目录
一、filter算子
二、map算子
三、聚合算子
1.keyBy——按键分区
2.简单聚合
(1)min:在输入流上,对指定的字段求最小值
(2)minBy:返回包含字段最小值的整条数据
(3)max:在输入流上,对指定的字段求最大值
(4)maxBy:返回包含字段最大值的整条数据
(5)sum:在输入流上,对指定的字段做叠加求和的操作
3.reduce——归约聚合
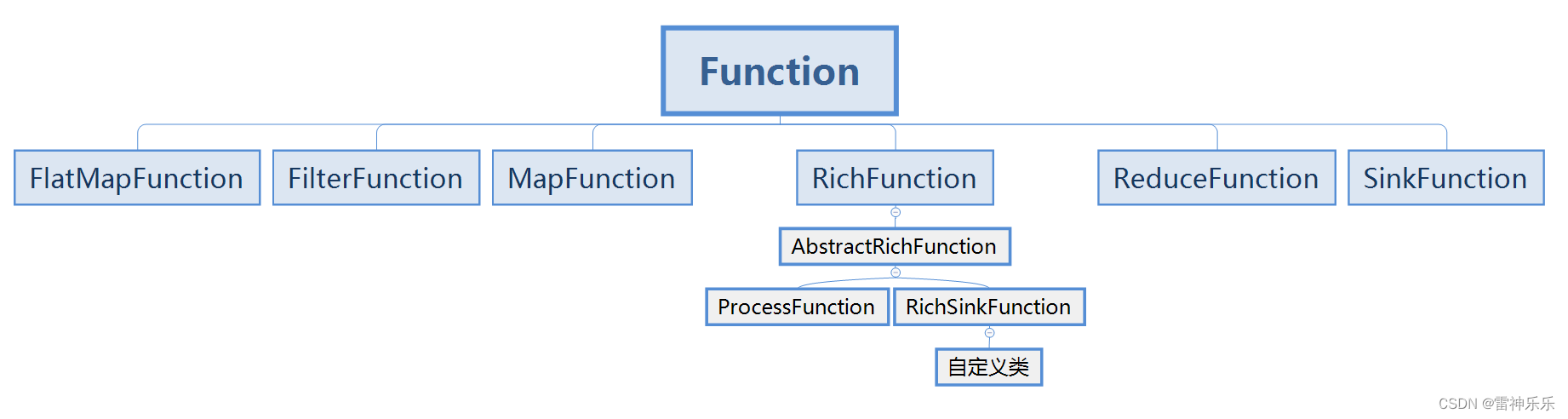 一、filter算子
一、filter算子
import source.SensorReading
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO filter函数用法一:匿名函数
// val filterStream: DataStream[SensorReading] = dataStream.filter(data => data.id.contains("sensor_1"))
// val filterStream: DataStream[SensorReading] = dataStream.filter(data => data.id=="sensor_1")
val filterStream: DataStream[SensorReading] = dataStream.filter(data => data.id.equals("sensor_1"))
filterStream.print()
// TODO filter函数用法二:FilterFunction函数
val filterStream1: DataStream[SensorReading] = dataStream.filter(new FilterFunction[SensorReading] {
override def filter(value: SensorReading): Boolean = {
value.id.contains("sensor_1")
}
})
// filterStream1.print()
// TODO filter函数用法三:自定义函数
val filterStream2: DataStream[SensorReading] = dataStream.filter(new FilterTest)
// filterStream2.print()
env.execute()
}
}
class FilterTest extends FilterFunction[SensorReading]{
override def filter(value: SensorReading): Boolean = {
value.id.equals("sensor_1")
true
else
false
}
}
运行结果:
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_1,1684201910,36.8)
SensorReading(sensor_1,1684202012,44.7)
SensorReading(sensor_1,1684201973,38.16)
SensorReading(sensor_1,1684201973,38.16)二、map算子
import source.SensorReading
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO map算子用法一:传入匿名函数
val mapStream: DataStream[String] = dataStream.map(data => data.id + " temp")
// mapStream.print()
// TODO map算子用法二:传入MapFunction
val mapStream1: DataStream[String] = dataStream.map(new MapFunction[SensorReading, String] {
override def map(value: SensorReading): String = {
value.id + " temp"
}
})
// mapStream1.print()
// TODO map算子用法三:传入自定义函数
val mapStream2: DataStream[String] = dataStream.map(new MapTest)
mapStream2.print()
env.execute()
}
}
class MapTest extends MapFunction[SensorReading, String] {
override def map(value: SensorReading): String = {
value.id + " temp"
}
}
运行结果:
sensor_1 temp
sensor_4 temp
sensor_3 temp
sensor_7 temp
sensor_1 temp
sensor_1 temp
sensor_1 temp
sensor_1 temp三、聚合算子
1.keyBy——按键分区
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO keyBy
val keyStream: KeyedStream[SensorReading, String] = dataStream.keyBy(x => x.id)
keyStream.print()
env.execute()
}
}2.简单聚合
(1)min:在输入流上,对指定的字段求最小值
只选择指定字段的最小值,其他字段会保留最初第一个数据的值。
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO keyBy
val keyStream: KeyedStream[SensorReading, String] = dataStream.keyBy(x => x.id)
// TODO min传参的第一种方法:field: String
val minStream: DataStream[SensorReading] = keyStream.min("temperature")
minStream.print()
// TODO min传参的第二种方法:position: Int
val minStream1: DataStream[SensorReading] = keyStream.min(2)
minStream1.print()
env.execute()
}
}
运行结果:
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_4,1684202000,17.7)
SensorReading(sensor_3,1684202064,27.3)
SensorReading(sensor_7,1684202068,13.8)
SensorReading(sensor_1,1684201947,36.8)
SensorReading(sensor_1,1684201947,36.8)
SensorReading(sensor_1,1684201947,36.8)
SensorReading(sensor_1,1684201947,36.8)(2)minBy:返回包含字段最小值的整条数据
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO keyBy
val keyStream: KeyedStream[SensorReading, String] = dataStream.keyBy(x => x.id)
// TODO minBy传参的第一种方法:field: String
val minByStream: DataStream[SensorReading] = keyStream.minBy("temperature")
minByStream.print()
// TODO minBy传参的第二种方法:position: Int
val minByStream1: DataStream[SensorReading] = keyStream.minBy(2)
minByStream1.print()
env.execute()
}
}
运行结果:
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_4,1684202000,17.7)
SensorReading(sensor_3,1684202064,27.3)
SensorReading(sensor_7,1684202068,13.8)
SensorReading(sensor_1,1684201910,36.8)
SensorReading(sensor_1,1684201910,36.8)
SensorReading(sensor_1,1684201910,36.8)
SensorReading(sensor_1,1684201910,36.8)(3)max:在输入流上,对指定的字段求最大值
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO keyBy
val keyStream: KeyedStream[SensorReading, String] = dataStream.keyBy(x => x.id)
// TODO max传参的第一种方法:field: String
val maxStream: DataStream[SensorReading] = keyStream.max(2)
maxStream.print()
// TODO max传参的第二种方法:field: String
val maxStream1: DataStream[SensorReading] = keyStream.max("temperature")
maxStream1.print()
env.execute()
}
}
运行结果:
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_4,1684202000,17.7)
SensorReading(sensor_3,1684202064,27.3)
SensorReading(sensor_7,1684202068,13.8)
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_1,1684201947,44.7)
SensorReading(sensor_1,1684201947,44.7)
SensorReading(sensor_1,1684201947,44.7)(4)maxBy:返回包含字段最大值的整条数据
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO keyBy
val keyStream: KeyedStream[SensorReading, String] = dataStream.keyBy(x => x.id)
// TODO maxBy传参的第一种方法:field: String
val maxByStream: DataStream[SensorReading] = keyStream.maxBy("temperature")
maxByStream.print()
// TODO maxBy传参的第二种方法:position: Int
val maxByStream1: DataStream[SensorReading] = keyStream.maxBy(2)
maxByStream1.print()
env.execute()
}
}
运行结果:
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_4,1684202000,17.7)
SensorReading(sensor_3,1684202064,27.3)
SensorReading(sensor_7,1684202068,13.8)
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_1,1684202012,44.7)
SensorReading(sensor_1,1684202012,44.7)
SensorReading(sensor_1,1684202012,44.7)(5)sum:在输入流上,对指定的字段做叠加求和的操作
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO keyBy
val keyStream: KeyedStream[SensorReading, String] = dataStream.keyBy(x => x.id)
// TODO sum算子传参的第一种方法:field: String
val sumStream: DataStream[SensorReading] = keyStream.sum("temperature")
sumStream.print()
// TODO sum算子传参的第一种方法:position: Int
val sumStream1: DataStream[SensorReading] = keyStream.sum(2)
sumStream1.print()
env.execute()
}
}
运行结果:
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_4,1684202000,17.7)
SensorReading(sensor_3,1684202064,27.3)
SensorReading(sensor_7,1684202068,13.8)
SensorReading(sensor_1,1684201947,76.6)
SensorReading(sensor_1,1684201947,121.3)
SensorReading(sensor_1,1684201947,159.45999999999998)
SensorReading(sensor_1,1684201947,197.61999999999998)3.reduce——归约聚合
object Transform {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 加载数据源
val path = "D:\\javaseprojects\\flinkstu\\resources\\sensor.txt"
val inputStream: DataStream[String] = env.readTextFile(path)
// 数据计算
val dataStream: DataStream[SensorReading] = inputStream.map(data => {
val arr: Array[String] = data.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
// TODO keyBy
val keyStream: KeyedStream[SensorReading, String] = dataStream.keyBy(x => x.id)
// TODO reduce使用方法一:传入匿名函数
val reduceStream: DataStream[SensorReading] = keyStream.reduce((x, y) => {
if (x.temperature <= y.temperature) {
x
} else {
SensorReading(x.id, x.timestamp, x.temperature)
}
})
reduceStream.print()
// TODO reduce使用方法二:传入自定义函数
val reduceStream1: DataStream[SensorReading] = keyStream.reduce(new ReduceTest)
reduceStream1.print()
env.execute()
}
}
class ReduceTest extends ReduceFunction[SensorReading] {
override def reduce(value1: SensorReading, value2: SensorReading): SensorReading = {
// todo 通过reduce实现min
// SensorReading(value1.id, value1.timestamp, value1.temperature.min(value2.temperature))
// todo 通过reduce实现minBy
SensorReading(value1.id, value2.timestamp, value1.temperature.min(value2.temperature))
}
}
运行结果:
SensorReading(sensor_1,1684201947,39.8)
SensorReading(sensor_4,1684202000,17.7)
SensorReading(sensor_3,1684202064,27.3)
SensorReading(sensor_7,1684202068,13.8)
SensorReading(sensor_1,1684201910,36.8)
SensorReading(sensor_1,1684202012,36.8)
SensorReading(sensor_1,1684201973,36.8)
SensorReading(sensor_1,1684201973,36.8)