CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
导言
优化是从一组可用的备选方案中选择最佳方案。优化无疑是深度学习的核心。基于梯度下降的方法已经成为训练深度神经网络的既定方法。
在最简单的情况下,优化问题包括通过系统地从允许集合中选择输入值并计算函数值来最大化或最小化实函数。
在机器学习的情况下,优化是指通过系统地更新网络权重来最小化损失函数的过程。在数学上,这表示为,给定损失函数 L 和权重 w。
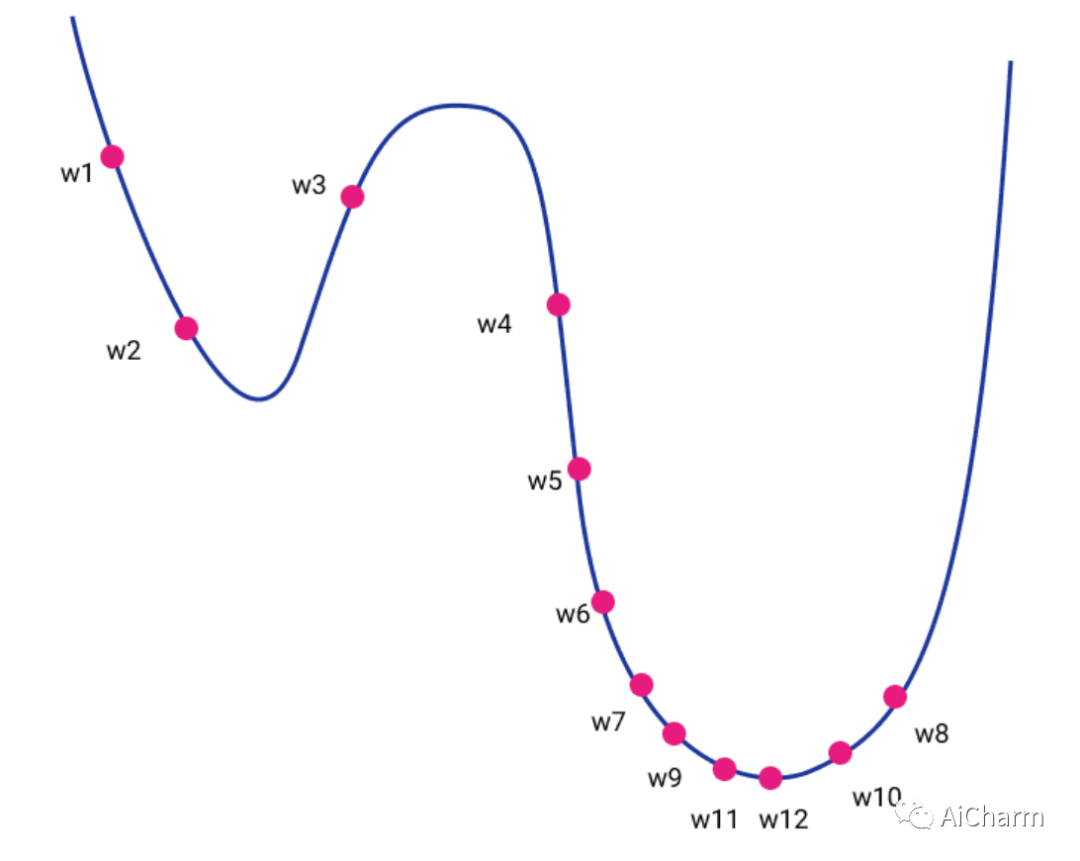
直观上,它可以被认为是一个高维地形的下降。如果我们可以将其投影到二维图中,则地形的高度将是损失函数的值,而水平轴将是我们的权重 w 的值。最终,我们的目标是通过反复探索我们周围的空间来到达地形的底部。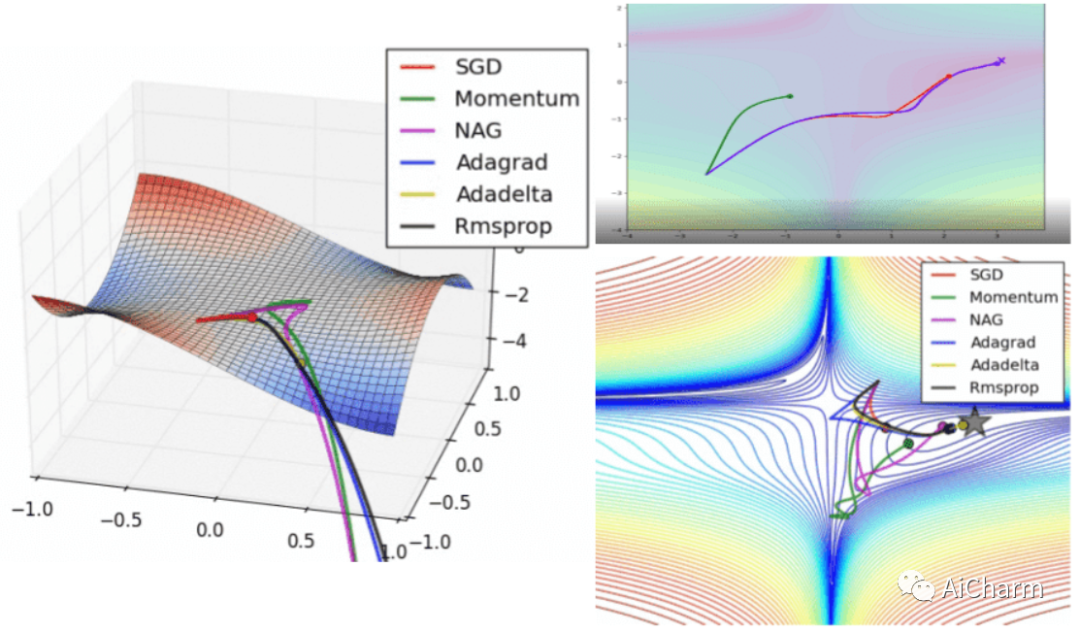
Gradient descent 梯度下降
梯度下降基于跟随地形局部坡度的基本思想。我们实质上是在混合中引入物理学和万有引力定律。微积分为我们提供了一种计算地形坡度的优雅方法,坡度是函数在该点(也称为梯度)相对于权重的导数。
_ _
learning_rate是一个常量值,称为学习率,它决定了每次迭代的步长,同时朝着损失函数的最小值移动。这可以用 Python 表示如下:
for t in range(steps): dw = gradient(loss, data, w) w = w - learning_rate *dw
在视觉上,我们可以想象下图对应一个二维空间。
实际上,在深度学习方面,梯度下降有 3 种主要的不同变体。
Batch gradient descent 批量梯度下降
上面给出的等式和代码实际上指的是批量梯度下降。在这个变体中,我们在更新权重之前计算每个训练步骤中整个数据集的梯度。
可以想象,由于我们对所有单个训练示例的损失求和,我们的计算很快就会变得非常昂贵。因此对于大型数据集来说是不切实际的。
Stochastic gradient descent 随机梯度下降
引入随机梯度下降(SGD)来解决这个确切的问题。SGD 不是计算所有训练示例的梯度并更新权重,而是更新每个训练示例的权重
_
for t in range(steps): for example in data: dw = gradient(loss, example, w) w = w - learning_rate *dw
因此,SGD 速度更快,计算效率更高,但它在梯度估计中存在噪声。由于它频繁更新权重,因此会导致较大的振荡,从而使训练过程非常不稳定。
你可以想象我们不断地沿着地形走锯齿形,这导致不断超调并错过我们的最小值。尽管出于同样的原因,我们可以轻松地摆脱局部最小值并继续寻找更好的值。
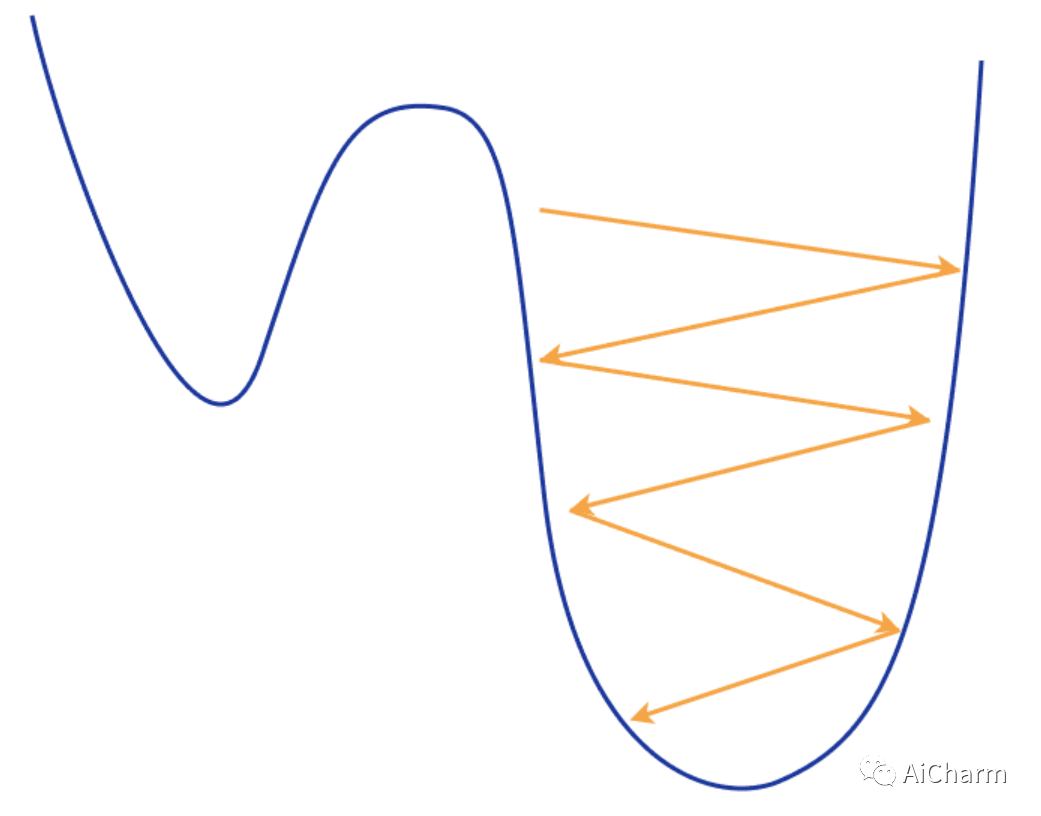
Mini-batch Stochastic Gradient Descent 小批量随机梯度下降
小批量 SGD 恰好位于前两个想法的中间,结合了两个世界的优点。它从整个数据集中随机选择 n个训练样例,即所谓的小批量,并仅从中计算梯度。它本质上试图通过仅对数据的一个子集进行采样来近似批量梯度下降。数学上:
在实践中,小批量 SGD 是最常用的变体,因为它的计算成本低,收敛性更强。
for t in range(steps): for mini_batch in get_batches(data, batch_size): dw = gradient(loss, mini_batch, w) w = w - learning_rate *dw
Concerns on SGD SGD的一些担忧
然而,这个基本版本的 SGD 有一些限制和问题,可能会对训练产生负面影响。
如果损失函数在一个方向上快速变化而在另一个方向上变化缓慢,则可能导致梯度的高度振荡,从而使训练进度非常缓慢。
如果损失函数有局部最小值或鞍点,SGD 很可能会卡在那里而无法“跳出”并继续寻找更好的最小值。发生这种情况是因为梯度变为零,因此权重没有任何更新。
ps:鞍点是函数图形表面上的一个点,其中斜率(导数)都为零但不是函数的局部最大值。
梯度仍然有噪声,因为我们仅根据数据集的一小部分样本来估计它们。嘈杂的更新可能与损失函数的真实方向没有很好的关联。
选择一个好的损失函数是很困难的,需要用不同的超参数进行耗时的实验。
相同的学习率应用于我们所有的参数,这对于具有不同频率或重要性的特征可能会产生问题。
但是为了克服这些问题,多年来已经提出了许多改进。
Adding Momentum 添加动量
对 SGD 的一项基本改进来自添加动量的概念。借用物理学中的动量原理,我们强制 SGD 保持与之前时间步相同的方向移动。为此,我们引入了两个新变量:速度和摩擦力
速度 v 被计算为直到这个时间点的梯度的运行平均值,并指示梯度应该继续移动的方向,摩擦力 ρ 是一个旨在衰减的常数。
在每个时间步,我们通过将先前的速度衰减 ρ 的因子来更新我们的速度,并在当前时间添加权重的梯度。然后我们在速度向量的方向上更新我们的权重
for t in range(steps): dw = gradient(loss, w) v = rho*v +dw w = w - learning_rate *v
但是我们从动量中获得了什么?
我们现在可以避开局部最小值或鞍点,因为即使小批量的梯度可能为零,我们也会继续向下移动。
动量还可以帮助我们减少梯度的振荡,因为速度矢量可以平滑这些高度变化的地形。
最后,它减少了梯度的噪声(随机性)并沿着地形更直接地行走。
Nesterov momentum
这是动量的另一种版本,称为 Nesterov 动量,以稍微不同的方式计算更新方向。
我们不是将速度向量和梯度结合起来,而是计算速度向量会将我们带到哪里,并计算此时的梯度。换句话说,如果我们只根据我们的建立速度移动,我们会发现梯度向量会是什么,并从那里计算它。
我们可以将其可视化如下:
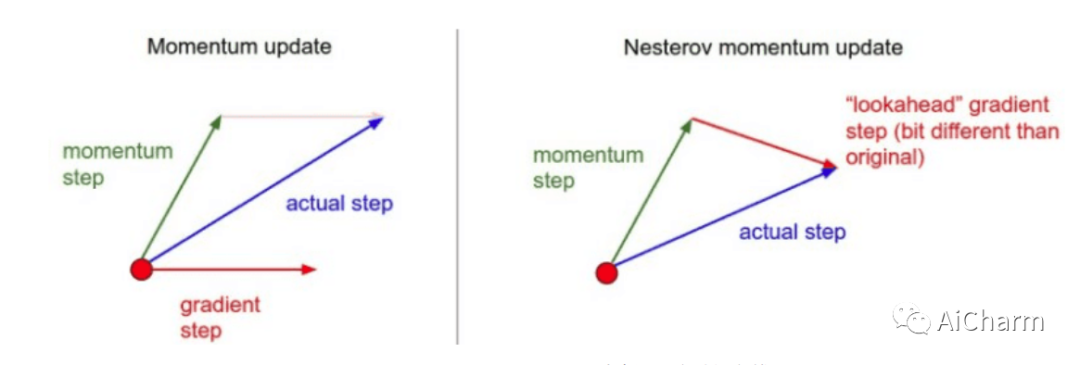
这种预期的更新可以防止我们走得太快,从而提高响应能力。最著名的利用 Nesterov 动量的算法称为 Nesterov 加速梯度 (NAG),其过程如下:
for t in range(steps): dw = gradient(loss, w) v = r*v -learning_rate*dw w = w + v
Adaptive Learning Rate 自适应学习率
优化算法的另一个重要思想是自适应学习率。直觉是我们希望对频繁的特征进行较小的更新,对不频繁的特征进行较大的更新。这将使我们能够克服之前提到的 SGD 的一些问题。
Adagrad
Adagrad 保留每个维度中梯度平方的运行总和,并且在每次更新中,我们根据总和调整学习率。这样我们就可以为每个参数实现不同的学习率(或自适应学习率)。此外,通过使用平方梯度的根,我们只考虑梯度的大小而不是符号。
⊙表示矩阵向量积
for t in range(steps): dw = gradient(loss, w) squared_gradients +=dw*dw w = w - learning_rate * dw/ (squared_gradients.sqrt() + e)
我们可以看到,当梯度变化非常快时,学习率会变小。当梯度变化缓慢时,学习率会更大。Adagrad的一大缺点是随着时间的推移,由于运行平方和的单调递增,学习率越来越小。
RMSprop
这个问题的解决方案是对上述算法进行修改,称为 RMSProp,可以将其视为“Leaky Adagrad”。本质上,我们通过衰减先前平方梯度的总和再次添加摩擦的概念。
正如我们在基于动量的方法中所做的那样,我们将项(此处为运行平方和)乘以常数值(衰减率)。这样我们希望算法不会像 Adagrad 那样在训练过程中变慢
for t in range(steps): dw = gradient(loss, w) squared_gradients = decay_rate*squared_gradients + (1- decay_rate)* dw*dw w = w - learning_rate * (dw/(squared_gradients.sqrt() + e)
可以看到分母是梯度的均方根误差 (RMS),因此是算法的名称。在大多数自适应速率算法中,添加了一个非常小的值 e 以防止分母无效。通常它等于 。
Adam
Adam(自适应矩估计)可以说是当今最流行的变体。它已广泛用于研究和商业应用。它的流行在于它结合了以前最好的两个想法。动量和自适应学习率。
我们现在跟踪两个运行变量,速度和我们在 RMSProp 上描述的平方梯度平均值。它们在原始论文中也被称为第一和第二时刻。
_δ_1 和 是每个时刻的衰减率。在 Pytorch 等框架中,您还会将它们视为 和 。
for t in range(steps): dw = gradient(loss, w) moment1= delta1 *moment1 +(1-delta1)* dw moment2 = delta2*moment2 +(1-delta2)*dw*dw w = w - learning_rate*moment1/ (moment2.sqrt()+e)
我们在这里需要提到的一件事是,对于_t_=0 ,二阶矩(速度)将非常接近于零,导致除法几乎为零分母。因此梯度变化很大。为了克服这个问题,我们还在我们的时刻添加了偏差,以迫使我们的算法在开始时采取更小的步骤。
Adam 算法转换为:
for t in range(steps): dw = gradient(loss, w) moment1= delta1 *moment1 +(1-delta1)* dw moment2 = delta2*moment2 +(1-delta2)*dw*dw moment1_unbiased = moment1 /(1-delta1**t) moment2_unbiased = moment2 /(1-delta2**t) w = w - learning_rate*moment1_unbiased/ (moment2_unbiased.sqrt()+e)
请注意,由于 Adam 算法越来越受欢迎,因此已经进行了一些进一步优化的工作。两个最有前途的变体是 AdaMax 和 Nadam,大多数深度学习框架都支持它们。
AdaMax
AdaMax 将速度 时刻计算为:
这背后的直觉?Adam 根据梯度的 L2 范数值缩放二阶矩。然而,我们可以扩展这个原则来使用无穷范数 。已经表明, 还提供稳定的行为,AdaMax 有时可以比 Adam 具有更好的性能(尤其是在具有嵌入的模型中)。
for t in range(steps): dw = gradient(loss, w) moment1= delta1 *moment1 +(1-delta1)* dw moment2 = max(delta2*moment2, abs(dw)) moment1_unbiased = moment1 /(1-delta1**t) w = w - learning_rate*moment1_unbiased/ (moment2+e)
Nadam
Nadam(Nesterov 加速自适应力矩估计)算法是对 Adam 的轻微修改,其中普通动量被 Nesterov 动量取代。
Nadam 通常在具有非常嘈杂的梯度或具有高曲率的梯度的问题上表现良好。它通常也提供更快的训练时间。
要结合 Nesterov 动量,一种方法是将梯度修改为 ,就像我们在 NAG 中所做的那样。然而,作者提出我们可以在算法的更新阶段更优雅地利用当前动量而不是旧动量 。结果,我们实现了 NAG 所基于的预期更新。
新动量(添加偏差后)的形状为:
速度矢量和更新规则保持不变。
AdaBelief
Adabelief 是 2020 年 提出的一种新的优化算法,它主要:
-
更快的训练收敛
-
更高的训练稳定性
-
更好的模型泛化
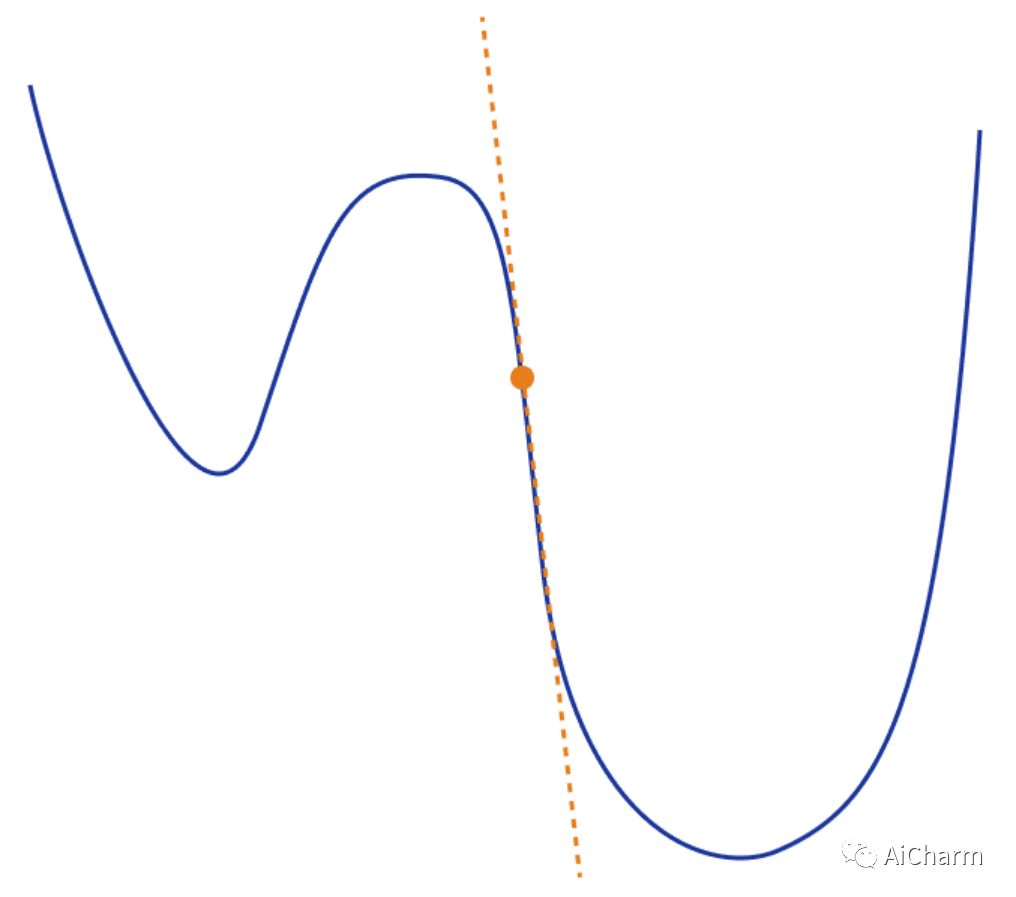
关键思想是根据当前梯度方向的“信念”改变步长。但是,这又是什么意思?在实践中,我们通过计算梯度随时间变化的方差而不是动量平方来增强 Adam。梯度的方差只不过是与预期(相信)梯度的距离。
换句话说,变成了
这就是 AdaBelief 和 Adam 之间的唯一区别!这样,优化器现在会考虑损失函数的曲率。如果观察到的梯度大大偏离bilief,我们不相信当前的观察并迈出一小步。
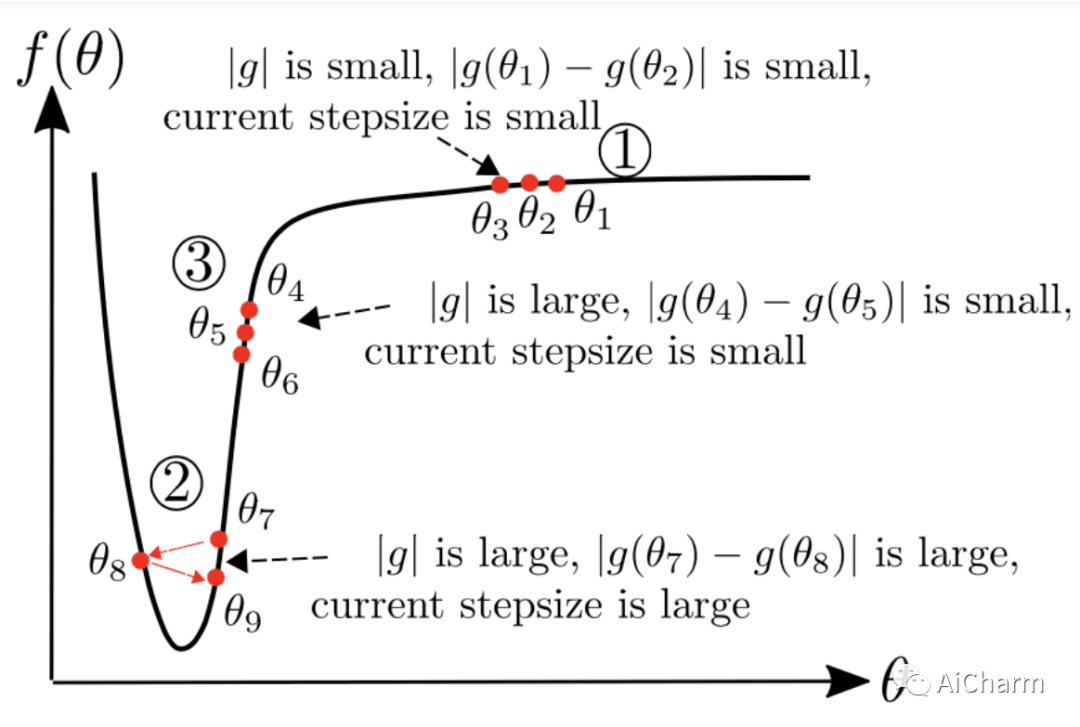
我们可以将视为对下一个梯度的预测。如果观察到的梯度接近预测,我们就相信它并迈出一大步。这在下图中变得非常清楚,其中 g 对应于
for t in range(steps):
dw = gradient(loss, w)
moment1= delta1 *moment1 +(1-delta1)* dw
moment2 = delta2*moment2 +(1-delta2)*(dw-moment1)*(dw-moment1)
moment1_unbiased = moment1 /(1-delta1**t)
moment2_unbiased = moment2 /(1-delta2**t)
w =w - learning_rate*moment1_unbiased/ (moment2_unbiased.sqrt()+e)
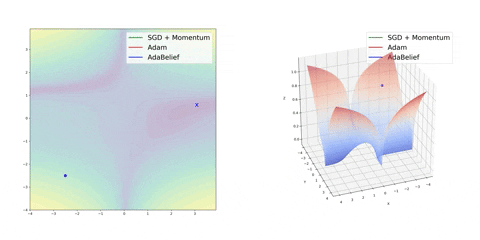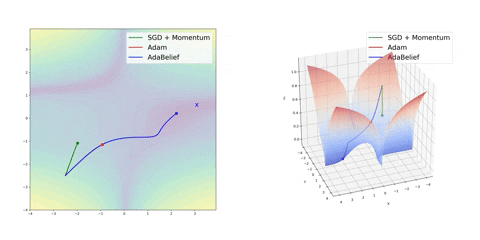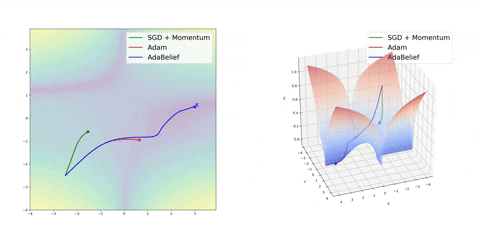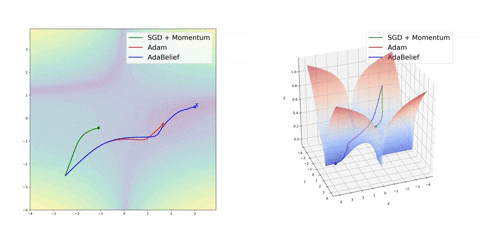
可视化优化器
如果我们查看以下可视化效果,每种算法的优缺点就会变得一目了然。
1) 具有动量的算法比基于非动量的算法具有更平滑的轨迹,但这可能会导致超调。

2)具有自适应学习率的方法具有更快的收敛速度、更好的稳定性和更少的抖动。

3)不缩放步长(自适应学习率)的算法更难逃脱局部最小值并破坏损失函数的对称性!
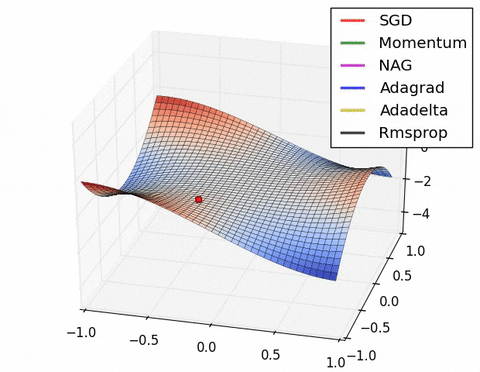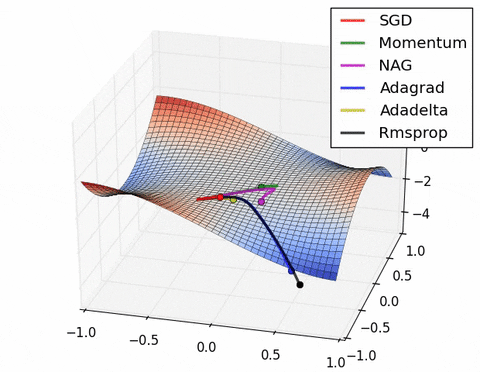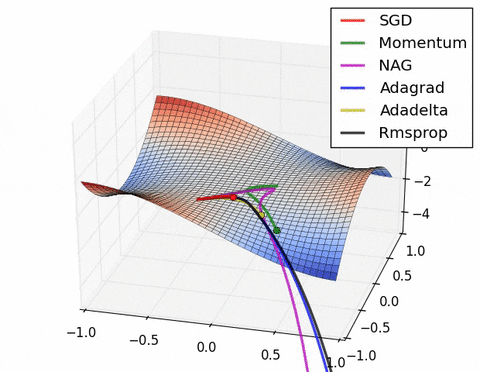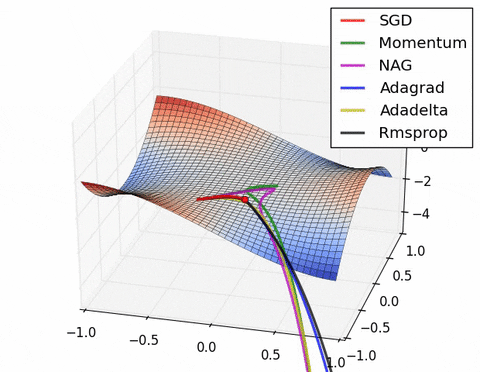
4)鞍点导致基于动量的方法在找到正确的下坡路径之前振荡
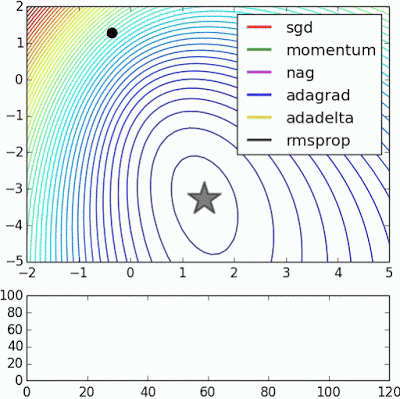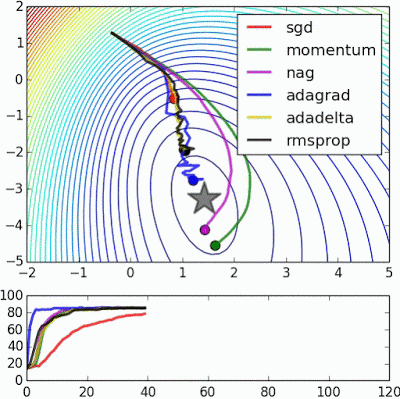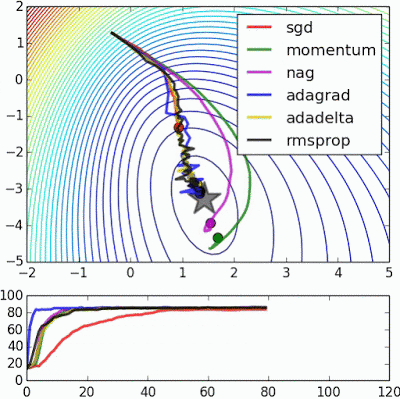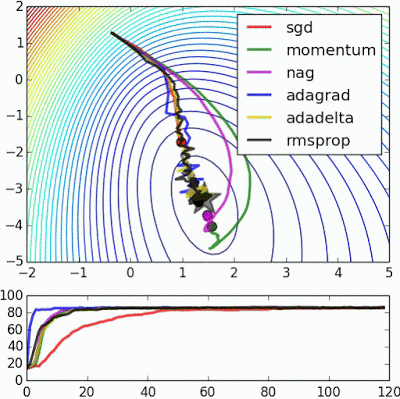
最后,AdaBelief 似乎比 Adam 更快更稳定,但现在下结论还为时过早
梯度下降作为损失函数的近似
考虑优化的另一种方法是近似。在任何给定点,我们都会尝试近似损失函数,以便朝正确的方向移动。梯度下降以线性形式实现了这一点。在数学上,这可以表示为点 w 周围的 L(w) 的一阶泰勒级数。
d 是我们要前进的方向。综上所述,梯度更新可以写成:
这直观地告诉我们梯度下降只是最小化局部近似.对于小的 d ,很明显近似值通常是相当合理的。随着 d变大,线性逼近将开始远离损失函数。
Second-order optimization 二阶优化
进过上面的学习,我们的脑海中自然而然地产生了一个疑问。我们不能使用高阶近似来获得更好的结果吗?
通过扩展上述想法,我们现在可以使用二次函数来局部逼近我们的损失函数。最常见的方法之一是再次使用泰勒级数。但是这次我们将同时保留一阶和二阶项
从视觉上看,这将如下所示:
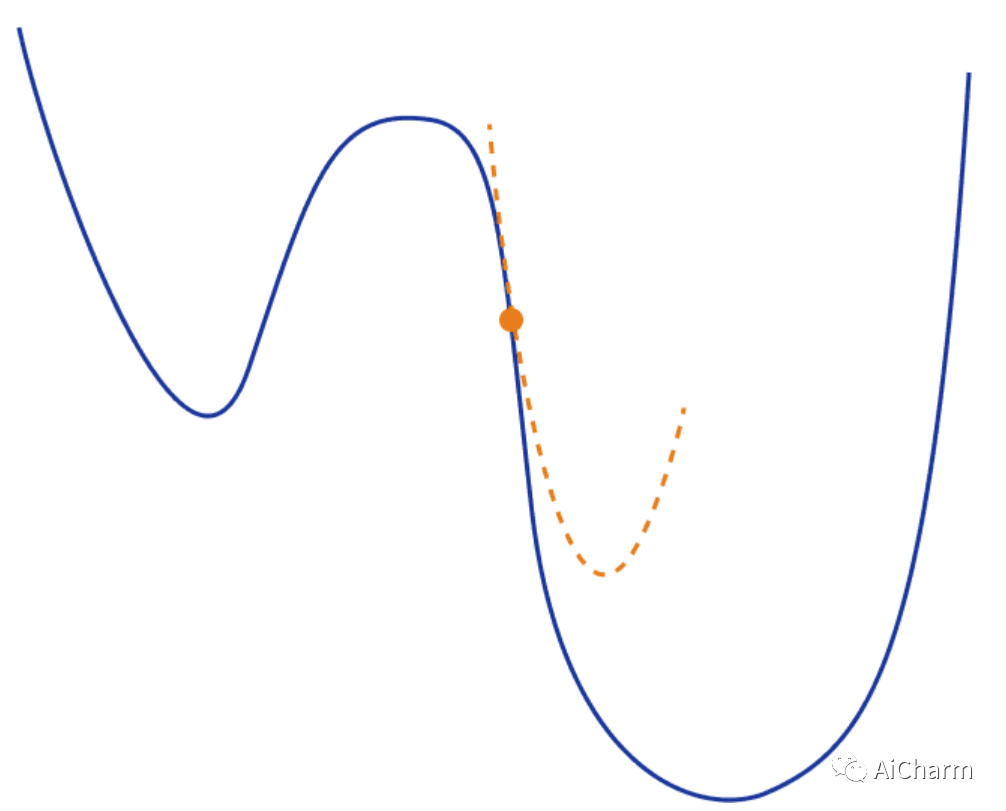
在这种情况下,梯度的更新将采用以下形式,它取决于 Hessian 矩阵 H*(w) :
有数学背景的人应该已经意识到,这无非是众所周知的牛顿法。算法的其余部分保持完全相同。另外,请注意,前面提到的许多概念(例如动量)也可以在这里应用。
二阶优化方法的缺点
二次逼近仅在小的局部区域中是可信的。当我们远离当前点(大 d )时,它可能会非常不准确。因此,我们在更新梯度时不能移动得太快。
一个常见的解决方案是将梯度更新限制在点周围的局部区域(信任区域),这样我们就可以确保近似值相当好。我们定义一个区域 r 并确保 。然后我们有:
其中取决于。
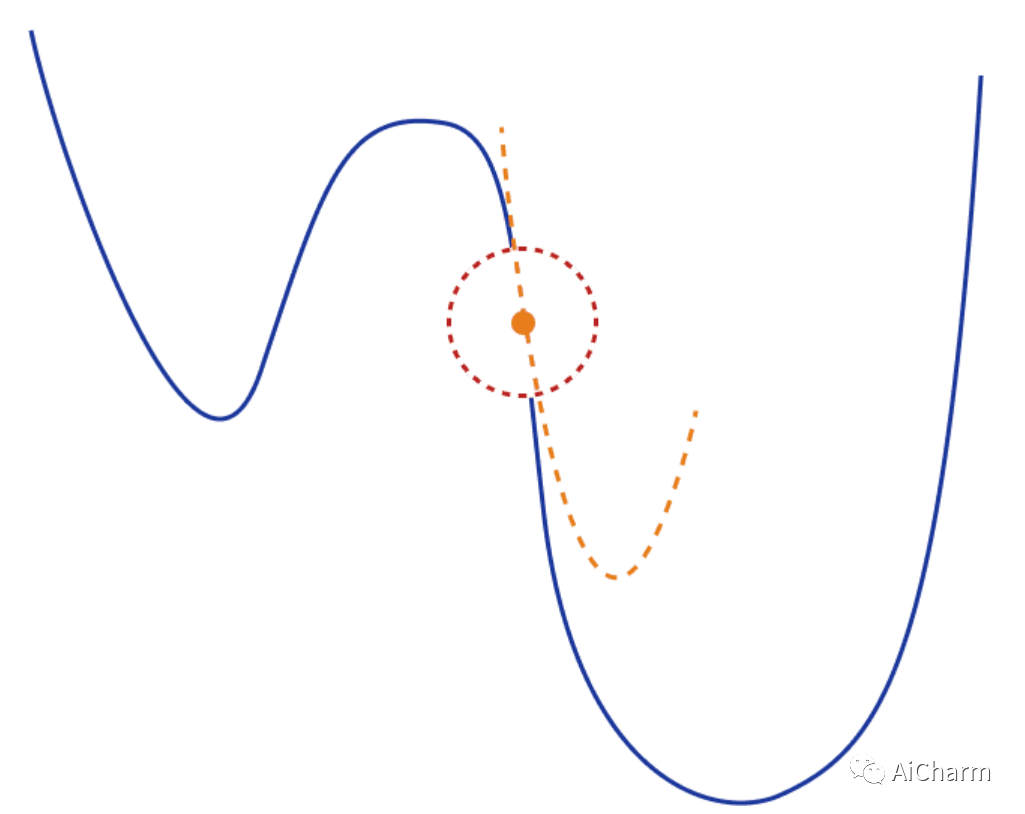
另一个常见问题是二阶泰勒级数和 Hessian 矩阵可能不是最好的二次近似。事实上,这在深度学习应用中通常是正确的。为了克服这个问题,已经提出了不同的替代矩阵:
-
Fisher information matrix Fisher 信息矩阵
-
Gradient Covariance 梯度协方差
-
Generalized Gauss-Newton 广义高斯-牛顿
最后,在这类方法中,最后也是最大的问题是计算复杂性。计算和存储 Hessian 矩阵(或任何替代矩阵)需要太多内存和资源而不实用。考虑一下,如果我们的权重矩阵具有 N 值,则 Hessian 具有 值,而逆 Hessian 具有 。这对于实际应用来说根本不可行。
总结
在这篇文章中,我们提供了深度学习中使用的不同优化算法的完整概述。我们从梯度下降的 3 种主要变体开始,继续介绍多年来提出的不同方法,最后以二阶优化结束。不过我们只是粗略地了解了每种方法的数学知识,每种方法还有更多需要学习的地方。如果你想了解更多信息,我建议您查看原始论文以获取更多详细信息。