相同
path.data: /data/es-data
path.logs: /data/es-logs
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:
enabled: false
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: false
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.31.14","192.168.31.178","192.168.31.184"]
cluster.initial_master_nodes: ["192.168.31.14","192.168.31.178","192.168.31.184"]
开启bootstrap.memory_lock: true 导致无法启动的错误解决方法
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/setupconfiguration-memory.html#bootstrap-memory_lock
https://www.elastic.co/guide/en/elasticsearch/reference/current/setting-systemsettings.html#systemd
解决办法:
[root@es-node1 ~]# vim /usr/lib/systemd/system/elasticsearch.service
LimitMEMLOCK=infinity
[root@node1 ~]#systemctl daemon-reload
[root@node1 ~]#systemctl restart elasticsearch.service
[root@node1 ~]#systemctl is-active elasticsearch.service
active
目录权限
在各个ES服务器创建数据和日志目录并修改目录权限为elasticsearch
#此步可选,可以不用创建下面目录es-data和es-logs,系统可以自动创建
[root@es-node1 ~]# mkdir -p /data/es-{data,logs}
[root@es-node1 ~]# ll /data/
total 0
drwxr-xr-x 2 root root 6 Apr 18 18:44 es-data
drwxr-xr-x 2 root root 6 Apr 18 18:44 es-logs
#必须分配权限,否则服务无法启动
[root@es-node1 ~]# chown -R elasticsearch.elasticsearch /data/
[root@es-node1 ~]# ll /data/
total 0
drwxr-xr-x 2 elasticsearch elasticsearch 6 Apr 18 18:44 es-data
drwxr-xr-x 2 elasticsearch elasticsearch 6 Apr 18 18:44 es-logs
启动Elasticsearch服务并验证
[root@es-node1 ~]#systemctl enable --now elasticsearch
验证端口监听成功
9200端口集群访问端口,9300集群同步端口

通过浏览器访问 Elasticsearch 服务端口
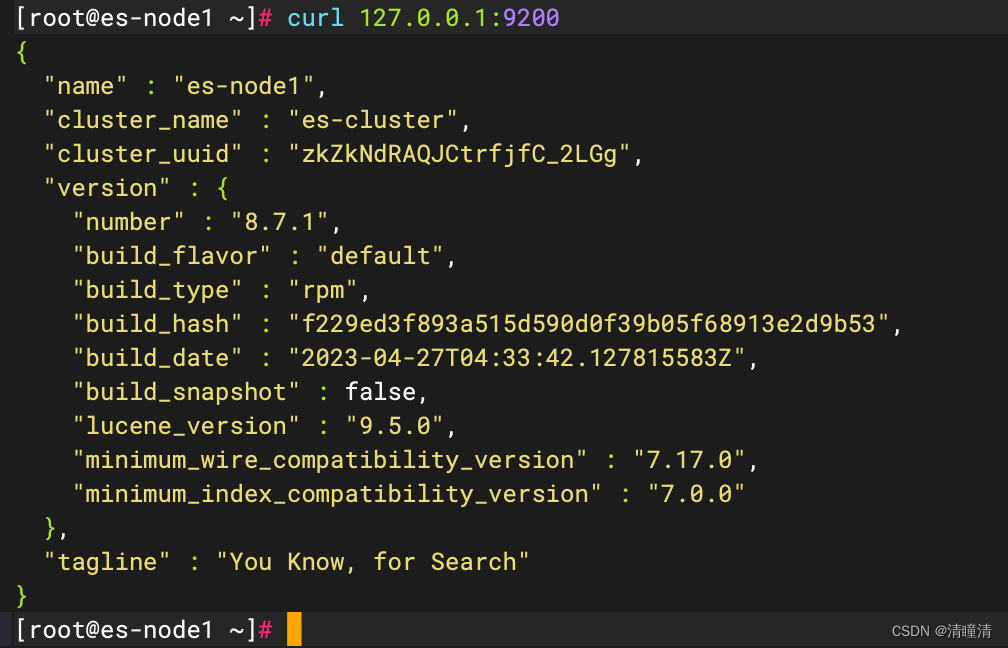
Elasticsearch 集群状态监控
官方文档
https://www.elastic.co/guide/en/elasticsearch/reference/master/rest-apis.html
Elasticsearch 支持各种语言使用 RESTful API 通过端口 9200 与之进行通信,可以用你习惯的 web 客户端访问 Elasticsearch
可以用三种方式和 Elasticsearch进行交互
- curl 命令和其它浏览器: 基于命令行,操作不方便
- 插件: 在node节点上安装head,Cerebro 等插件,实现图形操作,查看数据方便
- Kibana: 需要java环境并配置,图形操作,显示格式丰富
监控下面两个条件都满足才是正常的状态
- 集群状态为 green
- 所有节点都启动
SHELL命令
curl -sXGET http://elk服务器:9200/_cluster/health?pretty=true
获取到的是一个json格式的返回值,那就可以通过python对其中的信息进行分析,例如对status进行分析,如果等于green(绿色)就是运行在正常,等于yellow(黄色)表示副本分片丢失,red(红色)表示主分片丢失
ES集群状态:
- 绿色状态:表示集群各节点运行正常,而且没有丢失任何数据,各主分片和副本分片都运行正常
- 黄色状态:表示由于某个节点宕机或者其他情况引起的,node节点无法连接、所有主分片都正常分配,有副本分片丢失,但是还没有丢失任何数据
- 红色状态:表示由于某个节点宕机或者其他情况引起的主分片丢失及数据丢失,但仍可读取数据和存储
#查看支持的指令
curl http://127.0.0.1:9200/_cat
#查看es集群状态
curl http://127.0.0.1:9200/_cat/health
curl 'http://127.0.0.1:9200/_cat/health?v'
#查看所有的节点信息
curl 'http://127.0.0.1:9200/_cat/nodes?v'
#列出所有的索引 以及每个索引的相关信息
curl 'http://127.0.0.1:9200/_cat/indices?v'
#查看集群分健康性
curl http://127.0.0.1:9200/_cluster/health?pretty=true
创建索引
#创建索引index1,简单输出
[root@node1 ~]#curl -XPUT '192.168.31.14:9200/index1'
{"acknowledged":true,"shards_acknowledged":true,"index":"index1"}
#创建索引index2,格式化输出
[root@node1 ~]#curl -XPUT '192.168.31.14:9200/index2?pretty'
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "index2"
}
#创建3个分片和2个副本
[root@node1 ~]#curl -XPUT '192.168.31.14:9200/index2' -H 'Content-Type:
application/json' -d '
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
}'
#调整副本数为1,但不能调整分片数
[root@node1 ~]#curl -XPUT '192.168.31.14:9200/index2/_settings' -H 'Content-Type:
application/json' -d '
{
"settings": {
"number_of_replicas": 1
}
}'
{"acknowledged":true}
删除索引
#删除格式
curl -XDELETE http://kibana服务器:9200/<索引名称>
Elasticsearch 插件
head 插件
通过使用插件可以实现对 ES 集群的状态监控, 数据访问, 管理配置等功能。
Head 是一个 ES 在生产较为常用的插件
git地址::https://github.com/mobz/elasticsearch-head
安装方式
GitHub 上提供了三种安装方式(编译安装,docker,浏览器插件)可以根据自己的需要自行选择
这里我们选择比较简单也是比较常用的一种:浏览器插件
从谷歌应用商店下载安装插件,支持chrome 和 edge浏览器
注意:需要科学上网
https://chrome.google.com/webstore/detail/elasticsearchhead/ffmkiejjmecolpfloofpjologoblkegm/related
针对没办法科学上网的小伙伴,我已经将Head插件文件下载下来了,放在资源文件里。需要请移步自取 https://download.csdn.net/download/m0_51277041/87800160
安装完插件,点击图标就可以打开插件
登陆,集群中的任意节点IP登陆即可
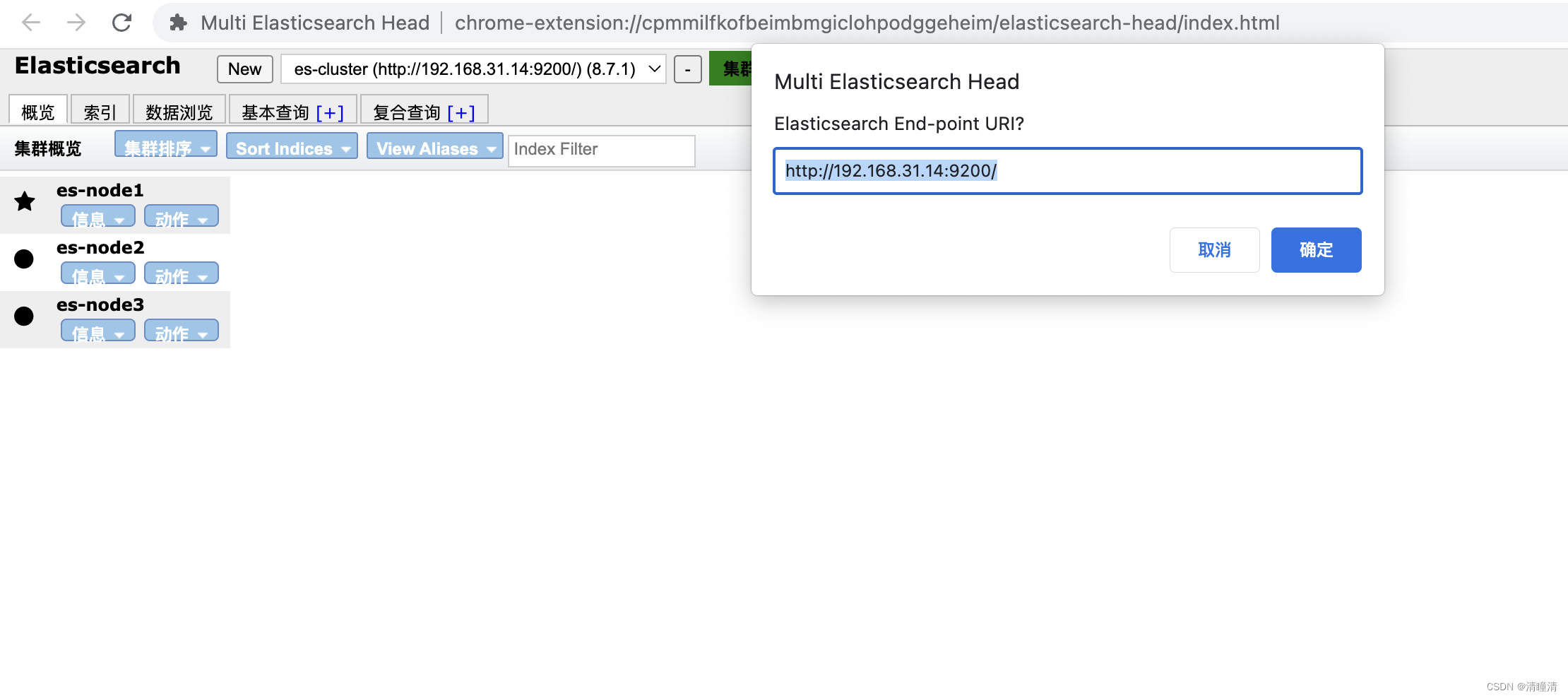
利用Head插件观察状态
head插件集群状态说明
状态颜色说明:
- 绿色:索引数据完整,副本满足,所有条件都满足
- 黄色:索引数据完整,副本不满足,即数据没有丢失,但副本丢失,可能会影响容错功能
- 红色:有索引数据不完整的情况,即数据丢失
- 紫色:有数据分片正在同步过程中
0 表示分片的片shard编号
粗体线框为主分片,细体线框为副本分片
星表示主master节点,圆点表示slave工作节点
添加索引后,可以观察到下面的显示
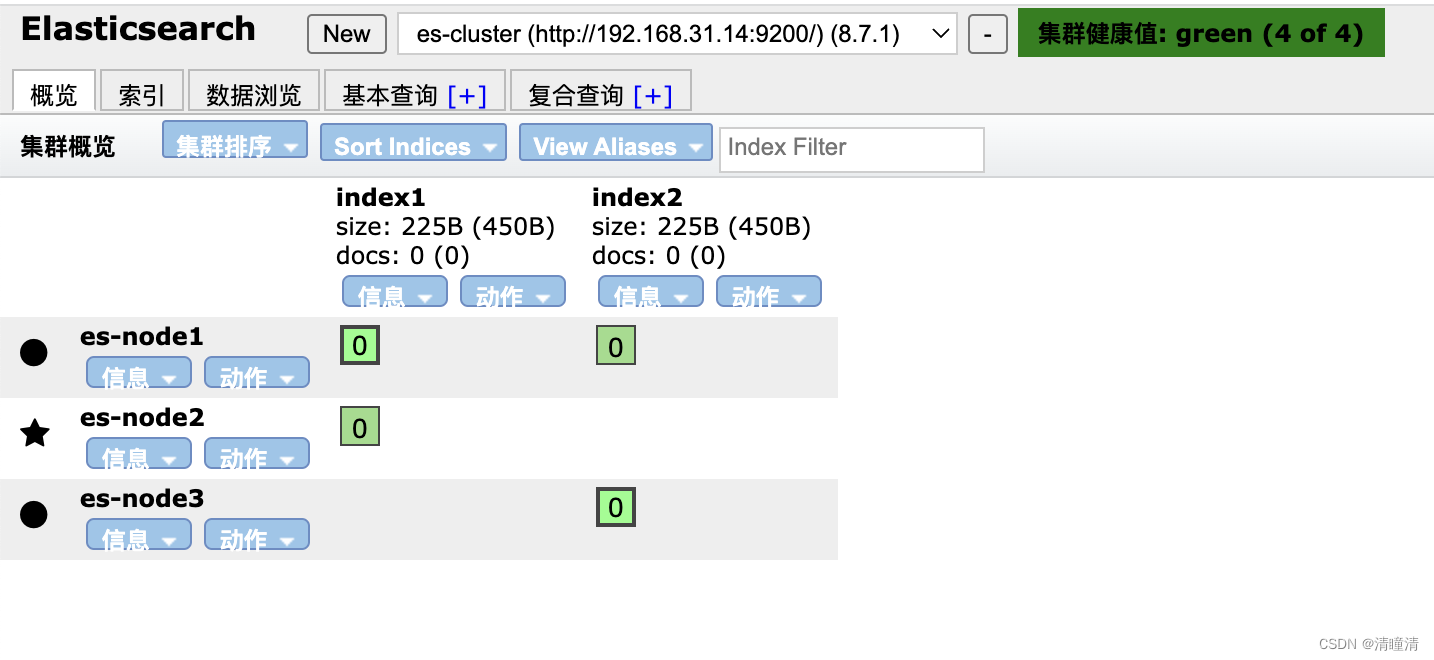
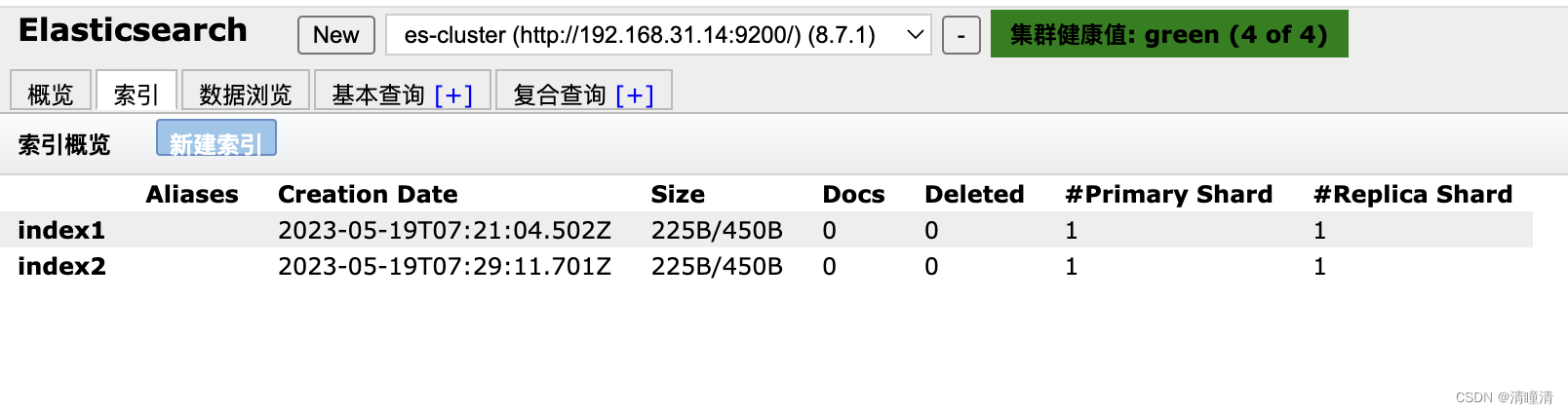
给索引插入数据
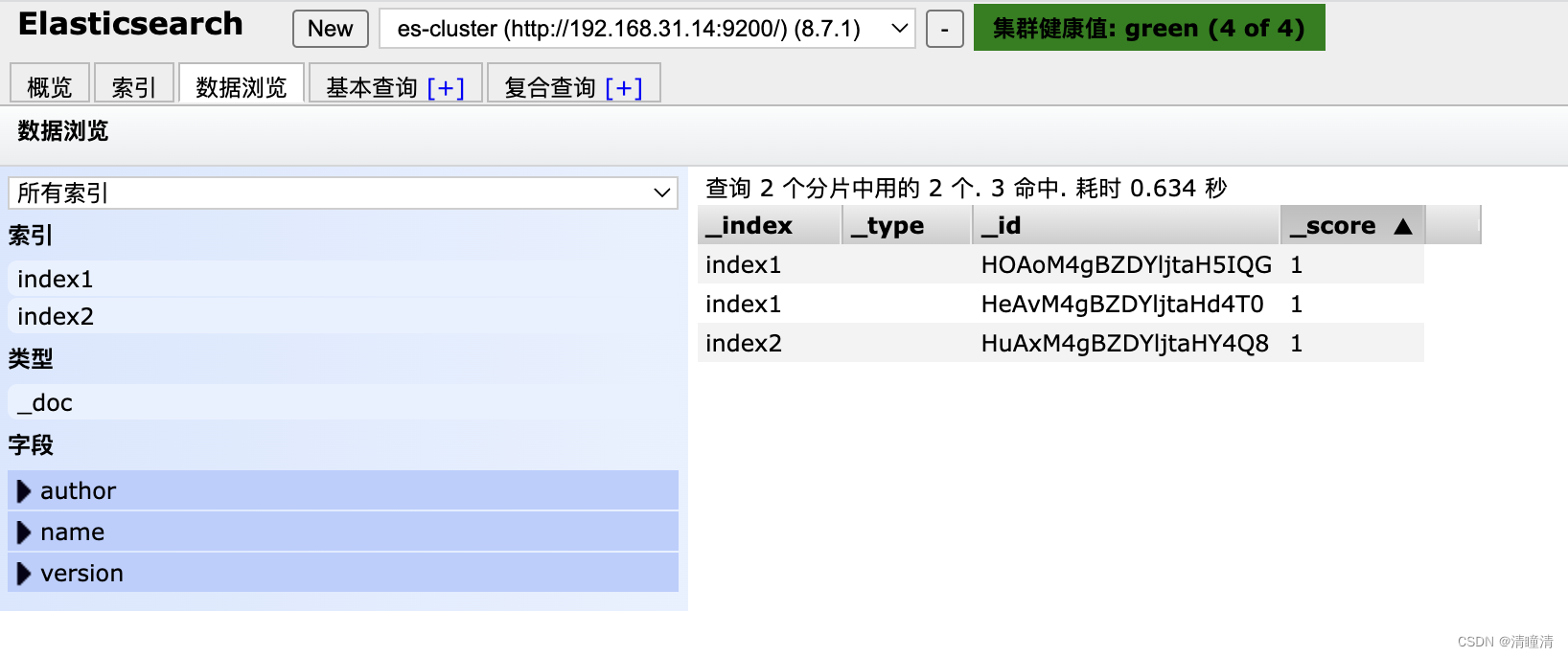
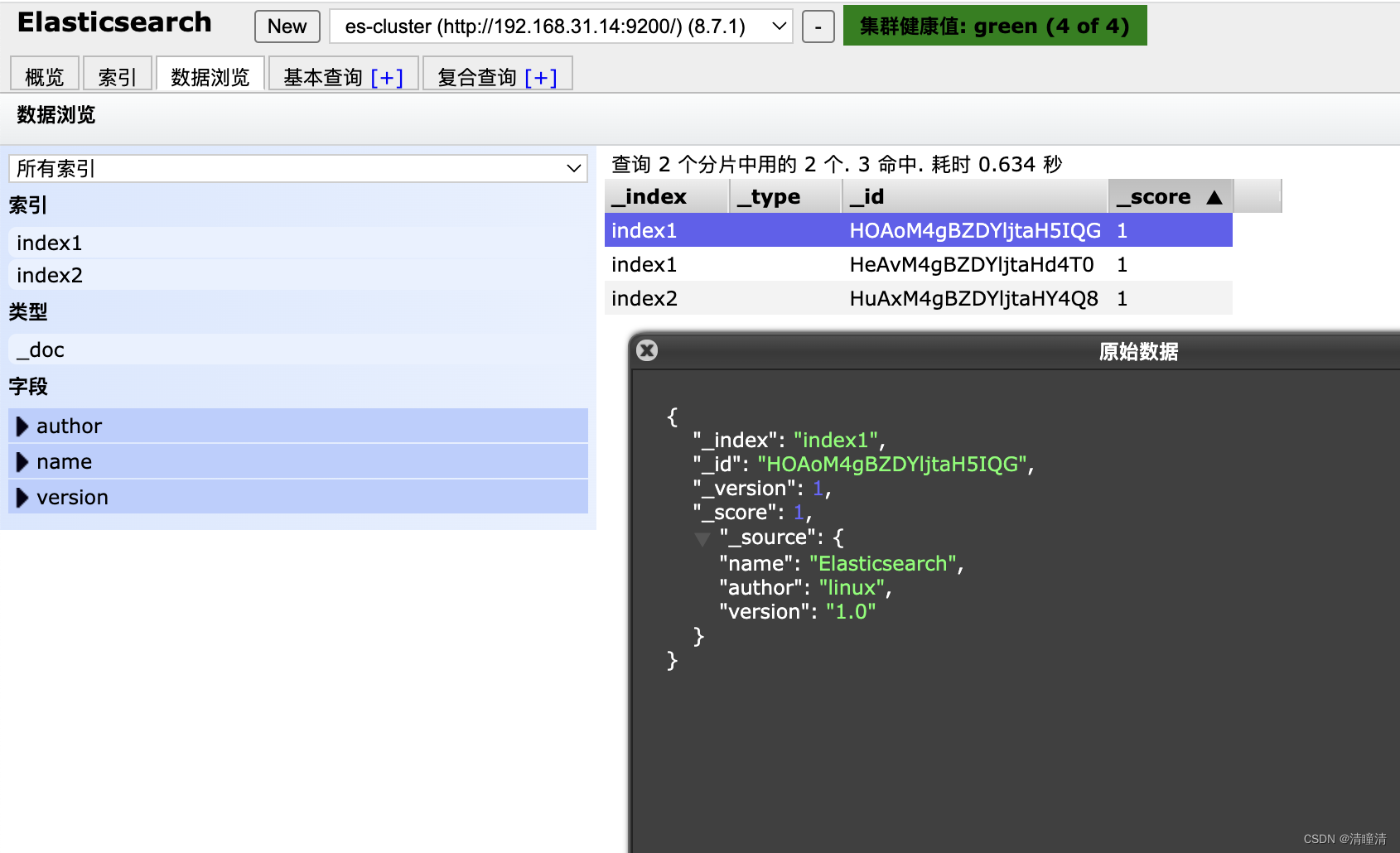
#_id 自动生成
#index1是索引数据库
[root@node1 ~]#curl -XPOST http://192.168.31.14:9200/index1/_doc -H 'Content-Type: application/json' -d '{"name":"Elasticsearch", "author": "linux", "version": "1.0"}'
{"_index":"index1","_id":"HeAvM4gBZDYljtaHd4T0","_version":1,"result":"created","_shards:{"total":2,"successful":2,"failed":0},"_seq_no":1,"_primary_term":1}

![[CTF/网络安全] 攻防世界 backup 解题详析](https://img-blog.csdnimg.cn/e3f68fb1108e463eb5897599da54893e.png#pic_center)