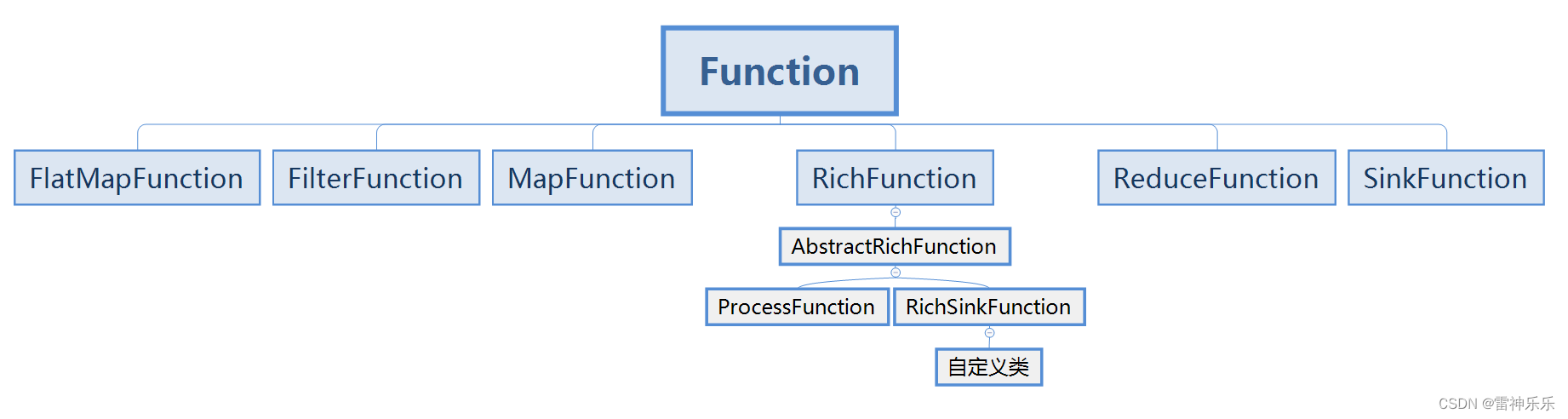
C++13-STL模板

在线练习:
http://noi.openjudge.cn/
https://www.luogu.com.cn/
大纲要求
【 3 】算法模板库中的函数:min、max、swap、sort
【 4 】栈 (stack)、队列 (queue)、链表 (list)、
向量(vector)等容器
1.函数模板
泛型编程
不再是针对某种类型,能适应广泛的类型
如下的交换函数:
#include <iostream>
using namespace std;
//交换int类型
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
//利用C++支持的函数重载交换double类型
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
main()
{
int int_left=1,int_right=2;
double dou_left=5.0,dou_right=6.0;
Swap(int_left,int_right);
printf("int_left-->%d,int_right-->%d \n",int_left,int_right);
Swap(dou_left,dou_right);
printf("dou_left-->%f,dou_right-->%f",dou_left,dou_right);
}

使用函数重载虽然可以实现不同类型的交换函数,但是有以下几个不好的地方:
重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数,使得代码重复性高,过渡冗余
代码的可维护性比较低,一个出错可能所有的重载均出错
那能否告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码呢?
函数模板
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
函数模板的格式如下:
template<typename T1, typename T2,......,typename Tn>
返回值类型 函数名(参数列表)
{
//……
}
注意:typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
#include <iostream>
using namespace std;
template<typename T>
void Swap(T& rx, T& ry) {
T tmp = rx;
rx = ry;
ry = tmp;
}
main()
{
int int_left=1,int_right=2;
double dou_left=5.0,dou_right=6.0;
Swap(int_left,int_right);
printf("int_left-->%d,int_right-->%d \n",int_left,int_right);
Swap(dou_left,dou_right);
printf("dou_left-->%f,dou_right-->%f",dou_left,dou_right);
}

问题:我上述交换函数调用过程中的Swap都是调用的同一个函数吗?
当然不是,这里我三次Swap不是调用同一个函数,其实我Swap的时候根据不同的类型通过模板定制出专属你的类型的函数,然后再调用, 如下图:

面向对象
#include<iostream>
#include<cstring>
//#include<bits/stdc++.h>
using namespace std;
class Person
{
public:
char* _name;
int _sex;
int _age;
/*
系统默认C++在类中普通成员方法第一个参数是类的指针,不可以手动写
类的普通成员方法的形参列表第一个参数是this指针,默认不感知,不可以手动写
类的普通成员方法使用的成员前面默认加上this->,不感知,也可以手动写
*/
//构造函数
Person(/*Person *const this*/const char* name, int sex, int age)
{
_name = new char[strlen(name) + 1];
strcpy_s(_name, strlen(name) + 1, name);
_sex = sex;
_age = age;
}
//没有参数的构造函数称为默认构造函数
Person()
{
cout << "Person()" << endl;
}
//拷贝构造函数
//要传&不能直接传对象,如果没有&,相当于Person src=per直接拷贝过程,从而进入死递归;
Person(Person& src)
{
_name = new char[strlen(src._name) + 1];
strcpy_s(_name, strlen(src._name) + 1, src._name);
_age = src._age;
cout << "Person(Person& src)" << endl;
}
//等号运算符重载
Person& operator=(const Person& src)
{
cout << "Person& operator=(const Person& src)" << endl;
//防止自赋值
if (&src == this)
{
return *this;
}
//防止内存泄漏
delete[]_name;
//防止浅拷贝
_name = new char[strlen(src._name) + 1];
strcpy_s(_name, strlen(src._name) + 1, src._name);
_sex = src._sex;
_age = src._age;
return *this;
}
//析构函数
~Person()
{
if (NULL != _name)
{
delete[]_name;
_name = NULL;
cout << "~Person()" << endl;
}
}
void eat()
{
cout << _name << " eat eat eat ······" << endl;
}
void run()
{
cout << _name << " run run run ······" << endl;
}
void sleep()
{
cout << _name << " sleep sleep sleep ······" << endl;
}
void show()
{
cout << "name:" << _name << endl;
cout << "sex:" << _sex << endl;
cout << "age:" << _age << endl;
}
};
int main()
{
//生成对象的过程叫做构造,自动调用构造函数
Person per(/*&per*/"zhangsan",32,1);
//Person per1;//ok
//Person per1();//error,编译器不知道是函数声明还是构造对象
//用一个已经存在的对象构造一个正在生成的对象
//叫做拷贝构造
Person per1(per);//等价于Person per1=per
Person per2 = per;
//per.show(/*&per*/);
//per.eat(/*&per*/);
//per.run(/*&per*/);
//per.sleep(/*&per*/);
//cout << "==========================" << endl;
//per1.show();
//per._name[4] = '8';
//per.show();
//per1.show();
//用已存在的对象给已存在的对象赋值
per1 = per = per2;//赋值
//per1.show();
per = per;
}

类模板
类模板的作用:建立一个通用类,类中的成员数据类型可以不具体制定,用一个虚拟的类型来代表。
格式:
template<typename T>
template声明创建模板
typename表明其后面的符号是一种数据类型,可以用class代替
T是通用的数据类型,名称可以替换,通常为大写字母
#include<iostream>
using namespace std;
//类模板
template<class NameType, class AgeType>
class Person
{
public:
Person(NameType name, AgeType age)
{
this->m_Age = age;
this->m_Name = name;
}
void showPerson()
{
cout << "name: " << this->m_Name << "age: " << this->m_Age << endl;
}
NameType m_Name;
AgeType m_Age;
};
void test01()
{
Person<string, int> p1("孙悟空", 999);
p1.showPerson();
}
int main()
{
test01();
system("pause");
return 0;
}

2.算法模板库中的函数:min、max、swap、sort
使用algorithm头文件,需要在头文件下加一行“using namespace std”
1.max()、min()、abs()
max(x,y)和min(x,y)分别返回x和y中的最大值和最小值,且参数必须是两个(可以是浮点数)。如果想要返回三个数x、y、z的最大值,可以使用max(x,max(y,z)的写法。
abs(x)返回x的绝对值。注意:x必须是整数,浮点型的绝对值请用math头文件下的fabs。
#include<cstdio>
#include<algorithm>
#include<math.h>
using namespace std;
int main()
{
int x=1,y= -2;
float xf=1.0,yf=-2.10;
printf("%d %d\n",max(x,y),min(x,y));
printf("%d %d\n",abs(x),abs(y));
printf("%.2f %.2f\n",abs(xf),abs(yf));
printf("%.2f %.2f\n",fabs(xf),fabs(yf));
return 0;
}

3.swap()
// This program demonstrates the use of the swap function template.
#include <iostream>
#include <string>
#include <algorithm> // Needed for swap
using namespace std;
int main ()
{
// Get and swap two chars
char firstChar, secondChar;
cout << "Enter two characters: ";
cin >> firstChar >> secondChar;
swap(firstChar, secondChar);
cout << firstChar << " " << secondChar << endl;
// Get and swap two ints
int firstInt, secondInt;
cout << "Enter two integers: ";
cin >> firstInt >> secondInt;
swap(firstInt, secondInt);
cout << firstInt << " " << secondInt << endl;
// Get and swap two strings
cout << "Enter two strings: ";
string firstString, secondString;
cin >> firstString >> secondString;
swap(firstString, secondString);
cout << firstString << " " << secondString << endl;
return 0;
}

3.sort()
在C++中,sort()函数常常用来对容器内的元素进行排序,先来了解一下sort()函数。
#include<bits/stdc++.h>
using namespace std;
int a[4]={1,5,0,2};
int main()
{
// cin>>a[1]>>a[2]>>a[3];
sort(a+1,a+4);
cout<<a[3]<<' '<<a[2]<<' '<<a[1];
return 0;
}

sort()函数有三个参数:
第一个是要排序的容器的起始迭代器。
第二个是要排序的容器的结束迭代器。
第三个参数是排序的方法,是可选的参数。
默认的排序方法是从小到大排序,也就是less<Type>(),还提供了greater<Type>()进行从大到小排序。这个参数的类型是函数指针,less和greater实际上都是类/结构体,内部分别重载了()运算符,称为仿函数,所以实际上less<Type>()和greater<Type>()都是函数名,也就是函数指针。我们还可以用普通函数来定义排序方法。
如果容器内元素的类型是内置类型或string类型,我们可以直接用less<Type>()或greater<Type>()进行排序。但是如果数据类型是我们自定义的结构体或者类的话,我们需要自定义排序函数,有三种写法:
重载 < 或 > 运算符:重载 < 运算符,传入less<Type>()进行升序排列。重载 > 运算符,传入greater<Type>()进行降序排列。这种方法只能针对一个维度排序,不灵活。
普通函数:写普通函数cmp,传入cmp按照指定规则排列。这种方法可以对多个维度排序,更灵活。
仿函数:写仿函数cmp,传入cmp<Type>()按照指定规则排列。这种方法可以对多个维度排序,更灵活。
重写操作符号
#include <bits/stdc++.h>
using namespace std;
struct Person {
int id;
int age;
Person(int id,int age):id(id),age(age){}
//重载<运算符,进行升序排列
bool operator < (const Person& p2) const {
return id < p2.id;
}
//重载>运算符,进行降序排列
bool operator > (const Person& p2) const {
return id > p2.id;
}
};
int main()
{
Person p1(1, 10), p2(2, 20), p3(3, 30);
vector<Person> ps;
ps.push_back(p2);
ps.push_back(p1);
ps.push_back(p3);
sort(ps.begin(), ps.end(), less<Person>());
for (int i = 0; i < 3; i++) {
cout << ps[i].id << " " << ps[i].age << endl;
}
cout << endl;
sort(ps.begin(), ps.end(), greater<Person>());
for (int i = 0; i < 3; i++) {
cout << ps[i].id << " " << ps[i].age << endl;
}
cout << endl;
}

普通函数
#include <bits/stdc++.h>
using namespace std;
struct Person {
int id;
int age;
Person(int id,int age):id(id),age(age){}
};
//普通函数
bool cmp(const Person& p1, const Person& p2) {
if (p1.id == p2.id) return p1.age >= p2.age;
return p1.id < p2.id;
}
int main()
{
Person p1(1, 30), p2(2, 20), p3(1, 20),p4(3, 30), p5(3, 40);
vector<Person> ps;
ps.push_back(p2);
ps.push_back(p1);
ps.push_back(p3);
ps.push_back(p4);
ps.push_back(p5);
sort(ps.begin(), ps.end(), cmp);//传入函数指针cmp
for (int i = 0; i < 5; i++) {
cout << ps[i].id << " " << ps[i].age << endl;
}
}

仿函数
#include <bits/stdc++.h>
using namespace std;
struct Person {
int id;
int age;
Person(int id, int age) :id(id), age(age) {}
};
//仿函数
struct cmp {
bool operator()(const Person& p1, const Person& p2) {
if (p1.id == p2.id) return p1.age >= p2.age;
return p1.id < p2.id;
}
};
int main()
{
Person p1(1, 30), p2(2, 20), p3(1, 20),p4(3, 30), p5(3, 40);
vector<Person> ps;
ps.push_back(p2);
ps.push_back(p1);
ps.push_back(p3);
ps.push_back(p4);
ps.push_back(p5);
sort(ps.begin(), ps.end(), cmp()); //传入函数指针cmp()
for (int i = 0; i < 5; i++) {
cout << ps[i].id << " " << ps[i].age << endl;
}
}

3.STL-栈 (stack)、队列 (queue)、链表 (list)、向量(vector)等容器
3.1STL 标准模板库-向量(vector)
STL 标准模板库,由惠普实验室提供,里面集成了常用的数据结构类模板和算法函数模板等。
容器:用来存储各类型数据的数据结构。
迭代器:类似于专门用来指向容器成员的指针,用来遍历、操作、管理容器中的成员,可以大大提高容器的访问速度。
算法:STL实现了常见的排序、查找算法。
STL-栈 (stack)、队列 (queue)、链表 (list)、向量(vector)等容器
#include <vector>
vector是变长数组,支持随机访问,不支持在任意位置O(1)插入。为了保证效率,元素的增删一般应该在末尾进行。
1. 初始化方法:
a. 通过赋值方式初始化:
std::vector<int> v1 = {1, 2, 3, 4, 5}; // 初始化一个包含5个元素的vector
std::vector<std::string> v2 = {"hello", "world"}; // 初始化一个包含2个字符串的vector
b. 通过构造函数方式初始化:
std::vector<int> v3(10); // 初始化一个包含10个元素的vector,每个元素的值为0
std::vector<int> v4(5, 2); // 初始化一个包含5个元素的vector,每个元素的值为2
std::vector<std::string> v5(3, "hello"); // 初始化一个包含3个字符串的vector,每个字符串的值为"hello"
c. 通过拷贝方式初始化:
std::vector<int> v6(v1); // 将v1中的元素拷贝到v6中
2. 常用操作函数:
1. 插入元素:
std::vector<int> v7 = {1, 2, 3};
v7.push_back(4); // 在vector的末尾插入一个元素
v7.insert(v7.begin() + 2, 5); // 在vector的第3个位置插入一个元素,值为5
2. 删除元素:
std::vector<int> v8 = {1, 2, 3,4,5};
v8.pop_back(); // 删除vector的最后一个元素
v8.erase(v8.begin() + 1); // 删除vector的第2个元素
v8.erase(a.begin()+1,a.begin()+3); //删除a中第1个(从第0个算起)到第2个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+ 3(不包括它)
3. 访问元素:
std::vector<int> v9 = {1, 2, 3};
int x = v9[1]; // 获取vector的第2个元素
int y = v9.at(2); // 获取vector的第3个元素,如果越界会抛出异常
int z = v9.front(); // 获取vector的第1个元素
int w = v9.back(); // 获取vector的最后一个元素
4. 修改元素:
std::vector<int> v10 = {1, 2, 3};
v10[1] = 4; // 修改vector的第2个元素的值为4
v10.at(2) = 5; // 修改vector的第3个元素的值为5,如果越界会抛出异常
5. 返回大小:size/empty
size函数返回vector的实际长度(包含的元素个数),empty函数返回一个bool类型,表明vector是否为空。二者的时间复杂度都是O(1)。
所有的STL容器都支持这两个方法,含义也相同,之后我们就不再重复给出。
6. clear
clear函数把vector清空。
7. 迭代器
迭代器就像STL容器的“指针”,可以用星号“*”操作符解除引用。
一个保存int的vector的迭代器声明方法为:
vector<int>::iterator it;
vector的迭代器是“随机访问迭代器”,可以把vector的迭代器与一个整数相加减,其行为和指针的移动类似。可以把vector的两个迭代器相减,其结果也和指针相减类似,得到两个迭代器对应下标之间的距离。
8. begin/end
begin函数返回指向vector中第一个元素的迭代器。例如a是一个非空的vector,则*a.begin()与a[0]的作用相同。
所有的容器都可以视作一个“前闭后开”的结构,end函数返回vector的尾部,即第n个元素再往后的“边界”。*a.end()与a[n]都是越界访问,其中n=a.size()。
下面两份代码都遍历了vector<int>a,并输出它的所有元素。
#include <iostream>
#include <vector>
using namespace std;
int main()
{
std::vector<int> v9 = {1, 2, 3};
int x = v9[1]; // 获取vector的第2个元素
int y = v9.at(2); // 获取vector的第3个元素,如果越界会抛出异常
int z = v9.front(); // 获取vector的第1个元素
int w = v9.back(); // 获取vector的最后一个元素
for (int i = 0; i < v9.size(); i ++) cout << v9[i] << endl;
for (vector<int>::iterator it = v9.begin(); it != v9.end(); it ++) cout << *it << endl;
return 0;
}

统计数组中的元素案例
#include<iostream>
using namespace std;
//算法 负责统计某个元素出现多少次
int mycount(int* start,int * end,int val)
{
int num = 0;
while (start != end)
{
if (*start == val)
num++;
start++;
}
return num;
}
int main()
{
//数组 容器
int arr[] = { 1,2,4,5,3,8,9,1,4,4 };
int* pBegin = arr;//指针 迭代器
int* pEnd = &arr[(sizeof(arr) / sizeof(arr[0]))];
int num = mycount(pBegin, pEnd, 4);
cout << num << endl;
return 0;
}
统计数组中的元素案例-vector版本
#include<iostream>
#include<vector>//动态数组 容器vector
#include<algorithm>//算法
using namespace std;
//回调函数
void myprint(int v)
{
cout << v << endl;
}
//stl基本语法
void text01()
{
//定义容器
vector<int> v;
v.push_back(10);
v.push_back(34);
v.push_back(40);
v.push_back(40);
//通过STL提供的for_each算法
//容器提供迭代器
//vector<int>::iterator迭代器类型
vector<int>::iterator pBegin = v.begin();
vector<int>::iterator pEnd = v.end();
//容器中可能存在基础的数据类型,也可以放自定义的数据类型
//for_each(start,end,回调函数)
//算法
for_each(pBegin, pEnd, myprint);
//计数
int count1 = count(v.begin(), v.end(),40);
cout << "元素40在数组中出现的次数为 " << count1 << endl;
}
class Person
{
public:
int age;
int id;
Person(int age,int id):age(age),id(id)
{
}
};
void text02()
{
//创建容器,类型为person
vector<Person> v;
Person p1(30, 1), p2(23, 2), p3(54, 3), p4(30,4);
v.push_back(p1);
v.push_back(p2);
v.push_back(p3);
v.push_back(p4);
//自己写算法遍历
for (vector<Person>::iterator it = v.begin(); it != v.end(); it++)
{
cout << (*it).age << " " << (*it).id << endl;
}
}
int main()
{
text01();//基本数据类型
text02();//类
return 0;
}

3.2 STL 标准模板库-队列queue
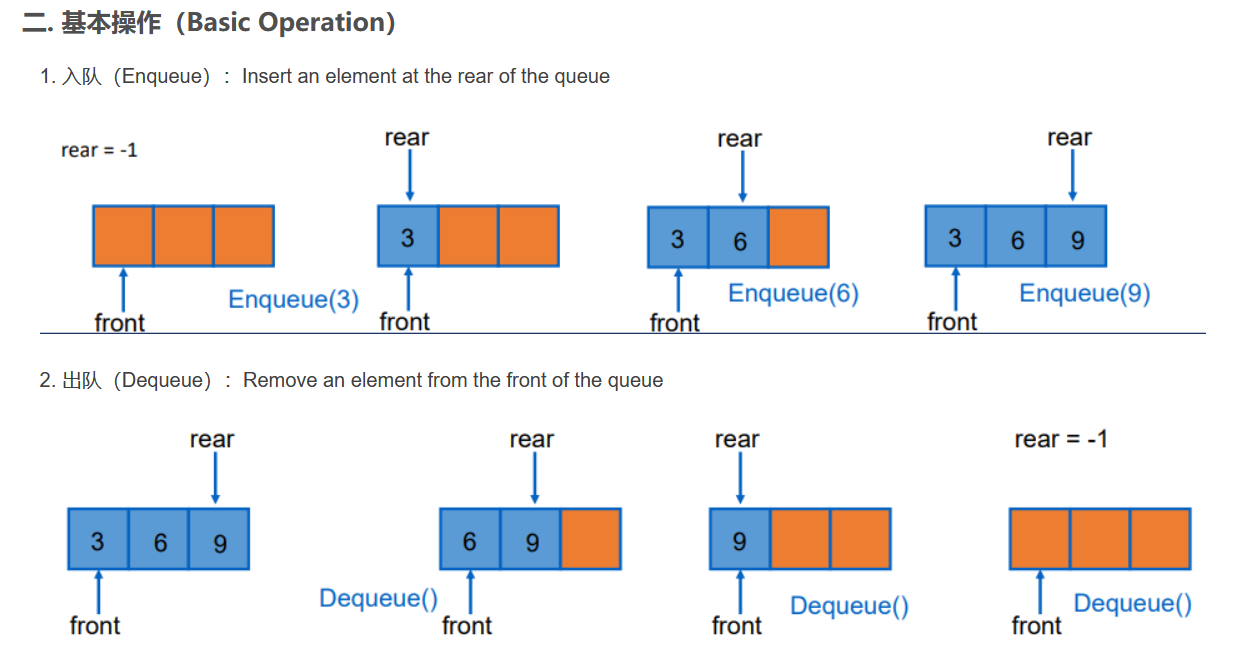
队列的概述
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。


基于数组的循环队列实现
以数组作为底层数据结构时,一般讲队列实现为循环队列。这是因为队列在顺序存储上的不足:每次从数组头部删除元素(出队)后,需要将头部以后的所有元素往前移动一个位置,这是一个时间复杂度为O(n)的操作:
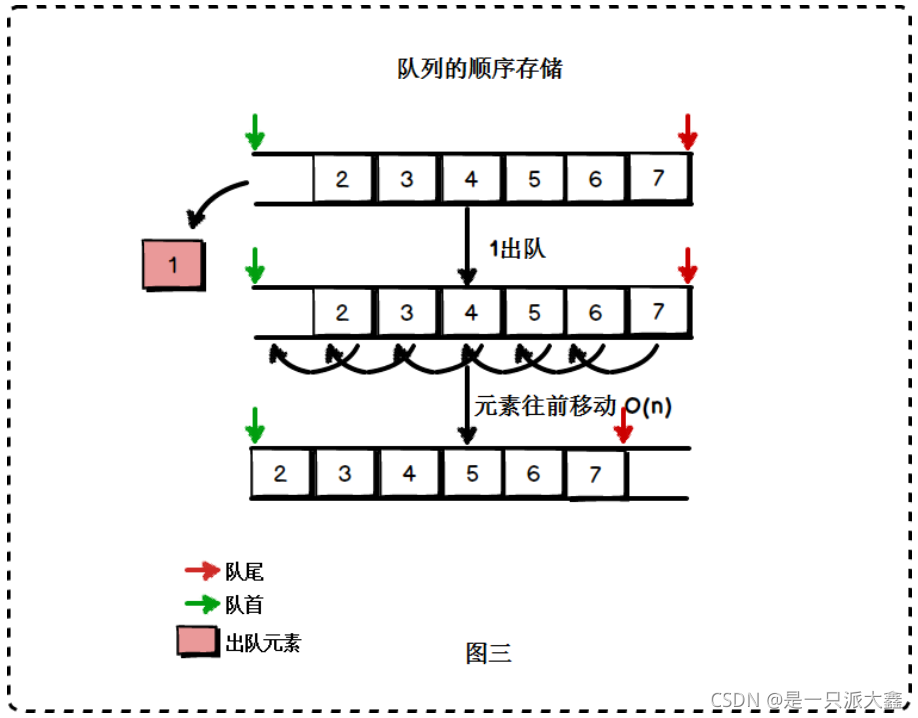

STL中的队列实现
参考:https://blog.csdn.net/weixin_43361652/article/details/113353918
队列先进先出
头文件:
<queue>
常用操作:
queue<int> q:建立一个队列q,其内部元素类型是int。
q.push(a):将元素a插入到队列q的末尾。
q.pop():删除队列q的队首元素。
q.front():查询q的队首元素。
q.back():查询q的队尾元素。
q.size():查询q的元素个数。
q.empty():查询q是否为空。
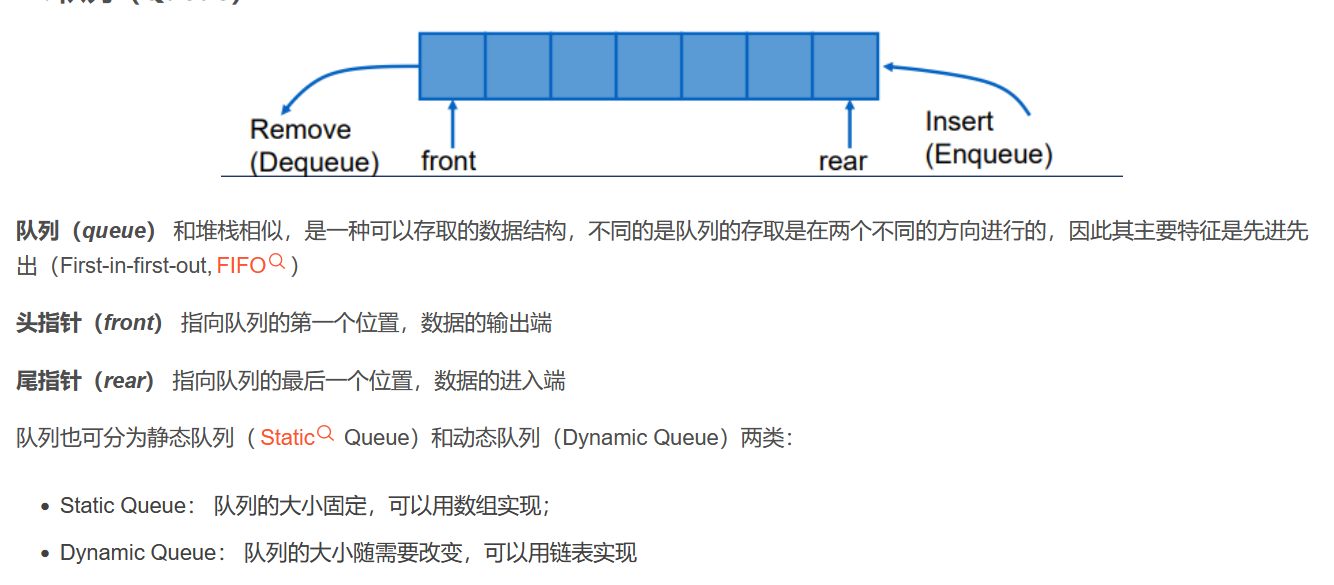
#include <iostream>
#include <queue>
using namespace std;
int main()
{
// 定义一个队列,存放 int 类型的数据
queue<int> q;
// 将一些数据入队
for (int i = 1; i <= 5; i++) {
q.push(i);
}
// 输出队列中的元素个数
cout << "Size of queue: " << q.size() << endl;
// 输出队列中的所有元素
cout << "Queue elements: ";
while (!q.empty()) {
cout << q.front() << " ";
q.pop();
}
// 输出队列中的元素个数
cout << "\nSize of queue: " << q.size() << endl;
return 0;
}

参考:https://blog.csdn.net/weixin_44572229/article/details/120016366
#include <queue>
头文件queue主要包括循环队列queue和优先队列priority_queue两个容器。
声明
queue<int> q;
struct rec{…}; queue<rec> q; //结构体rec中必须定义小于号
priority_queue<int> q; // 大根堆
priority_queue<int, vector<int>, greater<int> q; // 小根堆
priority_queue<pair<int, int>>q;
循环队列 queue
push 从队尾插入
pop 从队头弹出
front 返回队头元素
back 返回队尾元素
优先队列 priority_queue
push 把元素插入堆
pop 删除堆顶元素
top 查询堆顶元素(最大值)
3.#include
头文件stack包含栈。声明和前面的容器类似。
push 向栈顶插入
pop 弹出栈顶元素
4.#include
双端队列deque是一个支持在两端高效插入或删除元素的连续线性存储空间。它就像是vector和queue的结合。与vector相比,deque在头部增删元素仅需要O(1)的时间;与queue相比,deque像数组一样支持随机访问。
[] 随机访问
begin/end,返回deque的头/尾迭代器
front/back 队头/队尾元素
push_back 从队尾入队
push_front 从队头入队
pop_back 从队尾出队
pop_front 从队头出队
clear 清空队列
5.#include
头文件set主要包括set和multiset两个容器,分别是“有序集合”和“有序多重集合”,即前者的元素不能重复,而后者可以包含若干个相等的元素。set和multiset的内部实现是一棵红黑树,它们支持的函数基本相同。
声明
set s;
struct rec{…}; set s; // 结构体rec中必须定义小于号
multiset s;
size/empty/clear
与vector类似
迭代器
set和multiset的迭代器称为“双向访问迭代器”,不支持“随机访问”,支持星号(*)解除引用,仅支持”++”和–“两个与算术相关的操作。
设it是一个迭代器,例如set::iterator it;
若把it++,则it会指向“下一个”元素。这里的“下一个”元素是指在元素从小到大排序的结果中,排在it下一名的元素。同理,若把it–,则it将会指向排在“上一个”的元素。
begin/end
返回集合的首、尾迭代器,时间复杂度均为O(1)。
s.begin() 是指向集合中最小元素的迭代器。
s.end() 是指向集合中最大元素的下一个位置的迭代器。换言之,就像vector一样,是一个“前闭后开”的形式。因此–s.end()是指向集合中最大元素的迭代器。
insert
s.insert(x)把一个元素x插入到集合s中,时间复杂度为O(logn)。
在set中,若元素已存在,则不会重复插入该元素,对集合的状态无影响。
find
s.find(x) 在集合s中查找等于x的元素,并返回指向该元素的迭代器。若不存在,则返回s.end()。时间复杂度为O(logn)。
lower_bound/upper_bound
这两个函数的用法与find类似,但查找的条件略有不同,时间复杂度为 O(logn)。
s.lower_bound(x) 查找大于等于x的元素中最小的一个,并返回指向该元素的迭代器。
s.upper_bound(x) 查找大于x的元素中最小的一个,并返回指向该元素的迭代器。
erase
设it是一个迭代器,s.erase(it) 从s中删除迭代器it指向的元素,时间复杂度为O(logn)
设x是一个元素,s.erase(x) 从s中删除所有等于x的元素,时间复杂度为O(k+logn),其中k是被删除的元素个数。
count
s.count(x) 返回集合s中等于x的元素个数,时间复杂度为 O(k +logn),其中k为元素x的个数。
6.#include
声明
map<key_type, value_type> name;
例如:
map<long, long, bool> vis;
map<string, int> hash;
map<pair<int, int>, vector<int>> test;
size/empty/clear/begin/end均与set类似。
Insert/erase
与set类似,但其参数均是pair<key_type, value_type>。
find
h.find(x) 在变量名为h的map中查找key为x的二元组。
[]操作符
h[key] 返回key映射的value的引用,时间复杂度为O(logn)。
[]操作符是map最吸引人的地方。我们可以很方便地通过h[key]来得到key对应的value,还可以对h[key]进行赋值操作,改变key对应的value。