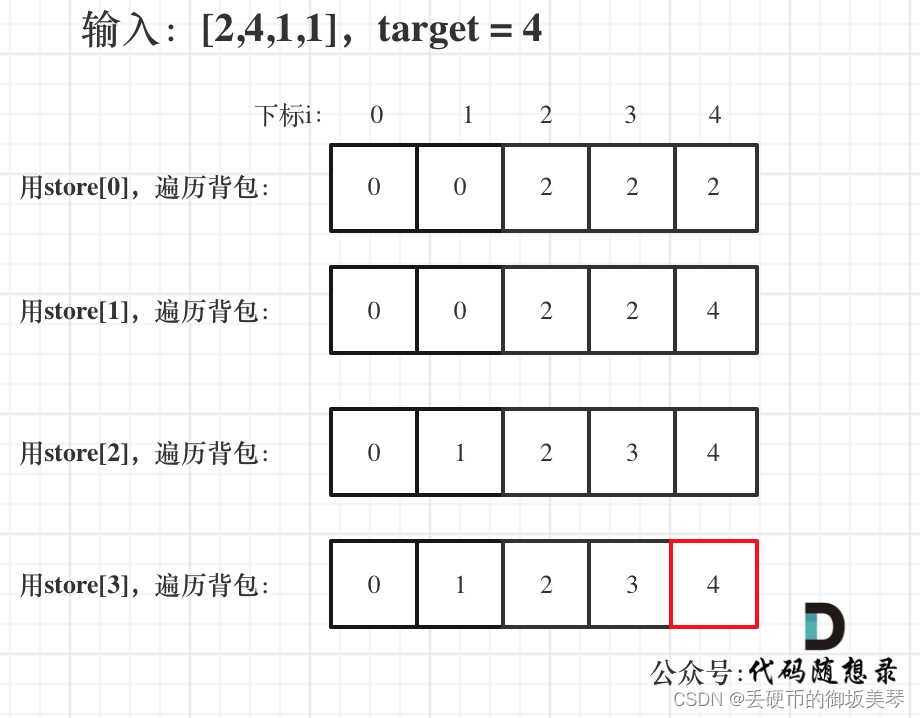
作者:谢其骏
北京航空航天大学在读硕士, Databend 研发工程师实习生
https://github.com/jun0315
论文原文:
Zhaoguo Wang, Zhou Zhou, Yicun Yang, Haoran Ding, Gansen Hu, Ding Ding, Chuzhe Tang, Haibo Chen, Jinyang Li. WeTune: Automatic Discovery and Verification of Query Rewrite Rules. 2022 ACM SIGMOD International Conference on Management of Data (SIGMOD'22)
源码地址:
OpenSource / WeTune · GitLab
本文的贡献:
-
本文借鉴了编译器超优化的思想,通过列举所有有效的逻辑查询计划来尝试发现潜在的等效计划,从而自动发现新的更有效的重写规则。
-
本文还提出了一个新的基于 SMT 的验证器,以验证不同枚举下两个查询的等价性。
Abstract
查询重写将一个关系型数据库的查询转换为一个等价的更高效的查询,这对数据库应用的性能至关重要。这些重写依赖于预先指定的重写规则,在现有的系统中,这些重写规则是通过人工洞察发现的,并在多年中慢慢积累。

图一:Query Rewrite in Apache Calcite
本文介绍了 WeTune,一个自动发现新的重写规则的规则生成器,受到编译器超优化的启发,WeTune 枚举了一定阈值下的所有有效的逻辑查询计划,并试图发现可能导致更有效重写的等效计划。核⼼挑战是确定哪⼀组条件(约束)可以来证明这⼀对查询计划之间的等价性。通过枚举每对查询之间的表及其属性相关的约束的组合情况,来解决这⼀挑战。
本文还提出了⼀种新的基于 SMT 的验证器来验证查询对在不同枚举约束下的等价性。为了评估 WeTune 发现的重写规则的有效性,我们将它们应⽤于从 GitHub 上 20个最流⾏的开源 Web 应⽤程序收集的 SQL 查询。WeTune 成功优化了现有数据库⽆法优化的 247 个查询,从⽽实现了显着的性能提升。
Introduce
查询重写,将原始查询转换为语义等价的替代查询,是查询优化的重要步骤。有效的重写可以将输⼊查询的执⾏时间加快⼏个数量级。重写依赖于指定查询之间等价关系的规则。现有的规则通常由⼈类专家制定,可能需要数⼗年才能积累。
然⽽,仅仅依靠⼈⼯来发现重写规则是不够的。查询语⾔丰富的特性和微妙的语义使得证明等价性和编写规则具有挑战性。但是由于⼿写的重写规则集增⻓⾮常缓慢,错过了许多重写机会。在 Web 应⽤程序开发中普遍使⽤对象关系映射 (ORM) 框架使情况变得更糟。ORM 使程序员⽆需显式构建 SQL 查询,但也会产⽣⾮直观的查询,其模式会避开⼈类制定的规则。
为了了解遗漏重写的影响,我们研究了 Github 上⼏个流⾏的开源 Web 应⽤程序中的 50 个真实查询。所有这些查询都已被开发⼈员重写以修复它们的性能问题。即使是最新版本的 SQL Server 也未能将其中 27 个查询 (54%) 重写为开发⼈员⼿动修复的更⾼效的形式。⼀个这样的查询会导致延迟⻓达 37 秒,⽽其等效的重写查询只需要 0.3 秒。
在本⽂中,我们提出了 WeTune,这是⼀种规则⽣成器,⽆需任何⼈⼯操作即可⾃动发现新的重写规则。从编译器超优化中汲取灵感,它通过穷举搜索找到语义上等效的最佳代码序列,WeTune 旨在通过对所有潜在规则的枚举⾃动发现重写规则,然后对每个⽣成的规则进⾏正确性检查。在此发现过程中,WeTune 依靠启发式⽅法过滤掉那些不太可能提⾼性能的规则,也就是⽐原始查询运算符更多的规则,其余的重写规则被认为是有希望的。
尽管大体的方法比较简单,但是也存在着以下一些挑战:
如何有效的枚举查询规则
a. 一方面需要在有效的搜索空间当中发现具有代表性的查询计划。
b. 另一方面为了产生一般性的规则, 我们需要避免过度严苛的约束条件。
怎么验证这些产生规则的正确性
a. 对一般的 query plan,现存的校验器无法验证正确性。
b. 需要一个新的校验器。
为了应对上述挑战,WeTune 将重写规则表示为查询计划模版和一组与查询计划模版相关的约束。先在运算符阈值以内枚举所有可能的查询计划模版,查询计划模版是通用的,它使用符号而不是具体的表、列和谓词。接着会进一步枚举所有的约束条件,这些条件使得一对查询计划模版在语义上是等价的。
WeTune 使⽤ SQL 验证器验证每个重写规则的正确性。它包括⼀个内置的验证器,它提供了⼀种将重写规则建模为 SMT 公式的方法。然后使⽤ SMT 求解器⾃动解决正确性问题。除了内置的验证器,WeTune 还可以⽀持使⽤现有的 SQL 验证器,如 SPES 来证明正确性。
文中还对 WeTune 在现实世界中的有效性进行了评估,选取了 GitHub 上 20 个最流⾏的 Web 应⽤程序,WeTune 输出 1106 条有希望的重写规则,其中 35 条⽤于优化这些应⽤程序的查询。此外,我们的结果表明,WeTune 可以成功优化现有系统遗漏的 247 个查询,从⽽将延迟减少⾼达 99%。这种优化是由于 WeTune 能够发现任何现有系统都不知道的新重写规则。WeTune 可以成功验证发现的重写规则。
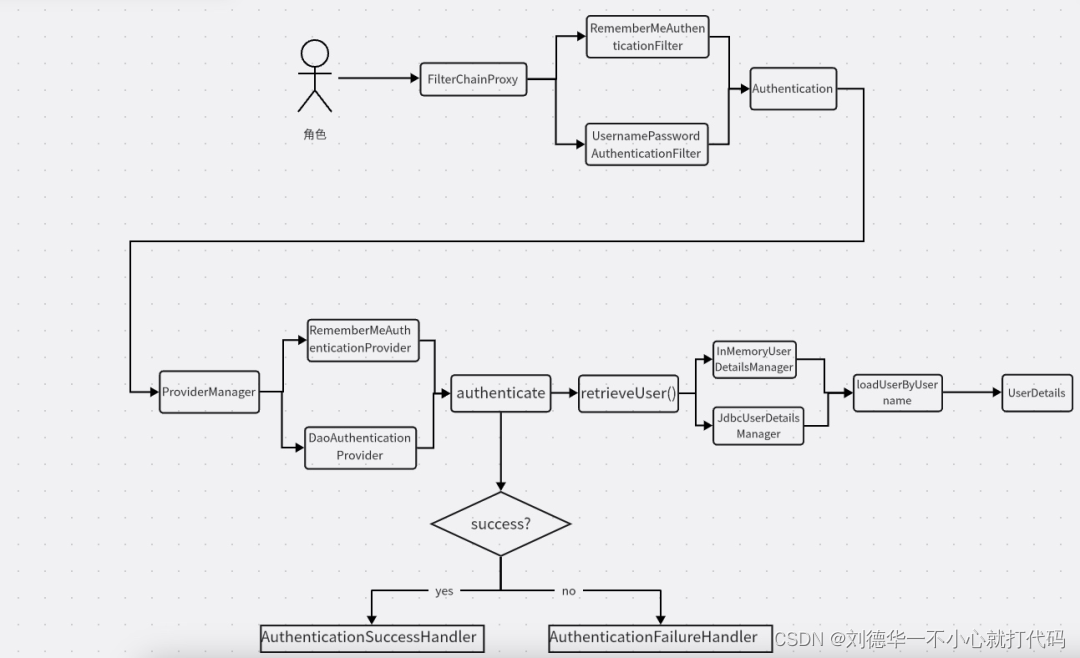
Wetune Approach
WeTune 主要包括三个部分,分别是规则枚举器、规则校验器和有效规则选择器。在 WeTune 中,首先会用规则枚举器通过暴力的算法列举出一切可能的规则,然后再用规则校验器去对每一个规则进行正确性的校验。当我们得到一组经过校验的正确的规则之后,会把它输入到有效规则选择器中,然后有效规则选择器会过滤出一系列的真正能够提高数据库性能的有用的规则。
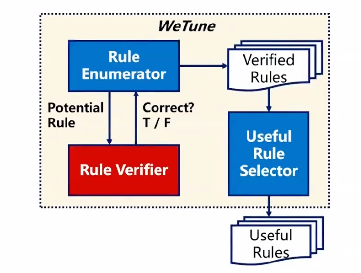
图二:WeTune 主要框架
👨🏻💻 规则枚举器
规则枚举器中总共分为三步,第一步是对所有可能的查询计划模版的一个枚举,第二步是对每一对查询计划模版枚举所有可能的约束条件,第三步是利用规则校验器来找到所有正确的规则。
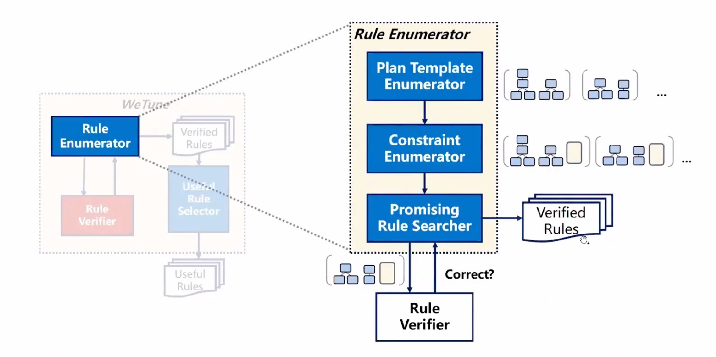
图三:规则枚举器流程图
在具体介绍之前,先介绍上文中提到的一些概念:
1️⃣ 查询计划模版
查询计划模版是一颗树,这棵树上的每一个节点是带有符号化的输入或者是参数的关系代数的算子。在这篇文章中主要支持 6 种关系算子,每一个关系算子里面,每个关系算子的输出都是一个单独的关系。除了 input 算子之外,其他的算子都会需要 1 到 2 个关系作为输入。在查询计划模版中,需要将之前那种具体的参数符号化,用 r 去表示一个关系,用 a 去表示一系列的属性,用 p 表示一个谓词逻辑。

图四:支持的六种关系算子
2️⃣ 规则
规则是一个三元组 (q src ,q dest ,C ) ,分别表示源查询计划模版、目标查询计划模版和约束条件,约束条件是指参数化的约束条件一个集合,用符号来表示一些具体的名字。如果是一个正确的规则,意味着如果约束条件成立,那么源查询计划模版和目标查询计划模版语义等价恒成立。
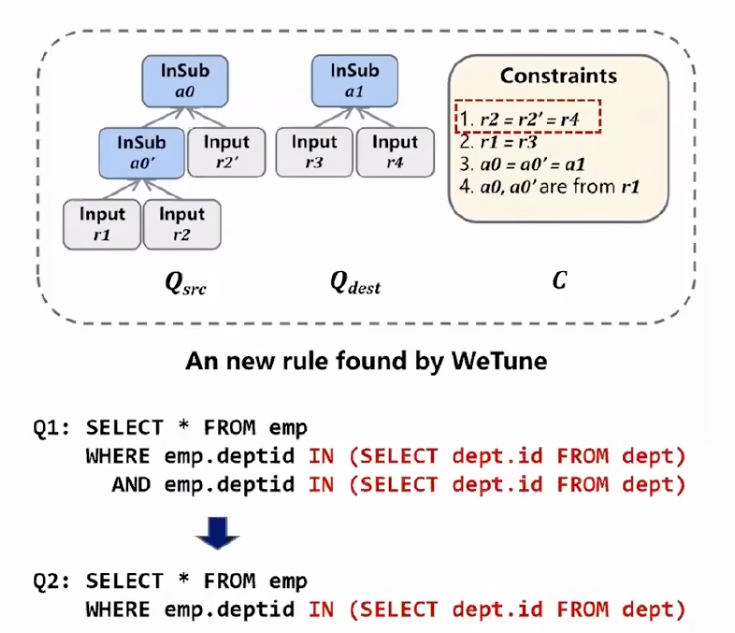
图五:WeTune 发现的一个规则
3️⃣ 枚举查询计划模版
介绍完需要的概念之后,下面介绍规则枚举器的第一步,枚举查询计划模版。我们先从结点数量为一的模版进行枚举,然后当结点数目超过一定数量的时候,就会停止枚举。
下面以最大结点数为 2 进行举例:
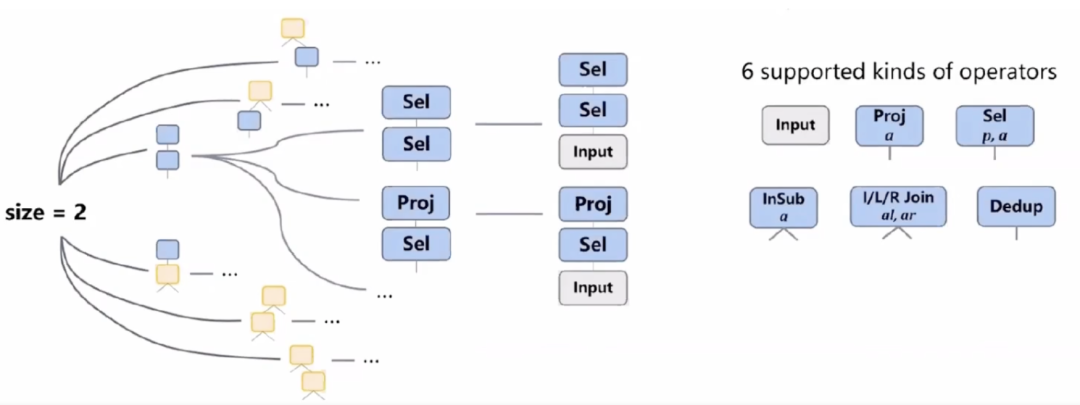
图六:枚举查询计划举例
第一步先列出所有可能的 6 种算子,然后把算子的叶子结点接着填充,当达到最大数量的时候,停止枚举。
4️⃣ 枚举约束条件
找到所有的查询计划模版之后,接着对每一对查询计划模版穷举所有的约束条件,采用的是启发式搜索方法,第一步需要找到一个初始的约束条件集,使得这一对查询计划模版在语义上是等价的,然后再对这个初始约束条件集不断松弛,松弛的目的是让这个规则更具有普遍性,找到初始条件集的一些子集,然后使这些子集也可以让这个等价条件成立。
初始约束条件集是要枚举所有可能的约束条件,本文定义了两类约束条件:
符号关系约束类型
a. RelEq(r1,r2),AttrsEq(a1,a2),PredEq(p1,p2)
b. SubAttrs(a1,a2):每个在 a1 中的属性在 a2 中也有。
完整性约束类型
a. RefAttrs(r1,a1,r2,a2):如果 a1 在 r1 中的话,那么 a2 也在 r2 中。
b. Unique(r,a):r.a 是独一无二的。
c. NotNull(r,a):r.a 是非空的。
把一对查询计划模版中所有可能的约束条件都列出来,这些所有可能的约束条件的集合就形成了初始的约束条件集。找到初始约束条件集合后还要找到最松弛的约束条件子集,最松弛的含义是如果减少当前约束条件集的任何一个条件,那么这个规则都不会恒成立。

图七:规则枚举器算法
在第 11 行中 ProveEq( q src ,q dest ,C * ) 会用到规则校验器。
👨🏻💻 规则校验器
本文提供了两个规则校验器,一个是内置的基于 FOL(一阶逻辑表达式)的规则校验器,另一个是现有的 SQL 等价性校验器 SPES。
1️⃣ 内置规则校验器
内置的规则校验器主要有两个步骤,第一步是把从规则枚举器中传来的规则转换成一阶逻辑表达式,第二步是把一阶逻辑表达式 SMT Solver 中,判断每一个规则是否正确。
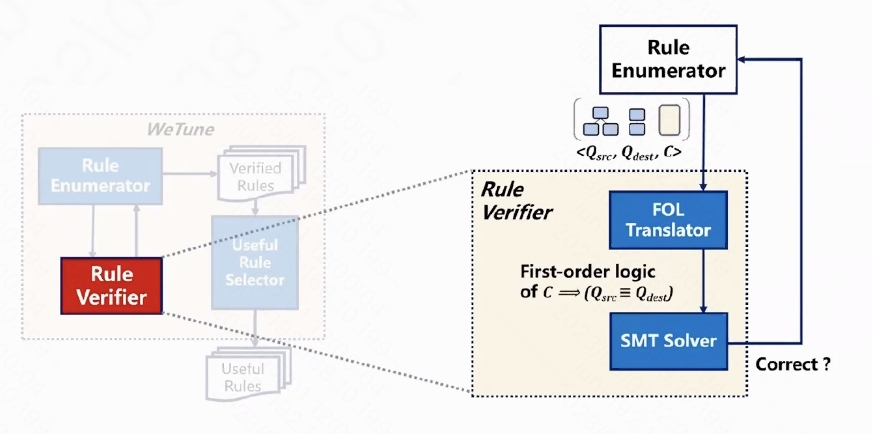
图八:内置规则校验器流程
1.1 规则形式化
给定一个规则,对于 q src 和 q dest ,我们先用 U 表达式来表示,然后再把 U 表达式转换成一阶逻辑表达式。对于 C 约束条件,我们直接转换成一阶逻辑表达式。
U 表达式是在包的语义下对 SQL 查询建模的一种方式,主要描述的是元组在一个关系表里面的出现的次数。
下面是 U 表达式建模的式子:
-

-
为了把查询计划模版转换成 U 表达式,分成了两个步骤:
-
翻译查询计划模版中的符号
-
关系表符号 rel 转换成 ⟦r⟧(t):Tuple->N ,表示元组到自然数的映射。
-
属性符号 attrs 转换成 ⟦a⟧(t):Tuple->Tuple,表示元组到元组的映射。
-
谓词符号 predicate 转换成 ⟦p⟧(t):Tuple->Bool,表示元组到布尔值的映射。
- 在树结构上以遍历的方式翻译查询计划
ToUExpr(q):
<fl,tl>:=ToUExpr(q.child[0]) //None if no child
<fr,tr>:=ToUExpr(q.child[1]) //None if single child
return TranslateByFigure9(q,fl,tl,fr,tr)
图九:SQL 运算符转换成 U 表达式的规则
将查询计划模版转换成 U 表达式之后,再根据图十转换成一阶逻辑表达式。

图十:U 表达式转换成一阶逻辑表达式的规则
接着再根据图十一把约束条件转换成一阶逻辑表达式。

图十一:约束条件转换成一阶逻辑表达式的规则
1.2 验证规则
把查询计划模版和约束条件转换成一阶逻辑表达式之后,接着使用 SMT 求解器来进行检查正确性。
规则的正确性定义为:
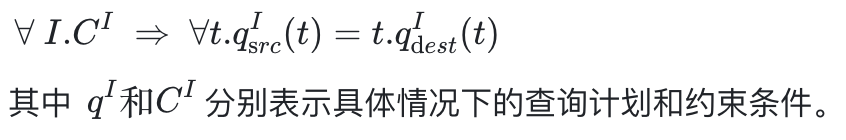
为了证明一阶逻辑表达式的重言性,SMT 检查所有的情况可能会超时。相反,来证明不可满足(UNSAT)要容易得多,当 STM 求解器发现 ¬(C ⇒ ∀t.q src (t)=q dest (t) 是不可满足(UNSAT)的话,那么可以证明规则的正确性。
2️⃣ SPES 校验器
相比于内置的校验器,SPES 校验器还支持 UNION 和 Aggregation 运算符。对于一个给定的规则 〈q src ,q dest , C 〉 ,还需要转换成 SPES 的输入格式。SPES 只接受具体的 SQL 查询,不能识别约束条件集合 C。WeTune 利用 C 把 q src ,q dest 具体化,具体有如下三个步骤:
-
把每一个符号具体命名,放到一个集合里,随机生成一些名字。
-
对于每个属性,找到通过 SubAttrs 约束找到对应的关系表,然后把名字 c 改成 t.c ( t是这个属性 c 所属于的关系表)。
-
通过关系的属性来构建 schema 定义。
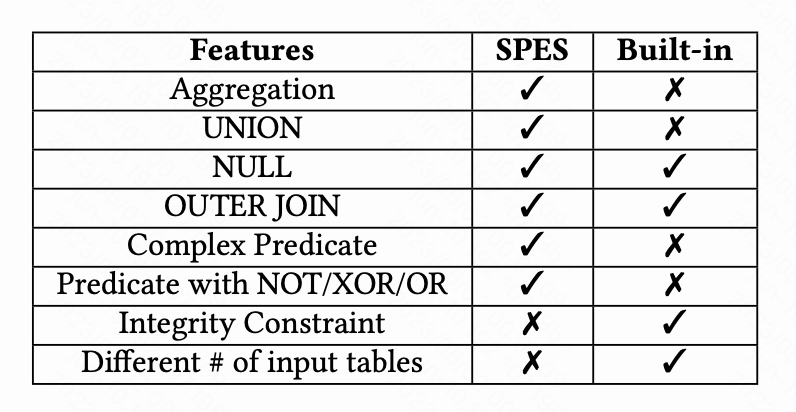
图十二:SPES 和内置校验器能力对比
我们可以发现两者的能力是相互补充的。
👨🏻💻 有效规则选择器
在生成被校验正确的规则后,WeTune 搜集一些真实世界的查询 sql,然后迭代的以贪心的方式(重写后具有最少的算子)来不断利用已有的规则进行优化,会利用已有的 SQL server 的成本估算器(如 MySQL 的 EXPLAIN EXTENDED 和 MS SQL 的 SHOW_PLAN_ALL )来对比重写前后的查询花费。
评估
评估的目的是为了回答以下三个问题:
-
WeTune 可以发现多少新的有用的规则?
-
WeTune 对于已有的系统中可以优化多少新的查询?
-
WeTune 内置的校验器和 SPES 相比如何?
WeTune 在查询计划模版最大节点为 4 的情况下,一共发现了 1106 个正确的规则。
本文在 Github 上选了 20 个 star 最多的开源 web 应用,搜集了一些查询优化的 issue 和一些不同的真实查询,一共收集了 50 个 issue 和 8518 个不同的查询。
在上述的查询中,WeTune 一共有 35 条可以应用的规则,MS SQL Server 缺失了 9 条,Calcite 缺失了 22 条,两个系统中有 5 条规则都缺失了。
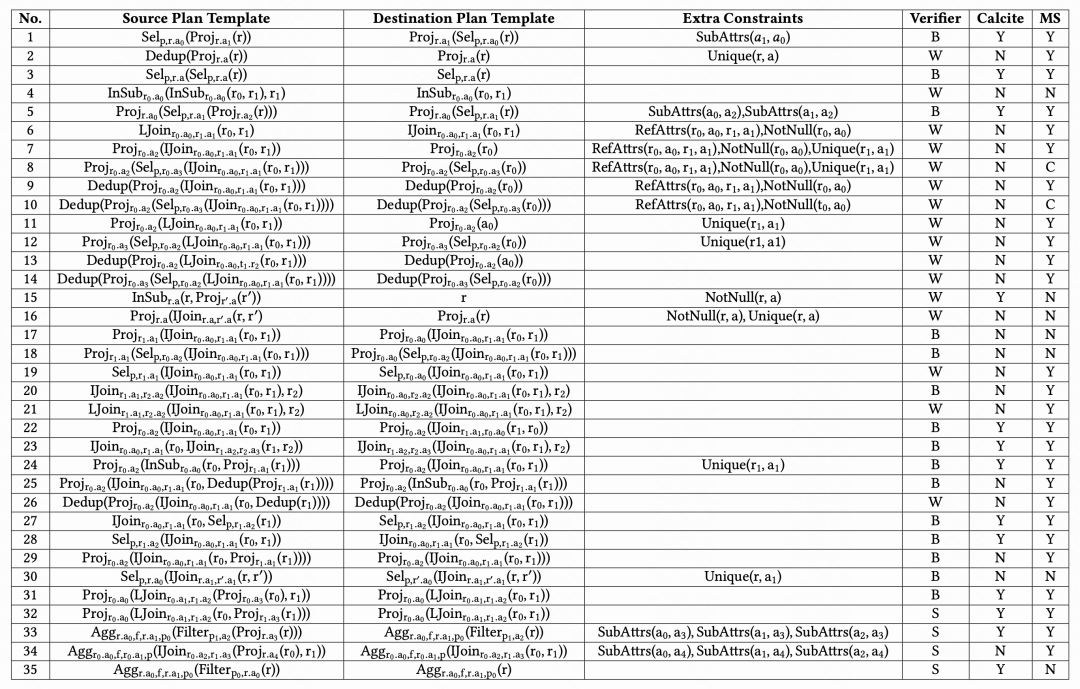
图十三:发现可以应用的规则 (W 表示内置校验器,S 表示 SPES,B 表示两者)
对于收集的 50 个重写优化 issue,WeTune 可以优化 76%(38个),MS SQL Server 和 Calcite 只能优化 46%( 23 个)和 8%( 4 个)。
对于 8518 个查询,WeTune 可以重写优化 674 个,在这其中有 247 个 MS SQL Server 不能重写优化。而这些有 4251 个查询仅包含 SELECT 子句和 WHERE 子句,没有 JOIN,Subquery,Aggregate 和其他的子句,这些往往实际需要在物理执行层进行优化(例如索引选择等),这些超出了 WeTune 的范围,因此结果表明 WeTune 比起现有的数据库可以优化更多的查询。
通过验证规则,内置校验器可以支持完整性约束的规则,SPES 可以支持复杂谓词的规则。
限制
- 内置校验器的不完整性:
只有上述提到的 U 表达式才可以转换成 FOL 并有 STM 求解器验证,同时 SMT 求解器可能会超时,从而错过有用的规则。
- SQL 运算符的有限性:
内置的校验器只能支持上述提到的一些运算符,同时 WeTune 也不支持递归查询。
参考
-
https://ipads.se.sjtu.edu.cn/_media/publications/wetune_final.pdf
-
WeTune: Automatic Discovery and Verification of Query Rewrite Rules | Proceedings of the 2022 International Conference on Management of Data
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:https://databend.cn
📖 Databend 文档:Databend - The Future of Cloud Data Analytics. | Databend
💻 Wechat:Databend
✨ GitHub:GitHub - datafuselabs/databend: A modern cloud data warehouse focusing on reducing cost and complexity for your massive-scale analytics needs. Open source alternative to Snowflake. Also available in the cloud: https://app.databend.com 🧠