文章目录
- 1、urllib的使用
- response 服务器返回的数据:一个类型,六个方法
- urllib.request.urlretrieve(url,filename) 请求下载网页 请求下载图片 请求下载视频
- 2、请求对象的定制
- 3.编解码
- post请求方式
- ajax的get请求
- ajax的post请求
- cookie模拟登录
- 使用`handler`来处理更高级的请求头
- 代理
- 代理池
1、urllib的使用
urllib.request.urlopen() 模拟浏览器向服务器发送请求
对于一个简单的urllib的代码使用:
import urllib.request
# 定义一个url
url = "http://www.baidu.com"
# 模拟浏览器发送数据
response = urllib.request.urlopen(url)
# 获取响应中页面的源码
# read方法,获取的是字节形成的二进制数据, 需要将二进制变成字符串, 使用decode来按照指定的解码格式进行解码
content = response.read().decode('utf-8')
print(content)
最后获得的数据一定要使用utf-8来进行解码,才能变成我们能看懂的东西。
response 服务器返回的数据:一个类型,六个方法
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 按照一个字节一个字节的去读
content = response.read()
print('response.read() is: ', content)
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 返回参数个字节
content = response.read(5)
print('response.read(5) is: ', content)
#--------------------------readline():读取一行
#import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 读取一行
content = response.readline()
print('response.readline() is ', content)
#-------------------readlines():读取所有行
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 读取所有行
content = response.readlines()
print(type(content))
print(content)
#-------------------geturl(): 返回的是url地址
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 返回的是url地址
print(response.geturl())
#--------------------getcode(): 返回状态码
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 返回状态码 如果是200了 那么就证明我们的逻辑没有错
print(response.getcode())
#获取请求头信息:获取的是一些状态信息
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 获取是一个状态信息
print(response.getheaders())
response的数据类型是HttpResponse
从 字节 — 字符串 的方式是解码 decode
从 字符串 ——字节的方式是编码 encode
对于六个方法:
read()字节形式读取二进制 扩展:read(5)返回前几个字节readline()只能 读取一行readlines()一行一行读取 直至结束getcode()获取状态码 (判断书写逻辑是否正确,返回200表示正常)geturl()获取url地址getheaders()获取headers
案例1: 使用urllib来获取百度首页的源码
# 使用urllib来获取百度首页的源码
import urllib.request
# (1)定义一个url 就是你要访问的地址
url = 'http://www.baidu.com'
# (2)模拟浏览器向服务器发送请求 response响应
response = urllib.request.urlopen(url)
# (3)获取响应中的页面的源码 content 内容的意思
# read方法 返回的是字节形式的二进制数据
# 我们要将二进制的数据转换为字符串
# 二进制--》字符串 解码 decode('编码的格式')
content = response.read().decode('utf-8')
# (4)打印数据
print(content)
urllib.request.urlretrieve(url,filename) 请求下载网页 请求下载图片 请求下载视频
对于方法中的参数说明:
url:下载地址
filename:下载文件名
import urllib.request
# 下载网页
# url_page = 'http://www.baidu.com'
# url代表的是下载的路径 filename文件的名字
# 在python中 可以变量的名字 也可以直接写值
# urllib.request.urlretrieve(url_page,'baidu.html')
# 下载图片
# url_img = 'https://img1.baidu.com/it/u=3004965690,4089234593&fm=26&fmt=auto&gp=0.jpg'
#
# urllib.request.urlretrieve(url= url_img,filename='lisa.jpg')
# 下载视频
url_video = 'https://vd3.bdstatic.com/mda-mhkku4ndaka5etk3/1080p/cae_h264/1629557146541497769/mda-mhkku4ndaka5etk3.mp4?v_from_s=hkapp-haokan-tucheng&auth_key=1629687514-0-0-7ed57ed7d1168bb1f06d18a4ea214300&bcevod_channel=searchbox_feed&pd=1&pt=3&abtest='
urllib.request.urlretrieve(url_video,'hxekyyds.mp4')
通过上述的分析好像我们已经能够下载所有的东西了,其实不然。很多网站都有反爬的机制。去检查你是不是一个爬虫,如果判定你是爬虫就不会让你访问。
所以,做爬虫的另一个机制就是,如何让你看起来比真的用户还像真的用户。
所以,我们需要自己定制一个请求对象,这个请求对象中包含了所有真实用户需要的头。
2、请求对象的定制
UA介绍:User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统 及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
UA反爬虫:在进行爬虫时候,程序模仿浏览器操作,但是反爬虫机制在响应爬虫请求时候需要进行UA识别,这时候就需要将UA参数传进我们的爬虫程序中。
浏览器的UA,可以从开发者模式中任何一个网络请求中的请求头中发现。

小妙招:
在复制请求表头到header中的时候,都需要将所有的东西变成json串的格式。
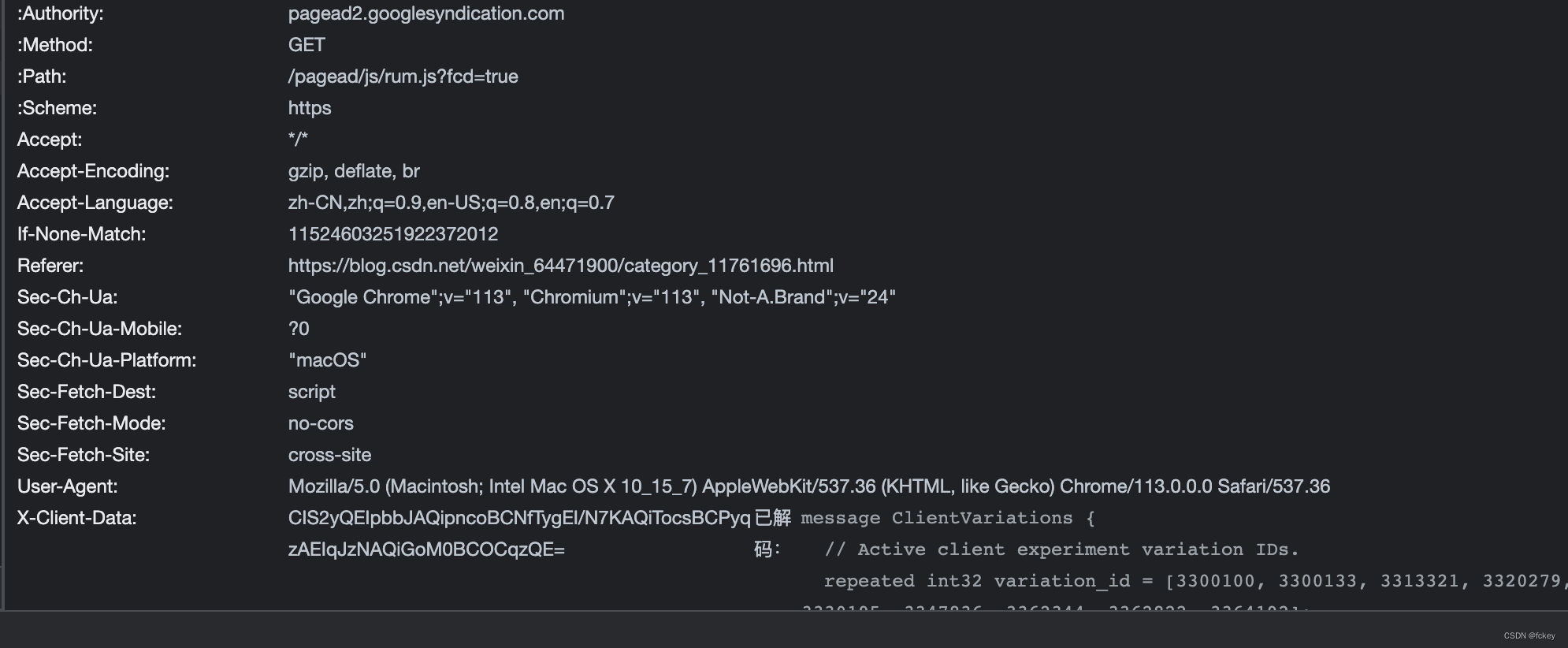
每次都一个一个去输入,特别不方便。
可以先复制到vscode中,之后在使用正则表达式来进行替换。

可能有些有特殊字符的,需要自己微调一下。
需要注意的是: 所有的键值对,键前面带: 不能放到headers去访问。还有
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7 也要去掉。

案例:
如,通过百度来搜索 周杰伦
import urllib.request
url = 'https://www.baidu.com'
# url的组成
# https://www.baidu.com/s?wd=周杰伦
# http/https www.baidu.com 80/443 s wd = 周杰伦 #
# 协议 主机 端口号 路径 参数 锚点
# http 80
# https 443
# mysql 3306
# oracle 1521
# redis 6379
# mongodb 27017
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 因为urlopen方法中不能存储字典 所以headers不能传递进去
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
print(content)
如果上述的代码,我们直接把周杰伦拼接在连接的后面:
url = 'https://www.baidu.com/s?wd=周杰伦'
然后发送请求就会出现

如果我们直接在浏览器的文本框输入,然后回车搜索,在开发者模式中可以看到,其实链接已经被编码成:
https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
那我们能不能使用一个方法来进行呢?
3.编解码
get请求方式:urllib.parse.quote()
quote()方法能够将汉字转换成unicode编码的格式,适用于单个参数
# https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
# 需求 获取 https://www.baidu.com/s?wd=周杰伦的网页源码
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
# 请求对象的定制为了解决反爬的第一种手段
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 将周杰伦三个字变成unicode编码的格式
# 我们需要依赖于urllib.parse
name = urllib.parse.quote('周杰伦')
url = url + name
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
content = response.read().decode('utf-8')
# 打印数据
print(content)
get请求方式:urllib.parse.urlencode()
urlencode()方法也可以将汉字转换成unicode编码,适用于多个参数
案例分析:
# urlencode应用场景:多个参数的时候
# https://www.baidu.com/s?wd=周杰伦&sex=男
# import urllib.parse
#
# data = {
# 'wd':'周杰伦',
# 'sex':'男',
# 'location':'中国台湾省'
# }
#
# a = urllib.parse.urlencode(data)
# print(a)
#运行结果
>>>wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7&location=%E4%B8%AD%E5%9B%BD%E5%8F%B0%E6%B9%BE%E7%9C%81
#获取https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7的网页源码
>>>import urllib.request
>>>import urllib.parse
>>>base_url = 'https://www.baidu.com/s?'
>>>data = {
'wd':'周杰伦',
'sex':'男',
'location':'中国台湾省'
}
>>>new_data = urllib.parse.urlencode(data)
# 请求资源路径
>>>url = base_url + new_data
>>>headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
>>>request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
>>>response = urllib.request.urlopen(request)
# 获取网页源码的数据
>>>content = response.read().decode('utf-8')
# 打印数据
print(content)
post请求方式
post请求方式与get请求方式区别
get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
# post请求
>>>import urllib.request
>>>import urllib.parse
>>>url = 'https://fanyi.baidu.com/sug'
>>>headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
>>>data = {
'kw':'spider'
}
# post请求的参数 必须要进行编码
>>>data = urllib.parse.urlencode(data).encode('utf-8')
# post的请求的参数 是不会拼接在url的后面的 而是需要放在请求对象定制的参数中
# post请求的参数 必须要进行编码
>>>request = urllib.request.Request(url=url,data=data,headers=headers)
# 模拟浏览器向服务器发送请求
>>>response = urllib.request.urlopen(request)
# 获取响应的数据
>>>content = response.read().decode('utf-8')
# 字符串--》json对象
>>>import json
obj = json.loads(content)
>>>print(obj)
ajax的get请求
案例1:获取豆瓣电影的第一页数据并保存起来
# get请求
# 获取豆瓣电影的第一页的数据 并且保存起来
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# (1) 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# (2)获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# (3) 数据下载到本地
# open方法默认情况下使用的是gbk的编码 如果我们要想保存汉字 那么需要在open方法中指定编码格式为utf-8
# encoding = 'utf-8'
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content)
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
案例2:爬取豆瓣电影的前十页数据
# 爬取豆瓣电影前10页数据
# https://movie.douban.com/j/chart/top_list?
type=20&interval_id=100%3A90&action=&start=0&limit=20
# https://movie.douban.com/j/chart/top_list?
type=20&interval_id=100%3A90&action=&start=20&limit=20
# https://movie.douban.com/j/chart/top_list?
10.ajax的post请求
案例:KFC官网
11.URLError\HTTPError
type=20&interval_id=100%3A90&action=&start=40&limit=20
import urllib.request
import urllib.parse
# 下载前10页数据
# 下载的步骤:1.请求对象的定制 2.获取响应的数据 3.下载
# 每执行一次返回一个request对象
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&'
headers = {
'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
data={
# 1 2 3 4
# 0 20 40 60
'start':(page‐1)*20,
'limit':20
}
# data编码
data = urllib.parse.urlencode(data)
url = base_url + data
request = urllib.request.Request(url=url,headers=headers)
return request
# 获取网页源码
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf‐8')
return content
def down_load(page,content):
# with open(文件的名字,模式,编码)as fp:
# fp.write(内容)
with open('douban_'+str(page)+'.json','w',encoding='utf‐8')as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
request = create_request(page)
content = get_content(request)
down_load(page,content)
ajax的post请求
疯狂星期四
# 1页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10
# 2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
'pid':'',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_' + str(page) + '.json','w',encoding='utf-8')as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载
down_load(page,content)
cookie模拟登录
我们知道判断一个用户是否登录的操作就是通过判断用户的唯一标识,大部分都是cookie, 所以,如果我们携带了cookie就可以模拟登录状态, 我们可以携带者cookie进入到任何页面
案例1:微博个人信息页面登录
# 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面
# 个人信息页面是utf-8 但是还报错了编码错误 因为并没有进入到个人信息页面 而是跳转到了登陆页面
# 那么登陆页面不是utf-8 所以报错
# 什么情况下访问不成功?
# 因为请求头的信息不够 所以访问不成功
import urllib.request
url = 'https://weibo.cn/6451491586/info'
headers = {
# ':authority': 'weibo.cn',
# ':method': 'GET',
# ':path': '/6451491586/info',
# ':scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
# cookie中携带着你的登陆信息 如果有登陆之后的cookie 那么我们就可以携带着cookie进入到任何页面
'cookie': '_T_WM=24c44910ba98d188fced94ba0da5960e; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFxxfgNNUmXi4YiaYZKr_J_5NHD95QcSh-pSh.pSKncWs4DqcjiqgSXIgvVPcpD; SUB=_2A25MKKG_DeRhGeBK7lMV-S_JwzqIHXVv0s_3rDV6PUJbktCOLXL2kW1NR6e0UHkCGcyvxTYyKB2OV9aloJJ7mUNz; SSOLoginState=1630327279',
# referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链
'referer': 'https://weibo.cn/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将数据保存到本地
with open('weibo.html','w',encoding='utf-8')as fp:
fp.write(content)
有关于Request和urlopen的对比
urllib.request.urlopen(url)不能定制请求头;urllib.request.Request()可以定制请求头;
使用handler来处理更高级的请求头
handler处理器:目的是用来定制更高级的请求头,随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求(例如动态cookie和代理不能使用请求对象定制)
案例:使用handler来访问百度 获取网页源码
# 需求 使用handler来访问百度 获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
# handler build_opener open
# (1)获取hanlder对象
handler = urllib.request.HTTPHandler()
# (2)获取opener对象
opener = urllib.request.build_opener(handler)
# (3) 调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
代理
代理服务器
代理服务器的常用功能:
- 突破自身ip访问限制,访问国外节点
- 访问一些单位和集体的内部资源
- 提高访问速度
- 隐藏真实ip
代码配置代理
- 创建
request对象 - 创建
proxyHandler对象 - 用
handler对象创建opener对象 - 使用
opener.open函数发送请求
案例
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers= headers)
# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)
proxies = {
'http':'118.24.219.151:16817'
}
# handler build_opener open
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('utf-8')
# 保存
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)
代理池
通过上述的方式,我们已经知道了代理是如何进行使用的。但是,实际上爬虫不会简单的使用一个固定的ip来进行访问。一个公司也不会只有一个ip地址。所以,我们需要从一个池子中来获取ip进行代理。
import urllib.request
proxies_pool = [
{'http':'118.24.219.151:16817'},
{'http':'118.24.219.151:16817'},
]
import random
#使其从代理池中任意选择一个IP
proxies = random.choice(proxies_pool)
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url,headers=headers)
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)





![基于Kruskal和Prim的最小生成树算法[matlab版本]](https://img-blog.csdnimg.cn/36093856c9db4002bca97153a1ef744e.png)