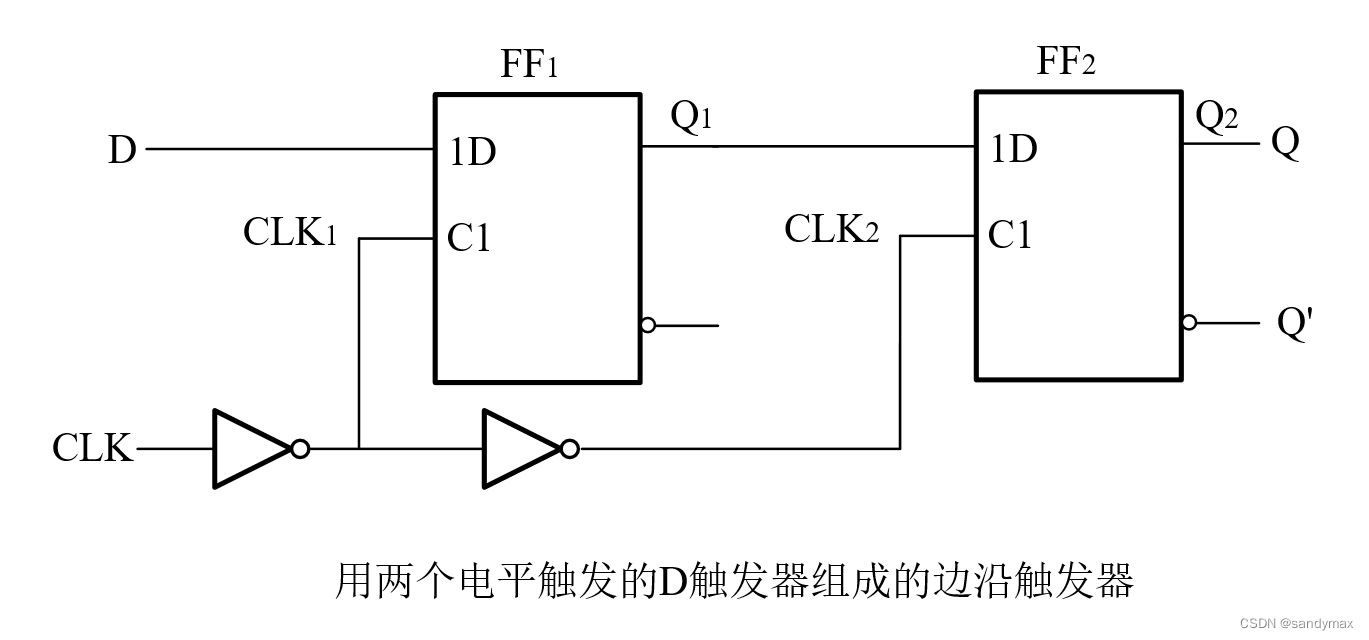
Drive&Act:A Multi-modal Dataset for Fine-grained Driver Behavior Recognition in Autonomous Vehicles
- 摘要
- 1. 简介
- 2. 其它驾驶员动作数据集
- 3. Drive&Act数据集
- 3.1 数据采集
- 3.2 记录的数据流
- 传感器设置和视频流
- 3D Body Pose
- 3D Head Pose
- Interior Model
- Activity Classes
- 数据分段 Data Splits
- 4. 驾驶员动作的层次词汇表
- 4.1 场景/任务
- 4.2 Fine-grained Activities
- 4.3 Atomic Action Units
- 4.4 Additional Annotations
- 5. 自动驾驶情景下的动作识别模型
- 5.1 End-To-End模型
- 5.2 人体姿态和汽车内部结构
- 6. Benchmarks 和实验结果
- 6.1 驾驶员动作识别
- (1)细粒度的活动
- (2)原子作用单位分类
- (3)场景识别/任务
- 6.2 多视图和多模态动作识别
- 6.3 Cross-View 动作识别
摘要
- 本文引入了一种新的特定领域的Drive&Act基准,用于对驾驶员行为进行细粒度分类。
- 数据集包含了12个小时,超过960万帧的人在手动驾驶和自动驾驶期间从事分心活动。
- 从六个视图中捕获颜色,红外,深度和3D身体姿势信息,并使用分层注释方案密集标记视频,从而得到83个类别。
- 数据集面临的主要挑战是:
(1)识别车辆舱内的细粒度行为;
(2)多模态活动识别,关注多种数据流;
(3)cross-view识别基准,其中模型处理来自不熟悉领域的数据,因为传感器的类型和座舱中的位置可能会在车辆之间发生变化。 - 最后,通过采用突出的基于视频和身体姿势的动作识别方法提供具有挑战性的基准。
1. 简介
- 虽然自动化的兴起鼓励了驾驶员的分心行为,但大多数计算机视觉研究都集中在理解车外的情况上。
- 同时,观察车内的人对改善人车通信、动态驾驶适应性和安全性具有很大的潜力。
- 据估计,大多数交通事故涉及方向盘后的次要活动,如果不发生分心,36%的碰撞是可以避免的。
- 虽然未来的驾驶员将逐渐从主动驾驶汽车中解脱出来,但向完全自动化水平的过渡是一个长期的过程。
- 过度依赖自动化可能会导致灾难性的后果,而且在很长一段时间内,司机将需要在不确定的情况下进行干预。
- 除了出于安全考虑识别驾驶员分心之外,驾驶员活动识别可以增加舒适性,例如,当人在喝咖啡、打开灯、读书时,可以调整驾驶风格。
- 驾驶员行为识别与更广泛的动作识别领域密切相关,由于深度学习的兴起,该领域的性能数据迅速增加。
- 这样的模型需要大量的数据,并且经常在基于颜色的大型数据集上进行评估,这些数据集通常来自Youtube,经过精心挑选,具有高度歧视性的操作。
- 可能是由于训练此类模型的数据集不足,对驾驶员活动理解的研究远远落后。
- 现有的工作通常是在仅限于对很少的低级动作进行分类(例如,人是否握着方向盘或换挡)。现有的基准都没有涵盖更高级别的活动(例如换衣服),尤其是在高度自动驾驶的情况下。
- 论文的目标是促进现实驾驶条件下的活动识别研究,如低光照和有限的身体能见度,并提出了新的Drive&Act数据集。
- Drive&Act提供了与活动识别模型的实际应用相关的各种潜在挑战,并且是第一个公开可用的数据集,它结合了以下属性:
(1)在自动驾驶和手动驾驶环境下的驾驶员次要活动(共83个类别)。
(2)多模态: 颜色、深度、红外和身体姿势数据,因为传统的基于rgb的动作识别数据集忽略了低照度的情况。
(3)多视图: 六个同步的摄像头视图覆盖车辆舱室,以处理有限的车身能见度。
(4)分层活动标签:在包括上下文注释的三个抽象和复杂级别上。
(5)单个类之间的细粒度区分 (如开瓶和闭瓶),动作持续时间和复杂性的高度多样性,这对动作识别方法提出了额外的挑战。(例如,从里面开门通常需要不到一秒钟的时间,而阅读一本杂志可能需要几分钟) - 除了自动驾驶应用之外,该数据集还填补了在多个抽象层次上进行简洁识别的大型多模态基准的不足。
- 对基于视频和身体姿势的动作识别的最新方法进行了广泛的评估,表明基准测试的难度,突出了进一步广泛的动作识别研究的必要性。
2. 其它驾驶员动作数据集
- AUC Distracted Driver Dataset
相关论文:Real-time Distracted Driver Posture Classification
3. Drive&Act数据集
为了解决缺乏特定领域行为识别基准的问题,我们收集并公开发布了Drive&Act数据集,其中包括驾驶员在手动和自动模式下驾驶时从事次要任务的12小时数据。
3.1 数据采集
- 在静态驾驶模拟器中收集数据集。
- 使用SILAB仿真软件1,在改装后的奥迪A3周围的多个屏幕上模拟和投影车辆周围的环境。
- 手动、自动驾驶和接管都可以在我们的设置中诱导。
- 为了鼓励多样化和积极主动的行为,在每个会话中,驾驶员被指示完成12个不同的任务(图1中说明了两个指令示例)。
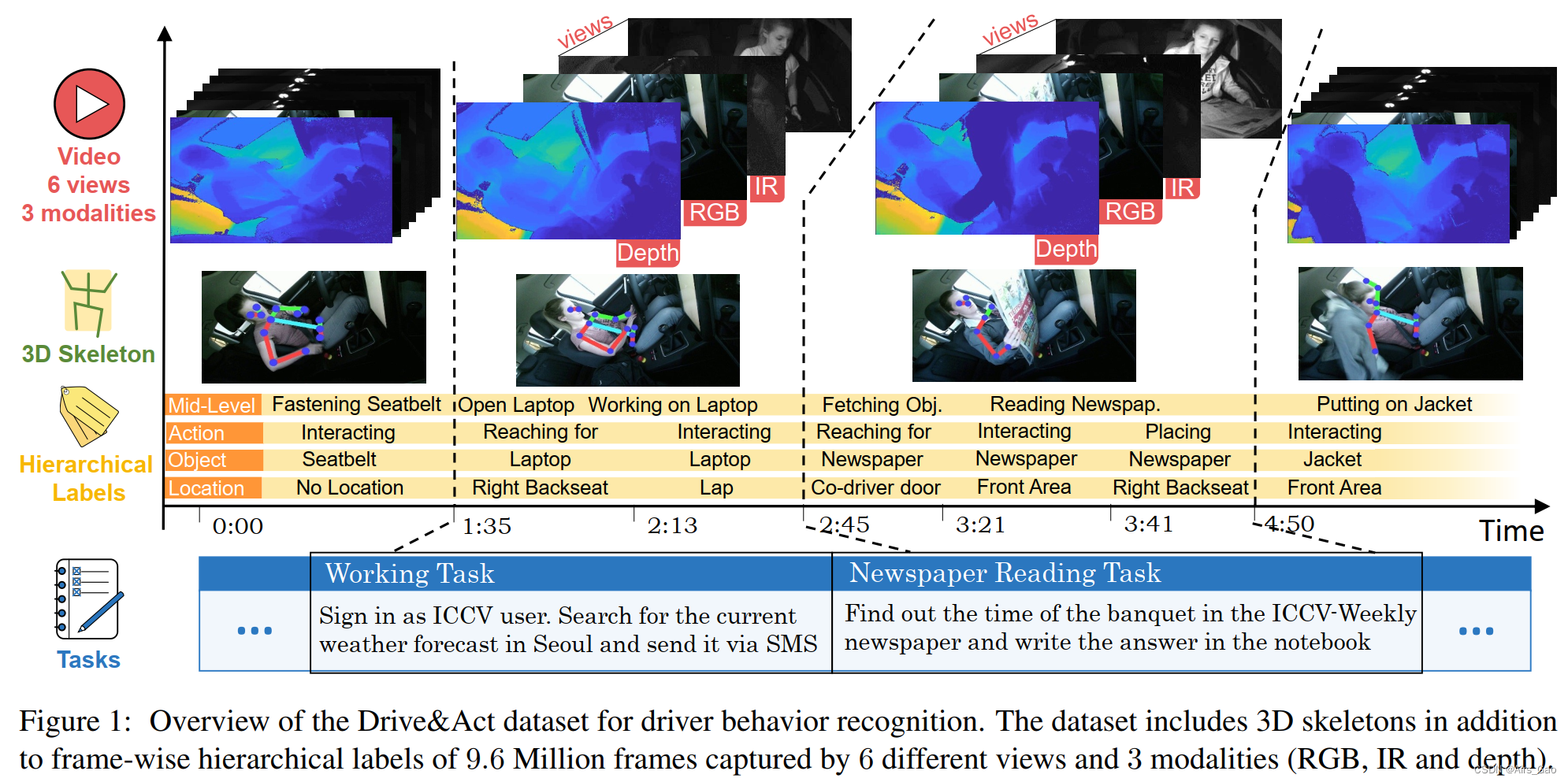
第一个任务包括进入汽车,进行调整,开始手动驾驶,并在几分钟后切换到自动模式。
所有下面的指示(例如,用笔记本电脑查找当前的天气预报,并通过短信报告),在安装的平板电脑上以随机顺序给出。
虽然大多数任务都是在自动驾驶时完成的,但在每个会话中,都会触发四个意外接管请求。
因此,这段旅程至少需要手动进行一分钟。虽然明确给出了粗任务的顺序,但它们执行的确切方式(即细粒度活动)留给了主体。 - 15人,4名女性和11名男性,参与了数据收集。为了促进多样性,我们选择了不同身高和体重、不同驾驶风格以及对辅助系统和自动化模式熟悉程度的参与者。所有参与者都被记录了两次,结果是30次驾驶,平均持续时间为24分钟。
3.2 记录的数据流

传感器设置和视频流
- 两种类型的静态定位摄像机覆盖车辆舱室: 5个近红外摄像机(NIR)(分辨率1280 × 1024像素,30 Hz),1个微软Kinect,用于获取颜色(950 × 540像素,15HZ),红外线(512 × 424 at 30 Hz)和深度数据(512 × 424 at 30 Hz)。
- 设置是专门为现实的驾驶条件,如低照明设计的。
- 目标是将活动识别模型从传统的颜色输入中解脱出来,因此青睐轻型近红外相机,这在夜间也很有效。
- 尽管如此,还是通过Kinect传感器,在尺寸上不太实用,但在研究界很受欢迎。
3D Body Pose
- 为了确定具有13个关节的3D上半身骨架,我们使用OpenPose,这是2D身体姿势估计的流行选择。
- 通过对3个正面视图(右上、前上、左上)的2D姿态进行三角测量获得3D姿态。
- 附加的后处理应用于填补缺失的关节使用插值相邻帧。
3D Head Pose
- 为了获得驾驶员的3D头部姿态,我们采用了流行的OpenFace神经架构。
- 由于这个模型有很大的头部旋转困难,我们确定了除后置摄像头以外的所有视图的头部姿势。
- 对于每一帧,只有一个子集的所有摄像机预测头部旋转成功。
- 从这些候选对象中,我们选择具有最正面视图的相机的结果,并将其转换为世界坐标。
Interior Model
- 我们还提供基于3D原语的汽车内部特征,这些原语描述了驾驶员与周围环境的交互。
- 这种表示包括汽车中不同存储空间的位置信息(例如座椅或脚踏)和汽车控制(例如方向盘、安全带和变速杆),这些信息在过去已成功应用于驾驶员观察。
Activity Classes
- 录制的视频帧由人类注释者在三个抽象级别上手动标记,总共产生83个动作类。
- 它的目标是高级场景、细粒度活动(保留语义意义)和低级原子操作单元(表示环境和对象交互)。
数据分段 Data Splits
- 由于我们的目标是对新驾驶员的泛化进行评级,因此我们只对分类器以前未见过的人评估模型。
- 我们根据驾驶人的身份将数据集随机分为3个Splits。
- 对于每个Split,我们使用10个受试者的数据进行训练,2个受试者的数据进行验证,3个驾驶员的数据进行测试 (即分别为20,4和6个驾驶session)。
- 由于标注的动作持续时间各不相同,我们将每个动作段分成3s 或更少,并将它们用作基准测试中的样本。
- 提供评估脚本,以方便比较结果。
4. 驾驶员动作的层次词汇表
-
为了充分代表真实的驾驶情况,我们使用三种类型的来源对人工驾驶期间的次要任务进行了全面的综述:
(1)司机访谈,(2)警察对事故的回顾,(3)自然的汽车研究。 -
选择车内场景的关键因素是驾驶时参与活动的频率以及行为对驾驶员注意力的影响(例如,通过增加事故几率)。
-
结果显示,学生们对诸如打电话、在笔记本电脑上工作、搜索东西和识别基本身体动作等类别很感兴趣
(比如伸手去拿地板上的东西),而吸烟等行为则被认为不那么有用。 -
某些类别,如睡眠,由于技术可行性而被省略。
-
从八个方面定义了相关驾驶员活动的词汇: 饮食,服装和配饰,工作,娱乐,进出和车辆调整,身体运动,物体操纵和使用车辆内部设备。
-
我们最后的词汇包括三个粒度级别上的83个活动标签,构建了一个基于复杂度和持续时间的三个级别的层次结构。
4.1 场景/任务
- 我们的受试者在每个阶段必须完成的12项任务(第3.1节)形成了我们的层次结构的第一级,这些任务要么是手动驾驶时的典型场景(例如吃喝),要么是高度分散注意力的场景,这些场景随着自动化程度的提高而变得普遍(例如使用笔记本电脑)。
- 图4显示了场景的帧频分析,显示了我们的受试者将大部分时间(23%)花在娱乐任务(即观看视频)上,而在接到接管请求后手动驾驶的时间最短。
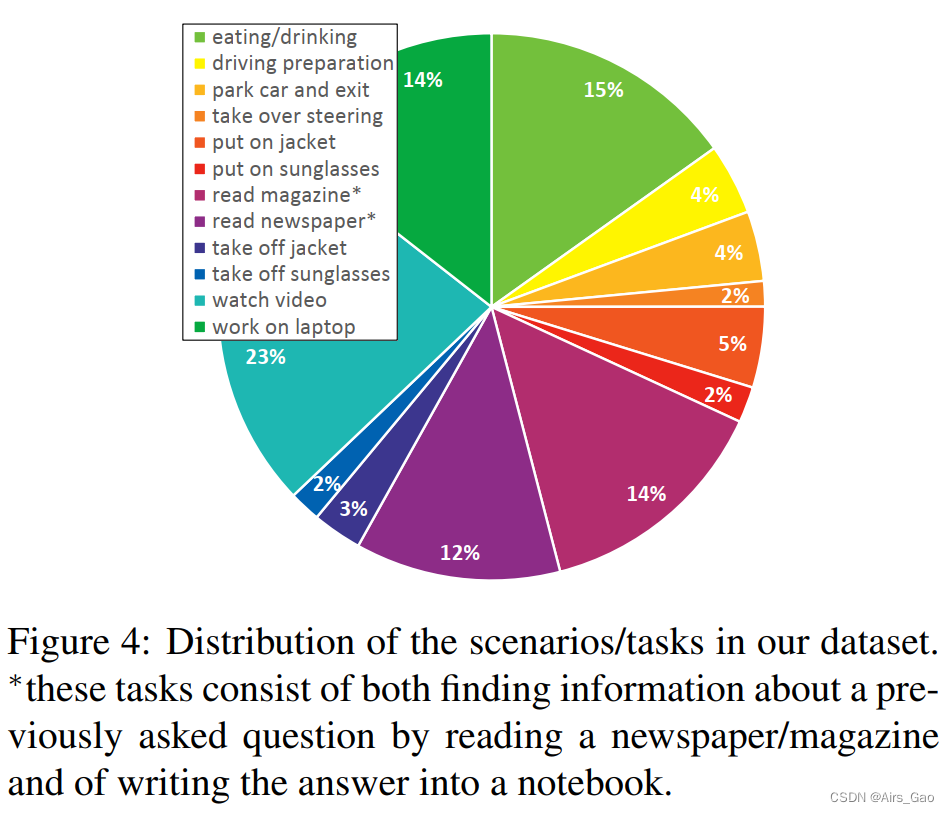
- 接管场景很特别,因为受试者被意外地要求中断他正在做的事情,接管并切换到手动驾驶。
- 分析对此类事件的反应(例如与先前活动或个人年龄的关系)是一个潜在的安全相关研究方向。
4.2 Fine-grained Activities
- 第二级表示细粒度的活动(Fine-grained Activities),将场景/任务分解为34个简洁的类别。
- 与即将到来的第三级原子动作(atomic action)单元相比,第二级类保留了明确的语义。
- 这些细粒度的活动在场景中自由交替,即不告诉驱动程序如何详细执行任务。
- 当然,不同程度的抽象之间有很强的因果关系,因为组合行为通常包含多个更简单的操作。
- 在这个层次上识别的一个关键挑战是类别的简洁性,就像我们区分关闭瓶子和打开瓶子,或者区分吃饭和准备食物一样。
- 我们认为,这种详细的区分对于应用非常重要,因为场景的粗组成部分(即车辆舱室或松散的身体位置)通常保持相似,并且相关的类别差异发生在比传统动作识别基准更小的规模上。
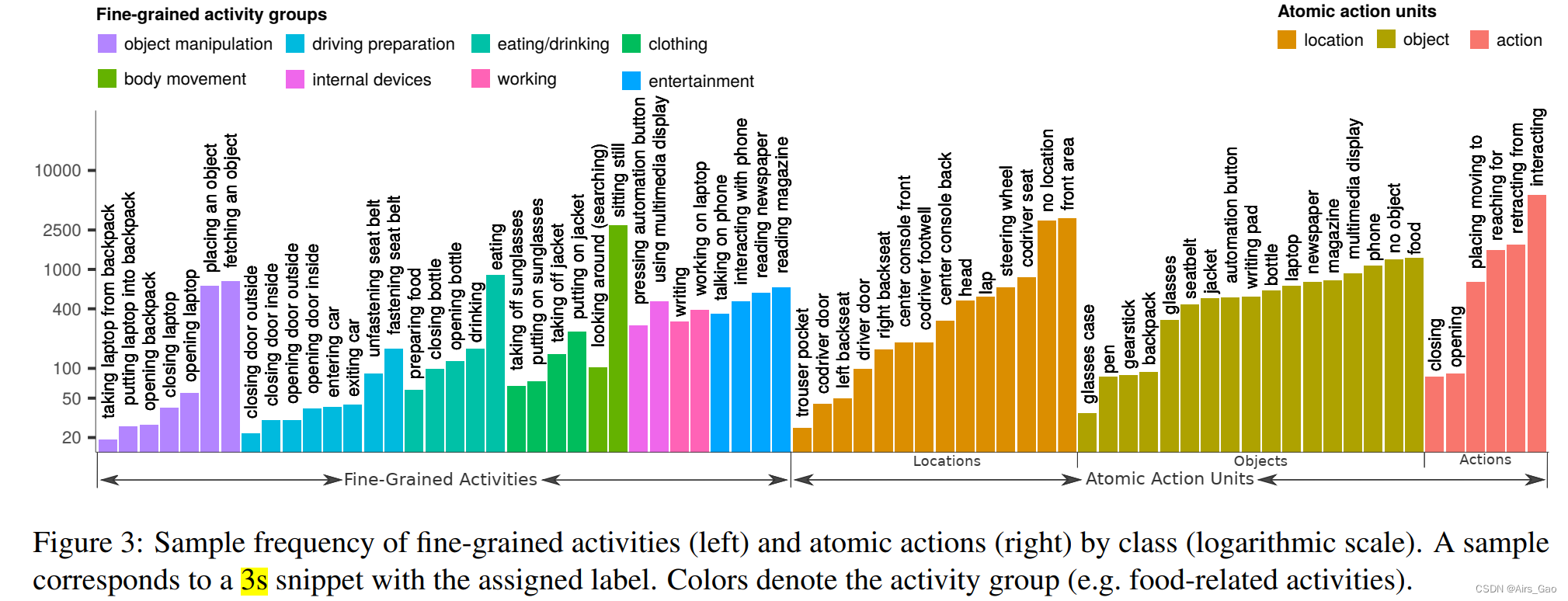
- 由于如此详细的注释,单个类的频率是变化的,如图3所示,图3显示了类分布的分析。
- 我们的数据集平均每个类别有303个样本,从背包里拿笔记本电脑是最少的(19个样本),而坐着不动是最常见的类别(2797个样本)。
- 虽然我们将 3s 作为我们的样本(第3.3节),但完整片段的持续时间因活动而异。
4.3 Atomic Action Units
- 原子操作单元 (Atomic Action Units) 的注释描述了最低程度的抽象,是与环境的基本驱动交互。
- 行动单元脱离了长期的语义意义,可以看作是前一级复杂活动的构建块。
- 我们将原子动作单元定义为动作、对象和位置的三元组。
- 我们涵盖了5种类型的动作(例如伸手),17个对象类(例如书写板)和14个位置注释 (例如副驾驶脚井),其分布如图3所示。
- 总的来说,在我们的数据集中捕获了372种可能的动作、对象和位置组合。
4.4 Additional Annotations
- 我们进一步提供驾驶环境的密集注释,表明驾驶员是处于自动驾驶模式,还是用左手、右手或双手驾驶。
- 我们还包括接管请求的时间戳和模拟器内部信号,例如方向盘角度。
5. 自动驾驶情景下的动作识别模型
-
为了更好地理解最先进算法在我们数据集上的性能,我们对各种方法及其组合进行了基准测试。
-
我们将这些算法分为两类:
(1)基于body pose和3D feature的方法;
(2)基于卷积神经网络(cnn)的端到端方法. -
虽然基于cnn的模型通常是传统动作识别数据集的领跑者,但它们处理非常高维的输入,并且对训练数据的数量和领域变化(如相机视图变化)更加敏感。
5.1 End-To-End模型
- 在基于图像的动作识别中,模型直接对视频数据进行操作,即没有明确定义中间表示,而是通过cnn学习。
- 接下来,我们描述了三个突出的基于cnn的动作识别架构,我们将其用于我们的任务。
(1)C3D
C3D模型是第一个广泛使用的利用3D卷积进行动作识别的CNN。C3D由8个卷积层(3 × 3 × 3核)和5个池化层,然后是两个完全连接的层。
(2)Inflated 3D ConvNet
目前,最先进的动作识别技术是Inflated 3D架构 (I3D)。该架构建立在Inception-v1网络的基础上,通过使用额外的时间维度扩展2D过滤器。
(3)P3D ResNet
与之前的型号不同,P3D ResNet架构通过将空间域(即3 × 3 × 1)上的滤波器与时间维度上的滤波器相结合,使用3 × 3 × 3内核模拟3D卷积(即1 × 1 × 3)。此外,由于残差连接在动作识别领域的有效性,P3D ResNet利用了残差连接。
5.2 人体姿态和汽车内部结构
- 与基于cnn架构生成的中级特征图相比,3D身体姿势能够提供有关驾驶员当前活动的信息线索,同时仍然保持人类的可解释性。
- 因此,我们采用了基于骨骼的方法,将空间流和时间流结合起来,共同建模身体动力学和骨骼空间构型。每个流由堆叠的两层LSTM单元,跟随一个softmax 的全连接层构成。
- 该架构已经被Martin等人用于驾驶员动作识别,他们将带有汽车内部信息的网络扩展为三流架构。
- 分别描述三个流的分布:
(1)Temporal Stream:为了对驾驶员身体的运动动态进行编码,在每个时间步骤中,我们通过连接将所有13个关节联合起来,并在架构的第一个流中使用生成的向量。
(2)Spatial Stream:第二个流通过在每一步向循环网络提供单个关节的表示来编码关节的空间依赖性。为了平面化基于图的身体姿态表示,使用了遍历方案。
(3)Car-Interior Stream:由于场景中物体的位置可以提供当前动作的重要线索,因此我们还向模型提供了汽车内部的表示。为了利用这些数据,我们确定了手和头到数据集内部模型中提供的每个物体表面的距离。这有助于网络学习汽车内部和执行动作之间的关系。
(4)Combined Models:将时空流通过加权后期融合相结合。这个模型在下面被称为Two-Stream。再加入Car-Interior作为第三流的扩展模型,下面称为Three-Stream。
6. Benchmarks 和实验结果
- 在当前版本的基准测试中,我们专注于驾驶员行为的细粒度分类,并将其扩展到多模式和交叉视图设置。
- 给定一个3秒或更短的动作片段(在较短事件的情况下),我们的目标是分配正确的活动标签。
- 我们遵循标准实践,通过使用每个类别的 top-1 识别率的平均值,采用average per-class accuracy。
- 注意,随机基线是特定于注释水平的,在0.31%和16.67%之间变化。
6.1 驾驶员动作识别
- 我们对每个层次结构级别分别评估我们的模型:
12个场景/任务(第一级),
34个细粒度活动(第二级),
372个{action, Object, Location}三元组可能组合的原子操作单元(第三级)。因为三元组的数量是非常多的,我们还分别报告正确分类的动作、目标和位置的性能(6,17和14类)。
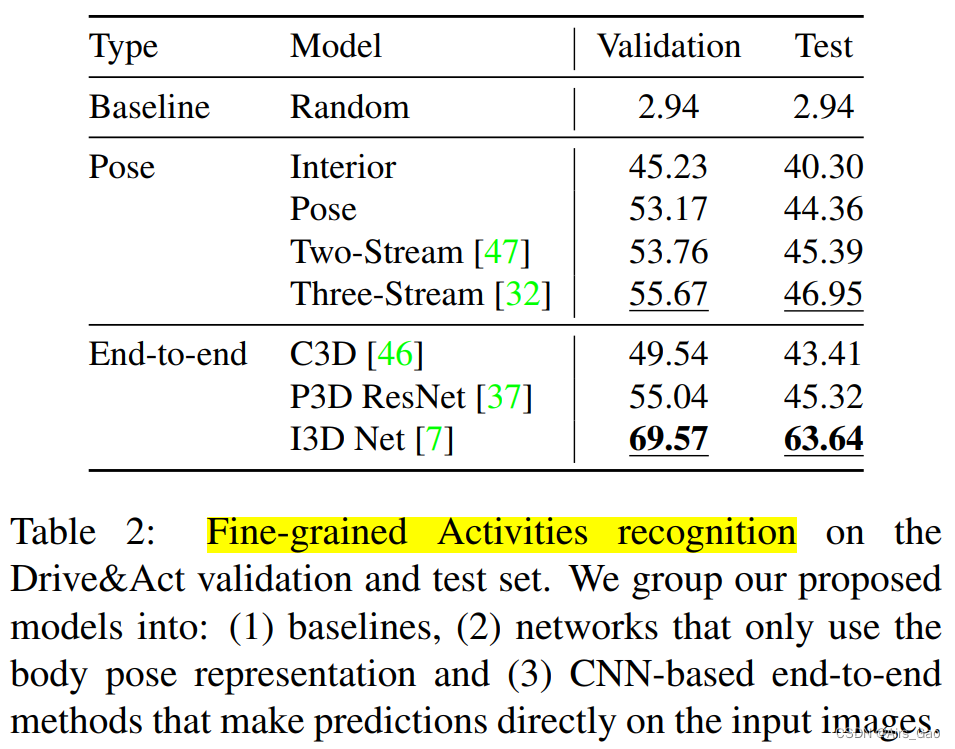
(1)细粒度的活动
- 在表2中,我们比较了许多已发表的用于识别细粒度活动的方法,包括三种基于cnn的方法和四种基于身体和内部表示的模型。
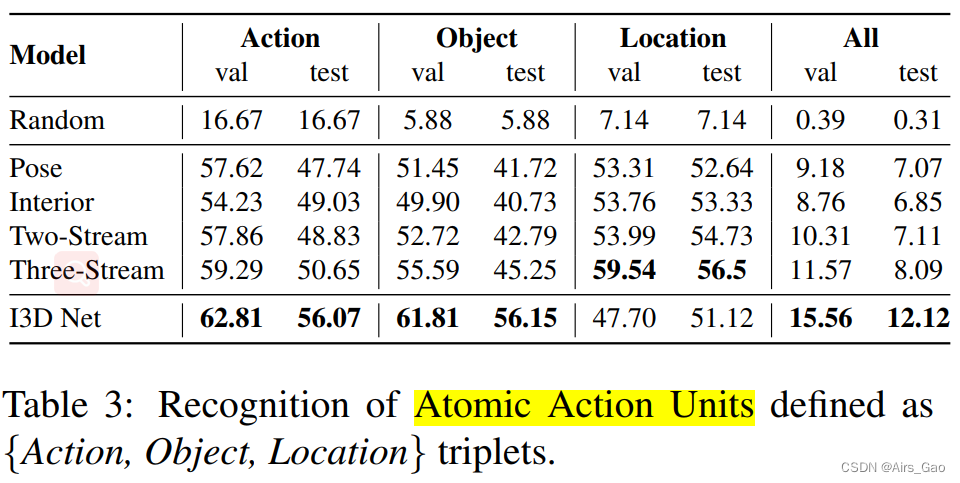
(2)原子作用单位分类
- 表3报告了原子操作单元分类的结果,其中显示了{action、Object、Location}三元组单独,以及,整体精度的三元组值组合。
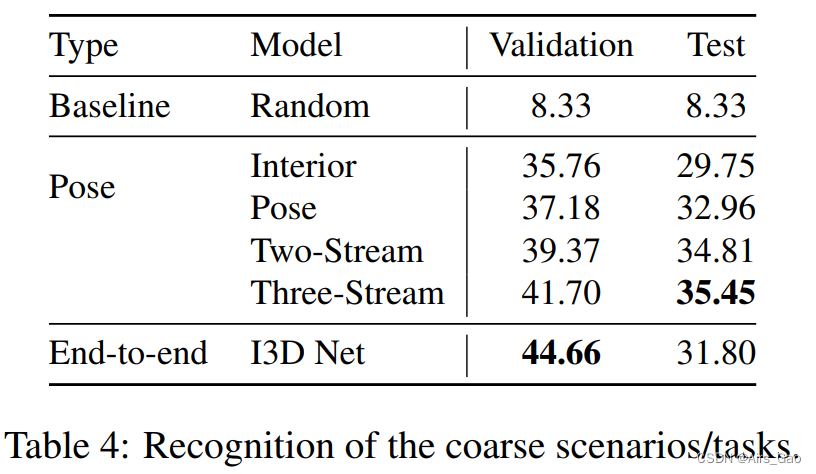
(3)场景识别/任务
- 表4显示了任务分类的结果。基于身体姿势的方法效果较好,但整体识别率低于其他水平。
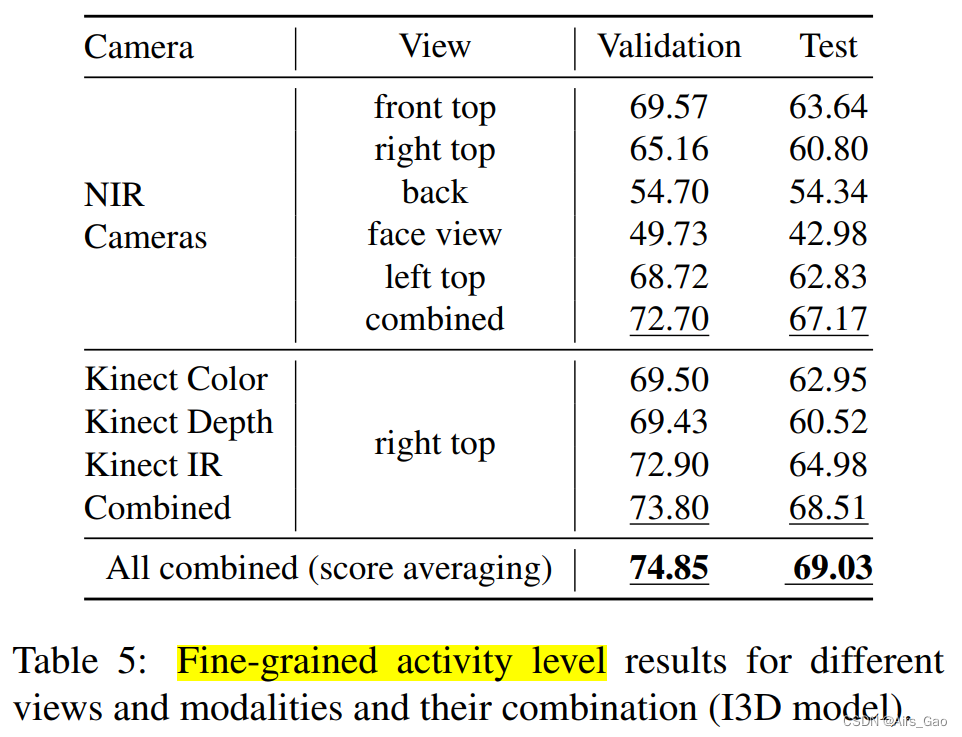
6.2 多视图和多模态动作识别
- 在表5中,我们报告了基于cnn的通过Softmax输出分数的平均,I3D方法用于单个视图和模态及其组合。
- 正如预期的那样,识别成功与一般场景可见性相关(参见图2中摄像机覆盖的区域)。
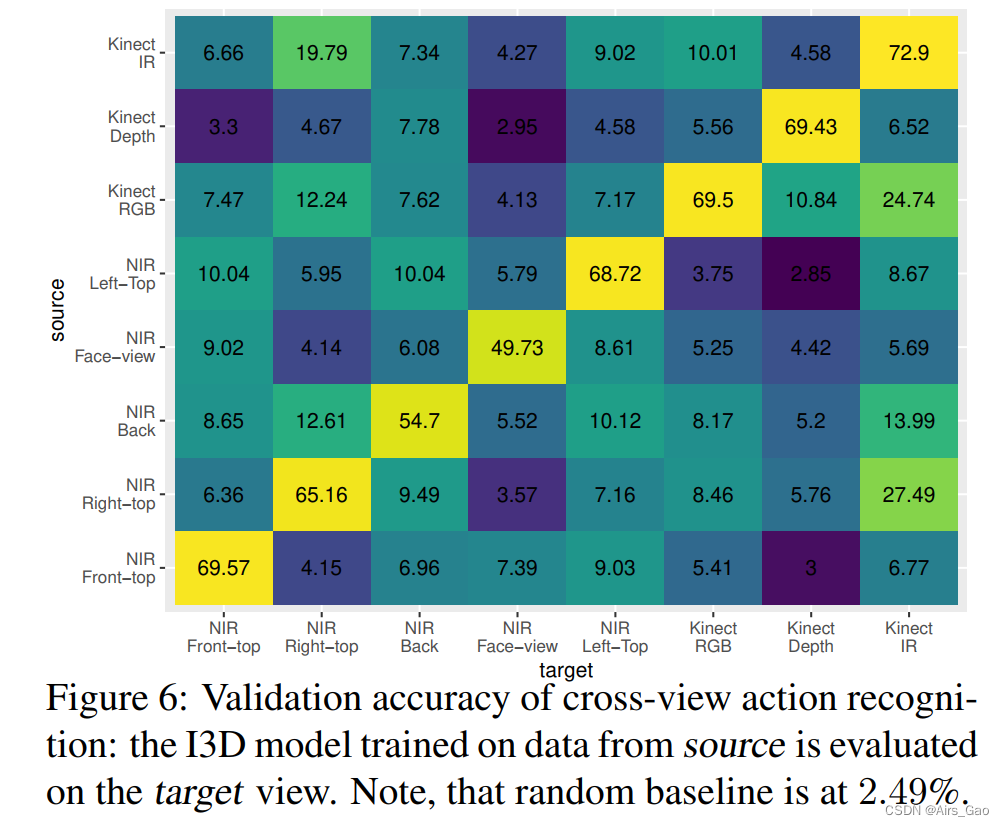
6.3 Cross-View 动作识别
- 我们下一个调查领域是交叉视图和交叉模态设置,在这里我们评估在培训期间没有见过的视图中我们最好的执行端到端方法(如图6所示)。
- 交叉视识别是一项非常困难的任务,并且性能会显著下降。尽管如此,在大多数情况下,模型比随机基线获得更好的结果。