在推荐系统概览的第一讲中,我们介绍了推荐系统的常见概念,常用的评价指标以及首页推荐场景的通用召回策略。本文我们将继续介绍推荐系统概览的其余内容,包括详情页推荐场景中的通用召回策略,排序阶段常用的排序模型,推荐系统的冷启动问题和推荐系统架构,更多细节以及更详细的内容可以参考我的 Github repo。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
详情页推荐场景中的通用召回策略
详情页推荐场景中的通用召回策略包括(最常用的是前两种):基于 item 表示向量的相似度的召回;基于 item 关联规则的召回;基于 item 表示向量聚类的召回。
- 基于 item 表示向量的相似度的召回,常见的 item 表示方法如下:物品 item 的显式画像的表示;物品 item 的整个 embedding 向量的表示;用户-物品交互矩阵中 item 对应列向量的表示(假设用户是行,物品是列)
- 基于 item 关联规则的召回(常用在电商中的购物车页面推荐或者购买页面推荐中),找出所有用户购买的所有物品数据里频繁出现的 Item 序列,来做频繁集挖掘,找到满足支持度(即两个商品被同时购买的概率)阈值的关联物品。关联规则分析中的关键概念包括:支持度 (Support),它是两件商品(A∩B)在总销售笔数 (N) 中出现的概率,即 A 与 B 同时被购买的概率;置信度 (Confidence),它是购买 A 后再购买 B 的条件概率;提升度 (Lift),它表示先购买 A 对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。
在进行召回的时候,经常需要构建索引。对所有的用户进行索引是非常耗存储和费时的,所以在构建索引的时候,可能选择月活用户来构建索引是合适的。在做实时召回的时候,用户的行为序列特征除了可以考虑推荐业务相关的行为,还可以考虑同一个应用的其他形态比如用户在搜索业务中的行为。比如 YoutubeDNN 召回模型的特征,除了有用户最近观看过的 video id 序列 /video embedding,还有该用户最近搜索过的 word 序列或者 word 的 embedding。作者提到加入搜索业务的用户行为对整个效果提升不错。有意思的地方是 YoutubeDNN 排序模型并没有把用户最近搜索过的 word 序列或者 embedding 建模进来。
排序阶段常用的排序模型
排序阶段目前主流的都是基于传统机器学习或者深度学习的模型,排序模型的研究一直都是推荐系统领域的热点,国内外大厂都在这个领域大展拳脚。当前的排序模型有如下趋势:引入行为序列特征;引入注意力机制(比如 DIN,DIEN 等);引入多任务/多目标(比如 ESMM,MMOE,ESMM2,PLE 等);引入多模态。下面我们介绍几个常见的简单排序模型。
- LR 逻辑回归模型,它是 CTR 预估排序任务早期使用最多的模型。LR 的预测函数如下:
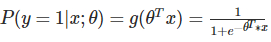
LR 模型的优点是简单方便,易解释。LR 模型的缺点是使用 LR 的时候,一般会把离散特征变成 one-hot 向量,这样就容易导致整个特征向量变成高维稀疏向量,从而使学习难度增大。LR 本质上是线性的,如果需要建模与目标变量非线性的关系,需要人工引入特征交叉来表示,因而相对于其他模型,需要更多的人工特征工程。目前为止, LR 在排序阶段的主要使用场景有两个地方:排序阶段的第一个模型;把 LR 模型作为排序阶段的 benchmark 或者 AB test 中的某个分桶。
- GBDT+LR 级联模型(具体可以参考 Facebook 的论文),思路是用 GBDT 对所有的原始特征进行编码,然后把得到的编码结果送入级联的 LR 做分类。本质上是利用 GBDT 自动进行特征筛选和组合,它的一个变体是 GBDT+FM 模型,利用 FM 来替换 LR。
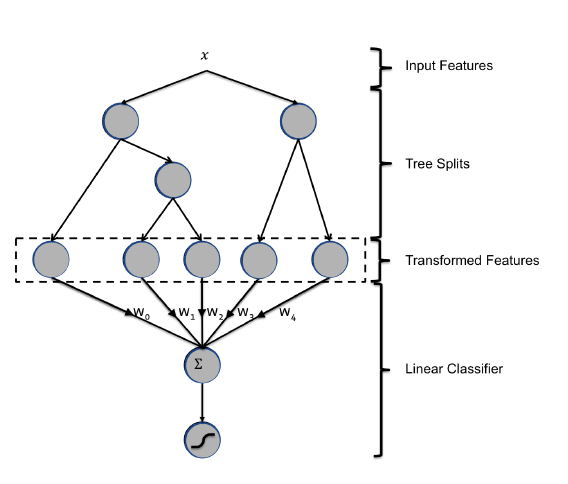
- FM 因子分解机模型(参考博客),它是在深度排序模型流行之前,使用的比较多的排序模型。FM 一般需要把 category 特征包括 ID 类特征都要变成 one-hot 向量,因此维度会很高(下图中的例子是针对3个 user,3个 item 的情况) 。爱奇艺使用用户的观看历史以及兴趣标签代替 user id,降低了特征维度,并且因为用户兴趣是可以复用的,同时也提高了对应特征的泛化能力。
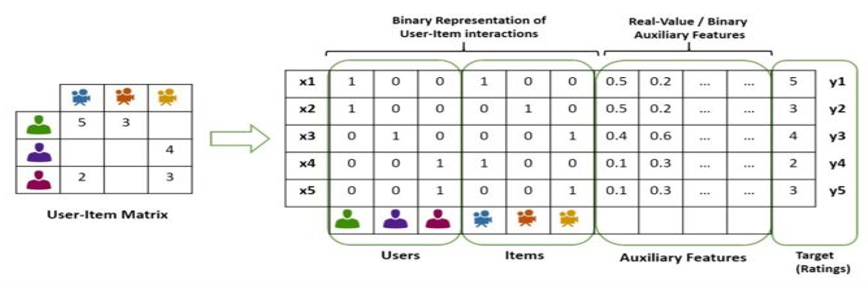
FM 可以看作是 Matrix Factorization(MF,矩阵分解)的进一步拓展,除了 User ID 和 Item ID 这两类特征外,很多其它类型的特征都可以进一步引入 FM。FM 自动计算特征二阶交叉,它将所有这些特征转化为 embedding 低维向量表达,并计算任意两个特征 embedding 的内积,作为这两个特征组合的权重。

- Wide & Deep networking Learning (WDL) 模型,它本质是上结合 LR 和 MLP,当前在业界用的比较多。Wide 部分即 LR 体现的是记忆功能,Deep 部分即 MLP 体现的是泛化功能,二者互补能提供更好的性能。区别于 GBDT+LR/FM(需要分别独立训练 GBDT 和 LR/FM),WDL 是端到端联合训练。WDL 能方便的建模用户的行为序列作为一个单独的特征。WDL 开创了在深度排序模型中结合 wide 部分和 deep 部分联合建模的热潮。WDL 中的 wide 部分是需要做手工的交叉特征的,这个是它的缺点(WDL模型之后,出了很多变体比如 DeepFM,Deep & Cross networking learning 等,它们的核心目的都是通过设计网络结构自动进行特征交叉)。他的网络结构如下:
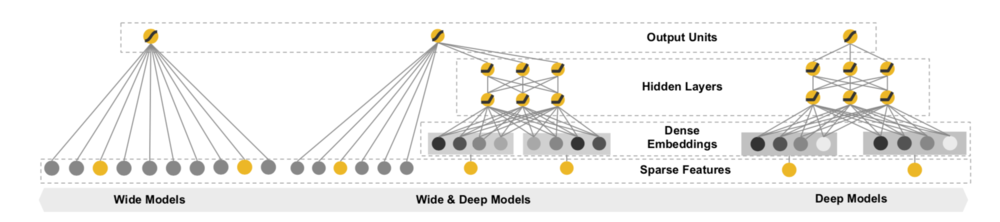
- DeepFM 模型,它是结合 FM 部分和 MLP 部分,不需要人工做特征二阶交叉组合(这个模型在国内客户中使用挺多的)。它的网络结构如下图所示:

重排阶段
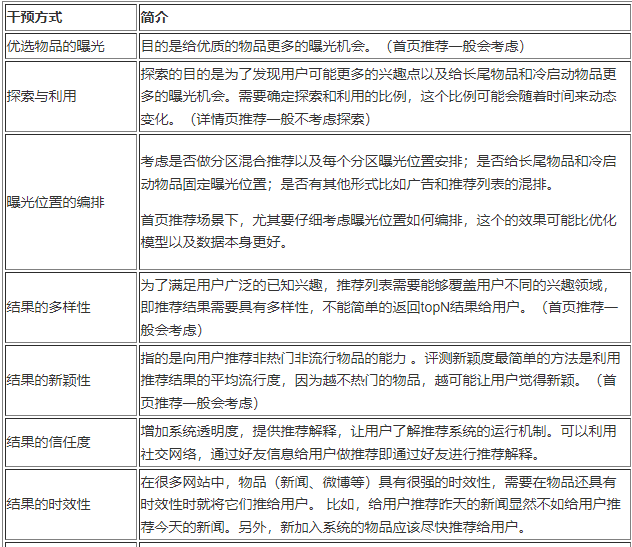
重排阶段主要就是业务运营人员用各种策略/规则进行干预。从对终端用户的推荐效果来讲,这个阶段我认为比排序阶段还要重要。重排主要从以下几个方面来进行干预(参考博客):

推荐系统的冷启动问题
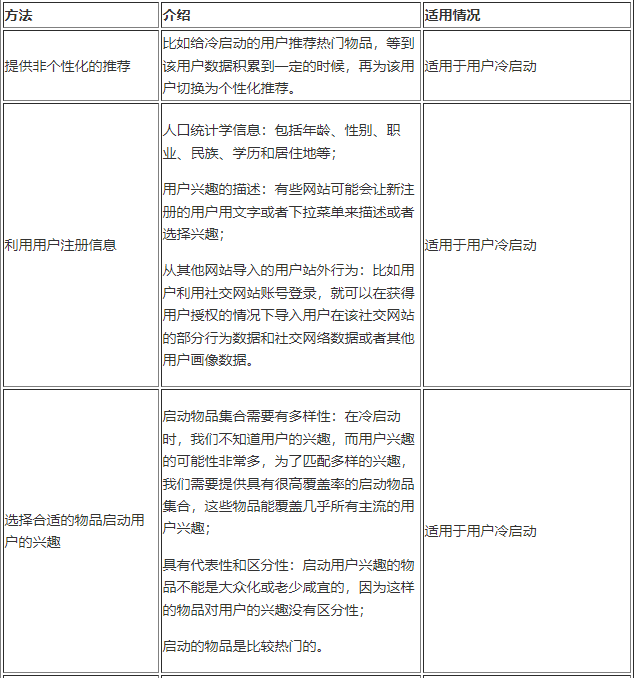
推荐系统冷启动问题分为如下三类:

针对冷启动问题,可能走专门的推荐链路效果更好,具体的方法参考如下(参考知乎博客):

推荐系统架构
一个好的推荐系统架构应该具有下面这些特点:实时响应请求;及时、准确、全面记录用户反馈(包括显示反馈和隐式反馈);可以优雅降级;快速实验多种策略和多种模型。
线上推荐的架构的两种模式:All in one process 方式,即所有逻辑包括召回,排序,重排都在一个 Recommendation server 中处理;解耦方式,即把逻辑中的两个部分召回和排序分别用一个服务来处理, Recommendation server 分别与这两个服务交互。
工业级推荐系统架构(参考自知乎博客):
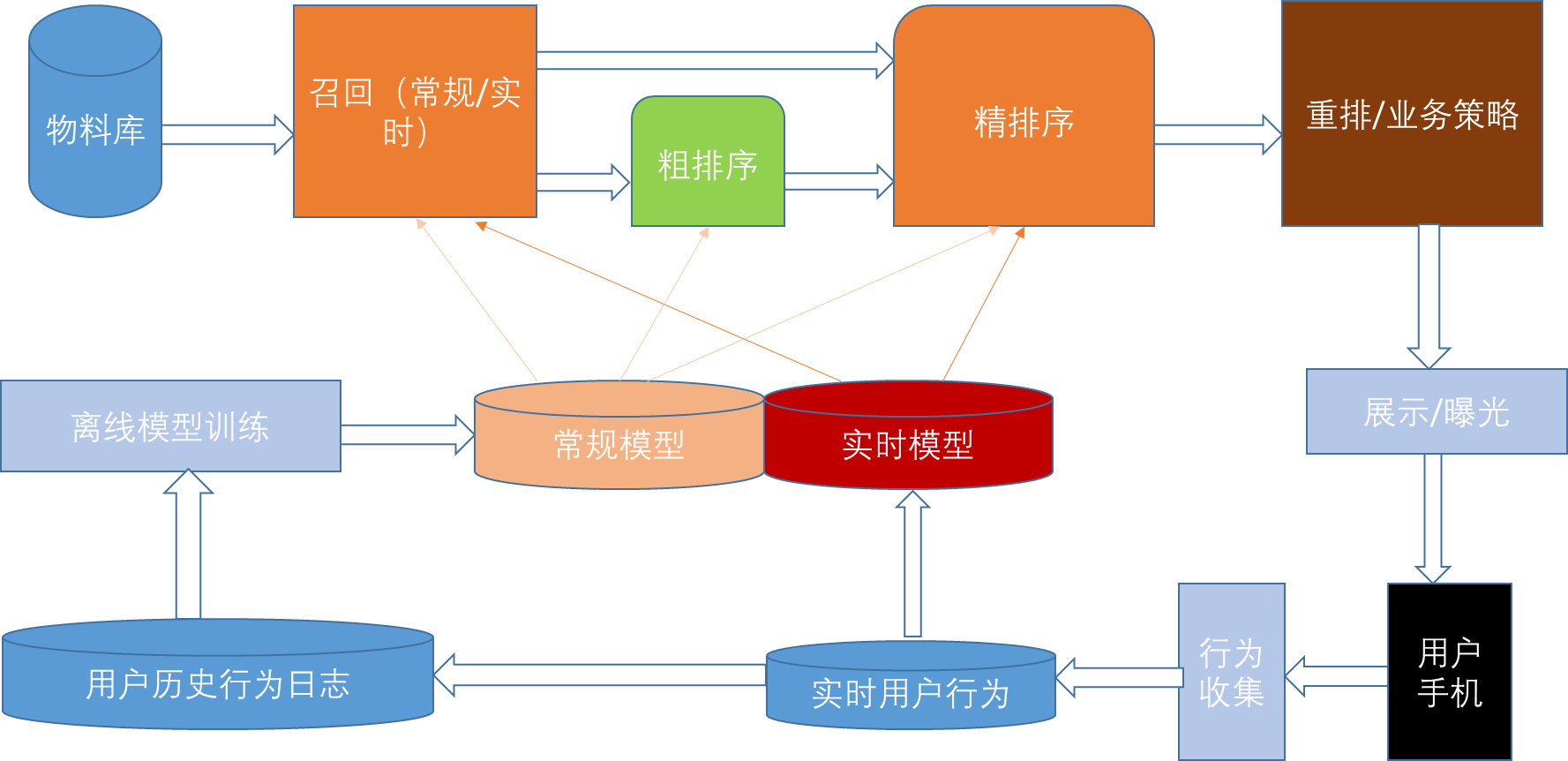
上图中的常规模型指的是周期离线训练并更新为线上的模型;上图中的实时模型指的是实时收集用户行为反馈,并选择训练实例,实时抽取拼接特征,并近乎实时地比如分钟级别更新在线推荐模型。这样做的好处是用户的最新兴趣能够近乎实时地体现到推荐结果里。这里的常规模型和实时模型共存的原因可能是某路召回模型或者排序模型没有办法做增量训练或当前常规模型和实时模型处于 A/B Test 部署中,或者常规模型作为 fallback 选择。
Netflix 的个性化推荐系统架构 (2013年) 如下图(参考自 Netflix 官方博客):
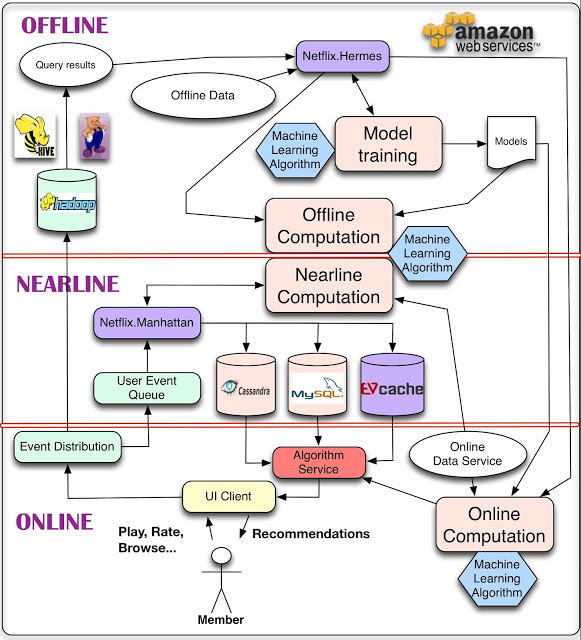
Netflix 的推荐系统分为离线,近在线,在线三个部分。在线部分要尽可能满足低延迟的 SLA 以响应实时的客户端请求。线上的召回,排序阶段的预测以及业务策略处理也属于 online 部分。离线部分是作为在线部分的一个 fallback 选项(即一种优雅降级的方法),同时它能提供一部分最终或者中间的推荐结果(比如作为一路召回或者分区混合推荐的一个分区),另外它能提供部分字段的预计算(比如用户画像和物品画像)。当然模型的离线训练也属于这个部分。近在线部分除了可以增量训练并近实时(比如分钟级别)的更新在线模型,还可以根据最新事件补充离线召回结果,以及根据用户最新浏览记录提取的兴趣标签补充到用户画像中。
总结
推荐系统系列之推荐系统概览到此就讲完了。本文介绍了推荐系统的常见概念,常用评价指标,首页推荐和详情页推荐两个场景下的通用召回策略,排序阶段常用的模型,重排阶段,冷启动问题以及推荐系统的架构。相信大家现在已经对推荐系统有了更深刻的理解,我们接下来深入探讨推荐系统的召回阶段。感谢大家的耐心的阅读。
本篇作者

梁宇辉
亚马逊云科技机器学习产品技术专家,负责基于亚马逊云科技的机器学习方案的咨询与设计,专注于机器学习的推广与应用,深度参与了很多真实客户的机器学习项目的构建以及优化。对于深度学习模型分布式训练,推荐系统和计算广告等领域具有丰富经验。
文章来源:https://dev.amazoncloud.cn/column/article/630a21b18a1013112795045a?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN

![[算法前沿]--009-HuggingFace介绍(大语言模型底座)](https://img-blog.csdnimg.cn/img_convert/56687661c9531548ce08c484ff699648.png)