有3种方式可在涉及套接字的IO操作上设置超时方法:
1.调用alarm,它在指定超时期满时产生SIGALRM信号。此方法涉及信号处理,而信号处理在不同的实现上存在差异,且此方法可能干扰进程中已经执行过的alarm调用,可能使之前已经设置的超时时间被覆盖或者被忽略。
2.在select函数中阻塞等待IO(select函数有内置的时间限制),以此代替直接阻塞在read或write调用上。
3.使用较新的SO_RCVTIMEO和SO_SNDTIMEO套接字选项,但并非所有实现都支持这两个套接字选项。
以上3个技术只适用于输入输出操作(如read、write,及诸如recvfrom、sendto之类的变体),我们期待用于connect函数的技术,因为TCP内置的connect函数超时相当长的时间(典型值为75s)。select函数可用来在connect函数上设置超时的条件是相应套接字处于非阻塞模式,而SO_RCVTIMEO和SO_SNDTIMEO套接字选项不适用于connect函数。以上前两个技术适用于所有描述符,而第三个技术只适用于套接字描述符。
以下connect_timeo函数由调用者指定的超时上限调用connect,它的前3个参数用于调用connect,第4个参数是等待的秒数:
#include "unp.h"
static void connect_alarm(int);
int connect_timeo(int sockfd, const SA *saptr, socklen_t salen, int nsec) {
Sigfunc *sigfunc;
int n;
// 为SIGALRM建立一个信号处理函数,同时保存现有信号处理函数(如果有),以便在函数结束时恢复它
// 此处的signal函数是我们在第五章中自定义的(图5-6)
sigfunc = Signal(SIGALRM, connect_alarm);
// 设置本进程的报警时钟,如果之前已设置过报警时钟,则alarm函数会返回这个报警时钟的剩余秒数,否则返回0
// 如果是前一种情况,我们显示一条警告信息,因为我们覆盖了先前设置的报警时钟
if (alarm(nsec) != 0) {
err_msg("connect_timeo: alarm was already set");
}
if ((n = connect(sockfd, saptr, salen)) < 0) {
// 如果connect调用被中断,把errno值改为ETIMEOUT,同时关闭套接字,以防三路握手继续进行
close(sockfd);
if (errno == EINTR) {
errno = ETIMEDOUT;
}
}
// 关闭本进程报警时钟,同时恢复原来的信号处理函数(如果有)
// 如果调用本函数前未曾建立过SIGALRM的信号处理函数,则第一个signal调用将返回SIG_DFL,此处会把它设置回默认设置
alarm(0); /* turn off the alarm */
Signal(SIGALRM, sigfunc); /* restore previous signal handler */
return n;
}
// 我们期望本函数中断进程主控制流中的未决的connect函数,使它返回EINTR
// 我们的signal函数在被捕获的信号是SIGALRM时,不设置SA_RESTART标志
static void connect_alarm(int signo) {
return; /* just interrupt the connect() */
}
以上程序:
1.本技术只能减少connect函数的超时期限,但无法延长内核现有的超时时长。源自Berkeley的内核的connect函数的超时值通常为75s。
2.使用了系统调用connect的可中断能力,即在内核超时(通常75s)发生前就能返回,我们于是能处理由它返回的EINTR错误。有些库函数执行系统调用时,如果系统调用返回EINTR,这些库函数会重新执行该系统调用,此时也可以使用alarm函数,但还需要使用sigsetjmp和siglongjum(在信号处理函数中调用)函数绕过库函数对EINTR的忽略。
在多线程程序中正确使用信号很困难,因此只建议在未线程化或单线程化的程序中使用以上技术。
改写第八章(图8-8)中的dg_cli函数,新dg_cli函数调用alarm使得5秒内收不到应答就中断recvfrom函数:
#include "unp.h"
static void sig_alrm(int);
void dg_cli(FILE *fp, int sockfd, const SA *pservaddr, socklen_t servlen) {
int n;
char sendline[MAXLINE], recvline[MAXLINE + 1];
Signal(SIGALRM, sig_alrm);
while (Fgets(sendline, MAXLINE, fp) != NULL) {
Sendto(sockfd, sendline, strlen(sendline), 0, pservaddr, servlen);
alarm(5);
if ((n = recvfrom(sockfd, recvline, MAXLINE, 0, NULL, NULL)) < 0) {
if (errno == EINTR) {
fprintf(stderr, "socket timeout\n");
} else {
err_sys("recvfrom error");
}
} else {
alarm(0);
recvline[n] = 0; /* null terminate */
Fputs(recvline, stdout);
}
}
}
static void sig_alrm(int signo) {
return; /* just interrupt the recvfrom() */
}
以下readable_timeo函数使用select函数实现读超时:
#include "unp.h"
int readable_timeo(int fd, int sec) {
fd_set rset;
struct timeval tv;
FD_ZERO(&rset);
FD_SET(fd, &rset);
tv.tv_sec = sec;
tv.tv_usec = 0;
return select(fd + 1, &rset, NULL, NULL, &tv);
/* > 0 if descriptor is readable */
}
以上函数的返回值就是select函数的返回值,出错返回-1,超时返回0,否则返回已就绪描述符的数目。
以上函数不执行读操作,它只是等待给定描述符变得可读,适用于任何类型套接字。
改写第八章(图8-8)中的dg_cli函数,新dg_cli函数调用readable_timeo,只有readable_timeo函数返回正数时才调用recvfrom:
#include "unp.h"
void dg_cli(FILE *fp, int sockfd, const SA *pservaddr, socklen_t servlen) {
int n;
char sendline[MAXLINE], recvline[MAXLINE + 1];
while (Fgets(sendline, MAXLINE, fp) != NULL) {
Sendto(sockfd, sendline, strlen(sendline), 0, pservaddr, servlen);
if (Readable_timeo(sockfd, 5) == 0) {
fprintf(stderr, "socket timeout\n");
} else {
// 假设select函数不会出错返回,此时sockfd已变为可读,recvfrom函数一定不会阻塞
n = Recvfrom(sockfd, recvline, MAXLINE, 0, NULL, NULL);
recvline[n] = 0; /* null terminate */
Fputs(recvline, stdout);
}
}
}
使用SO_RCVTIMEO套接字选项实现读超时,一旦本选项设置到某描述符上(指定了超时值),将应用于该描述符上所有读操作。本方法的优势在于只需设置一次,前两个方法要求在每次会超时的读操作前都做一些工作。SO_RCVTIMEO仅适用于读操作,SO_SNDTIMEO选项仅适用于写操作,两者都不能为connect函数设置超时。
以下是使用SO_RCVTIMEO套接字选项的dg_cli函数:
#include "unp.h"
void dg_cli(FILE *fp, int sockfd, const SA *pservaddr, socklen_t servlen) {
int n;
char sendline[MAXLINE], recvline[MAXLINE + 1];
struct timeval tv;
tv.tv_sec = 5;
tv.tv_usec = 0;
Setsockopt(sockfd, SOL_SOCKET, SO_RCVTIMEO, &tv, sizeof(tv));
while (Fgets(sendline, MAXLINE, fp) != NULL) {
Sendto(sockfd, sendline, strlen(sendline), 0, pservaddr, servlen);
n = recvfrom(sockfd, recvline, MAXLINE, 0, NULL, NULL);
if (n < 0) {
// 如果IO操作超时,recvfrom函数返回EWOULDBLOCK
if (errno == EWOULDBLOCK) {
fprintf(stderr, "socket timeout\n");
continue;
} else {
err_sys("recvfrom error");
}
}
recvline[n] = 0; /* null terminate */
Fputs(recvline, stdout);
}
}
有两个类似read和write函数的函数,它们需要一个额外参数:

recv和send函数的前3个参数等同于read和write函数的前3个参数。flags参数的值或为0,或为以下一个或多个常值的逻辑或:

1.MSG_DONTROUTE:告知内核目的主机在某个直接连接的本地网络上,因此无需执行路由表查找。该特性既可以使用MSG_DONTROUTE标志针对单个输出操作开启,也可以使用SO_DONTROUTE套接字选项针对某套接字上的所有输出操作开启。
2.MSG_DONTWAIT:本标志无需打开相应套接字的非阻塞标志,就可把单个IO操作临时指定为非阻塞的。此标志是随Net/3新增设的,可能有些系统不支持它。
3.MSG_OOB:对于send函数,本标志指明要发送带外数据。TCP连接上只有一个字节可以作为带外数据发送。对于recv函数,本标志指明即将读入带外数据而非普通数据。
4.MSG_PEEK:本标志适用于recv和recvfrom函数,它允许我们查看可读取的数据,系统不在recv或recvfrom函数返回后丢弃这些数据。
5.MSG_WAITALL:随4.3 BSD Reno引入,它告知内核尚未读入所请求的字节数前不要让读操作返回。如果系统支持此标志,可代替readn函数,可用以下宏代替readn函数:
#define readn(fd, ptr, n) recv(fd, ptr, n, MSG_WAITALL)
即使指定了MSG_WAITALL标志,下列情况读函数仍可能返回比所请求字节数少的数据:
(1)捕获一个信号。
(2)连接被终止。
(3)套接字发生错误。
还有一些标志适用于TCP/IP以外的协议族,如OSI的传输层是基于记录的(不像TCP那样是一个字节流),其输出操作支持MSG_EOR标志,指示逻辑记录的结束。
recv和send函数的flags参数是按值传递的,而不是一个值-结果参数,因此它只能用于从进程向内核传递标志,内核无法向进程传回标志。对于TCP/IP协议这不是问题,因为TCP/IP几乎不需要从内核向进程传回标志,但随着OSI协议被加到4.3 BSD Reno中,提出了随输入操作向进程传回MSG_EOR标志的需求,4.3 BSD Reno决定保持其他常用输入函数(recv、recvfrom函数)的参数不变,而改变recvmsg和sendmsg函数所用的msghdr结构,该结构新增了一个msg_flags成员,由于该结构按引用传递,内核就能在返回时修改这些标志,这一决定意味着如果一个进程需要由进程更新标志,就必须调用recvmsg,而不是recv或recvfrom函数。
readv和writev函数类似于read和write函数,但readv和writev函数允许单个系统调用读入或写出一个或多个缓冲区,这些操作称为分散读和集中写,因为来自读操作的输入数据被分散到多个应用缓冲区中,而来自多个应用缓冲区的输出数据被集中提供给单个写操作。

这两个函数的第二个参数都是指向某iovec结构数组的指针,iovec结构定义在sys/uio.h头文件中:

这里给出的iovec结构的各个成员的数据类型符合POSIX规范,但你可能碰到把iovec_base成员定义为char *,把iov_len成员定义为int的实现。
iovec结构数组中元素数量存在限制,具体取决于实现。4.3 BSD和Linux最多允许1024个,而HP-UX最多允许2100个。POSIX要求在头文件sys/uio.h中定义IOV_MAX常值,且其值至少为16。
readv和writev函数可用于任何描述符,不仅限于套接字。writev函数是一个原子操作,这意味着对于一个基于纪录的协议(如UDP)来说,一次writev调用只产生一个UDP数据报。
第七章中提过,可能一个4字节的write后跟一个396字节的write会触发Nagle算法,首选办法之一就是对这两个缓冲区调用writev。
recvmsg和sendmsg函数是最通用的IO函数,我们可以把所有read、readv、recv、recvfrom函数替换成recvmsg函数,类似地,各种输出函数也能替换成sendmsg函数。

这两个函数把大部分参数封装在msghdr结构中:

这里的msghdr结构符合POSIX规范,有些系统仍使用源自4.2 BSD的本结构的较旧版本,这个较旧的结构没有msg_flags成员,而msg_control和msg_contrllen成员分别被称为msg_accrights和msg_accrightslen,这个较旧结构唯一支持的辅助数据形式用于传递文件描述符(称为访问权限)。
msg_name和msg_namelen成员用于套接字未连接的场合(如未连接的UDP套接字)。msg_name指向一个套接字地址结构,调用者在其中存放接收者(对于sendmsg函数)或发送者(对于recvmsg函数)的协议地址。如果无需指明协议地址(如TCP套接字或已连接UDP套接字),msg_name应置为空指针。msg_namelen对于sendmsg函数是一个值参数,对于recvmsg函数是一个值-结果参数,含义是地址结构的大小。
msg_iov和msg_iovlen成员用于指定输入或输出缓冲区数组(iovec结构数组)。msg_control和msg_controllen成员指定可选的辅助数据及其大小。msg_controllen对于recvmsg函数是一个值-结果参数。
对于recvmsg和sendmsg函数,我们需要区分标志变量,一个是值传递的flags参数,一个是引用传递的msghdr.msg_flags成员。
只有recvmsg函数使用msg_flags成员,recvmsg被调用时,flags参数被复制到msg_flags成员,之后由内核使用其值处理接收过程,内核还依据recvmsg调用结果更新msg_flags成员值。
sendmsg函数忽略msg_flags成员,因为它使用flags参数处理发送过程。
以下是内核为输入输出函数检查的标志,表中没有sendmsg函数的msg_flags成员,因为它被忽略:
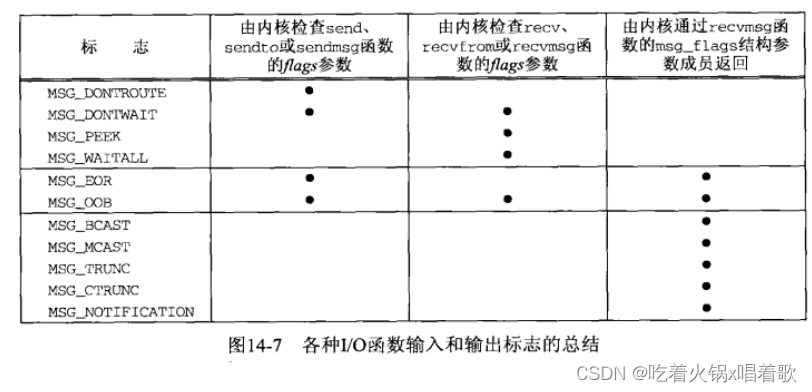
以上标志中,内核只检查而不返回前4个标志;既检查又返回接下来2个标志;不检查只返回后4个标志。recvmsg函数返回的7个标志的解释:
1.MSG_BCAST:随BSD/OS引入,相对较新,它的返回条件是,本数据报作为链路层广播或其目的IP地址是一个广播地址。与IP_RECVDSTADDR套接字相比(把接收到的UDP数据报的目的IP地址由recvmsg函数作为辅助数据返回),本标志是用于判断一个UDP数据报的目的地址是否是广播地址的更好方法。
2.MSG_MCAST:随BSD/OS引入,相对较新,它的返回条件是,本数据报作为链路层多播收取。
3.MSG_TRUNC:本标志的返回条件是本数据报被截断,即内核预备返回的数据超过进程事先分配的空间(所有iov_len成员之和)。
4.MSG_CTRUNC:本标志的返回条件是本数据报的辅助数据被截断,即内核预备返回的辅助数据超过进程事先分配的空间(msg_controllen)。
5.MSG_EOR:本标志的返回条件是返回数据是一个逻辑记录的结束。TCP不使用本标志,因为它是字节流协议。
6.MSG_OOB:本标志不会随TCP带外数据返回,它用于其他协议族(如OSI协议族)。
7.MSG_NOTIFICATION:本标志由SCTP接收者返回,指示读入的消息是一个事件通知,而非数据消息。
具体实现肯能会在msg_flags成员中返回一些flags参数的值,因此我们应只检查感兴趣的标志。
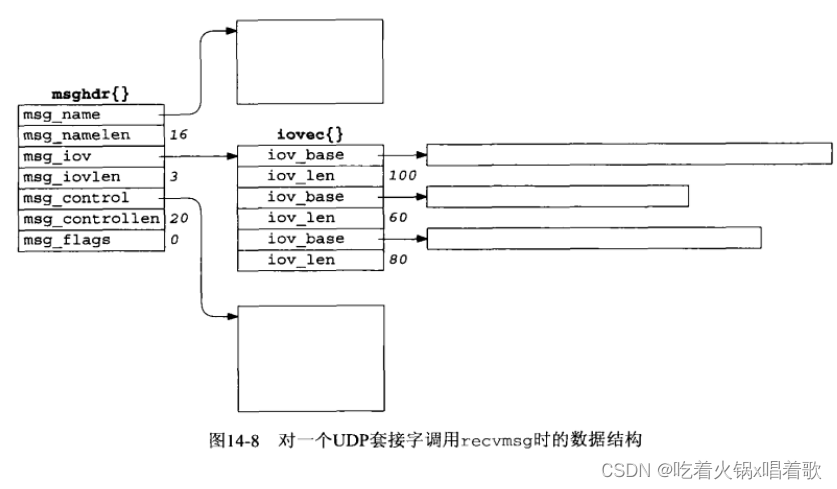
上图给协议地址分配了16个字节;给辅助数据分配了20个字节;为缓冲数据初始化了一个由3个iovec结构构成的数组:第一个指定一个100字节的缓冲区,第二个指定一个60字节的缓冲区,第三个指定一个80字节的缓冲区。我们还假设为上图UDP套接字设置了IP_RECVDSTADDR套接字选项,以接收读取到的UDP数据报的目的IP地址。
接着我们假设从源IP 198.6.38.100,源端口2000发过来一个170字节的UDP数据报,它的目的是上图中的UDP套接字,目的IP地址为206.168.112.96。下图是recvmsg函数返回时msghdr结构中的信息:
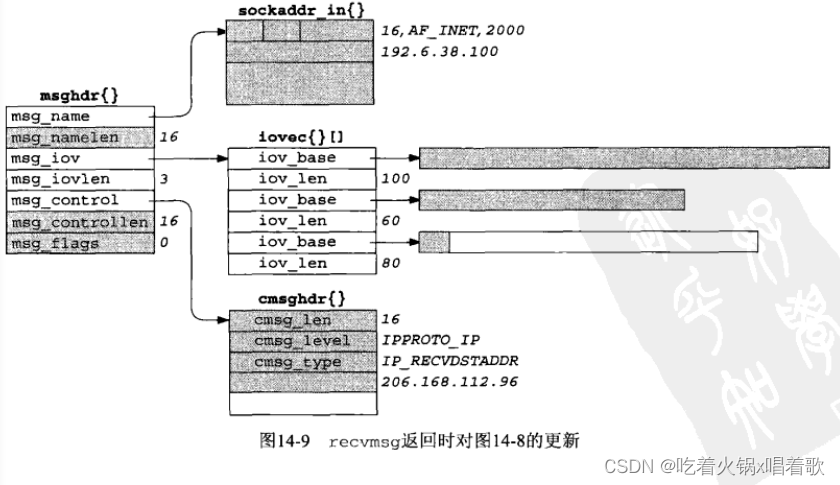
上图中阴影字段表示被修改过,包括以下几点:
1.由msg_name成员指向的缓冲区被填以一个网际套接字地址结构,其中是所收到数据报的源IP和源UDP端口号。
2.msg_namelen成员(值-结果参数)被更新为存放在msg_name成员所指缓冲区中的数据量。本成员实际无变化,recvmsg函数返回前后其值均为16。
3.所收取数据的前100字节存在第一个缓冲区,中60字节存在第二个缓冲区,后10字节存放在第三个缓冲区。最后那个缓冲区中后70字节没有改动,recvmsg函数返回值为170,即该数据报大小。
4.由msg_control成员指向的缓冲区被填以一个cmsghdr结构,该cmsghdr结构中,cmsg_len成员值为16,cmsg_level成员只为IPPROTO_IP,cmsg_type成员值为IP_RECVDSTADDR,随后4个字节存放收到的UDP数据报的目的IP地址。这个20字节缓冲区的后4个字节没有改动。
5.msg_controllen成员被更新为所存放辅助数据的实际数据量,本成员也是值-结果参数,recvmsg函数返回时其结果为16。
6.msg_flags成员同样被recvmsg函数更新,但没有要返回给进程的标志。
辅助数据可通过调用sendmsg和recvmsg函数,使用msghdr结构中的msg_control和msg_controllen成员发送和接收。辅助数据的另一个名字是控制信息。

上图是我们将在本书中讨论的辅助数据的各种用途。OSI协议族也使用辅助数据,但本书不做讨论。
辅助数据由一个或多个辅助数据对象构成,每个对象都以定义在头文件sys/socket.h中的cmsghdr结构开头:

msg_control所指向的辅助数据必须对于cmsghdr结构适当地进行对齐。
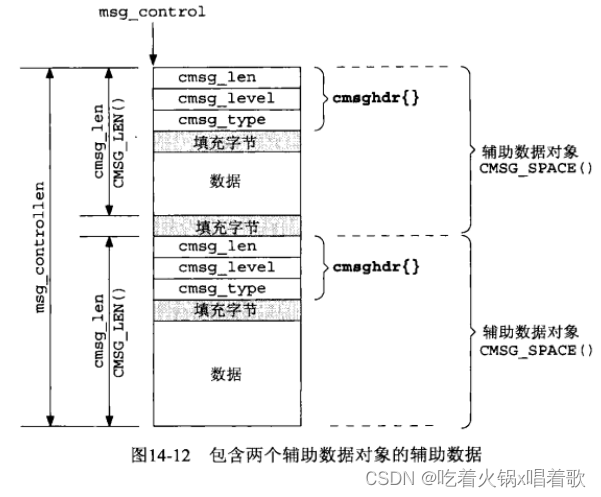
由上图,msg_control指向第一个辅助数据对象,辅助数据的总长度由msg_controllen指定。每个辅助数据对象的开头都是描述该对象的cmsghdr结构。在cmsg_type成员和实际数据之间可以有填充字节,从辅助数据结尾到下一个辅助数据对象之前也可以有填充字节。
不是所有实现都支持单个控制缓冲区中存放多个辅助数据对象。
通过一个Unix域套接字传递描述符或凭证时所用的cmsghdr结构:
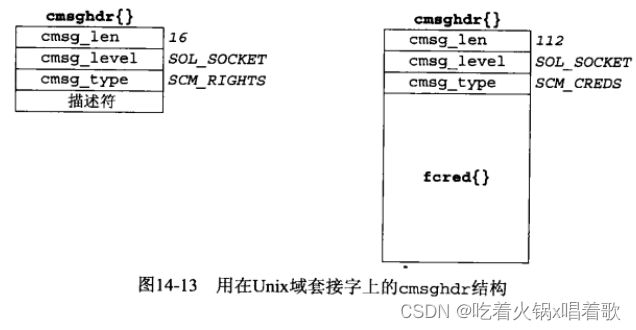
上图我们假设cmsghdr结构的每个成员(共3个)都占4字节,且cmsghdr结构和实际数据间没有填充字节。当传递描述符时,cmsg_data数组的内容是描述符值,上图只展示了1个待传递描述符,但一般可以传递多个描述符(此时cmsg_len的值为12加4乘描述符数目,这里假设每个描述符占4字节)。
既然由recvmsg函数返回的辅助数据可含有任意数目的辅助数据对象,为了对应用程序屏蔽可能出现的填充字节,在头文件sys/socket.h中定义了5个宏,以简化对辅助数据的处理:

POSIX定义了前3个宏,RFC 3542定义了后2个宏。
这些宏能以如下伪代码形式使用:
struct msghdr msg;
struct cmsghdr *cmsgptr;
/* fill in msg structures */
/* call recvmsg() */
for (cmsgptr = CMSG_FIRSTHDR(&msg); cmsgptr != NULL; cmsgptr = CMSG_NXTHDR(&msg, cmsgptr)) {
if (cmsgptr->cmsg_level == ... && cmsgptr- >cmsg_type == ...) {
u_char *ptr;
ptr = CMSG_DATA(cmsgptr);
/* ptocess data pointed to by ptr */
}
}
CMSG_FIRSTHDR返回指向第一个辅助数据对象的指针,但如果msghdr结构中没有辅助数据(msg_control为一个空指针),或cmsg_len小于一个cmsghdr结构的大小,则返回一个空指针。当控制缓冲区中不再有下一个辅助数据对象时,CMSG_NXTHDR也返回一个空指针。
CMSG_FIRSTHDR的许多实现不检查msg_controllen是否等于控制缓冲区的大小,而是直接返回cmsg_control的值,最好在调用该宏前测试msg_controllen的值。
CMSG_LEN不计辅助数据对象中数据部分之后可能的填充字节,因此返回的是存放在cmsg_len成员中的值;CMSG_SPACE计上结尾处可能的填充字节,因此返回的是为辅助数据对象动态分配空间的值。
以下3个技术可在不真正读取数据的前提下直到一个套接字上已有多少数据排队等着读:
1.如果获悉已排队数据量的目的在于避免读操作阻塞在内核,则可用非阻塞式IO。
2.如果我们既想查看数据,又想数据仍留在接收队列中以供本进程其他部分稍后读取,则可用MSG_PEEK标志。如果我们不能确定是否有数据可读,可结合非阻塞套接字使用该标志,或组合使用MSG_DONTWAIT和MSG_PEEK标志。就一个字节流套接字而言,其接收队列中的数据量可能在两次相继的recv调用之间发生变化,例如,指定MSG_PEEK标志以一个长为1024字节的缓冲区对一个TCP套接字调用recv,其返回值为100,如果再次调用同一个recv,返回值就可能超过100(假设接收缓冲区长度大于100),因为这两次recv调用之间TCP可能又收到一些数据。
就一个UDP套接字而言,假设其接收队列中已有一个数据报,如果我们指定MSG_PEEK标志调用recvfrom一次,稍后不指定MSG_PEEK再调用recvfrom一次,那么即使另有数据报在这两次调用之间加入该套接字的接收队列,这两个调用的返回值(数据报大小、内容、发送者地址)也完全相同(这里假设没有其他进程共享该套接字并从中读数据)。
3.一些实现支持ioctl的FIONREAD命令,该命令的第3个ioctl参数是指向某整数的指针,内核通过该整数返回套接字接收队列的当前字节数,该值是已排队字节的总和,对于UDP套接字而言包含所有已排队的数据报。源自Berkeley的实现中,为UDP返回的值还包括一个套接字地址结构的空间(此空间会含IP地址和端口号等信息,对IPv4为16字节,对IPv6为24字节)。
上例都是使用称为Unix IO的函数执行IO,它们围绕描述符工作,通常作为Unix内核中的系统调用实现。
执行IO的另一个方法是使用标准IO函数库,这个函数库由ANSI C标准规范,意在便于移植到支持ANSI C的非Unix系统上。标准IO函数库处理我们直接使用IO函数时要考虑的一些细节,如自动缓冲输入流和输出流,但它对于流的缓冲处理导致了一组新的问题。
标准IO函数库也使用流(stream)这一称谓,如打开一个输入流或刷写输出流,不要将其和流(STREAMS)子系统相混淆。
标准IO函数库可用于套接字:
1.通过调用fdopen,可从任何描述符创建出一个标准IO流。通过调用fileno,可获取一个给定标准IO流对应的描述符。第六章(6-9)中,我们当时想在一个标准IO流上调用select,select只能用于描述符,因此我们获取了那个标准IO流的描述符。
2.TCP和UDP套接字是全双工的,标准IO流也是全双工的(只要以r+打开流即可,r+意味着读写),但在这样的流上,我们必须在调用一个输出函数后调用一次fflush、fseek、fsetpos、rewind才能调用一个输入函数;类似地,调用一个输入函数后也要调用一次fseek、fsetpos、rewind才能调用一个输出函数,除非输入函数遇到一个EOF。fseek、fsetpos、rewind这3个函数都调用lseek,而lseek用在套接字上只会失败。在输入输出切换的时候,要保证缓冲区中的数据已被读入或已被写出,否则下次输出输入会覆盖缓冲区中的数据,或者我们要调用fseek、fsetpos、rewind函数调整偏移量,以确保下一次读写操作可以从正确的位置开始。
3.解决2中读写问题的最简单方法是为一个给定套接字打开两个IO流,一个用于读,一个用于写。
使用标准IO代替read和writen函数重新编写第五章(5-3)中TCP回射服务器程序:
#include "unp.h"
void str_echo(int sockfd) {
char line[MAXLINE];
FILE *fpin, *fpout;
fpin = Fdopen(sockfd, "r");
fpout = Fdopen(sockfd, "w");
while (Fgets(line, MAXLINE, fpin) != NULL) {
Fputs(line, fpout);
}
}
以上函数调用fdopen创建两个标准IO流,一个用于输入,一个用于输出,然后把原来的read和writen函数换为fgets和fputs函数。
运行使用以上版本str_echo函数的服务器,然后运行其用户:


如上图,服务器直到我们键入EOF字符才回射所有文本行,原因在于这里存在一个缓冲问题,以下是实际发生的步骤:
1.我们键入第一行文本,它被发送到服务器。
2.服务器用fgets函数读入本行,在用fputs函数回射本行。
3.服务器的标准IO流被标准IO函数库完全缓冲,这意味着函数库把回射行复制到输出流的标准IO缓冲区,但不把该缓冲区中内容写到描述符,因为该缓冲区未满。
4.我们键入第二行文本,它被发送到服务器。
5.服务器用fgets函数读入本行,再用fputs函数回射本行。
6.服务器的标准IO函数库再次把回射行复制到输出流的标准IO缓冲区,但不把该缓冲区中内容写到描述符,因为该缓冲区未满。
7.同样的情形发生在我们键入的第三行文本上。
8.我们键入EOF字符,致使客户的str_cli函数(第六章6-13)调用shutdown,从而发送一个FIN到服务器。
9.服务器TCP收取这个FIN,它被fgets函数滴入,致使fgets函数返回一个空指针。
10.str_echo函数返回到服务器的main函数(第五章5-12),子进程通过调用exit终止。
11.C库函数exit调用标准IO清理函数,之前由fputs函数填充的输出缓冲区中的未满内容被输出。
12.服务器子进程终止,致使它的已连接套接字被关闭,从而发送一个FIN到客户,完成TCP的四分组终止序列。
13.str_cli函数接收并输出由服务器回射的三行文本。
14.str_cli接着在其套接字上收到一个EOF,客户于是终止。
这里的问题出在服务器中由标准IO函数库自动执行的缓冲上,标准IO函数库执行以下三类缓冲:
1.完全缓冲:只在下列情况才发生IO:缓冲区满、进程显式调用fflush、进程调用exit终止自身。标准IO缓冲区大小通常为8192字节。
2.行缓冲:只在下列情况才发生IO:碰到换行符、进程调用fflush、进程调用exit终止自身。
3.不缓冲:每次调用标准IO输出函数都发生IO。
标准IO函数库的大多Unix实现使用如下规则:
1.标准错误输出总不缓冲。
2.标准输入和标准输出完全缓冲,除非它们指代终端设备(此时是行缓冲)。
3.其他IO流都是完全缓冲,除非它们指代终端设备(此时是行缓冲)。
套接字不是终端设备,因此以上str_echo函数的问题就出在输出流是完全缓冲的。解决方法有两个:一是通过调用setvbuf使这个流变为行缓冲;二是每次调用fputs后通过fflush函数强制输出每个回射行。现实使用中,这两种方法都容易犯错,与Nagle算法的交互可能也成问题。大多情况下,最好不在套接字上使用标准IO函数库,且像3.9节所述在缓冲区而非文本行上执行操作。当标准IO流的便利性大过对缓冲带来的bug的担忧时,也可在套接字上使用标准IO流,但这很罕见。
标准IO库的某些实现在描述符大于255时会有问题,这对于需要处理大量描述符的网络服务器是一个问题,可检查stdio.h头文件中定义的FILE结构,看存放描述符的变量是什么类型。
许多操作系统提供其他为套接字设置IO等待时间限制的方法,它们有select和poll函数的特性,这些方法未被POSIX采纳,且在不同实现上存在差异,使用这些机制的代码应被认为是不可移植的。
Solaris上名为/dev/poll的特殊文件提供了一个可扩展的轮询大量描述符的方法。select和poll函数的问题是,每次调用它们都要传递待查询的文件描述符。轮询设备能在调用之间维持状态,因此轮询进程可预先设置好待查询描述符列表,然后进入一个循环等待事件发生,每次循环回来时不必再次设置待查询描述符列表。
打开/dev/poll后,轮询进程必须先初始化一个pollfd结构(poll函数使用的结构,但本机制不使用其中的revents成员)数组,再调用write往/dev/poll设备上写这个结构数组以把它传给内核,然后执行ioctl函数的DP_POLL命令阻塞自身等待事件发生。传递给ioctl函数的结构如下:

dp_fds成员指向一个缓冲区,供ioctl函数返回时存放pollfd结构数组,dp_nfds成员指定该缓冲区中有几个pollfd结构。ioctl函数将一直阻塞到一个被轮询描述符上发生所关心的事件,或流逝时间超过dp_timeout成员指定的毫秒数。dp_timeout指定为0将导致ioctl函数立即返回,从而提供了使用本接口的非阻塞手段。dp_timeout设为-1表示没有超时限制。
把第六章(6-13)中的str_cli函数改为使用/dev/poll的版本:
#include "unp.h"
#include <sys/devpoll.h>
void str_cli(FILE *fp, int sockfd) {
int stdineof;
char buf[MAXLINE];
int n;
int wfd;
// 我们只需要使用2个描述符,因此此处静态分配了2个元素的数组
// 实际可能要监视成百上千个描述符,可能这些程序的这个数组是动态分配的
struct pollfd pollfd[2];
struct dvpoll dopoll;
int i;
int result;
wfd = Open("/dev/poll", O_REWR, 0);
pollfd[0].fd = fileno(fp);
pollfd[0].events = POLLIN;
pollfd[0].revents = 0;
pollfd[1].fd = sockfd;
pollfd[1].events = POLLIN;
pollfd[1].revents = 0;
Write(wfd, pollfd, sizeof(struct pollfd) * 2);
stdineof = 0;
for (; ; ) {
/* block until /dev/poll says something is ready */
dopoll.dp_timeout = -1;
dopoll.dp_nfds = 2;
dopoll.dp_fds = pollfd;
// ioctl函数返回值是已就绪描述符个数
result = Ioctl(wfd, DP_POLL, &dopoll);
/* loop through ready file descriptors */
for (i = 0; i < result; ++i) {
if (dopoll.dp_fds[i].fd == sockfd) {
/* socket is readable */
if ((n = Read(sockfd, buf, MAXLINE)) == 0) {
if (stdineof == 1) {
return; /* normal termination */
} else {
err_quit("str_cli: server terminated permaturely");
}
Write(fileno(stdout), buf, n);
}
// 我们知道就绪的描述符不外乎sockfd和输入文件描述服
// 规模较大的程序描述符遍历工作比较复杂,可能涉及往线程派遣任务
} else {
/* input is readable */
if ((n = Read(fileno(fp), buf, MAXLINE)) == 0) {
stdineof = 1;
Shutdown(sockfd, SHUT_WR); /* send FIN */
continue;
}
Writen(sockfd, buf, n);
}
}
}
}
FreeBSD随4.1版本引入了kqueue接口,允许向内核注册描述所关注kqueue事件的事件过滤器。事件除了关注与select函数类似的文件IO和超时外,还有异步IO、文件修改通知(如文件被删除或修改时发出的通知)、进程跟踪(如进程调用exit或fork时发出的通知)、信号处理。kqueue接口包含以下2个函数和1个宏:

kqueue函数返回一个新的kqueue描述符,用于后续的kevent函数。kevent函数既用于注册所关注的事件,也用于确定是否有所关注的事件发生。changelist和nchanges参数给出对所关注事件作出的更改,若无更改则分别取值为NULL和0。条件触发的事件(包括刚在changelist参数中增设的事件)由kevent函数的eventlist参数返回,它指向一个由参数nevents个元素构成的kevent结构数组。kevent函数在eventlist参数中返回的事件数目作为函数返回值返回,0表示超时。超时通过timeout参数设置,其处理类似select函数:NULL阻塞进程、非0值timespec指定明确的超时值、0值的timespec执行非阻塞事件检查。kevent函数使用的timespec结构不同于select函数使用的timeval结构,前者分辨率为纳秒,后者分辨率为微秒。
kevent结构在头文件sys/event.h中定义:

flags成员在调用kevent时改变过滤器行为的值和返回时被设置的值如下:

filter成员指定的过滤器类型:

把第六章(6-13)中使用select函数的str_cli函数改为使用kqueue的版本:
#include "unp.h"
void str_cli(FILE *fp, int sockfd) {
int kq, i, n, nev, stdineof = 0, isfile;
char buf[MAXLINE];
struct kevent kev[2];
struct timespec ts;
struct stat st;
// 文件描述符关联的是否是文件
isfile = ((fstat(fileno(fp), &st) == 0) && (st.st_mode & S_IFMT) == S_IFREG);
EV_SET(&kev[0], fileno(fp), EVFILT_READ, EV_ADD, 0, 0, NULL);
EV_SET(&kev[1], sockfd, EVFILT_READ, EV_ADD, 0, 0, NULL);
// 调用Kqueue取得一个kqueue描述符
kq = Kqueue();
// 设置超时值为0以便非阻塞地调用kevent
ts.tv_sec = ts.tv_nsec = 0;
// 以设置好的kevent结构数组作为过滤器更改请求调用kevent
Kevent(kq, kev, 2, NULL, 0, &ts);
for (; ; ) {
// 每次调用kevent指定的过滤器更改列表为NULL(我们仅关注已注册过的事件),超时参数为NULL(永远阻塞)
nev = Kevent(kq, NULL, 0, kev, 2, NULL);
for (i = 0; i < nev; ++i) {
if (kev[i].ident == sockfd) { /* socket is readable */
if ((n = Read(sockfd, buf, MAXLINE)) == 0) {
if (stdineof == 1) {
return; /* normal termination */
} else {
err_quit("str_cli: server terminated prematurely");
}
}
Write(fileno(stdout), buf, n);
}
if (kev[i].ident == fileno(fp)) { /* input is readable */
n = Read(fileno(fp), buf, MAXLINE);
if (n > 0) {
Writen(sockfd, buf, n);
}
// kqueue函数在报告EOF时,对于管道和终端,kqueue函数和select函数一样
// 对于文件,kqueue函数每次返回把文件中剩余字节数存到kevent.data,如果我们读到的字节数和该值一样,就说明读到了EOF
if (n == 0 || (isfile && n == kev[i].data)) {
stdineof = 1;
Shutdown(sockfd, SHUT_WR); /* send FIN */
kev[i].flags = EV_DELETE;
Kevent(kq, &kev[i], 1, NULL, 0, &ts); /* remove kevent */
continue;
}
}
}
}
}
对新近发展中的接口而言,阅读它们特定于操作系统具体版本的文档时要小心,这些接口在不同版本间往往存在细微差别,因为操作系统厂家仍在推敲它们该如何工作的细节。
尽管应避免编写不可移植的代码,但对于一个任务繁重的网络应用而言,使用各种可能的方式为它在特定主机系统上进行优化也很常见。
T/TCP(事务TCP)是对TCP进行修改的版本,能避免近来彼此通信过的主机之间的三路握手。
T/TCP最广为流传的实现是FreeBSD的实现。
T/TCP能把SYN、FIN和数据组合到一个分节中,前提是数据大小小于MSS。
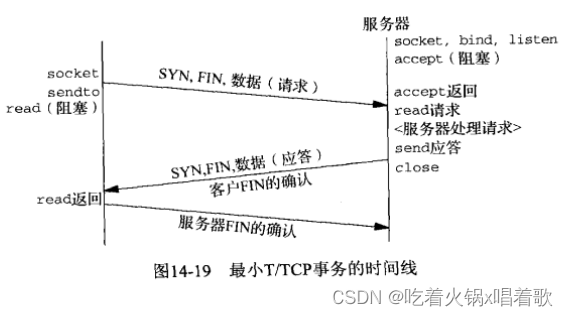
如上图,第一个分节是由客户的单个sendto调用产生的SYN、FIN和数据,该分节组合了connect、write、shutdown三个函数的功能。而服务器会执行通常的套接字函数调用步骤:socket、bind、listen、accept,accept函数在客户的分节到达时返回。服务器用send函数发回应答并关闭套接字。服务器在同一分节中向客户发出SYN、FIN和应答。可见T/TCP可减少网络中传输的分节(TCP需10个,UDP需2个),且客户从初始化连接到发送一个请求再到读取相应应答所花时间也减少了一个RTT。
T/TCP的优势在于TCP的所有可靠性(序列号、超时、重传等)得以保留,而不像UDP那样把可靠性推给应用去实现。T/TCP同样维持TCP的慢启动和拥塞避免措施。
客户与服务器第一次通信时三路握手是需要的,不过将来只要两端各自高速缓冲的一些信息没过时,且没有一端的主机崩溃并重启过,就可以避免三路握手。上图的3个分节构成最少请求-应答交换,如果请求或应答超过一个分节的承载量,就需要额外的分节。
术语“事务”的含义是客户的请求与服务器的应答,常见的事务的例子有DNS请求与服务器的应答、HTTP请求与服务器的应答。该术语并非指代两阶段提交协议(two-phase commit protocol),两阶段提交协议是一种分布式系统中用于协调多个参与者(进程或节点)的一致性的协议,它旨在确保在分布式环境中进行的事务操作的原子性和一致性。在分布式系统中,如果涉及多个参与者的操作需要保持一致性,那么在提交(commit)这些操作之前,必须确保所有参与者都同意执行操作,并且在所有参与者都成功执行后,再统一提交或回滚操作。 Two-Phase Commit Protocol提供了一种机制来实现这种协调和一致性。该协议由两个阶段组成:
1.Prepare Phase(准备阶段):在这个阶段,协调者(coordinator)向所有参与者发送一个准备请求,询问它们是否可以执行事务操作。每个参与者会根据自身的状态来决定是否可以执行。如果所有参与者都同意执行,它们将准备好并发送准备完成的消息给协调者。
2.Commit Phase(提交阶段):在准备阶段完成后,协调者将向所有参与者发送一个提交请求。如果所有参与者在准备阶段都准备好了,它们将执行事务的提交操作。一旦所有参与者完成提交操作,它们将向协调者发送确认消息。
这个协议的关键在于所有参与者必须遵循协议的执行流程,并且在故障发生时有适当的恢复机制。如果所有参与者都成功执行并确认提交,那么协调者将通知应用程序事务已成功提交。如果任何一个参与者无法执行或者在提交阶段发生故障,协调者将通知应用程序事务失败,需要进行回滚操作。
Two-Phase Commit Protocol通过协调者与参与者之间的消息交换,确保了分布式环境中的事务一致性,但也因为需要所有参与者的同意和网络通信的开销,导致了协议的复杂性和性能上的一定开销。
为处理T/TCP,套接字API需作出一些改动,但在提供T/TCP的系统上的TCP应用无需任何改动,除非要使用T/TCP特性。有关T/TCP:
1.客户调用sendto,以便把数据的发送结合到连接的建立中,该调用替换单独的connect和write调用,服务器的协议地址传递给sendto函数而非connect函数。
2.sendto函数的flags参数新增标志MSG_EOF,用于指示本套接字上不再有数据待发送。该标志允许我们把shutdown调用结合到输出操作,给一个sendto调用同时指定本标志和服务器的协议地址可能导致发送单个含有SYN、FIN、数据的分节。图14-9指出服务器发送应答使用的是send函数而非write函数,是为了指定MSG_EOF标志,以便随应答一起发送FIN。
3.新定义一个级别为IPPROTO_TCP的套接字选项TCP_NOPUSH,本选项阻止发送方将小数据块发送出去,直到达到一定的条件。具体条件的实现可能因操作系统而异,但一般情况下,当发送缓冲区中的数据块大小达到一定阈值、发送方收到确认或发送缓冲区被填满时,数据才会被发送。
4.想跟服务器建立连接并使用T/TCP发送请求的客户应调用socket、setsockopt(开启TCP_NOPUSH选项)、sendto(若只有一个请求待发送则指定MSG_EOF标志)。如果setsockopt函数返回ENOPROTOOPT或sendto函数返回ENOTCONN错误,则本主机不支持T/TCP,此时客户只能调用connect和write,后跟shutdown函数(如果只有一个请求待发送)。
5.服务器所需的唯一变动是,如果想随应答一起发送FIN,就指定MSG_EOF标志调用send函数发送应答,而不是调用write函数。
6.可用条件编译指令#ifdef MSG_EOF进行编译时测试MSG_EOF是否定义。
在套接字操作上设置时间限制的方法:
1.使用alarm函数和SIGALRM信号。
2.使用由select函数提供的时间限制。
3.使用较新的SO_RCVTIMEO和SO_SNDTIMEO套接字选项。
第一个方法易于使用,但涉及信号处理,信号处理可能存在竞争条件。使用select函数意味着我们阻塞在指定了时间限制的该函数上,而非read、write、connect函数上。第三个方法易于使用,但并非所有实现都支持。
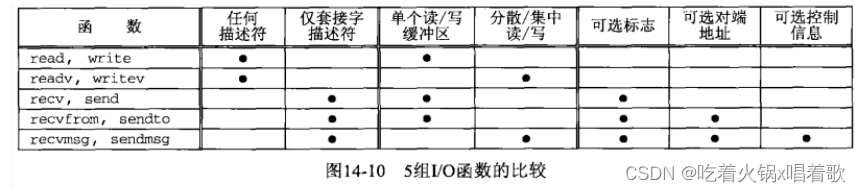
recvmsg和sendmsg函数是5组IO函数中最通用的,它们有以下能力:指定MSG_xxx标志(来自recv和send函数)、返回或指定对端协议地址(来自recvfrom和sendto函数)、使用多个缓冲区(来自readv和writev函数),另外一组IO函数是read和write。此外还新增了两个新特性:给进程返回标志、接受或发送辅助数据。
辅助数据由一个或多个辅助数据对象构成,每个对象都以一个cmsghdr结构打头,它指定数据的长度、协议级别、类型。
C标准IO库也可用在套接字上,但这么做将在已经由TCP提供的缓冲级别上新增一级缓冲。事实上,对由标准IO函数库执行的缓冲缺乏了解是使用该函数库的最常见问题,该问题的重用解决方法是把标准IO流设置成不缓冲,或不要在套接字上使用标准IO。
许多厂家提供轮询大量事件却没有select和poll函数所需开销的高级方法,尽管应避免编写不可移植的代码,有时性能改善的收益会重于不可移植造成的风险。
T/TCP是对TCP增强版本,能在客户和服务器最近彼此通信过的前提下避免三路握手,使得服务器对客户的请求更快给出应答。从编程角度看,客户通过调用sendto而非通常的connect、write、shutdown调用序列来发挥T/TCP的优势。
如果main函数末尾没有调用exit,标准IO缓冲区中尚未输出的数据也会输出,因为main函数末尾未调用exit等同于从main函数返回,而main函数又是由C启动例程如下调用的:
exit(main(argc, argv));
因此exit函数仍被调用,标准IO清扫例程也同样被调用。