redis cluster需求至少需要3个master才能组成一个集群,同时每个sentinel至少有一个slave节点,各个节点之间保持tcp通信。当master发生宕机,redis cluster自动将对应的slave节点提拔为master,来重新对外提供服务。
先来说一下槽,集群的中每个redis实例都负责接管一部分槽,总槽数为:16384(2^ 14),如果有3台master,那么每台负责5641个槽(16284)。
官网建议 集群个数不要超过1000个
| redis节点 | 负责的槽位 | 个数 |
|---|---|---|
| 节点1 | 0-5461 | 5631 |
| 节点2 | 5461-10922 | 5632 |
| 节点1 | 10922-16383 | 5631 |
当redis客服端设置值时,会拿key进行CRC16算法,然后更16284取模,得到的就是落在那个槽位。根据上面的表格就知道key在那台redis上。
slot = CRC16(key) mod 16383
redis cluster功能: 负载均衡,故障转移,主从复制。
- 负载均衡,
redis 集群支持多个master - 故障转移
cluster自带sentinel 故障转移机制 - 主从复制
cluster 可支持多个master,每个master 又支持多个slave - 客服端与redis的节点连接,不需要连接节点中的所有节点,只要连接集群中任意一个可用节点即可,由cluster 通过CRC16算法将key分配到槽位,而又在不同的redis实例中。
rediscluster 分片
使用redis集群时,我们会将存储的数据分散到多台redis上,这称为分片。简言之,集群中每个redis实例都是一个分片。
rediscluster 为何要使用槽位
最大优势时方便扩容,和数据分派查找
方便扩容
这种结构很容易添加或删除节点,
比如我们想新添加节点D,我们需要将A,B,C中部分槽位分到D上。
再比如我们需要将A中的槽位移到B,C,然后将没有任何槽位的A节点移除即可
由于从一个节点将哈希槽移到另一个节点不会停止服务,无论是添加槽删除槽或者改变某个节点槽的数量,都不会造成集群不可用状态。
槽位映射,一般业界有三种解决方案
-
哈希取余分区
假设有n台redis实例,每次hash(key)%n计算出hash值,用hash值决定数据映射在那一台主机上
优点:
简单有效,只需要预估好数据的节点,例如3,起到负载均衡,分而治之的作用
缺点
原来已经规划好的节点,进行扩容或缩容就比较麻烦,每次扩容映射关系需要重新计算。取模公式也会发生变化,hash(key)%3->hash(key)%?。 -
一致性哈希算法分区
设计目的:为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母的值改变了,自然取余数就不OK了的问题。
主要实现以下三步
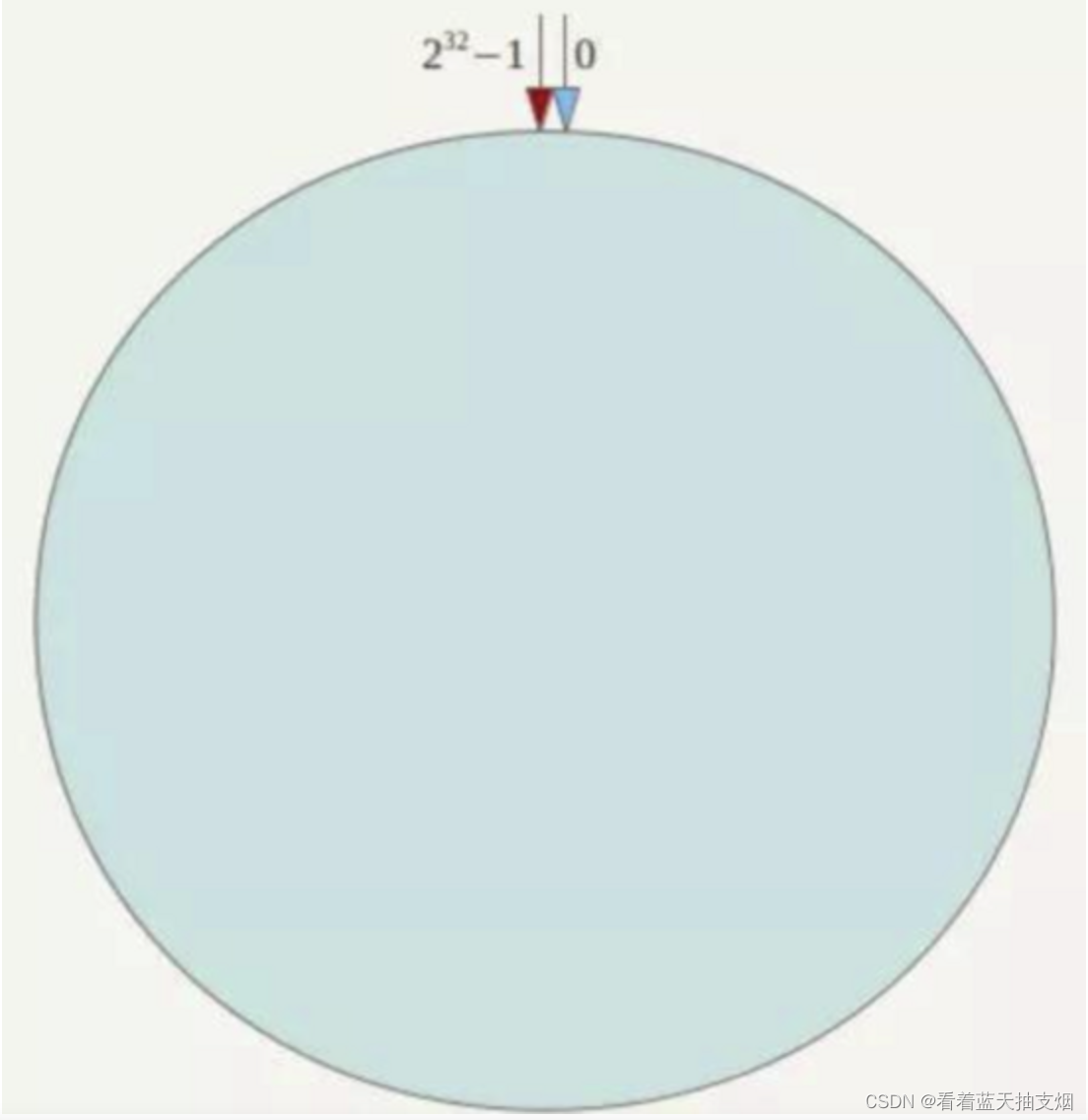
A.算法一致性hash环一致性hash算法必然有一个hash函数按算法产生hash值,这个算法的 所有hash值在0-2^ 32中,让0=2^ 32。就形成了一个环形空间。 它也是按照使用取模的方法,但是是按2^ 32 取模。
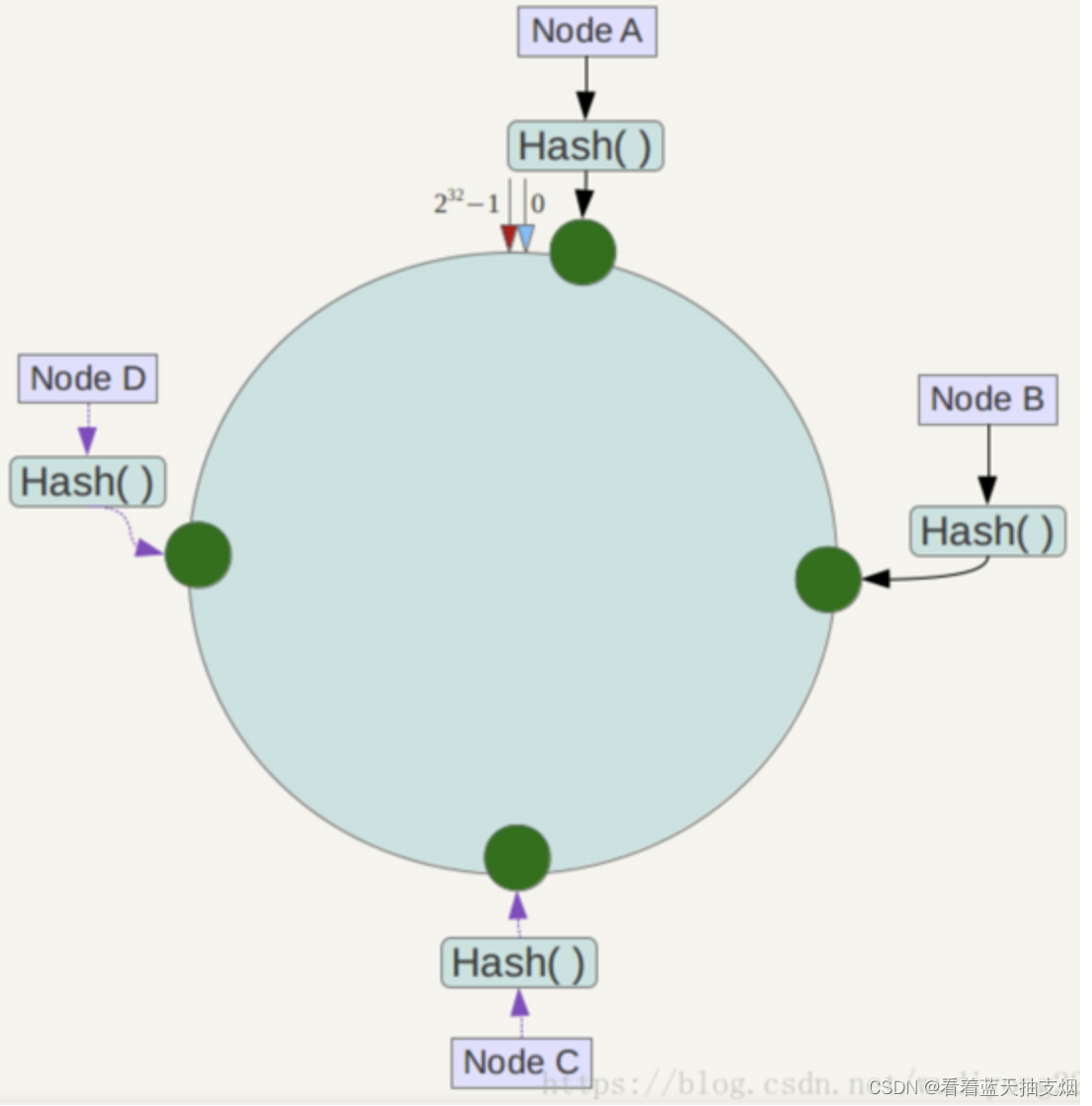
B。服务器IP节点映射
将集群的各个节点的IP映射到环上的某一个位置,
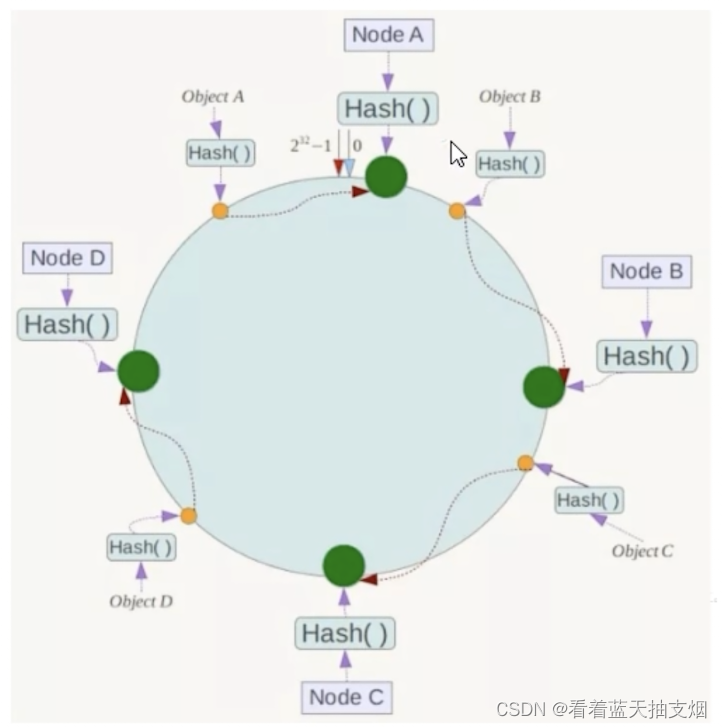
假如4个节点 NodeA,B,C,D
C.key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先会计算key的hash值,将这个key使用相同
的函数Hash()计算出hash值,并确定此程序在环上的位置,从此位置沿顺时针行
走,第一台遇到的服务器就是其存储到的服务器。
如,我们有ObjectA,ObjectB,ObjectC,OjbectD 4个存储对象,经过hash计
算后,在环形空间上位置如下,hash一致性算法ObjectA在NodeA,ObjectB在
nodeB,ObjectC在nodeC
一致性hash算法的优点
1.容错性
假上图的nodeC宕机了,可以看到A,B,D不会受影响,一般在一致性hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器的数据,简单说,就是C不可用了,受影响的是BC之间的数据且这些数据会转移到D
2.扩展性
数据量增加了,需要增加一台节点nodeX,假设nodeX在A和B之间,那受到影响的只是A到X之间的数据,重新吧A->X中的数据录入X即可,不会导致
hash取余重新洗牌。
一致性hash 算法的缺点
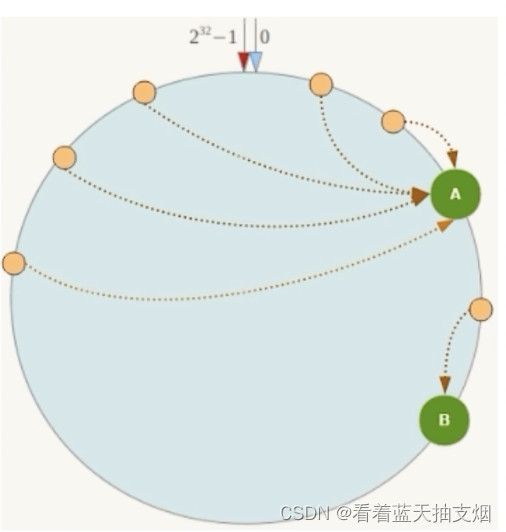
1.数据倾斜问题
一致性hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中在某一天服务器)问题。
加入只有两台redis服务器:




![C++ [STL之string模拟实现]](https://img-blog.csdnimg.cn/84e4fd60d85a42619862f999bd6ec9ea.png#pic_center)