1 背景与基础
1.1 为什么需要分词
对于人而言,在我们学会阅读之前,仍然可以理解语言。比如当你开始上学时,即使你不知道名词和动词之间的区别,但是你已经可以和你的同学交谈了,比如“我喜欢吃香蕉”,孩子对于这些虽然不清楚,但是知道是什么意思的。在此刻,我们学会了把语音/语言变成一种书面语言,这样你就可以读写了。一旦你学会了将文本转换为声音,你就可以回忆使用之前学过的词义库。
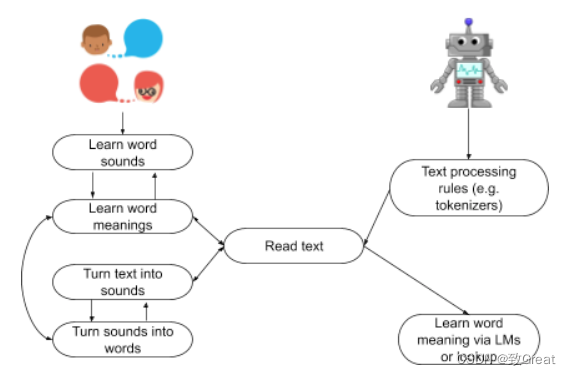
计算机(即语言模型 (LM) 或查找程序 (WordNet))在学习阅读之前不会学习说话,因此它们无法依赖以前学习过的词义记忆库。他们需要找到另一种发现词义的方法。
机器没有这种语音先机。在对语言一无所知的情况下,我们需要开发系统,使它们能够处理文本,而无需像人类那样已经能够将声音与单词的含义联系起来的能力。这是经典的“先有鸡还是先有蛋”的问题:如果机器对语法、声音、单词或句子一无所知,它们如何开始处理文本?您可以创建规则来告诉机器处理文本,按照词典库对查找所需要的词。但是,在这种情况下,机器不会学习任何东西,您需要有一个静态数据集,其中包含每个可能的单词组合及其所有语法变体。
我们不是训练机器查找固定的词典,而是要教机器识别和“阅读”文本,使其可以从这个动作本身中学习。换句话说,它读得越多,学得越多。人类通过利用他们以前学习语音的方式来做到这一点。机器不具备可利用的这些知识,因此需要告知它们如何将文本分解为标准单元以进行处理。他们使用一种称为“标记化”的系统来做到这一点,在该系统中,文本序列被分成更小的部分或“Token”,然后作为输入输入到像 BERT 这样的 DL NLP 模型中。但是,在我们查看我们可以对文本进行分词的不同方式之前,让我们首先看看我们是否真的需要使用分词。
为了训练像 BERT 或GPT-2这样的 DL 模型在 NLP 任务中表现出色,我们需要为其提供大量文本。希望通过架构的特定设计,模型将学习一定程度的句法或语义理解。关于这些模型学习的语义理解水平仍然是一个活跃的研究领域。人们认为他们在神经网络的较低级别学习句法知识,然后在他们开始研究更具体的语言领域信号(例如医学与技术培训文本)时在较高级别学习语义知识。
使用的特定架构类型将对模型可以处理的任务、学习的速度以及执行情况产生重大影响。例如,GPT2 使用解码器架构,因为它的任务是预测序列中的下一个单词。相比之下,BERT 使用编码器类型的架构,因为它经过训练可用于更大范围的 NLP 任务,例如下一句预测、问答检索和分类。不管它们是如何设计的,它们都需要通过输入层输入文本才能执行任何类型的学习。

一种简单的方法是简单地输入训练数据集中出现的文本。这听起来很容易,但有一个问题。我们需要找到一种方法来以数学方式表示单词,以便神经网络对其进行处理。
请记住,这些模型没有语言知识。因此,如果他们对语言结构一无所知,就无法从文本中学习。它对模型来说就像是乱码,它不会学到任何东西。它不会理解一个词从哪里开始,另一个词从哪里结束。它甚至不知道什么是单词。我们通过首先学习理解口头语言然后学习将语音与书面文本联系起来来解决这个问题。所以我们需要找到一种方法来做两件事,以便能够将我们的文本训练数据输入到我们的 DL 模型中,下面就是我们为什么需要分词的主要原因:
- 将输入分成更小的块:模型对语言结构一无所知,因此我们需要在将其输入模型之前将其分成块或标记。
- 将输入表示为向量:我们希望模型学习句子或文本序列中单词之间的关系。我们不想将语法规则编码到模型中,因为它们会受到限制并且需要专业的语言知识。相反,我们希望模型学习关系本身并发现某种理解语言的方法。为此,我们需要将标记编码为向量,其中模型可以在这些向量的任何维度中编码含义。它们可以用作输出,因为它们代表单词的上下文参考。或者,它们可以作为更高级别
NLP 任务(例如文本分类)的输入或用于迁移学习而馈送到其他层。
1.2 分词粒度介绍
在使用GPT BERT模型输入词语常常会先进行tokenize ,tokenize具体目标与粒度是什么呢?tokenize也有许多类别及优缺点,这篇文章总结一下各个方法及实际案例。
tokenize的目标是把输入的文本流,切分成一个个子串,每个子串相对有完整的语义,便于学习embedding表达和后续模型的使用。
tokenize有三种粒度:word/subword/char
word级别
word/词,词,是最自然的语言单元。对于英文等自然语言来说,存在着天然的分隔符,如空格或一些标点符号等,对词的切分相对容易。但是对于一些东亚文字包括中文来说,就需要某种分词算法才行。顺便说一下,Tokenizers库中,基于规则切分部分,采用了spaCy和Moses两个库。如果基于词来做词汇表,由于长尾现象的存在,这个词汇表可能会超大。像Transformer XL库就用到了一个26.7万个单词的词汇表。这需要极大的embedding matrix才能存得下。embedding matrix是用于查找取用token的embedding vector的。这对于内存或者显存都是极大的挑战。常规的词汇表,一般大小不超过5万。

基于词粒度的Tokenization优缺点
- 优点:词粒度很像人类去阅读一样,一方面能够很好地保留词的边界信息,另一方面能够很好地保留词的含义。
- 缺点:(1)词粒度的方法,需要构造的词典太过庞大,严重影响计算效率和消耗内存。(2)即使使用这么大的词典不影响效率,也会造成 OOV 问题。因为人类语言是不断发展的,词汇也在发展中不断增加。例如:针不戳,Niubility,Sixology 等。 (3)词表中的低频词/稀疏词在模型训练过程中无法得到充分训练,进而模型不能充分理解这些词的语义。(4)一个单词因为不同的形态会产生不同的词,如由“look”衍生出的“looks”, “looking”, 但是意义相近,对他们都进行训练是不必要的。
字符级别
char/字符,即最基本的字符,如英语中的’a’,‘b’,‘c’或中文中的’你’,‘我’,'他’等。而一般来讲,字符的数量是少量有限的。这样做的问题是,由于字符数量太小,我们在为每个字符学习嵌入向量的时候,每个向量就容纳了太多的语义在内,学习起来非常困难。

基于字符粒度的Tokenization优缺点
- 优点:它的优点是,词表大大减小,26 个英文字母基本能覆盖出几乎所有词,5000 多个中文基本也能组合出覆盖的词汇。
- 缺点: 这种方法严重丢失了词汇的语义信息和边界信息,这对 NER 等关注词汇边界的任务来说会有一定的影响。而且把单词切分的太细,会使得输入太过长增加输入计算压力,减小词表的代价就是输入长度大大增加,从而输入计算变得更耗时,训练时更占内存空间。
子词级别
subword/子词级,它介于字符和单词之间。比如说’Transformers’可能会被分成’Transform’和’ers’两个部分。这个方案平衡了词汇量和语义独立性,是相对较优的方案。它的处理原则是,常用词应该保持原状,生僻词应该拆分成子词以共享token压缩空间。

2 常用tokenize算法
最常用的三种tokenize算法:BPE(Byte-Pair Encoding),WordPiece和SentencePiece

2.1 BPE
BPE 全称 Byte Pair Encoding,字节对编码,是一种数据压缩方法。最早是论文 [1] 将其引入到 NLP 技术中。BPE 迭代地合并最频繁出现的字符或字符序列,具体步骤:

举一个例子,有一个段文本““FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models.””
首先让我们看看单个单词出现的频率。本文中的单词出现频率如下:
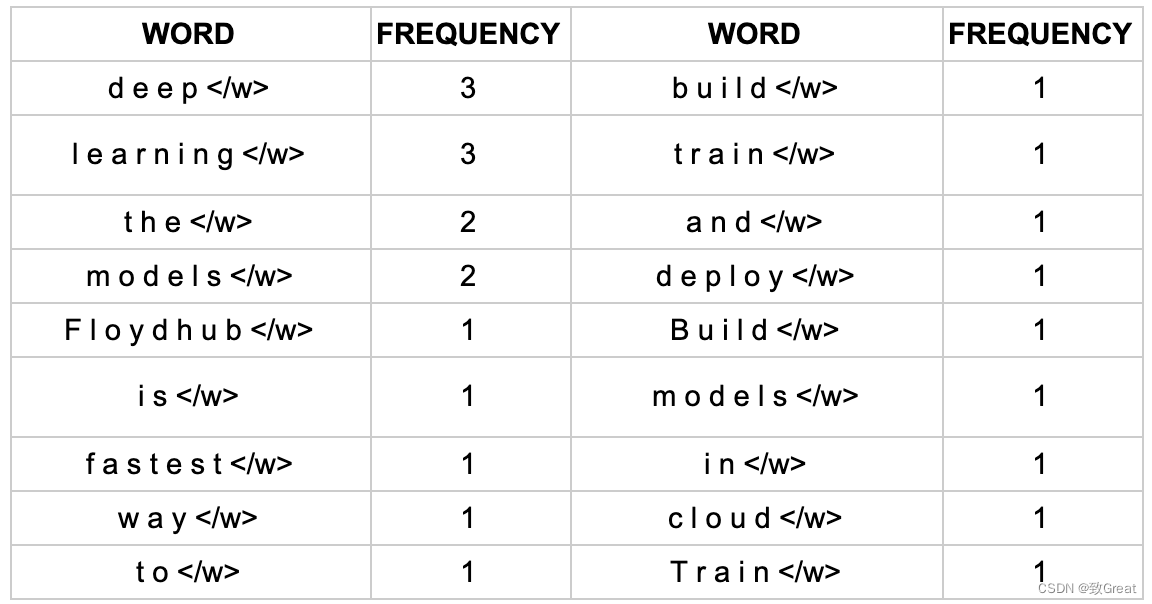
可以看到的是每个单词末尾都有一个“ ”标记。这是为了识别单词边界,以便算法知道每个单词结束的位置。这一点很重要,因为子词算法会查看文本中的每个字符并尝试找到频率最高的字符对。
BPE 子词算法的主要目标是找到一种方法来用最少的标记表示整个文本数据集。与压缩算法类似,我妈们希望找到表示图像、文本或您正在编码的任何内容的最佳方式,它使用最少的数据量,或者在我们的例子中是令牌。在 BPE 算法中,合并是我们尝试将文本“压缩”为子词单元的方式。
合并通过识别最常表示的字节对来实现。在我们的示例中,一个字符与一个字节相同,但情况并非总是如此,例如,在某些语言中,一个字符将由多个字节表示。但出于我们的目的,并且为了简单起见,字节对和字符对是相同的。这些合并操作有几个步骤():
- 获取单词计数频率
- 获取初始token计数和频率(即每个字符出现多少次)
- 合并最常见的字节对
- 将其添加到token列表并重新计算每个token的频率计数;这将随着每个合并步骤而改变
- 清洗去重,直到达到定义的令牌限制或设定的迭代次数(如我们的示例所示)
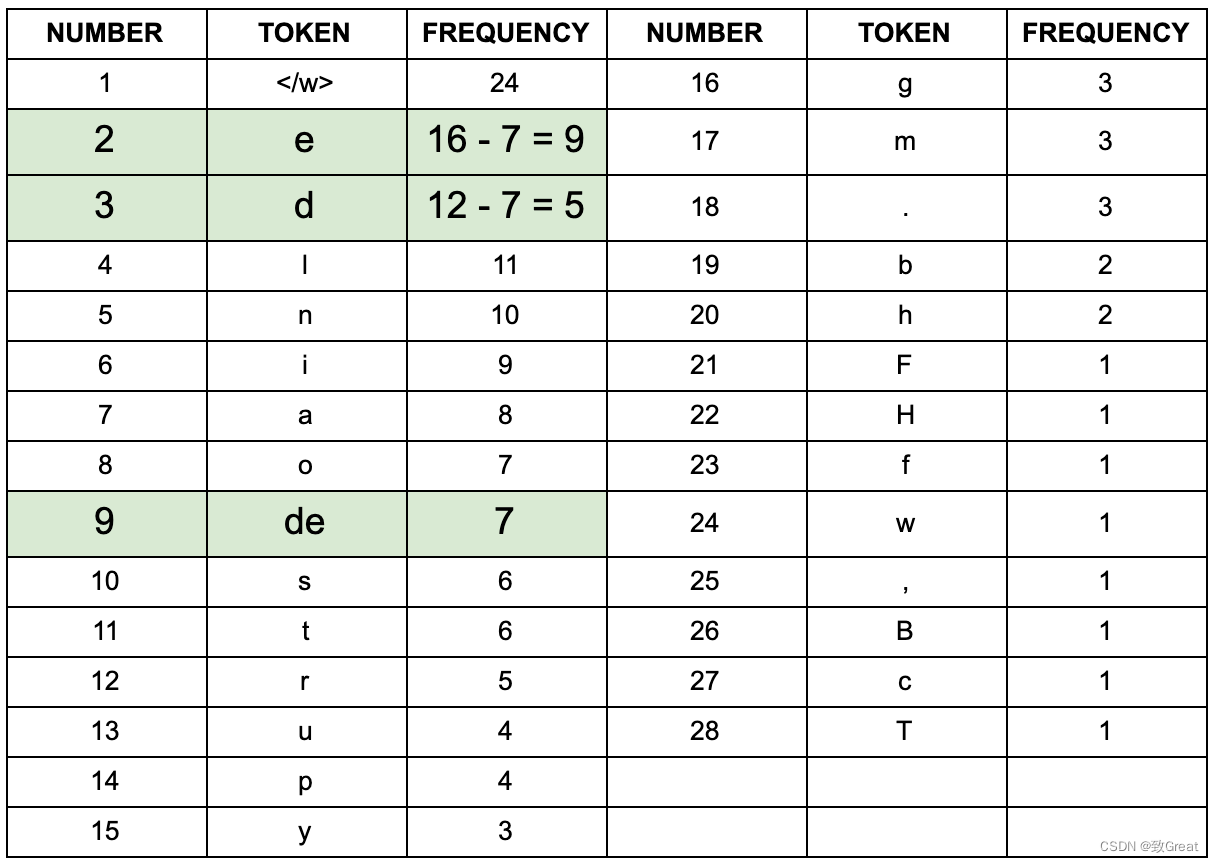
在一次迭代之后,我们最频繁的字符对是“ d ”和“ e ”。因此,我们将这些结合起来创建了我们的第一个子词标记(不是单个字符)“ de ”。我们是如何计算的?如果你还记得我们之前计算的词频,你会发现“ de ”是最常见的配对。

如果你把“ de ”出现的单词的频率加起来,你会得到 3 + 2 + 1 + 1 = 7,这就是我们新的“ de ”标记的频率。由于“ de ”是一个新token,我们需要重新计算所有标记的计数。我们通过从合并操作之前的单个字符的频率中减去新的“ de ”标记的频率 7 来实现这一点。如果我们考虑一下,这是有道理的。我们刚刚创建了一个新的token“ de ”。这在我们的数据集中出现了 7 次。现在我们只想计算“ d ”和“ e ”未配对时出现的次数。为此,我们从“ e”的原始出现频率中减去 7”,16,得到 9。我们从“ d ”的原始频率,12 中减去 7,得到 5,可以在“迭代 1”表中看到这一点。
让我们再做一次迭代,看看下一个最频繁的字符对是什么:

同样,我们添加了一个新字符,使字符数量达到 29,因此我们实际上在 2 次迭代后增加了字符数量。这很常见;当我们开始创建新的合并对时,字符的数量会增加,但随着我们将它们组合在一起并删除其他字符,字符的数量会开始减少。当我们在这里进行不同的迭代时,我们可以看到这个数字发生变化:

正如上图所看到的,当我们开始合并时,词汇的数量最初会增加。然后它在 34 处达到峰值并开始下降。此时子词单元开始合并,我们开始消除一个或两个合并对。然后,我们将字符构建成一种格式,该格式可以以最有效的方式表示整个数据集。对于我们这里的例子,我们在 70 次迭代和 18 个标记处停止。事实上,我们已经从单个字符标记的起点重新创建了原始单词。最终的词汇列表如下所示:

这看起来很熟悉吗?确实是这样的,这就是我们一开始开始使用的原始单词列表。那么我们做了什么?我们通过从单个字符开始并在多次迭代中合并最频繁的字节对标记来重新创建原始单词列表(如果使用较小的迭代,将看到不同的标记列表)。虽然这看起来毫无意义,但记住这是一个demo数据集,目标是展示子词标记化所采取的步骤。在现实世界的例子中,数据集的词汇量应该大得多,那么你将无法为词汇表中的每个单词都分配一个字符。
代码实现
import re
import collections
class BytePairEncoder:
def __init__(self):
self.merges = None
self.characters = None
self.tokens = None
self.vocab = None
def format_word(self, text, space_token='_'):
return ' '.join(list(text)) + ' ' + space_token
def initialize_vocab(self, text):
text = re.sub('\s+', ' ', text)
all_words = text.split()
vocab = {}
for word in all_words:
word = self.format_word(word)
vocab[word] = vocab.get(word, 0) + 1
tokens = collections.Counter(text)
return vocab, tokens
def get_bigram_counts(self, vocab):
pairs = {}
for word, count in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pair = (symbols[i], symbols[i+1])
pairs[pair] = pairs.get(pair, 0) + count
return pairs
def merge_vocab(self, pair, vocab_in):
vocab_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
bytepair = ''.join(pair)
for word in vocab_in:
w_out = p.sub(bytepair, word)
vocab_out[w_out] = vocab_in[word]
return vocab_out, (bigram, bytepair)
def find_merges(self, vocab, tokens, num_merges):
merges = []
for i in range(num_merges):
pairs = self.get_bigram_counts(vocab)
best_pair = max(pairs, key=pairs.get)
best_count = pairs[best_pair]
vocab, (bigram, bytepair) = self.merge_vocab(best_pair, vocab)
merges.append((r'(?<!\S)' + bigram + r'(?!\S)', bytepair))
tokens[bytepair] = best_count
return vocab, tokens, merges
def fit(self, text, num_merges):
vocab, tokens = self.initialize_vocab(text)
self.characters = set(tokens.keys())
self.vocab, self.tokens, self.merges = self.find_merges(vocab, tokens, num_merges)
2.2 WordPiece
WordPiece 最早在《Japanese and korean voice search》中提出,并应用于解决日语和韩语语音问题。它与 BPE 相同点:每次从统计语料中选取出两个新的子词进行合并。
**它与 BPE 最大区别在于选择两个子词进行合并的原则:BPE 按频率,WordPiece 按能够使得 LM 概率最大的相邻子词加入词表。 **
对于 WordPiece 构造词表的原理如下:
假设由句子
s
=
{
t
1
,
t
2
,
t
3
,
.
.
.
,
t
n
}
s=\{t_1,t_2,t_3,...,t_n\}
s={t1,t2,t3,...,tn} 由
n
n
n个子词组成,
t
i
t_i
ti表示第
i
i
i 个子词,且假设子词之间是相互独立的,那么句子
s
s
s的语言模型对数似然值为:

假设把相邻的
t
i
t_i
ti和
t
j
t_j
tj两个子词合并,产生
t
x
t_x
tx子词,此时句子的对数似然值增益为:

两个子词合并前后的对数似然值增益等于
t
x
t_x
tx和
t
i
t
j
t_it_j
titj 的互信息。所以,WordPiece 每次选择合并的两个子词,具有最大的互信息值,从语言模型上来说两个子词之间有很强的关联性,从语料上来说两个子词共现概率比较高。
WordPiece 的算法步骤如下:

2.3 UniLM
Unigram 语言建模首先在 《 Improving neural network translation models with multiple subword candidates》 中提出。这种方法与 WordPiece 相同点是:同样使用语言模型来挑选子词。与 WordPiece 最大区别:WordPiece 算法的词表大小都是从小到大变化。UniLM 的词库则是从大到小变化,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM 算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
对于 UniLM 构造词表的原理如下:
对于句子
s
s
s ,假如存在一种子词切分结果为
s
=
{
t
1
,
t
2
,
t
3
,
.
.
.
,
t
n
}
s=\{t_1,t_2,t_3,...,t_n\}
s={t1,t2,t3,...,tn} 则当前分词下句子
s
s
s的对数似然值可以表示为:

对于句子
s
s
s,挑选似然值最大的作为分词结果,即:

s
∗
s^*
s∗为最优切分结果。
UniLM 构造词典的算法步骤如下:

可以看出,UniLM 会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。
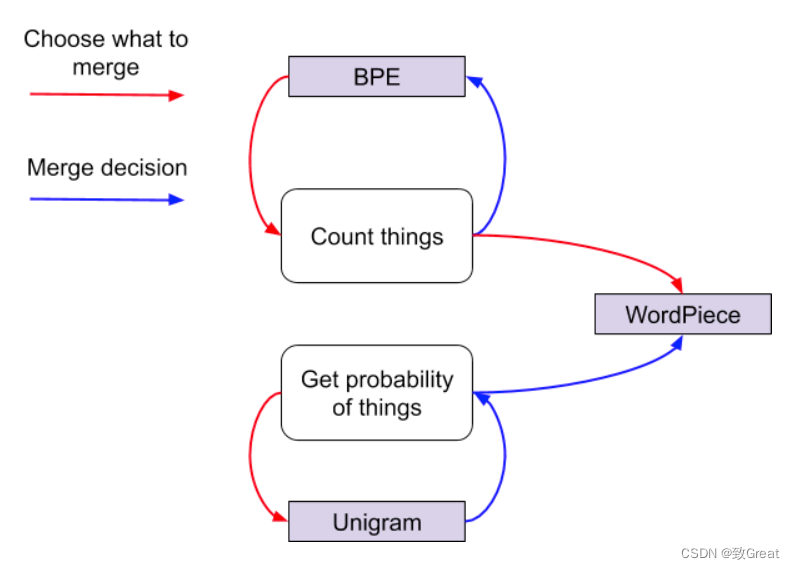
到这里我们喘口气,谁想到深度学习 NLP 过程的这一部分会如此困难?这只是这些模型的第一步!现在,简要总结一下:
- BPE:只是使用出现的频率来识别每次迭代的最佳匹配,直到它达到预定义的词汇量大小。
- WordPiece:类似于 BPE,使用频率出现来识别潜在的合并,但根据合并令牌的可能性做出最终决定
- Unigram:不使用频率出现的完全概率模型。相反,它使用概率模型训练
LM,删除提高整体可能性最少的标记,然后重新开始,直到达到最终标记限制。
2.4 SentencePiece
以上三种方法都存在着两个问题就是:1)无法逆转;2)训练的时候需要提前切分。无法逆转是什么意思呢,就是对句子 s 进行切分后得到的结果无法准确复原回 s。更直白地说就是空格不能被保留,如下:
到此,我们今天主角登场!
而 SentencePiece 的解决方法是:
-
SentencePiece 首先将所有输入转换为 unicode 字符。这意味着它不必担心不同的语言、字符或符号,可以以相同的方式处理所有输入;
-
空白也被当作普通符号来处理。Sentencepiece显式地将空白作为基本标记来处理,用一个元符号 “▁”( U+2581 )转义空白,这样就可以实现简单地decoding;
-
Sentencepiece 可以直接从 raw text 进行训练;
-
支持 BPE 和 UniLM 训练方法。
SentencePiece 由谷歌将一些词-语言模型相关的论文进行复现,开发了一个开源工具——训练自己领域的SentencePiece 模型,该模型可以代替预训练模型(BERT,XLNET)中词表的作用。开源代码地址为:https://github.com/google/sentencepiece。其原理就相当于:提供四种关于词的切分方法。这里跟中文的分词作用是一样的,但从思路上还是有区分的。通过使用我感觉:在中文上,就是把经常在一起出现的字组合成一个词语;在英文上,它会把英语单词切分更小的语义单元,减少词表的数量。
例如“机器学习领域“这个文本,按jieba会分“机器/学习/领域”,但你想要粒度更大的切分效果,如“机器学习/领域”或者不切分,这样更有利于模型捕捉更多N-gram特征。为实现这个,你可能想到把对应的大粒度词加到词表中就可以解决,但是添加这类词是很消耗人力。然而对于该问题,sentencepiece可以得到一定程度解决,甚至完美解决你的需求。
模型在训练中主要使用统计指标,比如出现的频率,左右连接度等,还有困惑度来训练最终的结果,论文题目为:《SentencePiece: A simple and language independent subword tokenizer
and detokenizer for Neural Text Processing》,地址为:https://arxiv.org/pdf/1808.06226.pdf
SentencePiece 的训练目标如下。我们希望最大化对数似然

其中x是 unigram 序列,S( x ) 表示所有可能序列的集合。同样,这些是隐藏变量,我们只看到未标记的语料库!为了解决这个问题,我们采用了 EM 类型的算法。如果熟悉 EM,你会注意到这些步骤实际上是倒退的,我们采用 ME 方法。尽管名字很花哨,但它实际上非常直观和直接。步骤是:
- 初始化一元概率。记住 P( x ) = P(x_1)…P(x_n) 所以一旦我们有了
unigrams,我们就有了任何序列的概率。在我们的代码中,我们只是使用 BPE 频率计数来更接近目标。 - M-step:计算给定当前概率的最可能的一元序列。这定义了单个标记化。实现这一点需要一些思考。
- E-step:给定当前标记化,通过计算标记化中所有子词的出现次数来重新计算一元概率。一元组概率就是该一元组出现的频率。实际上,将其贝叶斯化并改为计算并不困难

这里,c_i 是当前标记化中子词(unigram)i 的计数。M 是子词的总数。Psi 是双伽马函数。箭头表示我们如何进行贝叶斯化。 - 重复步骤 2 和 3 直到收敛。理论上保证对数似然单调增加,所以如果不是这样,你就错了。
3 训练SentencePiece分词模型
实现代码可以见:
https://github.com/google/sentencepiece
3.1 训练 BPE 模型
# train sentencepiece model from our blog corpus
spm.SentencePieceTrainer.train('--model_type=bpe --input=blog_test.txt --model_prefix=bpe --vocab_size=500 --normalization_rule_tsv=normalization_rule.tsv')
训练完模型后,加载它就可以开始使用了!
# makes segmenter instance and loads the BPE model file (bpe.model)
sp_bpe = spm.SentencePieceProcessor()
sp_bpe.load('bpe.model')
3.2 训练 Unigram 模型
可以采用与 BPE 模型大致相同的方式训练 Unigram 模型。
# train sentencepiece model from our blog corpus
spm.SentencePieceTrainer.train('--model_type=unigram --input=blog_test.txt --model_prefix=uni --vocab_size=500 --normalization_rule_tsv=normalization_rule.tsv')
# makes segmenter instance and loads the BPE model file (bpe.model)
sp_uni = spm.SentencePieceProcessor()
sp_uni.load('uni.model')
3.3 对比两种模型
可以通过调用“encode_as_pieces”函数使用训练好的子词模型对句子进行编码。我们对句子进行编码:“This is a test”。
print("BPE: {}".format(sp_bpe.encode_as_pieces('This is a test')))
print("UNI: {}".format(sp_uni.encode_as_pieces('This is a test')))
输出:
BPE: ['▁This', '▁is', '▁a', '▁t', 'est']
UNI: ['▁Thi', 's', '▁is', '▁a', '▁t', 'est']
3.4 查看所有的token
可以运行以下代码以查看完整词汇列表
vocabs = [sp_bpe.id_to_piece(id) for id in range(sp_bpe.get_piece_size())]
bpe_tokens = sorted(vocabs, key=lambda x: len(x), reverse=True)
bpe_tokens
输出如下:
['▁something',
'▁because',
'▁thought',
'▁really',
.
.
.
'9',
'*',
'8',
'6',
'7',
'$']
3.5 HuggingFace Tokenizers
HuggingFace的Tokenizers也实现了分词算法,具体使用可以参考如下:
from tokenizers import (ByteLevelBPETokenizer,
BPETokenizer,
SentencePieceBPETokenizer,
BertWordPieceTokenizer)
tokenizer = SentencePieceBPETokenizer()
tokenizer.train(["../blog_test.txt"], vocab_size=500, min_frequency=2)
output = tokenizer.encode("This is a test")
print(output.tokens)`
4 如何训练一个LLM分词器
SentencePiece的核心参数如下:
"""
sentencepiece 参数
trainer_spec {
input: data/corpus.txt
input_format: #
model_prefix: open_llama # 模型输出路径
model_type: BPE # 模型类型 bpe、char、word、unigram(gram)
vocab_size: 50000 # 词汇表大小,数量越大训练越慢,太小(<4000)可能训练不了
self_test_sample_size: 0
character_coverage: 0.9995 # 模型中覆盖的字符数
input_sentence_size: 0
shuffle_input_sentence: 0
seed_sentencepiece_size: 1000000 #
shrinking_factor: 0.75
max_sentence_length: 16384 # 最大句子长度,默认是4192,长度按照字节计算,一个中文代表长度为2
num_threads: 16 # 进程个数
num_sub_iterations: 2
max_sentencepiece_length: 16
split_by_unicode_script: 1
split_by_number: 1
split_by_whitespace: 1
split_digits: 1
pretokenization_delimiter:
treat_whitespace_as_suffix: 0
allow_whitespace_only_pieces: 1
required_chars:
byte_fallback: 1
vocabulary_output_piece_score: 1
train_extremely_large_corpus: 1
hard_vocab_limit: 1
use_all_vocab: 0 # 使用
unk_id: 0
bos_id: 1
eos_id: 2
pad_id: 3
}
normalizer_spec {
name: nfkc
add_dummy_prefix: 1
remove_extra_whitespaces: 0
escape_whitespaces: 1
normalization_rule_tsv:
}
"""
下面是我基于一个中文wiki语料(1.4GB)左右训练的sp模型例子:

import time
import sentencepiece as spm
start_time = time.time()
spm.SentencePieceTrainer.train(
input='data/corpus.txt', # 输入文件
model_prefix='open_llama', # 模型前缀
shuffle_input_sentence=False, # 是否打乱句子
train_extremely_large_corpus=True,
# hyperparameters of tokenizer
max_sentence_length=16384, # 句子最大长度
pad_id=3,
model_type="BPE",
vocab_size=50000,
split_digits=True,
split_by_unicode_script=True,
byte_fallback=True,
allow_whitespace_only_pieces=True,
remove_extra_whitespaces=False,
normalization_rule_name="nfkc",
)
end_time = time.time()
print(end_time - start_time)
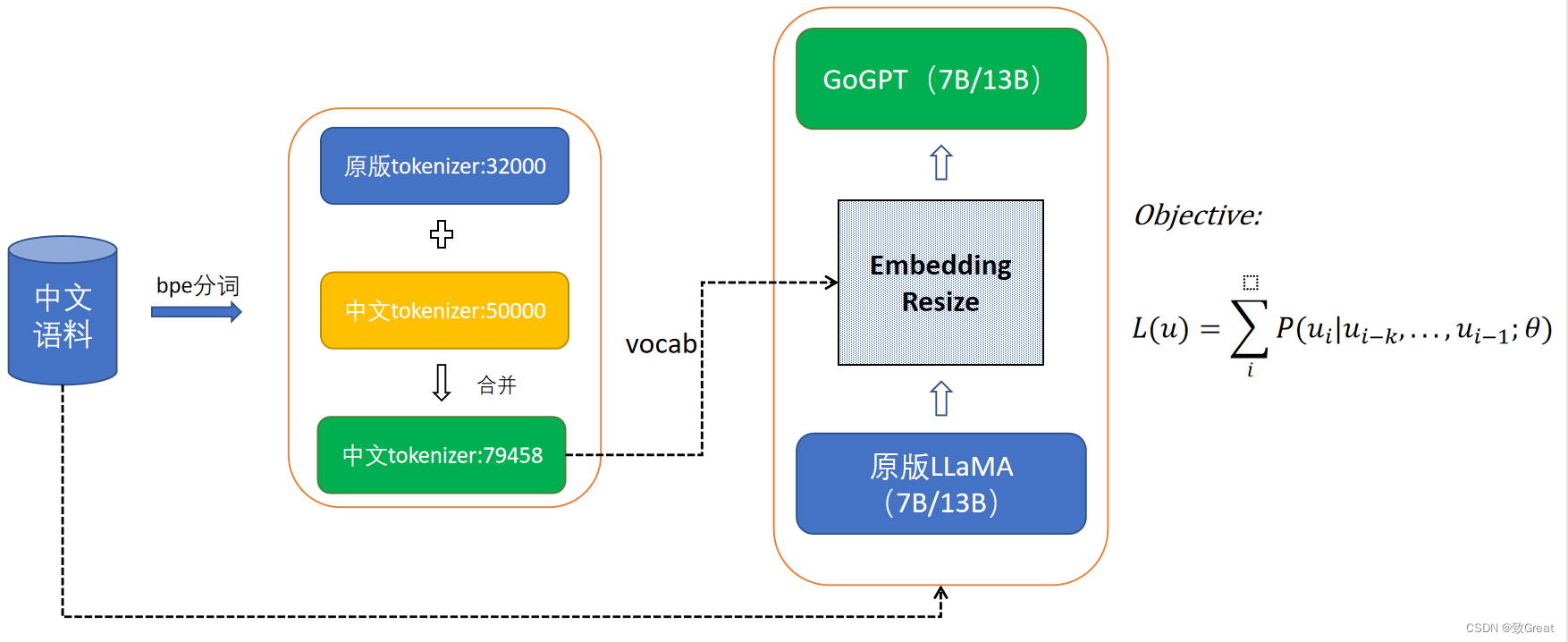
熟悉LLaMA模型的同学知道,LLaMA模型预训练中文语料特别少,并且中文测试效果比较差,在做中文增量的时候,我们可以将自己在中文训练语料训练的分词模型和原版llama分词模型合并:
#!/usr/bin/env python
# -*- coding:utf-8 _*-
"""
@author:quincy qiang
@license: Apache Licence
@file: step4_merge_tokenizers.py
@time: 2023/05/19
@contact: yanqiangmiffy@gamil.com
@software: PyCharm
@description: coding..
"""
from sentencepiece import sentencepiece_model_pb2 as model
''' Merge tokenizer '''
orig_model_path = '/path/to/llama/tokenizer.model'
belle_model_path = '/path/to/belle/belle.model'
orig_m = model.ModelProto()
belle_m = model.ModelProto()
orig_m.ParseFromString(open(orig_model_path, "rb").read())
belle_m.ParseFromString(open(belle_model_path, "rb").read())
print(len(orig_m.pieces), len(belle_m.pieces))
orig_pieces = []
for piece in orig_m.pieces:
orig_pieces.append(piece.piece)
for piece in belle_m.pieces:
if piece.piece not in orig_pieces:
orig_m.pieces.append(piece)
orig_pieces.append(piece.piece)
print(len(orig_m.pieces))
save_vocab_path = '/path/to/merge_tokenizer/tokenizer.model'
with open(save_vocab_path, 'wb') as f:
f.write(orig_m.SerializeToString())
训练大模型分词器的笔者认为比较重要的因素是:
(1)词表大小,词表大小应该是和语料大小去匹配的,具体设置我们可以参考下ChatGLM、和一些Chinese-LLaMA模型,像ChatGLM词表大小有13万,其他Chinese-LLaMA模型基本上在5万-8万左右。词表大小设置是否合理直接影响了模型参数以及训练速度
(2) 语料尽量充沛,因为垂直领域语料以及特殊语料库与大的底座模型的词频统计差别挺大的,如果单纯用一个相对狭隘的语料库训练tokenizer,有可能切词出来的token和常见切词方式不太一样,不符合通用语义。
(3) 词汇量大小的选择取决于模型质量和效率之间的权衡。当模型参数量较大的时候,我们可以设置较大的词汇表,在语料充足的情况下
完整代码:
https://github.com/yanqiangmiffy/how-to-train-tokenizer
参考资料
- BPE、WordPiece和SentencePiece
- NLP技术中的Tokenization