1.基础读写指令
写内存指令:STR
@ MOV R1, #0xFF000000
@ MOV R2, #0x40000000
@ STR R1, [R2]
@ 将R1寄存器中的数据写入到R2指向的内存空间需注意,此命令是将R1中的数据写给R2所指向的内存空间,而不是直接把R1的数据赋给R2,R2寄存器中存放的是数据要被写入的内存的起始地址,由于使用的是STR指令,所以R2中存放的地址时不会改变的,如果后续再次向R2所指向的内存中写数据,则原来的数据会被覆盖。
读内存指令:LDR
@ MOV R1, #0xFF000000
@ MOV R2, #0x40000000
@ LDR R3, [R2]
@ 将R2指向的内存空间中的数据读取到R3寄存器原理基本同上,是将R2存放的地址指向的空间中的数据读取到R3寄存器中
读写指定的数据类型:
在ARM中有三种数据类型,Byte类型占一个字节,Halfword类型占两个字节,Word类型占四个字节,如果我们指向读取某个数据类型的数据,只需要在读写指令后加上后缀即可,示例如下:
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@Byte类型:
@ STRB R1, [R2]
@ 因为Byte类型占一个字节也就是8bit,
@所以指令的含义是将R1寄存器中的数据的前8位写入到R2指向的内存空间
@Halfword类型:
@ STRH R1, [R2]
@ 将R1寄存器中的数据的前16位写入到R2指向的内存空间
@Word类型:
@ STR R1, [R2]
@ 将R1寄存器中的数据的前32位写入到R2指向的内存空间
@ LDR指令同样支持以上后缀,并且含义相同2.基址加变址寻址:
前索引和后索引:
由其定义可知,我们要操作的地址变成了 基本地址 + 可变地址,如下程序所示,要进行读写操作的内存的地址变成了中括号中的数据的和。
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ MOV R3, #4
@ STR R1, [R2,R3]
@ 将R1寄存器中的数据写入到R2+R3指向的内存空间,也就是0x40000004指向的地址空间
@ STR R1, [R2,R3,LSL #1]
@ 将R1寄存器中的数据写入到R2+(R3<<1)指向的内存空间上面代码中将可变地址R3写入中括号里的方法叫做基址加变址寻址的前索引方式,而将其写在中括号后为后索引方式,他们俩的含义如下:
@ 前索引
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2,#8]
@ 将R1寄存器中的数据写入到R2+8指向的内存空间
@ 后索引
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2],#8
@ 将R1寄存器中的数据写入到R2指向的内存空间,然后R2自增8自动索引:
除了他们俩之外,还有一种索引叫做自动索引,其定义如下:
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2,#8]!
@ 将R1寄存器中的数据写入到R2+8指向的内存空间,然后R2自增8需注意,自动索引! 的位置是不能改变的并且 必须要是英文的
3.多寄存器内存访问指令:
多寄存器内存访问指令,其含义就是同时读写多个寄存器中的数据,示例如下:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STM R11,{R1-R4}
@ 将R1-R4寄存器中的数据写入到以R11为起始地址的内存空间中
@ LDM R11,{R6-R9}
@ 将以R11为起始地址的内存空间中的数据读取到R6-R9寄存器中与单独读写一个寄存器的数据相比,指令由STR和LDR变成了STM和LDM,其存放 要进行读或写操作的地址 的寄存器变成了目标寄存器,也就是作为了指令后的第一个参数,要被读入或写的数据所要存放的寄存器被放在一个大括号中,ARM会依次将其读取或写入到相应的位置,大括号中的写法也可以使用逗号隔开,例如{R1,R2,R3,R4},但是无论其顺序怎么改变,他在进行操作时都是低地址对应小号的寄存器,例如上边程序的写指令即使写成 STM R11,{R2,R1,R4,R3} 他在写入到R11为起始地址的内存空间中时也是先将R1存放到底地址0x4000020当中,读指令也是如此。
自动索引也同样适用于多寄存器内存访问指令,只是感叹号位置发生了改变,具体如下:
@ STM R11!,{R1-R4}执行完这条指令后,R1-R4会被依次写入在R11指向的地址处,因为写入了四个数据,所以R11所储存的地址会自增16个字节。
多寄存器内存访问指令的寻址方式:
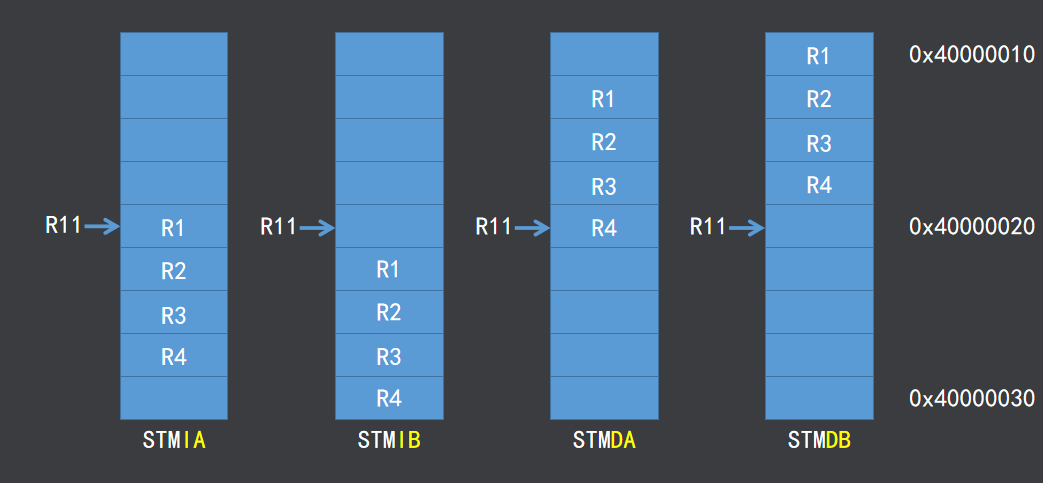
STM指令与LDM指令有四个后缀,分别为IA,IB,DA,DB,下面的这些都是在其有自动索引时的解释,其意义分别为:
- STMIA R11! :先储存数据,然后地址在增加
- STMIB R11! : 地址先增加,然后再储存数据
- STMDA R11! :先储存数据,然后地址递减
- STMDB R11! :地址先减少,然后再储存数据
如下图所示,我用大白话形容一下,IA就是先把你要写入的第一条数据先写进R11存放的地址中,然后再将R11的地址增加去存放下一个数据,直到数据全部存完后R11的地址在增加一次指向写入的最后一个数据的下一个地址,IB就是先让R11的地址增加一次,然后再开始写入数据,最后R11的地址会指向所写入的最后一条数据。DA和DB只是存储方向相反而已,方式是相同的,注意写入数据和增加地址的过程是一一对应的,写一条就要加一次,数据是一条一条存放到内存中而不是一下全放进去然后地址一次性增加。
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STMIA R11!,{R1-R4}
@ 先存储数据,后增长地址
@ STMIB R11!,{R1-R4}
@ 先增长地址,后存储数据
@ STMDA R11!,{R1-R4}
@ 先存储数据,后递减地址
@ STMDB R11!,{R1-R4}
@ 先递减地址,后存储数据ARM使用的大多是
4.ARM栈的种类与使用:
概念:栈的本质就是一段内存,程序运行时用于保存一些临时数据,如局部变量、函数的参数、返回值、以及程序跳转时需要保护的寄存器等
栈的分类:
- 增栈:压栈时栈指针越来越大,出栈时栈指针越来越小
- 减栈:压栈时栈指针越来越大,出栈时栈指针越来越小
- 满栈:栈指针指向最后一次压入到栈中的数据,压栈时需要先移动栈指针到相邻位置然后再压栈
- 空栈:栈指针指向最后一次压入到栈中的数据的相邻位置,压栈时可直接压栈,之后需要将栈指针移动到相邻位置
增减和空满是组合在一起的,栈分为空增(EA)、空减(ED)、满增(FA)、满减(FD)四种,EA对应上面的IA,ED对应DA,FA对应IB,FD对应DB可以对应ARM处理器一般使用满减栈,所以对ARM的栈做存储操作时可以直接使用FD后缀
叶子函数:一个函数里没有调用其他函数,那么他就是叶子函数
汇编中进行跳转的过程就在下面代码中,程序自己理解吧,等哪天我在把具体的步骤写一下哈哈哈
示例:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STMFD R11!,{R1-R4}
@ LDMFD R11!,{R6-R9}
@ 栈的应用举例
@ 1.叶子函数的调用过程举例
@ 初始化栈指针
@ MOV SP, #0x40000020
@ MIAN:
@ MOV R1, #3
@ MOV R2, #5
@ BL FUNC
@ ADD R3, R1, R2
@ B STOP
@ FUNC:
@ 压栈保护现场
@ STMFD SP!, {R1,R2}
@ MOV R1, #10
@ MOV R2, #20
@ SUB R3, R2, R1
@ 出栈恢复现场
@ LDMFD SP!, {R1,R2}
@ MOV PC, LR
@ 2.非叶子函数的调用过程举例
@ MOV SP, #0x40000020
@ MIAN:
@ MOV R1, #3
@ MOV R2, #5
@ BL FUNC1
@ ADD R3, R1, R2
@ B STOP
@ FUNC1:
@ STMFD SP!, {R1,R2,LR}
@ MOV R1, #10
@ MOV R2, #20
@ BL FUNC2
@ SUB R3, R2, R1
@ LDMFD SP!, {R1,R2,LR}
@ MOV PC, LR
@ FUNC2:
@ STMFD SP!, {R1,R2}
@ MOV R1, #7
@ MOV R2, #8
@ MUL R3, R1, R2
@ LDMFD SP!, {R1,R2}
@ MOV PC, LR
@ 执行叶子函数时不需要对LR压栈保护,执行非叶子函数时需要对LR压栈保护

![[CTF/网络安全] 攻防世界 Training-WWW-Robots 解题详析](https://img-blog.csdnimg.cn/11f1d8d9089c44e3a49a585fe4222f57.png#pic_center)


![[Hadoop]MapReduce与YARN](https://img-blog.csdnimg.cn/3e30448c90074f74b9ee4196accc5b10.png)